
はじめに
近年、目覚ましい進化を遂げている大規模言語モデル(LLM)は、私たちの日常生活だけでなく、学術界にも大きな影響を与えつつあります。特に、論文執筆におけるLLMの活用は、その効率性や表現力向上の可能性から注目されています。しかし、その利用実態はどの程度広まっているのでしょうか。
本稿では、米国の科学誌『Science Advances』に掲載された「Delving into LLM-assisted writing in biomedical publications through excess vocabulary」という研究をもとに、生物医学分野におけるLLMを活用した論文執筆の現状とその影響について解説していきます。
引用元記事
- タイトル:Delving into LLM-assisted writing in biomedical publications through excess vocabulary
- 著者:Dmitry Kobak, Rita González-Márquez, Emőke-Ágnes Horváth, and Jan Lause
- 発行元:Science Advances
- 発行日:2025年7月2日
- URL:https://doi.org/10.1126/sciadv.adt3813
・あくまで個人の理解に基づくものであり、正確性に問題がある場合がございます。
必ず参照元論文をご確認ください。
・本記事内での画像は、上記論文より引用しております。
要点
- 大規模言語モデル(LLM)のChatGPTが2022年11月に公開されて以降、生物医学分野の学術論文においてLLMによる執筆支援が急速に普及している。
- この研究では、1500万件以上のPubMed抄録の単語頻度変化を分析する「超過語彙分析」という独自の手法を用いた。
- 分析の結果、2024年のPubMed抄録の少なくとも13.5%がLLMによって処理されたと推定された。これはあくまで「下限値」であり、実際の利用率はさらに高い可能性がある。
- LLMがもたらした執筆の変化は、COVID-19パンデミックによる語彙変化をも上回る、前例のない規模と質のものである。
- LLMの利用状況には、専門分野、国、ジャーナルによって大きな差が見られ、一部のサブカテゴリでは利用率が40%に達すると示唆された。
詳細解説
大規模言語モデル(LLM)は、ChatGPTに代表されるように、まるで人間が書いたかのような自然なテキストを生成したり、既存のテキストを修正したりできるAI技術です。これは、膨大な量のテキストデータを学習することで、言語のパターンや構造を理解しているためです。学術分野では、文章の構成、文法の改善、英語への翻訳、要約の作成など、多岐にわたる執筆作業でLLMが活用される可能性が期待されてきました。
しかし、LLMには限界もあります。例えば、不正確な情報(これを「ハルシネーション」と呼びます)を生成したり、既存のバイアスを強化したり、さらには参考文献をでっち上げたりするリスクも指摘されています。このような問題から、研究の公正性や信頼性への懸念も高まっています。また、いわゆる「論文工場」と呼ばれる、不正な論文を量産する組織がLLMを悪用することも懸念されています。
