
はじめに
大規模言語モデル(LLM)が直面する大きな課題として、コンテキスト長(文脈の長さ)が伸びた際の計算量の問題(二次スケーリング)があります。この課題は、長大な文書や対話履歴を処理する際に、リソースの制約を深刻化させます。
この問題に対する潜在的な解決策として、DeepSeek-AIの研究者たちは、視覚モダリティを効率的な圧縮媒体として活用することを提案しています。文書テキストを含む単一の画像は、対応するデジタルテキストよりもはるかに少ない視覚トークン(vision tokens)で豊かな情報を表現できるため、光学的圧縮(optical compression)を通じて非常に高い圧縮率を達成できる可能性があります。
この可能性を検証するために開発されたのが、DeepSeek-OCRです。このモデルは、視覚言語モデル(VLM)として、特にOCR(Optical Character Recognition、光学文字認識)タスクをテストベッドにしています。OCRは、視覚表現(画像)からテキスト表現への自然な圧縮と展開(デコード)のマッピングを提供する、理想的な検証環境だからです。
本稿では、DeepSeek-OCRの革新的なアーキテクチャ、特に長文コンテキストの効率的な処理を実現するDeepEncoderの仕組みと、その性能について説明します。
解説論文
- 論文タイトル:DeepSeek-OCR: Contexts Optical Compression
- 論文URL:https://arxiv.org/abs/2510.18234
- 発行日:2025年10月21日
- 発表者:Haoran Wei, Yaofeng Sun, Yukun Li (DeepSeek-AI)
〇GitHub: https://github.com/deepseek-ai/DeepSeek-OCR
・あくまで個人の理解に基づくものであり、正確性に問題がある場合がございます。
必ず参照元論文をご確認ください。
・本記事内での画像は、上記論文より引用しております。
※利用方法が知りたい方は以下をご参照ください。

要点
- 視覚-テキスト圧縮の実現:DeepSeek-OCRは、長文コンテキストの課題に対応するため、文書を画像として視覚モダリティに変換し、それを少数の視覚トークンに圧縮・展開する手法を検証している。
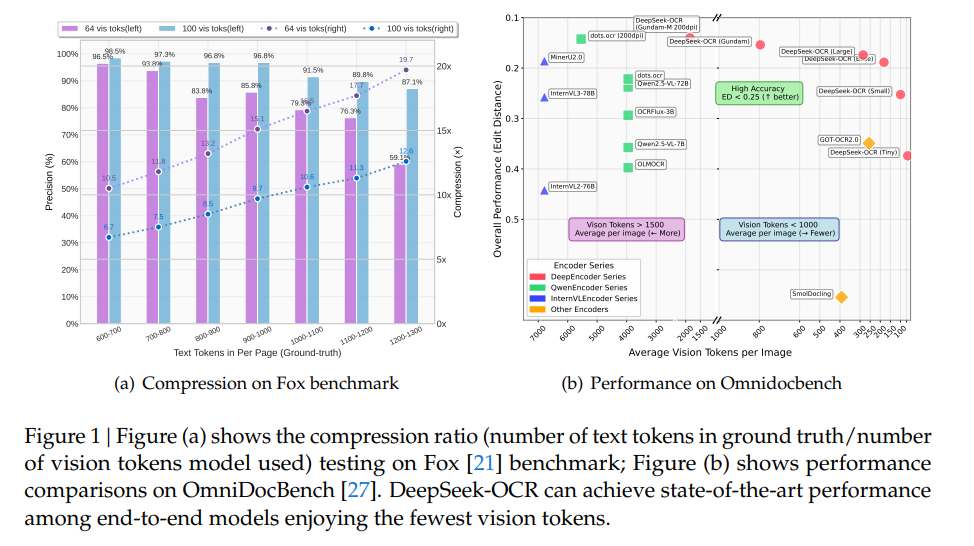
- 圧縮性能と精度:テキストトークンが視覚トークンの10倍以内(約10倍圧縮)であれば、デコーディング精度は97%に達する。20倍圧縮時でも、OCR精度は約60%を維持する。
- DeepEncoderの独自性:コアエンジンであるDeepEncoderは、高解像度入力時に低い活性化メモリ(GPUメモリの使用量)を保ちつつ、高い圧縮率を実現するために設計された新しいアーキテクチャである。
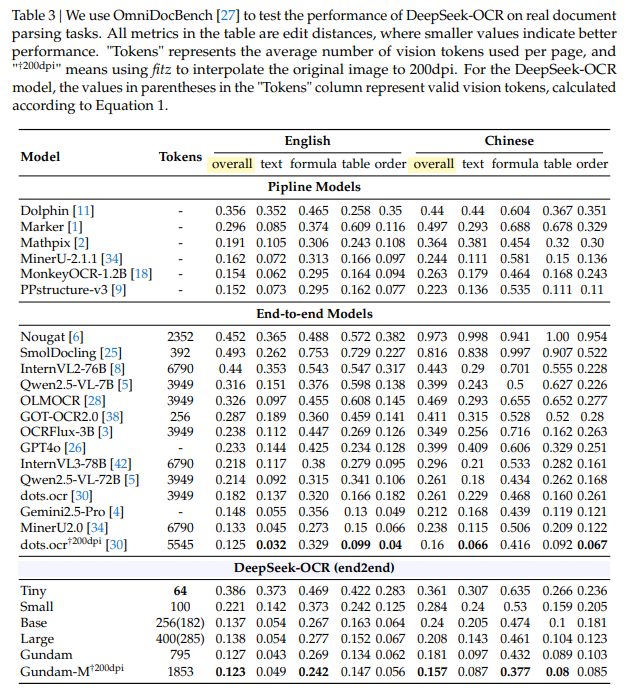
