
はじめに
LLMをサービスとして提供する(サービングと呼びます)には、高性能なGPUが大量に必要となり、その運用コストは非常に高額となっています。 従来型の検索クエリと比べて、LLMのリクエスト処理は10倍もコストがかかるという試算もあるほどです。この高いコストを抑え、より多くのユーザーにサービスを提供するためには、サービングシステムのスループット(単位時間あたりに処理できるリクエスト数)をいかに向上させるかが重要になります。 LLMのスループット向上において、現在大きなボトルネックとなっているのが、GPUメモリの効率的な管理です。
2023年に発表された論文「Efficient Memory Management for Large Language Model Serving with PagedAttention」について解説します。メモリ管理の課題に挑み、大きな成果を上げたvLLMというシステムと、それを支えるPagedAttentionという新しいアテンションアルゴリズムについて詳しく解説しています。
引用元記事
- タイトル: Efficient Memory Management for Large Language Model Serving with PagedAttention
- 発行元: arXiv
- 発行日: 2023年9月12日
- URL: https://arxiv.org/abs/2309.06180
論文の要点
- 既存のLLMサービングシステムでは、Transformerモデルがトークンを順番に生成する際に使用する「KVキャッシュ」というデータが、GPUメモリを大量に消費する。 このKVキャッシュのメモリ管理が非効率なため、一度にバッチ処理できるリクエスト数に制限があり、スループットが低くなっていた。
- 非効率の原因は、KVキャッシュのサイズがリクエストごとに動的に変化し、また事前に正確な長さを予測できないにも関わらず、既存システムでは連続したメモリ領域にまとめて確保しようとするため。 これにより、「断片化」というメモリの無駄や、複数のリクエスト間でのメモリ共有が困難になるという問題が発生している。
- この問題を解決するため、論文ではオペレーティングシステム(OS)の「仮想記憶」と「ページング」という古典的なメモリ管理技術にインスパイアされた、PagedAttentionという新しいアテンションアルゴリズムを提案。 PagedAttentionは、KVキャッシュを固定サイズの小さなブロックに分割し、物理メモリ上の非連続な場所に配置することを可能にする。
- PagedAttentionを基盤として構築されたvLLMというLLMサービングシステムは、KVキャッシュメモリの無駄をほぼゼロに削減し、さらにリクエスト内やリクエスト間での柔軟なKVキャッシュ共有を可能にした。
- 評価の結果、vLLMは既存の最先端システム(FasterTransformerやOrcaなど)と比較して、同じレイテンシレベルでLLMのスループットを2倍から4倍向上させることが実証された。 特にシーケンス長が長い場合、モデルサイズが大きい場合、複雑なデコーディングアルゴリズムを使用した場合に、その効果は顕著であった。
詳細解説
論文のセクション構成に沿って、内容を詳しく解説します。
1 Introduction (はじめに)
このセクションでは、LLMの登場とその社会的影響から始まり、それらをサービスとして提供する際の経済的な課題、特にGPUリソースの高コストが強調されます。 LLMのコアであるTransformerモデルが、トークンを一つずつ生成する「自己回帰的」な性質を持つため、GPUの計算能力を十分に活用できず、メモリがボトルネックになりやすいことが指摘されています。
スループット向上のための一般的な手法として、複数のリクエストをまとめて処理する「バッチ処理」が挙げられますが、そのためには各リクエストに必要なメモリ空間を効率的に管理する必要があります。 特に、Transformerモデルが過去のトークンの情報を保持するために使う「KVキャッシュ」(KeyとValueというベクトルのペア)が、リクエストごとにサイズが大きく、動的に変化するため、その管理がGPUメモリ容量を制限し、バッチサイズを制限する最大の要因となっています。
既存のLLMサービングシステムは、KVキャッシュを連続したメモリ空間に確保しようとするため、動的かつ予測不能なサイズのKVキャッシュを効率的に扱えないことが課題でした。 具体的には、将来生成されるトークン分のメモリをあらかじめ確保しておくことで、内部断片化(確保した領域のうち、実際に使われていない部分の無駄)や、異なるサイズのリクエストが混在することによる外部断片化(空きメモリが小さく分断され、大きな領域を確保できない無駄)が発生します。 また、複数の出力候補を扱うような複雑なデコーディングアルゴリズム(ビームサーチなど)を使う場合、異なる候補間でKVキャッシュの一部を共有できる機会がありますが、連続メモリ空間に格納しているとこれが難しくなります。
これらの問題を解決するため、論文ではOSの仮想記憶とページングの概念を応用したPagedAttentionを提案し、それに基づくvLLMというシステムを開発したことを述べています。 vLLMはKVキャッシュのメモリ無駄を大幅に削減し、メモリ共有を柔軟に行えるようにすることで、既存システムを大きく上回るスループットを達成したとしています。
2 Background (背景)
ここでは、LLMの基本的な動作原理とサービング手法、そしてバッチ処理について説明しています。
2.1 Transformer-Based Large Language Models:
言語モデルは、与えられたトークンの羅列に対して、次のトークンがどのくらいの確率で出現するかをモデル化するタスクです。 言語の性質上、これは一つ前のトークンまでの履歴に基づいて次のトークンを予測する「自己回帰的」な方法が一般的です。 Transformerは、この自己回帰的な確率モデルを大規模に構築するためのデファクトスタンダードなアーキテクチャです。 その中心的な要素である「自己注意層」では、入力トークンからQuery (Q), Key (K), Value (V) という3つのベクトルを計算し、QとKの内積から計算される注意スコアを使ってVの重み付き平均を計算することで、各トークンが他のトークンとどれだけ関連があるかを捉えます。
2.2 LLM Service & Autoregressive Generation:
学習済みのLLMは、ユーザーのプロンプト(入力)を受け取り、その続きを生成するサービスとして提供されます。 この生成プロセスは、プロンプト全体を一度に処理して最初の出力トークンを生成する「プロンプトフェーズ」と、生成されたトークンを一つずつ入力として与え、次のトークンを順次生成していく「自己回帰生成フェーズ」に分かれます。 特に自己回帰生成フェーズでは、新しいトークンを生成するために、それまでに入力および生成された全てのトークンのKとVベクトル(これがKVキャッシュです)が必要になります。 このプロセスは一度に1トークンしか処理できないため、GPUの計算能力を十分に活用できず、KVキャッシュの読み書きがボトルネックとなり、「メモリバウンド」になりやすい性質があります。
2.3 Batching Techniques for LLMs:
LLMサービングのGPU利用率を高めるために、複数のリクエストをまとめてバッチとして処理することが行われます。 同じモデルウェイトを共有することで、そのロードにかかるオーバーヘッドなどを複数のリクエストで分担できるためです。 しかし、LLMのリクエストは到着時間がばらばらで、またプロンプト長や生成される出力長も大きく異なります。 これらを単純にバッチ処理しようとすると、到着が遅いリクエストを待ったり、出力を最大長にパディング(埋める)したりする必要が生じ、大きな待ち時間や計算・メモリの無駄が発生します。 そこで、リクエスト全体ではなく、トークンを生成する各「イテレーション」(反復処理)の単位で細かくバッチ処理を行う手法(iteration-level schedulingなど)が提案されています。 これにより、完了したリクエストをすぐにバッチから外し、新しいリクエストをすぐに追加できるため、待ち時間が削減され、スループットが向上します。
3 Memory Challenges in LLM Serving (LLMサービングにおけるメモリの課題)
細粒度バッチ処理によって計算の無駄や待ち時間は減らせるものの、バッチ処理できるリクエスト数は依然としてGPUメモリ容量、特にKVキャッシュのサイズによって制限されます。 つまり、スループットはメモリによって制限されている状態です。
このセクションでは、LLMサービングにおけるKVキャッシュのメモリ管理の具体的な課題が深掘りされます。
- KVキャッシュが大きいこと: KVキャッシュのサイズはリクエスト数に応じて急速に増加します。例えば、OPT-13Bモデルの場合、1トークンあたりのKVキャッシュが約800KBにもなります。 最大2048トークンを生成できるとすると、1つのリクエストだけで最大1.6GBのメモリが必要です。 最新のGPUでもメモリ容量は数十GB程度であり、KVキャッシュだけでメモリがいっぱいになってしまうため、同時に処理できるリクエスト数は限られます。 GPUの計算能力の進化はメモリ容量の進化よりも速いため、メモリは今後ますます重要なボトルネックになると予想されています。
- 複雑なデコーディングアルゴリズムへの対応: 並列サンプリングやビームサーチといった複雑なデコーディング手法では、同じプロンプトから複数の出力候補が生成されます。 これらの候補は、プロンプト部分や途中の共通部分のKVキャッシュを共有できる可能性があります。 どの部分を共有できるかはアルゴリズムや生成プロセスによって動的に変化するため、これを効率的に管理できる仕組みが必要です。
- 未知の入出力長への対応: ユーザーリクエストのプロンプト長や、生成される出力長は事前に分かりません。 生成が進むにつれてKVキャッシュのサイズは増加し、GPUメモリを使い尽くしてしまう可能性があります。 この場合、システムは一部のリクエストの処理を中断したり(プリエンプション)、KVキャッシュをCPUメモリなどに退避させたり(スワッピング)といった判断を行う必要があります。
3.1 Memory Management in Existing Systems:
既存のシステムでは、TensorFlowやPyTorchのような一般的な深層学習フレームワークの制約から、KVキャッシュはリクエストごとに連続したメモリ領域に確保されていました。 そして、出力長が予測できないため、最大可能なシーケンス長(例えば2048トークン)に基づいて、あらかじめ大きなメモリ領域を静的に割り当てていました。
Figure 3は、この既存システムのメモリ管理における非効率性を分かりやすく示しています。 最大長が異なる2つのリクエスト(Aは2048、Bは512)に対し、それぞれの最大長分のメモリチャンクが確保されています。
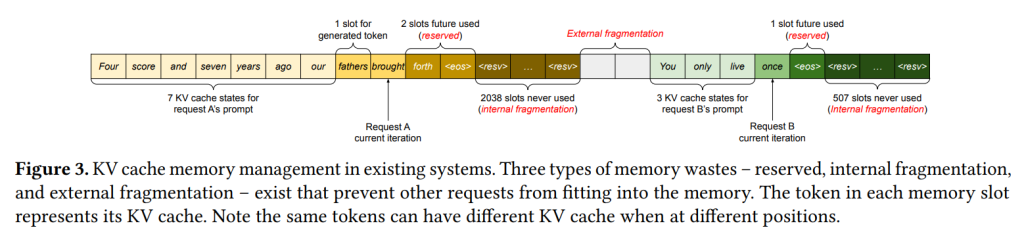
ここには主に3種類のメモリ無駄が生じます。
- Reserved slots (予約スロット): 将来生成されるトークン分のために確保された、まだ使用されていない領域です。 最終的には使用される可能性はありますが、リクエストの処理が終わるまでこの領域を占有し続けるため、他のリクエストがメモリを使えなくなります。
- Internal fragmentation (内部断片化): リクエストの実際の出力長が最大長よりも短かった場合に、確保した領域のうち最終的に全く使用されなかった部分です。 これはリクエスト完了後に無駄だったことが分かります。
- External fragmentation (外部断片化): メモリ確保・解放を繰り返すうちに、空きメモリが小さな塊に分断され、大きなリクエストに必要な連続領域を確保できなくなる無駄です。 これはリクエストを受け付ける前に無駄だと分かります。