これまでにも、学術論文におけるLLM利用の痕跡を追跡する研究はいくつか行われてきました。これらの研究は主に、LLMが生成したテキストと人間が書いたテキストの「正解データ」を比較することで、LLMによって書かれた部分を特定しようとするものでした。しかし、この方法には、「どのようなLLMが、どのようにプロンプト(指示)されて使われているのか」という仮定が必要であり、その仮定によってはバイアスが生じる可能性があるという課題がありました。また、LLMの検出器は「ブラックボックス」であるため、なぜ特定のテキストがLLMによるものと判断されたのか、単語レベルで詳細に分析することが難しいという問題もありました。
「超過語彙」分析のアプローチ
本研究では、これらの既存手法の限界を克服するため、新たな「データ駆動型アプローチ」を提案しています。その着想源となったのは、COVID-19パンデミック時の「超過死亡率」の分析でした。これは、過去の死亡率と比較して、パンデミック時にどれだけ多くの人が死亡したかを見る手法です。
このアイデアを単語の利用頻度に応用したのが、今回の「超過語彙(Excess Vocabulary)分析」です。具体的には、PubMedという生物医学分野の論文抄録(要旨)を収集・公開しているデータベースから、2010年から2024年までの1500万件以上 の英語抄録をダウンロードし、各単語の年ごとの出現頻度を計算しました。
研究者たちは、LLMのChatGPTが広く利用可能になった2022年11月以前の単語頻度(特に2021年と2022年のデータ)から、2024年の単語頻度を線形に「外挿(将来を予測)」して、「期待される頻度」を算出しました。そして、この「期待される頻度」と実際の2024年の「観測された頻度」を比較することで、その差(超過頻度ギャップδ)や比率(超過頻度比 r)を計算しました。
この二つの指標は補完的です。超過頻度ギャップ(δ)は、比較的高頻度で使われる単語がどれだけ多く出現したかを捉えるのに適しています。例えば、もともと「0.5」の頻度だった単語が「0.6」になった場合のように、わずかな頻度増加でも非常に多くの論文で使われていることを示します。一方、超過頻度比(r)は、比較的低頻度で使われる単語がどれだけ急激に増えたかを捉えるのに有効です。例えば、もともと「0.001」の頻度だった単語が「0.01」になった場合のように、絶対数は少なくともその増加率が顕著であることを示します。
LLMが引き起こした「前例のない」変化
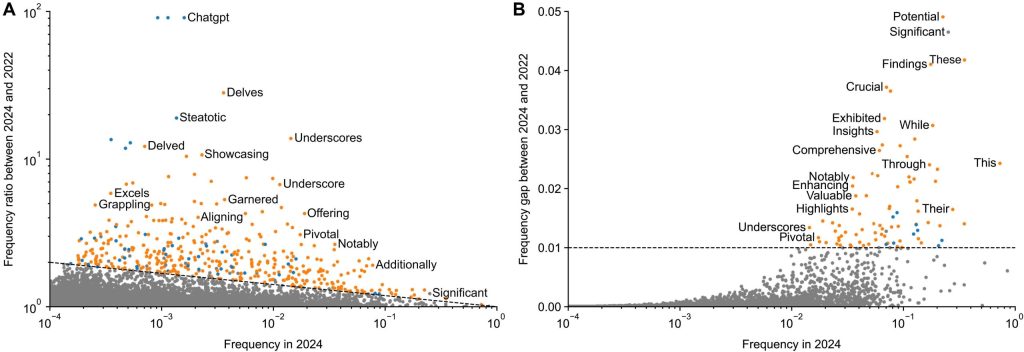
この分析の結果、2024年には多くの単語で顕著な「超過使用」が見られました。比較的珍しい単語では「delves」(深く掘り下げる、r=28.0)、「underscores」(強調する、r=13.8)、「showcasing」(見せびらかす、r=10.7)などが挙げられます。また、より一般的な単語では「potential」(可能性、δ=0.052)、「findings」(知見、δ=0.041)、「crucial」(極めて重要、δ=0.037)などが大きく増加していました。
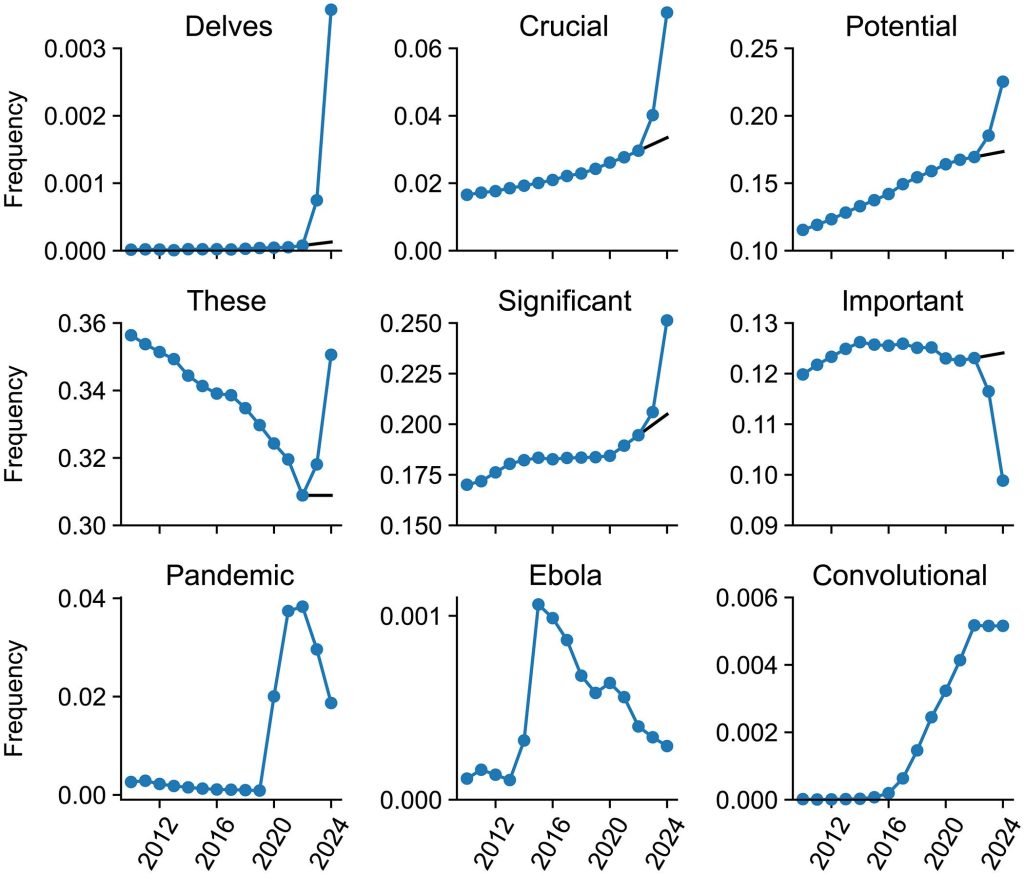
