
はじめに
機械学習モデルの開発は、データの前処理からモデルの選択、ハイパーパラメータの調整まで、膨大で複雑な試行錯誤を必要とする作業です。このプロセスを自動化するため、近年、大規模言語モデル(LLM)を活用した「機械学習エンジニアリング(MLE)エージェント」の研究が進んでいます。本稿では、Google Researchが発表したこの分野における新しいAIエージェントMLE-STARについて、分かりやすく解説します。
※より詳細に理解したい方:

参考記事
- タイトル: MLE-STAR: A state-of-the-art machine learning engineering agent
- 著者: Jinsung Yoon (Research Scientist), Jaehyun Nam (Student Researcher), Google Cloud
- 発行元: Google Research
- 発行日: 2025年8月1日
- URL: https://research.google/blog/mle-star-a-state-of-the-art-machine-learning-engineering-agents/
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- MLE-STARは、機械学習モデルの開発プロセスを自動化するAIエージェントである。
- 最大の特徴は、Web検索を活用して最新かつタスクに最適な手法を自ら見つけ出し、初期ソリューションを構築する点である。
- コード全体を一度に修正するのではなく、アブレーションスタディ(要素除去試験)によって性能への影響が最も大きいコード部分を特定し、そこを集中的に改良することで、効率的に性能を向上させる。
- 複数のモデル候補を高度な戦略で統合する独自のアンサンブル手法を持つ。
- 「デバッガ」「データリーケージチェッカー」「データ使用量チェッカー」という3つの監視モジュールを備え、コードの品質と堅牢性を高めている。
- 世界的なデータサイエンスコンペティションプラットフォームKaggleのベンチマークにおいて、参加したコンペの63%でメダルを獲得するという高い性能を実証した。
詳細解説
前提知識:機械学習エンジニアリング(MLE)エージェントとは?
まず、本稿のテーマであるMLE-STARを理解するために、「MLEエージェント」がどのようなものかを知る必要があります。
MLEエージェントとは、一言で言えば「機械学習モデル開発を自動で行うAI」です。開発者から「このデータセットを使って、こういう予測をしてほしい」といったタスクの指示を受け取ると、エージェントが自律的にデータの分析、適切なモデルの選択、コードの記述、学習、評価までの一連のプロセスを実行し、最終的に成果物として実行可能なPythonスクリプトなどを生成します。これは、これまで人間が多くの時間と専門知識を費やして行ってきた作業を、AIが代行しようという試みです。

従来のエージェントが抱えていた課題
MLEエージェントは有望な技術ですが、従来の手法にはいくつかの課題がありました。