- 実用性の高さ:OmniDocBenchにおいて、最先端のエンドツーエンドOCRモデルの中で最も少ない視覚トークン数で最高水準の性能を達成している。また、大規模なLLM/VLMのトレーニングデータ生成(1日あたり20万ページ以上)の実用的な価値も高い。
- 将来の応用:この光学的圧縮パラダイムは、LLMにおける長文コンテキスト処理の効率化や、人間の記憶のような忘却メカニズムのモデリングに道を開く、有望な研究方向性である。
詳細解説
DeepSeek-OCRがどのように設計され、その性能がどのように評価されたかについて、論文の構成に沿ってみていきます。
1 Introduction(はじめに)
大規模言語モデル(LLMs)が抱える、シーケンス長の二次的なスケーリングによる計算上の課題がまず指摘されています。
本研究の基本的な発想は、テキスト情報が格納された画像を視覚モダリティとして利用することで、等価なデジタルテキストよりも大幅に少ないトークンで情報を表現し、高い圧縮率(光学的圧縮)を達成することです。
このアプローチを定量的に評価するために、視覚表現とテキスト表現の間のマッピングを確立できるOCRタスクが理想的なテストベッドとして選ばれました。DeepSeek-OCRは、この効率的な視覚-テキスト圧縮の概念実証(PoC)モデルとして提示されています。
本稿が提供する主な貢献は以下の3点です。
- 視覚-テキストトークン圧縮比の包括的な定量分析の提供。Foxベンチマークで、9~10倍圧縮時に96%以上の精度、20倍圧縮時に約60%の精度を達成しました。
- 高解像度入力でも低い活性化メモリと最小限の視覚トークン数を維持する新しいアーキテクチャDeepEncoderの提案。
- DeepEncoderとDeepSeek3B-MoEを基盤としたDeepSeek-OCRが、OmniDocBenchにおいて、使用する視覚トークン数が最も少ないエンドツーエンドモデルの中で最高水準の性能を達成したこと。
2 Related Works(関連研究)
2.1 Typical Vision Encoders in VLMs(VLMにおける一般的な視覚エンコーダ)
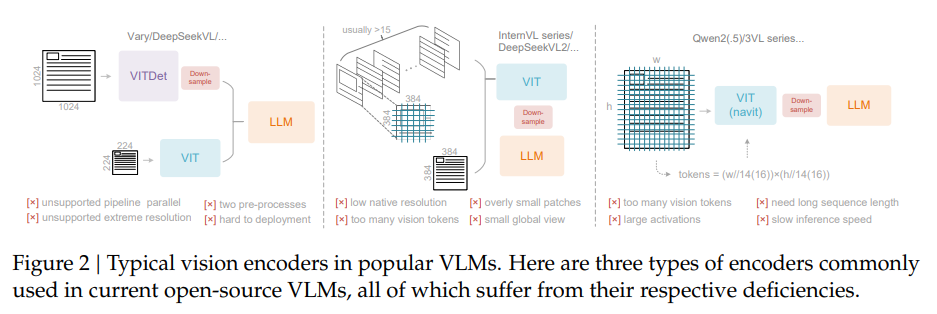
現在のオープンソースVLMで使用されている視覚エンコーダは主に3つのタイプに分類されますが、DeepSeek-OCRが目指す「高解像度処理」「低活性化メモリ」「少ない視覚トークン」などの要件をすべて満たすものはありません。
- Varyに代表されるデュアルタワーアーキテクチャは、高解像度処理のために並列エンコーダを使用しますが、二重の前処理や学習時の並列化の困難さという欠点があります。
- InternVL2.0に代表されるタイルベース手法は、画像をタイルに分割して処理することでメモリを削減しますが、ネイティブ解像度が低いため、大きな画像では視覚トークンが過剰に発生します。