これらの変化がどれほど「異常」なのかを比較するため、研究者たちは過去の年(2013年〜2023年)についても同様の分析を行いました。過去には、エボラ出血熱(2015年の「ebola」でr=9.9)やジカ熱(2017年の「zika」でr=40.4)といった単語が、その年に大きな流行があったことで一時的に頻度を増やした例がありました。しかし、2013年から2019年の間には、超過頻度ギャップ(δ)が0.01を超える単語は一つもありませんでした。
この状況が大きく変わったのはCOVID-19パンデミック時です。2020年から2022年には、「coronavirus」「covid」「lockdown」「pandemic」といった単語が非常に大きな超過使用を示し、その超過使用率はr>1000、δ=0.06に達するものもありました。これは、COVID-19が生物医学論文に前例のない影響を与えたという先行研究の観察と一致します。
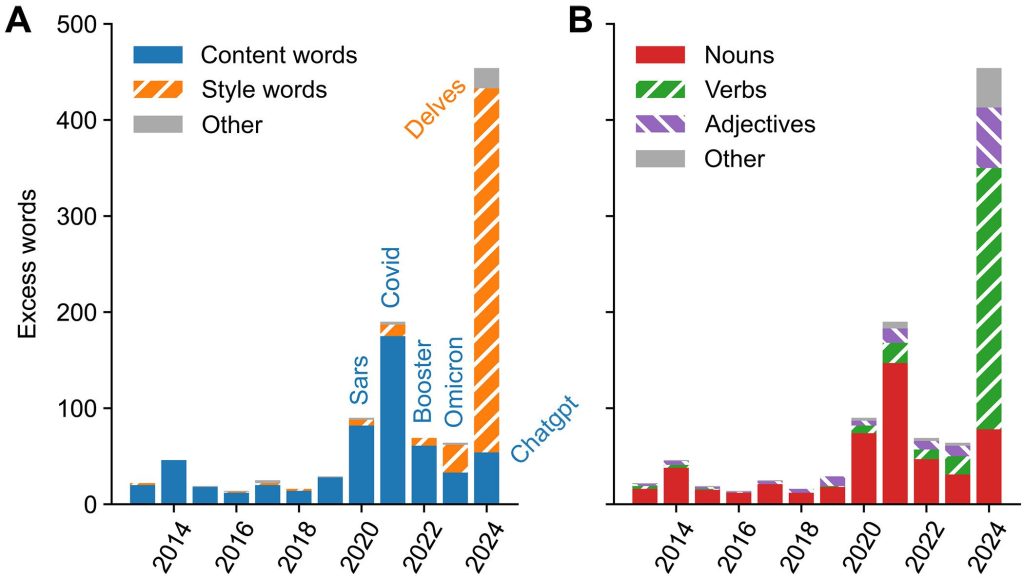
しかし、2024年に見られた単語頻度の変化は、COVID-19パンデミックによるものとは質的に異なっていました。研究者たちは、超過使用された単語を手作業で「内容語(content words)」と「スタイル語(style words)」に分類しました。内容語とは「マスク」「畳み込み(ニューラルネットワークの)層」のように、テキストの内容に直接関連する単語です。一方、スタイル語とは「入り組んだ(intricate)」「特筆すべきは(notably)」のように、文章の様式や修辞に関わる単語です。
COVID-19パンデミック時の超過語彙は、ほぼすべてが「respiratory(呼吸器の)」「remdesivir(レムデシビル)」といった内容語でした。これに対し、2024年の超過語彙は、ほぼすべてがスタイル語で構成されていました。さらに、品詞(単語の種類)で見ると、内容語は名詞が圧倒的に多かったのに対し、2024年の超過スタイル語の66%は動詞、14%は形容詞でした。これは、LLMがしばしば用いる「流麗な」表現に見られる特徴と一致します。
LLM利用の推定値
これらの超過スタイル語は、LLMが文章作成に用いられた「マーカー(目印)」となると考えられました。個々のマーカー単語の超過頻度ギャップ(δ)は、LLMによって処理された抄録の割合の「下限値」を示します。例えば、「potential」という単語のδが0.052であったことは、2024年の抄録の少なくとも5.2%がLLMを通過したことを示唆しています。
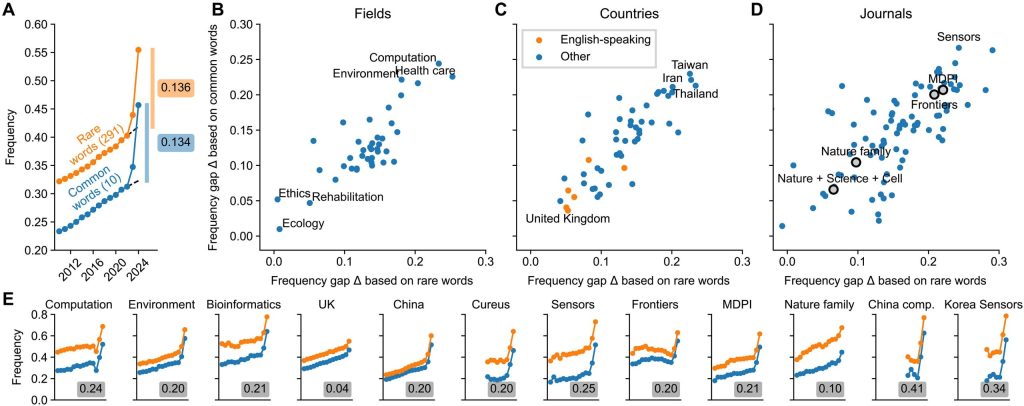
この研究では、さらに複数のマーカー単語を組み合わせることで、LLM利用の推定下限値を高めることに成功しました。彼らは、「珍しいスタイル語のセット」(291語)と「一般的なスタイル語のセット」(10語:「across」「additionally」「comprehensive」「crucial」「enhancing」「exhibited」「insights」「notably」「particularly」「within」)という二つの異なる方法でマーカー単語のグループを作成しました。