- 知識の偏りと固定化: 多くのエージェントは、自身が学習したLLMの内部知識に依存していました。そのため、表形式のデータであれば「scikit-learn」、画像であれば「ResNet」といった、有名で頻繁に使われる手法に頼りがちでした。しかし、タスクによっては、もっと新しくてニッチな手法の方が高い性能を発揮することもあります。従来のエージェントは、そうした最適な選択肢を見逃してしまう傾向がありました。
- 非効率な改良プロセス: 従来のエージェントは、生成したコードの性能を改善しようとする際、コード全体を一度に書き換えるというアプローチを採っていました。しかし、機械学習のパイプラインは「特徴量エンジニアリング」「モデル選択」「ハイパーパラメータ調整」など複数の要素で構成されており、性能への影響度はそれぞれ異なります。全体を一度に修正する方法では、どの部分の改良が本当に効果的だったのかが分からず、深い探索ができないという問題がありました。
MLE-STARのアプローチ
MLE-STARは、これらの課題を克服するために、いくつかの新たな仕組みを導入しています。
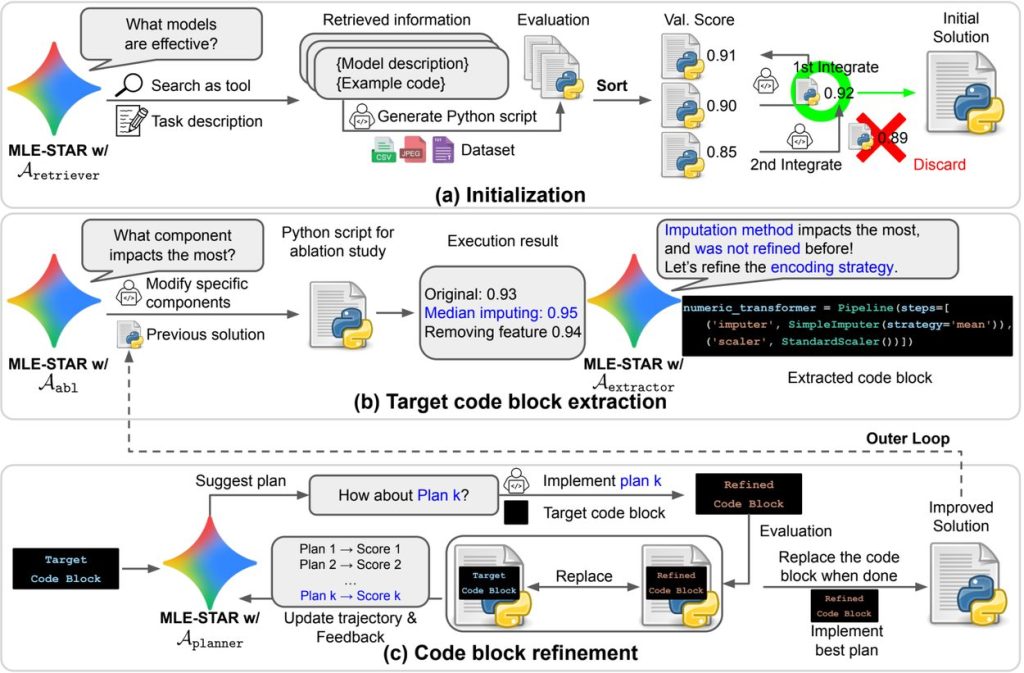
1. Web検索による最新知識の獲得
MLE-STARの最も重要な特徴は、LLMの内部知識だけに頼るのではなく、Web検索を積極的に利用する点です。タスクが与えられると、まずその内容に関連する最新の論文、Kaggleの上位解法、GitHubのコードなどをWebで検索し、「どのようなモデルやアプローチが有効か」という情報を収集します。この情報に基づいて、非常に質の高い初期ソリューションコードを生成します。これにより、従来のエージェントが陥りがちだった知識の偏りをなくし、常にその時点での最先端かつタスクに特化したアプローチを取り入れることができます。
2. 「選択と集中」による効率的なコード改良
初期ソリューションをさらに改良するプロセスもユニークです。MLE-STARは、まずアブレーションスタディと呼ばれる手法を用いて、コード内のどの部分(コンポーネント)が最終的な性能に最も大きく影響しているかを分析します。
アブレーションスタディとは、例えば「特徴量Aを処理するコード」を一時的に無効化してみて、性能がどれくらい低下するかを計測するような実験です。これを各コンポーネントで繰り返すことで、「この部分が性能の要だ」という最重要コードブロックを特定できます。
特定後は、そのコードブロックだけを集中的に改良します。様々な代替案を試し、フィードバックを得ながら最も良い結果が出たものに置き換えるのです。この「選択と集中」のアプローチにより、やみくもに全体を修正するよりもはるかに効率的かつ効果的にコードを洗練させていくことができます。
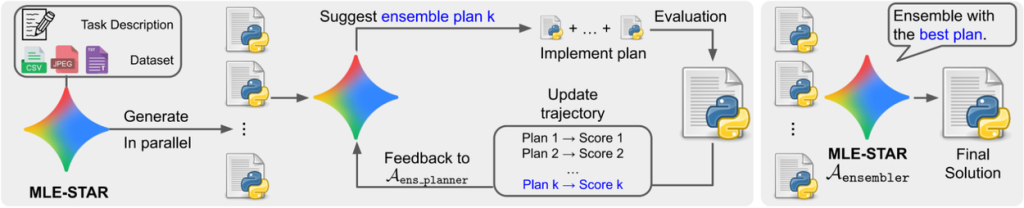
3. より効果的なアンサンブル
さらに、アンサンブルを生成するための新たな手法を提案しています。
MLE-STARはまず複数の候補解を提示します。次に、検証スコアに基づく単純な投票メカニズムに頼るのではなく、エージェント自身が提案するアンサンブル戦略を用いて、これらの候補解を単一の改善された解に統合します。このアンサンブル戦略は、先行する戦略のパフォーマンスに基づいて反復的に改良されます。
