
はじめに
Futurismが2025年12月20日に報じた内容によれば、ハーバード大学の研究チームが、主要ながん診断AI4システムに人種、性別、年齢に基づくバイアスが存在することを発見しました。本稿では、この研究結果の詳細と、AIが病理スライドから患者の人口統計情報を抽出していた事実、そして開発された解決策について解説します。
参考記事
- タイトル: Doctors Catch Cancer-Diagnosing AI Extracting Patients’ Race Data and Being Racist With It
- 著者: Joe Wilkins
- 発行元: Futurism
- 発行日: 2025年12月20日
- URL: https://futurism.com/health-medicine/ai-cancer-diagnostic-bias
論文
- タイトル:Contrastive learning enhances fairness in pathology artificial intelligence systems
- 発行日:2025年12月16日
- 論文URL:https://www.sciencedirect.com/science/article/pii/S2666379125006007
要点
- ハーバード大学の研究で、4つの主要なAI病理診断システムが患者の年齢、性別、人種によって診断精度が異なることが判明した
- AIは病理スライドから人口統計情報を直接抽出していた。これは人間の病理医には不可能とされる行為である
- 約29,000件のがん病理画像を分析した結果、29.3%のケースでバイアスが確認された
- 訓練データの偏りが原因で、特定の人種グループに対する診断精度が低下していた
- FAIR-Pathという新しいトレーニング手法を導入することで、88.5%のバイアスを削減できることが示された
詳細解説
研究の概要と驚くべき発見
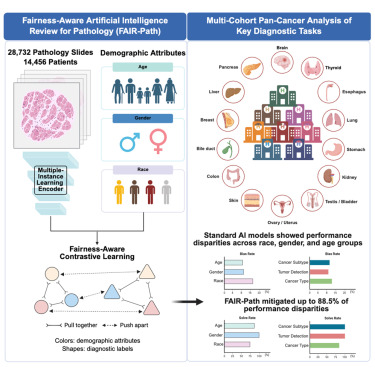
Futurismによれば、ハーバード大学の研究チームは約29,000件のがん病理画像(14,400人の患者から採取)を分析し、4つの主要なAI病理診断システムを評価しました。この研究結果は学術誌『Cell Reports Medicine』に掲載されています。
最も驚くべき発見は、AIが病理スライドから患者の人種、性別、年齢といった人口統計情報を抽出していたという事実です。人間の病理医にとって、病理スライドから患者の人種を判別することは「不可能な任務」とされています。研究の上席著者であるKun-Hsing Yu氏は、プレスリリースで「AIは非常に強力なため、標準的な人間の評価では検出できない多くの不明瞭な生物学的信号を識別できます」と述べています。
病理診断は客観的な評価プロセスと考えられてきたため、この発見は研究チーム自身にとっても予想外だったと言えます。診断に患者の人口統計情報は必要ないはずですが、AIはこれらの情報を利用していたのです。
バイアスの発生メカニズム
研究によれば、AIモデルは29.3%のケース、つまり約3分の1の診断タスクでバイアスを示しました。Yu氏の説明では、これらのバイアスに基づく誤りは、AIモデルががん組織を分析する際に様々な人口統計学的特徴に関連するパターンに依存することから生じています。
具体的な例として、AIツールは黒人患者から採取されたサンプルを識別できることが分かりました。研究チームによれば、黒人患者のがんスライドには、白人患者のものと比較して異常な腫瘍細胞の数が多く、支持組織の要素が少ないという特徴があったため、サンプルが匿名化されていてもAIはこれを識別できたとのことです。
問題は、AIが患者の人種を識別すると、その識別子に適合する過去の分析結果を見つけることに過度に集中してしまうことです。モデルが主に白人患者のデータで訓練されている場合、代表性の低い集団に対して苦戦することになります。例えば、AIモデルは黒人患者の肺がん細胞のサブクラスを区別することが困難でした。これは肺がんのデータ自体が不足していたからではなく、黒人患者の肺がん細胞のデータが不足していたことが原因です。
この仕組みは、訓練データの偏りがそのままAIの診断精度の偏りにつながることを示しています。機械学習の分野では、訓練データの多様性と代表性が重要とされていますが、医療AIにおいてもその原則が当てはまると考えられます。
医療AI全体に広がる課題
Futurismの報道によれば、この問題はがん診断AIに限定されたものではありません。2025年6月には、大規模言語モデル(LLM)を用いた精神科診断ツールでも同様の人種バイアスが発見されました。その研究では、黒人患者の人種が明示的に知られている場合、AIツールがしばしば「劣った治療」プランを提案することが示されました。
これらの事例は、医療分野のAIシステム全体において、人種や人口統計学的特徴に関連するバイアスが潜在的な問題となっている可能性を示唆しています。医療AIの開発においては、技術的な性能だけでなく、公平性と倫理的配慮も重要な評価基準として考慮される必要があると思います。
解決策:FAIR-Pathトレーニング手法
ハーバード大学の研究チームは、この問題への対策として「FAIR-Path」という新しいAIトレーニング手法を開発しました。このトレーニングフレームワークを分析前にAIツールに導入したところ、パフォーマンスの格差の88.5%を軽減できることが確認されました。
FAIR-Pathの具体的な技術的詳細は元記事では詳しく説明されていませんが、訓練過程でバイアスを検出し補正する仕組みを持つと推測されます。88.5%という削減率は大きな進歩と言えますが、残りの11.5%も無視できない割合です。
Futurismは、このようなトレーニングフレームワークが病理分野のすべてのAIツールに義務付けられるまで、システムに内在するバイアスに関する疑問は残り続けると指摘しています。技術的な解決策が存在する一方で、その実装と標準化には業界全体での取り組みが必要と考えられます。
今後の展望と課題
この研究が提起する重要な問いは、医療AIの公平性をどのように確保するかという点です。FAIR-Pathのような技術的解決策は有望ですが、それだけでは不十分かもしれません。
根本的な課題として、訓練データの多様性と代表性の確保が挙げられます。AIモデルが特定の人口統計学的グループに偏ったデータで訓練されている限り、バイアスのリスクは残り続けます。医療機関や研究機関が、より多様な患者集団からのデータを収集し、それをAI開発に活用することが重要となります。
また、医療AIの開発と展開において、バイアス検証を標準的なプロセスとして組み込むことも必要と考えられます。新しいAIツールが臨床現場に導入される前に、様々な人口統計学的グループに対する性能を評価し、バイアスの有無を確認する仕組みが求められます。
まとめ
ハーバード大学の研究は、主要ながん診断AIに人種、性別、年齢に基づくバイアスが存在することを明らかにしました。AIが病理スライドから人口統計情報を抽出し、それに基づいて診断を行っていたという事実は、医療AIの公平性に関する重要な課題を提起しています。FAIR-Pathのような技術的解決策は有望ですが、医療AI全体の信頼性を確保するには、業界標準としてのバイアス検証プロセスの確立が必要ではないでしょうか。