驚くべきことに、これらの独立した二つのセットは、それぞれ13.6%と13.4%という非常に類似した頻度ギャップをもたらしました。この二つの推定値を平均した結果、2024年のPubMed抄録の少なくとも13.5%がLLMによって処理されたという最終的な「下限値」が導き出されました。PubMedには年間約150万件の論文が登録されているため、これは少なくとも年間20万件の論文の執筆にLLMが関与していることを意味します。
なぜ「下限値」なのでしょうか?それは、この分析が特定の「マーカー単語」の増加に基づいているためです。もしLLMがこれらのマーカー単語を使わずに文章を生成したり、LLMの出力が人間の手によって巧妙に修正され、LLM特有のスタイル語が取り除かれていたりした場合、そのLLM利用は検出されません。そのため、実際のLLM利用率は、この13.5%という数値よりもはるかに高い可能性があります。
サブグループごとの差異
LLM利用の「下限値」は、研究分野、国、ジャーナルといった様々なサブグループによって大きく異なることが明らかになりました。
- 研究分野別: 計算機科学やバイオインフォマティクスといった計算系の分野では、LLM利用の下限値が約20%と高めでした。これは、コンピュータサイエンスの研究者がLLM技術に慣れ親しみ、積極的に導入しているためと考えられます。
- 国別: 英語圏の国、例えばイギリスやオーストラリアでは下限値が約5%と比較的低かったのに対し、中国、韓国、台湾といった国々では約20%と高くなっていました。非英語圏の著者にとって、LLMが英語での執筆や校正の助けになることが、その広範な利用を後押ししている可能性があります。
- ジャーナル別: オープンアクセスジャーナルで、迅速な査読プロセスを持つことで知られるMDPI社の”Sensors”や”Cureus”のようなジャーナルでは、LLM利用の下限値がそれぞれ25%と20%と非常に高かったのです。対照的に、『Nature』『Science』『Cell』のような権威ある一流ジャーナルでは、この下限値は7%から10%とかなり低めでした。これは、査読が厳格なジャーナルほど、LLMによる検出可能な「癖」が少ないのかもしれません。
- さらに細かく分析すると、韓国からの論文で”Sensors”に掲載されたものの場合、下限値は34%に達し、中国からの計算科学分野の論文では41%にまで跳ね上がる事例も確認されました。これは、ディープラーニングに基づく物体検出に関する論文のクラスターで顕著に見られた現象です。
これらの違いは、単にLLMの採用率が異なるだけでなく、LLMの出力をどれだけ巧妙に修正しているか、あるいは各分野やジャーナルの出版タイムラインの速さなども影響している可能性が指摘されています。研究者たちは、LLM利用の検出可能な下限値が最も高いサブグループ(例えば40%を超えるようなケース)が、実際のLLM利用状況に近いのではないかと考えています。なぜなら、これらのケースではLLMの利用が「素朴」で、最も検出しやすい形で現れている可能性が高いからです。
研究の意義と今後の課題