- Qwen2-VLに代表される適応的解像度エンコーディングは、タイル化せずフル画像をパッチベースで処理しますが、大きな画像では活性化メモリ消費が大きすぎてGPUメモリオーバーフローを引き起こす可能性があり、また多くの視覚トークンが必要となるため推論速度も低下します。
2.2 End-to-end OCR Models(エンドツーエンドOCRモデル)
VLMの進歩により、検出と認識の専門モデルを必要とした従来のパイプラインから、単一のモデルで完結するエンドツーエンドのOCRモデル(例:Nougat、GOT-OCR2.0)が登場し、システムが大幅に単純化されています。
本研究は、このエンドツーエンドOCRの文脈において、「1000語を含む文書をデコードするために、最低限必要な視覚トークンはいくつなのか?」という、視覚-テキスト圧縮の限界を探る核心的な問いを立てています。これは「一見は百聞に如かず」(”a picture is worth a thousand words.”)という原則の研究にとって、重要な意味をもつとされています。
3 Methodology(手法)
3.1 Architecture(アーキテクチャ)
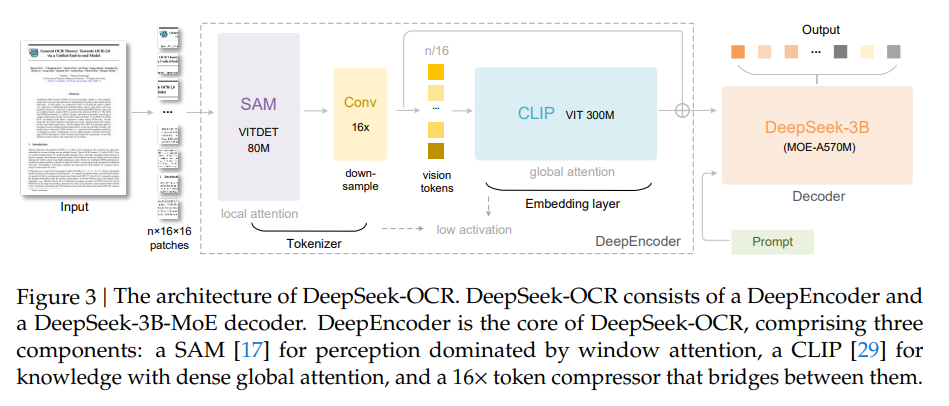
DeepSeek-OCRは、エンコーダとデコーダからなる統一されたエンドツーエンドのVLMアーキテクチャを採用しています。
- DeepEncoder:画像の特徴抽出と、視覚表現のトークン化および圧縮を担当します。パラメータは約380Mで、80MのSAM-base と300MのCLIP-large を直列に接続した構成です。
- デコーダ:DeepSeek-3B-MoE(Mixture-of-Experts)を採用しており、推論時には64個のエキスパートのうち6個と2つの共有エキスパートが活性化され、約570Mの活性化パラメータで動作します。このMoEアーキテクチャにより、3Bモデルの表現力と500Mモデルの推論効率を両立しています。
3.2 DeepEncoder
DeepEncoderは、高解像度処理、低活性化メモリ、少ない視覚トークンという要件を満たすために特別に設計された、新規の視覚エンコーダです。
3.2.1 Architecture of DeepEncoder(DeepEncoderのアーキテクチャ)
DeepEncoderは、以下の要素で構成されています。
- 視覚知覚特徴抽出コンポーネント:ウィンドウアテンション(window attention)が主体(SAM-baseを使用)。
- 視覚知識特徴抽出コンポーネント:密なグローバルアテンション(dense global attention)を持つ(CLIP-largeを使用)。
- 16倍トークンコンプレッサ:上記2つのコンポーネントの間に位置し、2層の畳み込みモジュールでトークン数を1/16にダウンサンプリングします。
