
はじめに
Google DeepMindが2025年12月9日、大規模言語モデル(LLM)の事実性を体系的に評価するための「FACTS Benchmark Suite」をKaggleと共同で公開しました。本稿では、この発表内容をもとに、4つのベンチマークの詳細と評価結果、LLMの事実性における現状と課題について解説します。
参考記事
- タイトル: FACTS Benchmark Suite: Systematically evaluating the factuality of large language models
- 著者: The FACTS team
- 発行元: Google DeepMind
- 発行日: 2025年12月9日
- URL: https://deepmind.google/blog/facts-benchmark-suite-systematically-evaluating-the-factuality-of-large-language-models/
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- FACTS Benchmark Suiteは、LLMの事実性を評価するための4つのベンチマーク(Parametric、Search、Multimodal、Grounding v2)から構成される総合評価スイートである
- 合計3,513の評価例が公開され、Kaggleが非公開の評価セットを管理し、主要LLMの評価結果を公開リーダーボードでホストする
- Gemini 3 Proが総合FACTSスコア68.8%で首位を獲得したが、全評価モデルが70%未満の精度にとどまり、改善の余地が大きいことが示された
- SearchベンチマークとParametricベンチマークでは、Gemini 2.5 ProからGemini 3 Proへの進化でエラー率がそれぞれ55%、35%削減された
- Multimodalベンチマークは全体的に最も低いスコアとなり、視覚情報と言語情報を統合した事実性の確保が特に困難であることが明らかになった
詳細解説
FACTS Benchmark Suiteの構成
FACTS Benchmark Suiteは、以前発表されたFACTS Grounding Benchmarkを拡張したもので、LLMの事実性を多角的に評価するための4つのベンチマークで構成されています。
Google DeepMindによれば、合計3,513の評価例が公開され、Kaggleが非公開の評価セット(held-out set)を管理する体制が整えられました。最終的なFACTSスコアは、4つのベンチマーク全体における公開セットと非公開セットの平均精度として算出されます。
この評価体制は、業界標準のプラクティスに従っており、モデルの汎化性能を適切に測定できる仕組みと言えます。評価の詳細な方法論については、技術レポートで公開されています。
Parametric Benchmark:内部知識の正確性を測定
Parametric Benchmarkは、ウェブ検索などの外部ツールを使わずに、モデルが内部知識のみで事実に基づく質問に正確に回答できるかを評価します。
ベンチマークの質問はすべて「トリビアスタイル」の形式で、ユーザーの関心に基づいてWikipedia経由で回答可能な内容です。公開セット1,052項目、非公開セット1,052項目で構成されています。
例えば、公開セットからの典型的な質問として「『ロックフォード・ファイル』のテーマソングでハーモニカを演奏したのは誰か?」といったニッチなトピックに関する単純な質問が含まれます。
このベンチマークは、LLMが事前学習で獲得した知識をどれだけ正確に引き出せるかを測定する指標となります。一般的に、LLMは膨大なテキストデータから学習するため、その知識の正確性と想起能力が実用上の重要な要素と考えられます。
Search Benchmark:複雑な情報検索と統合能力を評価
Search Benchmarkは、モデルがウェブ検索ツールを使用して質問に答える能力を評価します。このベンチマークは、ウェブアクセスがあってもLLMにとって困難になるよう設計されており、単一のクエリに答えるために複数の事実を順次取得する必要がある質問が多く含まれます。
公開セット890項目、非公開セット994項目で構成され、すべてのモデルに同じウェブ検索ツールが提供されることで、カスタム設定の違いによる影響を排除し、モデル能力そのものを評価できます。
Google DeepMindの説明では、公開セットからの例として「1960年夏季オリンピックでVazik Kazarianを破ったイギリスのボクサー、同じオリンピックの男子ライトウェルター級に出場したモロッコのボクサー、1960年と1964年の両オリンピックに出場したデンマークのボクサーの生年の合計は?」といった、複数のウェブページから情報を取得する必要がある質問が含まれています。
このような複雑な情報統合タスクは、実際のビジネス場面でも頻繁に発生する可能性があり、実用的な評価指標として重要だと思います。
Multimodal Benchmark:視覚情報と言語の統合
Multimodal Benchmarkは、画像ベースの質問に対して事実的に正確なテキストを生成するモデルの能力を評価します。これは現代のマルチモーダルシステムにとって重要な機能です。
このタスクでは、視覚的グラウンディング(視覚入力からの情報を正確に解釈・接続する能力)と、モデルの内部知識を統合する必要があります。評価フレームワークは、回答が正確であるだけでなく、完全に必要な情報を提供しているかも確認します。公開セット711項目、非公開セット811項目で構成されています。
例えば、公開セットからの画像として、緑の葉の上に休んでいる小さな茶色の蛾の写真が示され、「この動物はどの属に属しますか?」という質問が付随します。
視覚情報と言語情報の統合は、技術的に高度な処理が必要とされる領域です。画像認識の精度だけでなく、認識した対象に関する正確な知識の想起も同時に求められるためです。
Grounding Benchmark v2:文脈に基づく回答生成
元のFACTS Grounding Benchmarkを拡張したGrounding Benchmark v2は、与えられたプロンプトの文脈に基づいて回答を提供するモデルの能力をテストします。
このベンチマークは、提供された情報を適切に活用し、その範囲内で正確な回答を生成できるかを評価します。実際の業務では、特定の文書や資料に基づいて質問に答える場面が多く、この能力は実用上極めて重要と考えられます。
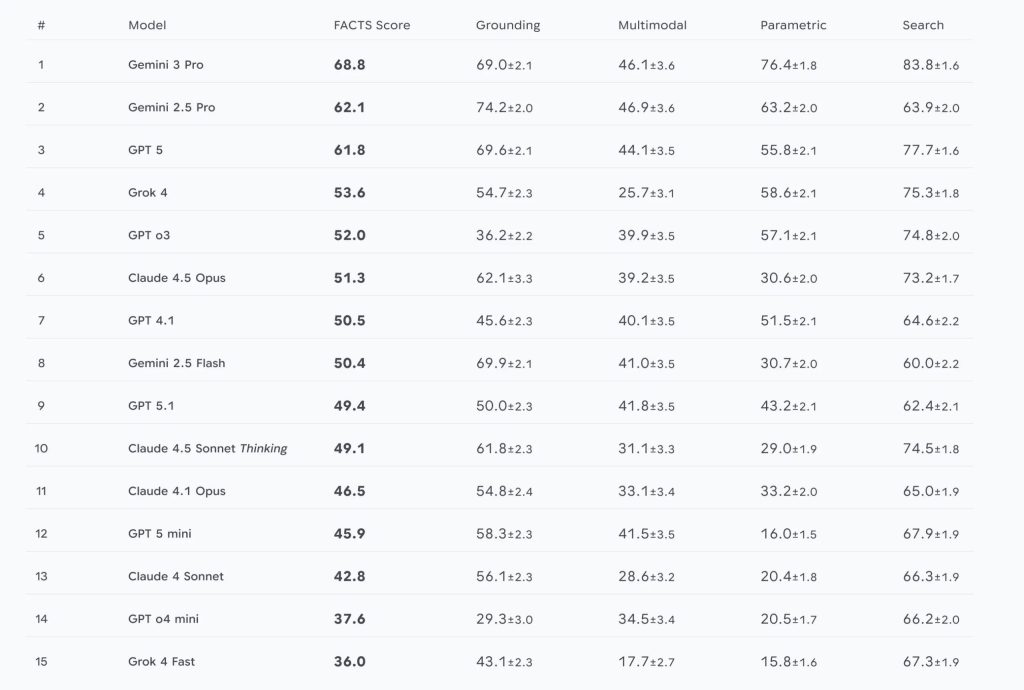
評価結果:Gemini 3 Proが首位も、改善の余地は大きい
Google DeepMindは15の主要LLMを評価し、Gemini 3 Proが総合FACTSスコア68.8%で首位となりました。特にSearchベンチマークとParametricベンチマークで大きな改善が見られ、Gemini 2.5 ProからGemini 3 Proへの進化でエラー率がそれぞれ55%と35%削減されたとのことです。
一方、Multimodalベンチマークは全体的に最も低いスコアとなり、すべての評価モデルが70%未満の総合精度にとどまりました。これは、今後の進歩に向けて大きな余地が残されていることを示しています。
なお、別の事実性ベンチマークであるSimpleQA Verifiedでも、Gemini 2.5 Proの54.5%からGemini 3 Proの72.1%へと精度が向上しました。SimpleQA Verifiedは、短文回答におけるLLMの知識を評価するベンチマークです。
業界全体として70%という精度水準は、現時点でのLLMの事実性における課題を明確に示していると言えます。特にマルチモーダルタスクでの低い精度は、視覚と言語の統合がまだ発展途上の技術であることを示唆しています。
まとめ
FACTS Benchmark Suiteは、LLMの事実性を4つの観点から体系的に評価する包括的なフレームワークです。Gemini 3 Proが68.8%のスコアで首位となったものの、全モデルが70%未満にとどまり、特にマルチモーダルタスクでの課題が浮き彫りになりました。今後、このベンチマークを通じてLLMの事実性に関する研究が深まり、より正確で信頼性の高いモデルが開発されることが期待されます。