本研究の最大の特徴は、これまでのLLM検出研究と異なり、正解となる教師データを必要としない点です。これにより、教師データ作成時のバイアスを回避し、実際の学術論文におけるLLMの「痕跡」を直接捉えることを可能にしました。また、過去のデータと比較することで、LLMが学術執筆に与えた影響が、COVID-19パンデミックによる変化をも凌駕する歴史上類を見ない規模であることを定量的に示した点も非常に重要です。
LLMの利用は、前述のメリットがある一方で、深刻なデメリットも抱えています。誤情報の生成、既存のバイアスの模倣、さらには剽窃(盗用)のリスクもあります。LLMが生成するテキストは、人間が書いたものに比べて多様性や新規性に欠ける可能性があり、学術的な議論の均質化やイノベーションの阻害につながる恐れも指摘されています。
こうした状況に対し、多くの出版社や研究助成機関は、すでにLLMを査読で禁止したり、共著者として認めなかったり、あるいは一切の利用を非公開にすることを禁じたりといったポリシーを打ち出しています。本研究のようなデータに基づいた分析は、これらのポリシーが実際に遵守されているのか、あるいは無視されているのかを監視する上で非常に役立ちます。
論文の著者たちは、今回の研究で示されたLLM利用の「下限値」が、今後さらに増加する可能性が高いと述べています。これは、より多くの出版サイクルを分析できるようになること、そしてLLM自体の利用がさらに広がるであろうことが理由です。同時に、LLMの出力がより洗練され、人間による修正が進むことで、その利用が「検出されにくくなる」という側面も強調されています。
この研究は、LLMが学術執筆に与える影響の大きさを明確に示し、その影響がCOVID-19パンデミックによる変化さえも凌駕するものであると結論付けています。この傾向は今後さらに強まることが予想されるため、LLMの利用に関する現在のポリシーや規制を再評価する必要があることを強く示唆しています。このような測定手法は、LLMの利用に関する必要な議論を深める上で不可欠なツールとなるでしょう。
まとめ
本稿では、『Science Advances』に掲載された研究論文を基に、生物医学分野におけるLLMを用いた論文執筆の現状と、その影響について解説しました。単語の出現頻度に着目する「超過語彙分析」という独創的な手法により、2024年にはPubMed抄録の少なくとも13.5%がLLMによって作成・修正されたと推定されました。この数値は控えめなものであり、実際の利用率はさらに高い可能性を秘めています。
特に注目すべきは、LLMによって増加した語彙が、COVID-19パンデミック時のように内容に関連する単語ではなく、文章の様式に関わる「スタイル語」であった点です。これは、LLMが文章表現そのものに大きな影響を与えていることを示唆しています。また、国や専門分野、ジャーナルによってLLMの利用率に大きな差があることも明らかになりました。
LLMは論文執筆を効率化し、より質の高い文章作成に貢献する可能性がありますが、同時に不正確な情報、バイアスの拡散、論文の均質化といったリスクもはらんでいます。この「前例のない」変化に対し、学術コミュニティはLLMの適切な利用に関するポリシーを策定し、その遵守状況を継続的に監視していく必要があります。本研究のようなデータに基づいた分析は、そうした議論を進める上で非常に重要な基盤となるでしょう。