この設計により、例えば1024×1024の画像は最初に4096パッチトークンに分割されますが、ウィンドウアテンション主体(80M)の前段では活性化メモリが抑えられます。その後、コンプレッサでトークン数が256に削減されてからグローバルアテンションに進むため、全体のメモリ消費とトークン圧縮が効率的に達成されます。
3.2.2 Multiple resolution support(多解像度サポート)
DeepEncoderは、位置エンコーディングの動的補間を通じて多解像度入力をサポートしており、同時に複数の解像度モードで学習されています。これにより、様々な圧縮率をテストできます。

主に以下の2つの入力モードがあります。
- ネイティブ解像度(Native resolution):
- Tiny (512×512, 64トークン)、Small (640×640, 100トークン)、Base (1024×1024, 256トークン)、Large (1280×1280, 400トークン) の4つがあります。
- Tiny/Smallでは画像を直接リサイズし、Base/Largeではアスペクト比を保持するためにパディングを使用します。パディングを使用した場合、有効な視覚トークン数 \(N_{valid}\) は、入力画像サイズ (w, h) に応じて以下の式で計算されます。
$$N_{valid} = \lceil N_{actual} \times \left[1 – \left(\frac{\max (w, h) -\min(w, h)}{\max (w, h)}\right)\right] \rceil \quad (1)$$
- ダイナミック解像度(Dynamic resolution):
- 超高解像度入力に対応するモードで、タイル化(tiling)を利用してローカルビューとグローバルビューを組み合わせます。タイル化は、活性化メモリをさらに削減する効果があります。
- Gundamモード:\(n \times 640 \times 640\) のタイル(ローカルビュー)と \(1024 \times 1024\) のグローバルビューで構成され、トークン数は \(n \times 100 + 256\) となります(\(n\) はタイルの数、2〜9)。
- Gundam-masterモード:さらに大規模な解像度で、学習済みのモデルに追加学習することで得られます。

3.3 The MoE Decoder(MoEデコーダ)
DeepSeekMoEデコーダは、DeepEncoderから得られた圧縮された潜在視覚トークン \(Z\) を受け取り、そこから元のテキスト表現 \( \hat{X} \) を再構築します。これは、コンパクトな言語モデルがOCR形式の学習を通じて効果的に学習できる非線形マッピング \( f_{dec} \) を表します。
$$f_{dec} : R^{n \times d_{latent}} \to R^{N \times d_{text}} ; \hat{X} = f_{dec}(Z) \quad (2)$$
このプロセスを通じて、LLMが視覚モダリティを介して圧縮された情報を自然に統合する能力を獲得できることが示唆されています。
3.4 Data Engine(データエンジン)
DeepSeek-OCRの学習のために、OCR 1.0、OCR 2.0、一般視覚データ、テキストのみのデータを含む、複雑で多様な学習データが構築されました。
3.4.1 OCR 1.0 data(OCR 1.0データ)
- 文書データ:約100言語をカバーする30Mページの多様なPDFデータから構成されます。
- 粗いアノテーション(fitzから直接抽出):特に少数言語の光学テキスト認識を学習させることが目的です。
- 細かいアノテーション(2Mページ/中英):高度なレイアウト・OCRモデルを用いて構築された、検出と認識が織り交ぜられたデータです。
- 自然景観OCR:中国語と英語をサポートし、LAION やWukong のデータ(各10Mサンプル)にラベル付けされています。

3.4.2 OCR 2.0 data(OCR 2.0データ)
チャート、化学式、平面幾何学といった複雑な人工画像の解析タスクを指します。
- チャートデータ:10M枚の画像がレンダリングされ、解析タスクは画像をHTMLテーブルに変換することとして定義されます。HTML形式を採用することでトークン数を削減しています。
- 化学式:PubChemのSMILES形式をRDKitで画像化した5Mの画像-テキストペアを使用します。
- 平面幾何学:図形内の線分間の複雑な相互依存関係を解析するタスクであり、Slow Perception に基づいて1Mの解析データが構築されています。

3.4.3 General vision data(一般視覚データ)
DeepSeek-OCRの一般画像理解能力を保持するために、キャプション、検出、グラウンディングなどのタスクのデータが全体の20%として導入されました。
3.4.4 Text-only data(テキストのみのデータ)
モデルの言語能力を確保するため、全体の10%が社内テキストのみの事前学習データで構成され、すべて8192トークンのシーケンス長で処理されています。
3.5 Training Pipelines(学習パイプライン)
学習は、DeepEncoderの独立学習と、DeepSeek-OCR全体の学習の2段階で構成されています。
3.5.1 Training DeepEncoder(DeepEncoderの学習)
Vary に準拠し、コンパクトな言語モデルと次のトークン予測フレームワークを用いて学習されます。OCR 1.0/2.0データおよびLAIONからの一般データが使用されました。
3.5.2 Training DeepSeek-OCR(DeepSeek-OCRの学習)
DeepEncoderが準備された後、DeepSeek-OCR全体の学習が行われます。
- 並列化:パイプライン並列性(PP)を用い、モデル全体を4つの部分に分割しています。DeepEncoderのSAM/コンプレッサ部分は凍結(PP0)、CLIP部分は非凍結(PP1)として扱われ、DeepSeek3B-MoEデコーダの12層はPP2とPP3に分けられました。
- 学習環境:20ノード(各ノード8 A100-40G GPU)を使用し、データ並列性(DP)40、グローバルバッチサイズ640で実施されました。高い学習速度を達成しています。
4 Evaluation(評価)
4.1 Vision-text Compression Study(視覚-テキスト圧縮研究)
Foxベンチマークの英語文書(600〜1300トークン)を用いて、Tinyモード(64視覚トークン)とSmallモード(100視覚トークン)での圧縮・展開能力が検証されました。
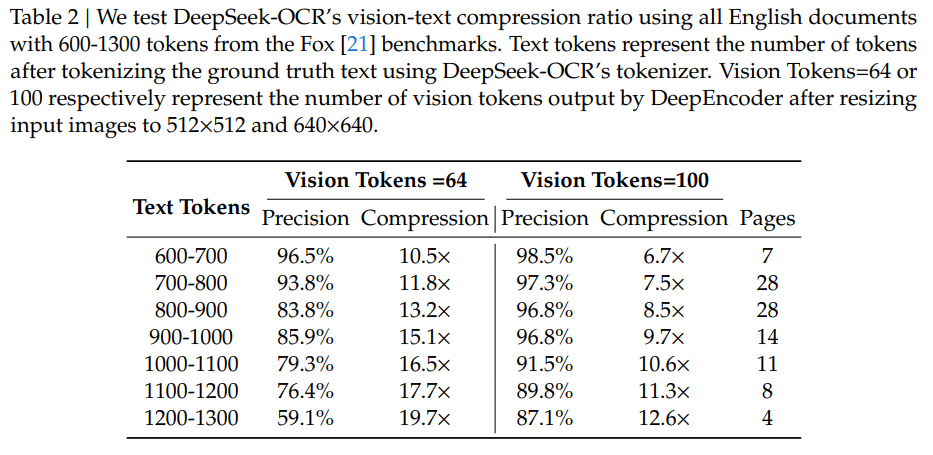
結果は、圧縮率10倍以内(テキストトークンが視覚トークンの10倍以内)の場合、デコーディング精度が約97%に達するという、非常に有望なものでした。これは、将来的にロスレスに近い圧縮(10倍)が実現する可能性を示唆しています。
さらに、圧縮率が約20倍に達しても、OCR精度は約60%を維持しました。これは、光学的コンテキスト圧縮が、VLMインフラストラクチャを利用できるためオーバーヘッドなしに、長文コンテキスト処理の課題に取り組む有望な方向性であることを示しています。
4.2 OCR Practical Performance(OCR実用性能)
OmniDocBench を用いた実用性能評価では、DeepSeek-OCRは驚異的な効率を示しました。
- DeepSeek-OCR (Smallモード、100視覚トークン) は、256トークンを使用するGOT-OCR2.0を上回ります。
- 800トークン未満(Gundamモード)を使用することで、平均約7,000視覚トークンを必要とするMinerU2.0を上回る性能を発揮しました。
文書の種類による分析(Table 4)からは、スライドや書籍、レポートなど(テキストトークンが1,000未満、圧縮率10倍以内)では64〜100視覚トークンで十分な性能が得られる一方で、新聞(テキストトークンが4,000〜5,000)のような高密度の文書では、GundamモードやGundam-masterモード(より多くのトークン)が必要となることが示されました。これは、光学的コンテキスト圧縮の限界と、VLMにおける視覚トークン最適化の研究に有効な指針を与えるものです。
4.3 Qualitative Study(定性研究)
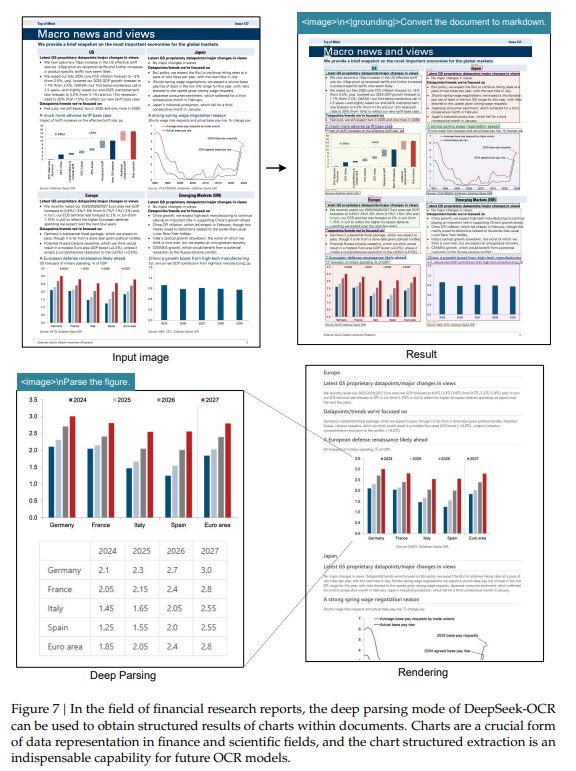
4.3.1 Deep parsing(深層解析)
DeepSeek-OCRは、文書内のチャート、化学式、幾何学図形、自然画像などを、統一されたプロンプトのみでさらに解析する「深層解析」能力を持っています。これにより、金融レポートのチャートからの構造化データの抽出(Figure 7)や、化学式のSMILES形式への変換(Figure 9)など、高度な処理が可能です。



4.3.2 Multilingual recognition(多言語認識)
インターネットから収集されたPDFデータに基づき、約100言語のOCR能力を学習しており、多言語文書に対してもレイアウトあり・なしの両方のOCR形式をサポートできます。

4.3.3 General vision understanding(一般視覚理解)
DeepSeek-OCRは、画像記述、物体検出、グラウンディング(画像内の特定の対象とテキストを結びつける能力)といった一定の一般画像理解能力も保持しています。また、テキストのみのデータを含むことで、言語能力も維持されています。

5 Discussion(考察)
本研究は、視覚-テキスト圧縮の限界を初期的に探求するものであり、約10倍圧縮でのほぼロスレスなOCR精度と、20倍圧縮での60%の精度維持という結果は、今後の研究に期待がもてるものといえます。
特に、この手法は、マルチターン会話において古い対話履歴を画像化して圧縮処理することで、10倍の圧縮効率を実現するなど、将来の応用において大きな可能性を秘めています。
さらに、古いコンテキストを処理する際、レンダリングされた画像を徐々に縮小することでトークン消費を抑える手法が提案されています。これは、時間の経過とともに記憶が薄れるという人間の忘却メカニズムに触発されたもので、最新の情報は高解像度(高忠実度)を保ち、遠い記憶は圧縮率の増加(ぼやけ)を通じて自然に薄れていくという、生物学的な記憶減衰をモデル化できます(Figure 13)。
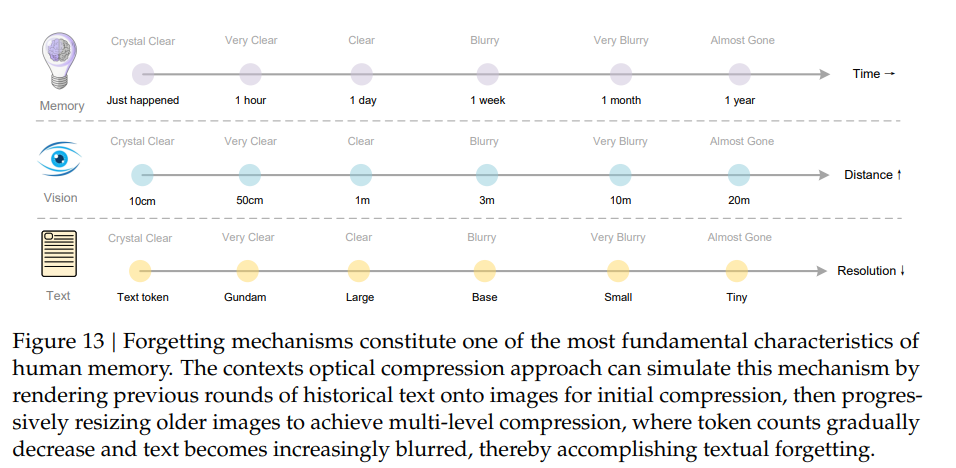
本アプローチは、計算制約と情報保持のバランスを取りながら、理論上無制限のコンテキストアーキテクチャへの道筋を示唆しており、今後の研究が期待される分野です。
まとめ
本稿でご紹介したDeepSeek-OCRは、視覚モダリティを効率的な圧縮媒体として活用するコンテキスト光学的圧縮の実現可能性を検証しました。視覚トークン数の10倍を超えるテキストトークンを効果的にデコードできるという発見は、将来のVLMやLLMの開発を大きく促進するものです。
DeepSeek-OCRは、高い圧縮効率と最先端のOCR性能を両立した実用的なモデルであり、LLM/VLMの事前学習データ生成においても不可欠なアシスタントとしての価値があります。
今後は、真のコンテキスト光学的圧縮をさらに検証するために、デジタル-光学テキストを織り交ぜた学習や、特定の情報が長大な文脈の中で見つけられるかをテストするニードル・イン・ア・ヘイスタックテストなどが予定されています。光学的コンテキスト圧縮は、LLMの長文処理の限界を打ち破る、有望な新しい研究分野として注目されています。