4. 堅牢性を高める3つのチェッカー
MLE-STARは、ただ性能を追求するだけでなく、生成するコードの品質と信頼性を担保するための監視機能も備えています。
- データリーケージチェッカー: 機械学習では、訓練データにテストデータの情報が漏れ(リーク)てしまうと、モデルの性能を正しく評価できなくなります。例えば、テストデータを含んだ全データで欠損値補完の平均値を計算してしまう、といったミスが起こりがちです。MLE-STARはこの種のデータリーケージを自動で検出し、修正します。
- データ使用量チェッカー: 複数のデータファイル(例: train.csv, extra_data.txt)が提供されたにもかかわらず、LLMが最も扱いやすいCSVファイルしか使わない、といったケースがあります。このチェッカーは、提供された全てのデータソースが適切に利用されているかを確認し、見落としがあればコードを修正します。
- デバッグエージェント: 生成したコードの実行中にエラーが発生した場合、そのエラー情報(トレースバック)を基にコードのバグを自動で修正します。
実証された高い性能
MLE-STARの有効性は、Kaggleの過去のコンペティションを再現したベンチマーク「MLE-Bench-Lite」で評価されました。その結果、比較対象となった他のどのエージェントよりも優れた成績を収め、参加したコンペの63%で何らかのメダル(金・銀・銅)を獲得し、そのうち36%は金メダルでした。
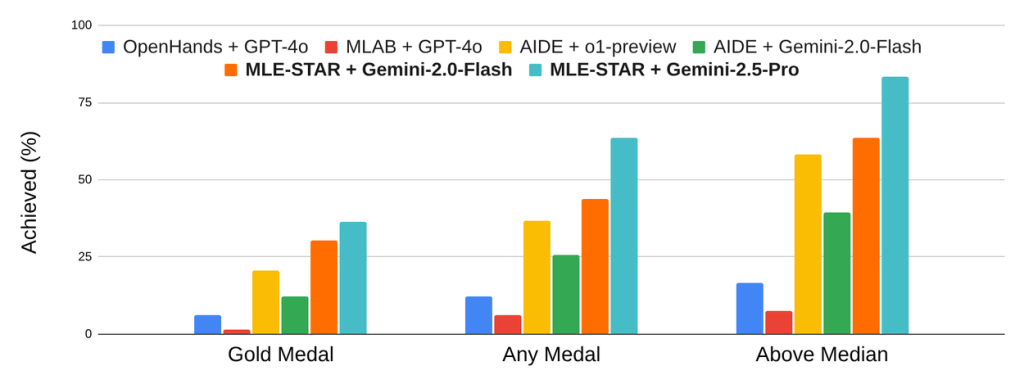
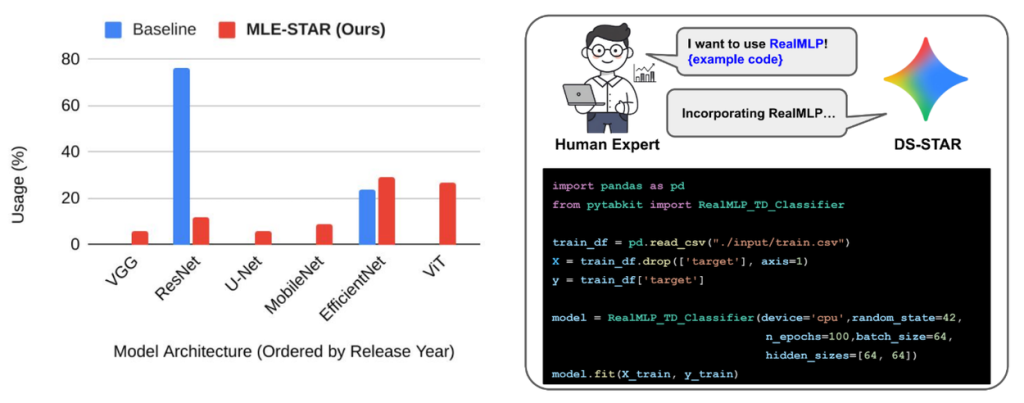
これは、人間が手動で戦略を集めて作ったベースラインさえも上回る結果です。この性能の背景には、Web検索によってResNetのような少し古いモデルではなく、EfficientNetやViTといったより新しく強力なモデルを適切に選択できていることが挙げられます。
まとめ
本稿では、Googleが開発した新しい機械学習エンジニアリングエージェント「MLE-STAR」について解説しました。MLE-STARは、Web検索による自己学習能力と、影響の大きい箇所に集中して改良する効率的なアプローチを組み合わせることで、機械学習モデル開発の自動化を新たなレベルへと引き上げました。さらに、データリーケージなどを防ぐ堅牢な設計により、信頼性の高いソリューションを生成します。
この技術は、専門家でない個人や組織が機械学習を活用する際の障壁を大きく下げ、様々な分野でのイノベーションを加速させる可能性を秘めています。また、Webから常に最新情報を取得するため、機械学習の分野が進歩すればするほど、MLE-STARが生み出すソリューションの性能も自動的に向上していくという、自己進化的な側面も持っています。開発者や研究者は、公開されたオープンソースコードベースを利用して、自身のプロジェクトを加速させることができるでしょう。
※より詳細に理解したい方:








