はじめに
近年、大規模言語モデル(LLM)は目覚ましい発展を遂げ、様々な分野での応用が期待されています。医療分野も例外ではなく、質問応答システムなどを通じて、診断支援や医療情報へのアクセス向上に貢献する可能性が示されています。特に、医療資源が限られる地域においては、LLMが貴重な意思決定支援ツールとなることが期待されます。
しかし、既存の医療ベンチマークテストで高い性能を示したLLMであっても、特定の地域や疾患、文化的な背景が異なる状況で、その性能が維持されるかは未知数でした。特に、熱帯病や感染症(TRINDs)のように、特定の地域に偏在し、多様な背景を持つ疾患群に対して、LLMがどの程度有効なのかは十分に検証されていませんでした。
本稿では、Google Researchが発表した、この課題に取り組むための研究を紹介します。この研究では、TRINDsに特化したデータセットと評価手法を開発し、LLMの性能を評価・最適化する方法を探っています。
引用元記事
- タイトル: Benchmarking LLMs for global health
- 発行元: Google Research
- 発行日: 2025年4月30日
- URL: https://research.google/blog/benchmarking-llms-for-global-health/
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
本稿で紹介する研究の要点は以下の通りです。
- 課題: LLMは一般的な医療ベンチマークでは高性能だが、熱帯病・感染症(TRINDs)のような特定の疾患群や地域、文化に特化した状況での性能(分布シフトへの対応力)は未知数であった。
- アプローチ: TRINDsに関する11,000以上の合成ペルソナ(患者のプロフィールや状況を模擬したデータ)を含むデータセットと評価手法を開発。これにより、様々な文脈(症状、場所、言語、人口統計学的情報など)でのLLMの性能を評価。
- 主な発見:
- LLM(Gemini 1.5)は、TRINDsデータセットにおいて、米国の医師国家試験(USMLE)ベースのベンチマークよりも低い正答率を示した。
- 診断精度には、症状だけでなく場所やリスク要因といった文脈情報が重要である。
- 人種や性別による顕著な性能差は見られなかった。
- 人間の専門家(単独)よりもLLMの方が高い性能を示したが、専門家集団(全員の知見を集約した場合)には及ばなかった。
- インコンテキスト学習(少数の事例をプロンプトに含める手法)により、LLMの性能は大幅に改善可能である。
- 意義: LLMは資源の限られた環境での意思決定支援ツールとして有望だが、正確性、文脈依存性、文化的な適切性について慎重な評価と継続的な改善が必要である。
詳細解説
LLMとグローバルヘルスにおける課題:分布シフト
LLMは、大量のテキストデータを学習することで、人間のような自然な文章を生成したり、質問に答えたりする能力を獲得します。医療分野では、症状を入力すると考えられる病名を提示する、といった応用が研究されています。実際に、米国の医師国家試験(USMLE)のような標準的なテストでは、LLMが高いスコアを出すことが報告されています。
しかし、これらのテストは、主に特定の地域(例えば米国)の医療知識や状況を反映している場合があります。一方で、熱帯病や感染症(TRINDs)は、世界の貧しい地域で流行し、世界で17億人もの人々に影響を与えています。これらの地域では、特有の病気が存在し、症状の現れ方や重視されるべきリスク要因、あるいは文化的な背景も異なります。
このように、学習データ(主に先進国の医療情報)と実際に適用したい状況(TRINDsが蔓延する地域)との間にデータの分布のずれ(分布シフト)があると、LLMの性能が低下する可能性があります。例えば、マラリアがほとんど発生しない地域で学習したLLMは、マラリア流行地域特有の症状やリスク要因を正しく解釈できないかもしれません。この研究は、まさにこの「分布シフト」の問題に焦点を当てています。
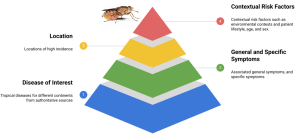
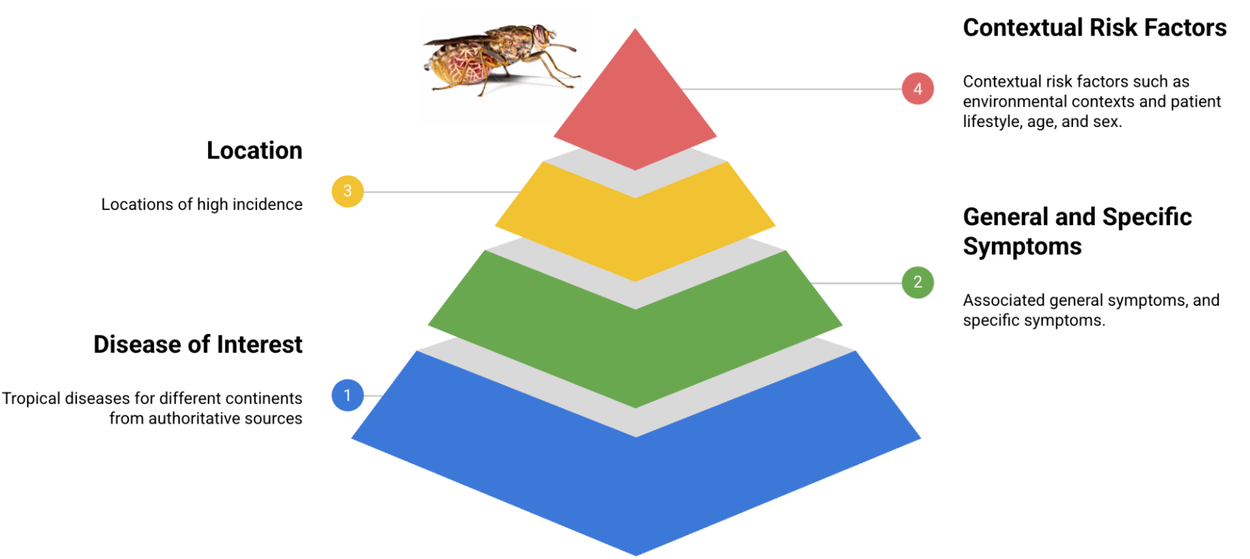
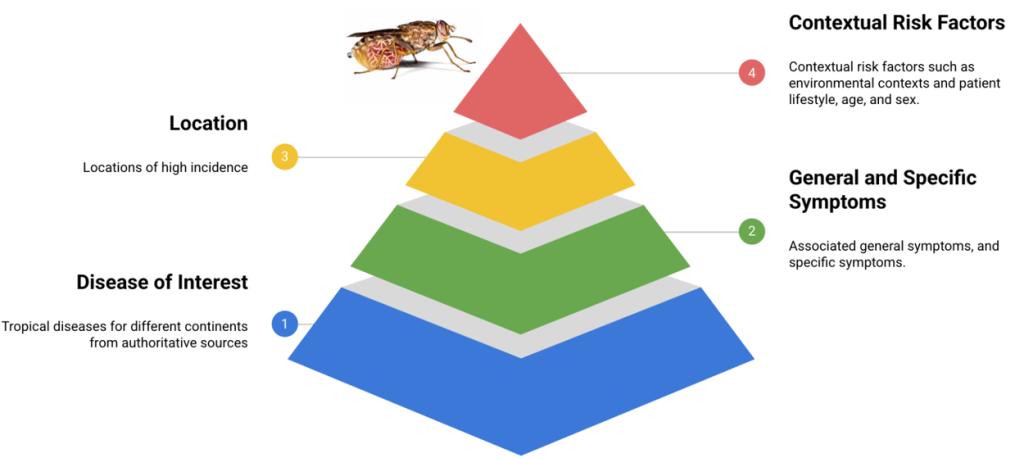
TRINDsデータセットと評価手法の開発
この課題に対処するため、研究チームはTRINDsに特化した評価基盤を開発しました。
- 合成ペルソナの作成: WHO(世界保健機関)などの信頼できる情報源に基づき、まず50種類のTRINDsについて、基本的な患者像(シードペルソナ)を作成しました。これには、一般的な症状、特定の症状、患者の背景(生活習慣、リスク要因など)が含まれます。これらのペルソナは、臨床医によって内容の正確性や妥当性が確認されています。
- LLMによる拡張: 作成したシードペルソナを基に、LLMのプロンプト技術(指示を与えること)を活用して、人口統計学的情報(年齢、人種、性別など)や意味的な多様性(臨床的な表現と一般的な表現の違いなど)を付加し、ペルソナを11,000以上に拡張しました。これにより、より多様な状況をシミュレートできます。さらに、一部はフランス語にも翻訳され、言語の違いによる影響も評価できるようにしました。
- 評価方法: 作成したペルソナを入力としてLLM(この研究ではGemini 1.5)に与え、提示された診断結果が正解と一致するか、または意味的に類似しているかを自動で評価するシステム(LLMベースの自動評価器)も開発しました。
LLMの性能評価結果
開発したTRINDsデータセットを用いて、LLM(Gemini 1.5)の性能を様々な角度から評価しました。
- USMLEとの比較: Gemini 1.5は、TRINDsデータセットでは、USMLEベースのデータセットで報告されている性能よりも低い正答率を示しました。これは、前述の分布シフトが実際にLLMの性能に影響を与えることを示唆しています。
- 文脈情報の重要性: 症状だけを与える場合よりも、場所(Location)やリスク要因(Risk factors)といった文脈情報を合わせて与えた場合に、LLMの診断精度が最も高くなりました。これは、特にTRINDsのような地域性の高い疾患においては、症状以外の情報がいかに重要かを示しています。
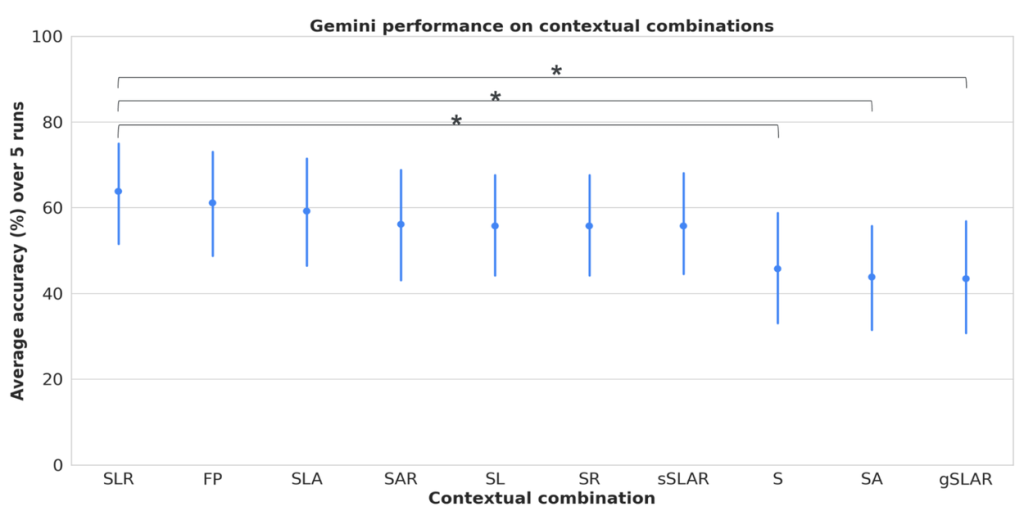
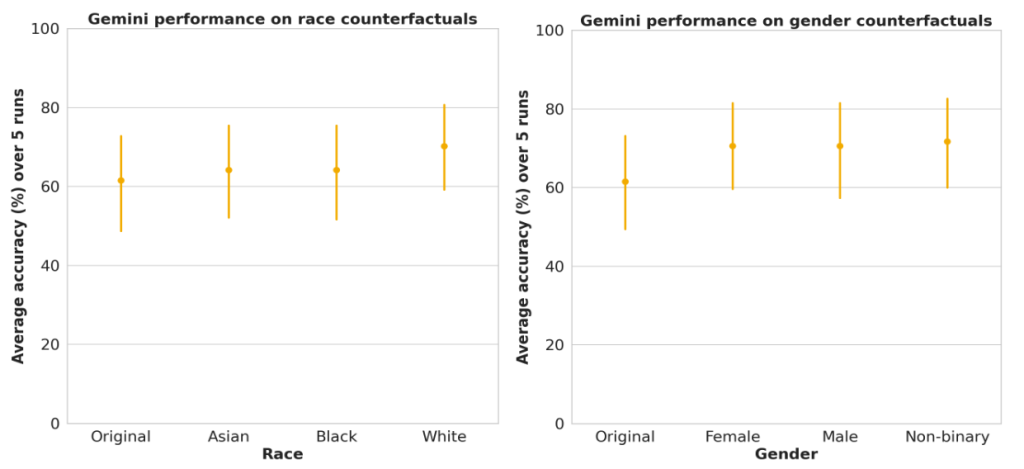
- 人種・性別の影響: ペルソナに人種(例:「私は黒人です」)や性別(女性、男性、ノンバイナリー)を明示的に含めて評価しましたが、統計的に有意な性能差は見られませんでした。ただし、これは今回のデータセットと評価方法における結果であり、あらゆる状況でバイアスがないことを保証するものではありません。
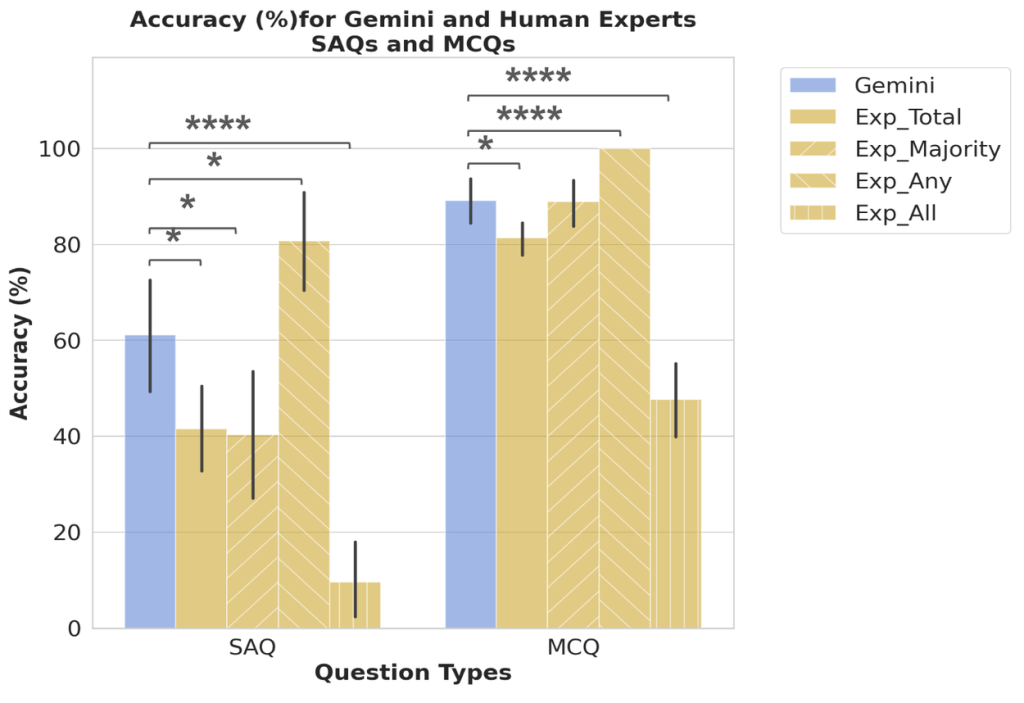
- 専門家との比較: TRINDsと公衆衛生分野で10年以上の経験を持つ7人の専門家にも同じタスク(ペルソナに基づく診断)を行ってもらいました。LLMは、個々の専門家の平均的な性能や、最も成績の良い専門家よりも高い正答率を示しました。しかし、専門家全員が正解した場合のみ正解とするような、専門家集団の総合的な判断力(Exp_Anyシナリオ:誰か一人でも正解すればOK)には及びませんでした。これは、LLMが個人の能力を超える可能性を示唆する一方で、複数の専門家の知見を集約した判断にはまだ及ばないことを示しています。
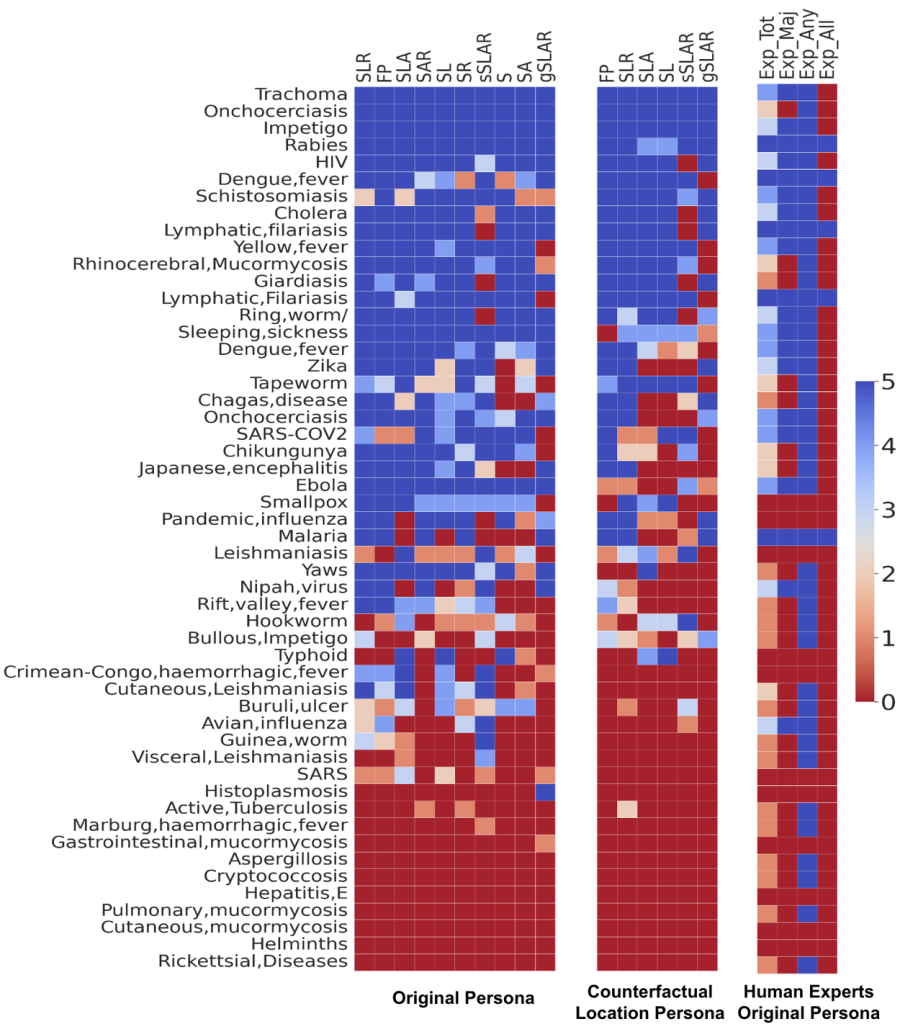
- 疾患ごとの性能差: HIVのように一般的な疾患や、狂犬病のように特異的な症状やリスク要因を持つ疾患は、LLMが比較的正確に特定できる傾向がありました。一方で、症状だけでは特定が難しい疾患(例:条虫感染症)もありました。
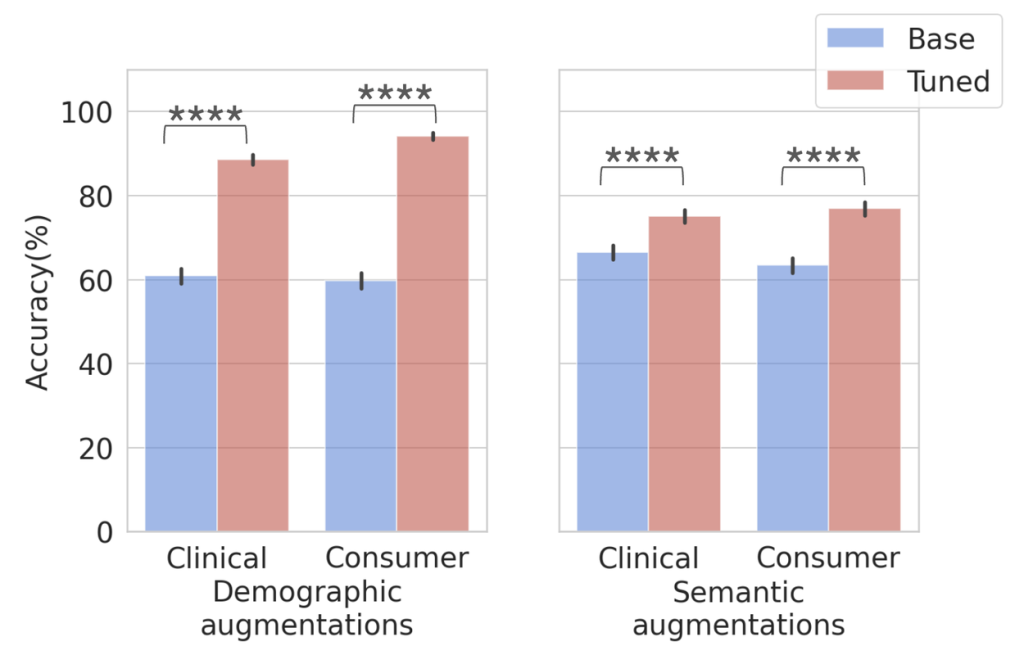
- 性能改善(インコンテキスト学習): 驚くべきことに、シードペルソナ(50疾患×1セット)をインコンテキスト学習(プロンプトにいくつかの正解例を含めてLLMに提示する手法)に用いるだけで、LLMの性能が大幅に向上しました。これは、比較的少量のターゲットデータであっても、LLMを特定のタスクに合わせてチューニング(調整)することの有効性を示しています。
疾患スクリーニングツールへの応用可能性
研究チームは、この研究成果を基に、TRINDsのスクリーニングを支援するユーザーインターフェースのプロトタイプも開発しました。ユーザーが自身の人口統計情報、場所、生活習慣、リスク要因を入力し、症状リストから該当するものを選ぶと、調整されたGeminiモデルが考えられる診断結果を提示するというものです。専門家による初期評価では、シンプルながらも臨床医や研究者にとってインパクトのある有用な参照ツールになる可能性が示唆されています。
まとめ
本稿で紹介したGoogle Researchの研究は、LLMをグローバルヘルス、特に熱帯病や感染症(TRINDs)の分野で活用する上での重要な示唆を与えています。
LLMは、標準的な医療ベンチマークでは高い性能を発揮しますが、TRINDsのような特定の状況(分布シフト)においては性能が低下する可能性があること、そして診断精度には症状だけでなく場所やリスク要因といった文脈情報が不可欠であることが明らかになりました。
一方で、インコンテキスト学習のような手法でLLMを適切に調整すれば、性能を大幅に改善できることも示されました。これは、LLMが資源の限られた地域における意思決定支援ツールとして大きな可能性を秘めていることを示唆します。
しかし、医療という人命に関わる分野でLLMを利用するには、性能の継続的な評価、現実世界の状況変化への対応、多様な臨床現場での信頼性担保が不可欠です。LLMは臨床判断を補完するものであり、それに取って代わるものではありません。本研究で示されたアプローチを実際の臨床ツールとして展開するには、さらなる検証と規制当局による標準的な審査プロセスが必要です。 今後は、多言語対応や、画像など他の情報(モダリティ)も組み合わせた評価(マルチモダリティ)へと研究が拡張されることが期待されます。LLM技術の慎重かつ適切な応用が、グローバルヘルスの課題解決に貢献する未来が近づいています。