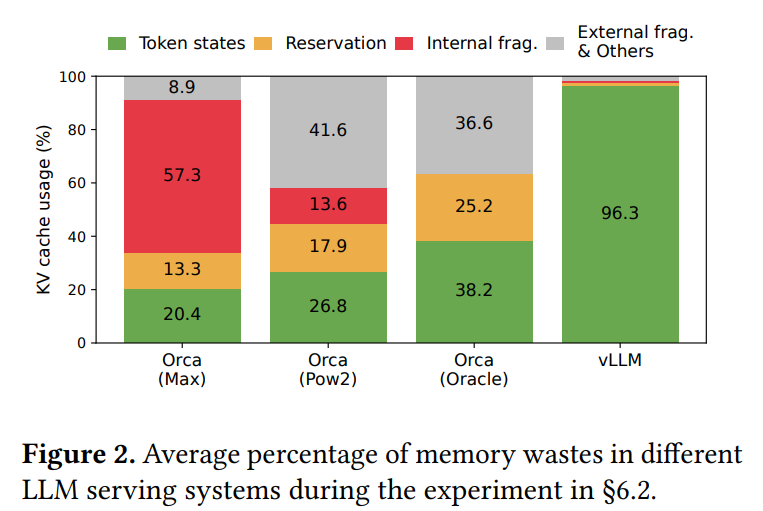
Figure 2のグラフは、実際の既存システムにおけるKVキャッシュメモリの使用効率が、トークン状態の格納に使われているのがわずか20.4%から38.2%に過ぎないことを示しており、残りは予約スロットや断片化による無駄であることを視覚的に表しています。 また、メモリの断片化を解消する「コンパクション」という手法も存在しますが、巨大なKVキャッシュに対してリアルタイム性が求められるLLMサービングシステムで行うのは非現実的だと論文では述べています。 加えて、静的なチャンク確保では、複雑なデコーディングアルゴリズムにおけるメモリ共有も実現できません。
4 Method (手法)
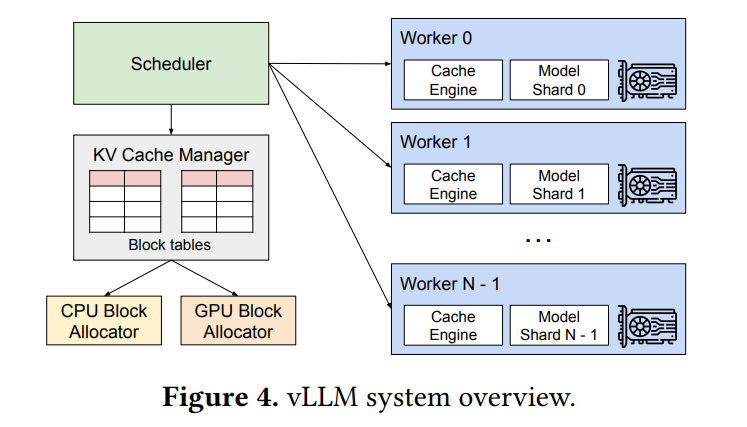
このセクションでは、vLLMとPagedAttentionが、前述のメモリ課題をどのように解決するのか、その詳細な仕組みが解説されています。vLLMのシステム全体の概要は Figure 4 に示されています。 vLLMは、中央集権型のスケジューラが分散配置されたGPUワーカーの実行を調整し、KVキャッシュマネージャがPagedAttentionを用いてKVキャッシュをページング方式で効率的に管理するアーキテクチャを採用しています。
4.1 PagedAttention:
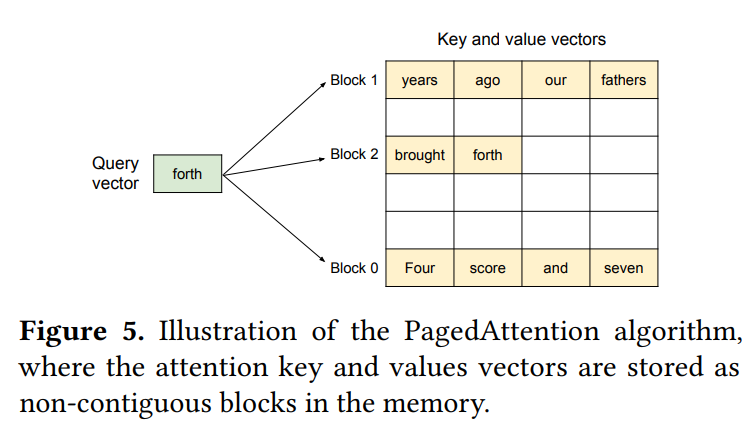
PagedAttentionは、OSのページングのアイデアから生まれました。 従来のアテンションアルゴリズムとは異なり、KVキャッシュを物理メモリ上の連続していない場所に格納することを可能にします。 具体的には、KVキャッシュを固定サイズの「KVブロック」に分割します。 各ブロックは、キーベクトルとバリューベクトルをそれぞれ固定数(ブロックサイズ $B$)のトークン分格納できます。 PagedAttentionのアテンション計算は、このブロック単位で行われます。 Figure 5では、KVキャッシュが非連続な3つのブロックに分かれて格納されている様子が描かれています。 アテンション計算時には、クエリトークンのQベクトルと、必要な各ブロック内のKベクトルをかけ合わせて注意スコアを計算し、Vベクトルと組み合わせて最終的な出力ベクトルを得ます。 このブロック単位でのアクセスが可能になったことで、KVキャッシュを物理メモリ上の非連続な場所に自由に配置できるようになり、より柔軟なページング方式のメモリ管理が実現します。
4.2 KV Cache Manager:
vLLMのメモリ管理の核心は、OSの仮想記憶の考え方と同じです。 OSがメモリを固定サイズのページに分割し、プログラムの「論理ページ」を「物理ページ」にマッピングするように、vLLMはKVキャッシュを固定サイズの「KVブロック」(ページに相当)として扱います。 各リクエストのKVキャッシュは、生成されるトークンに応じて左から右へ埋まっていく一連の「論理KVブロック」として表現されます。 GPUワーカー上には、連続したGPUメモリ領域を物理KVブロックに分割して管理するブロックエンジンがあります。 KVキャッシュマネージャは、各リクエストの論理KVブロックと物理KVブロックのマッピングを記録した「ブロックテーブル」を管理します。論理ブロックと物理ブロックを分離することで、vLLMは最大シーケンス長分のメモリを事前に予約する必要がなくなり、必要に応じて物理ブロックを動的に割り当てることで、既存システムのほとんどのメモリ無駄を解消します。
4.3 Decoding with PagedAttention and vLLM:
単一の入力シーケンスのデコーディング処理が、PagedAttentionとvLLMのメモリ管理下でどのように行われるかの例が Figure 6 で説明されています。 最初のプロンプトフェーズでは、プロンプトのトークン数に応じて必要なKVブロック数(Figure 6 の例では7トークンなので2ブロック)分の物理ブロック(物理ブロック7と1)のみを割り当てます。 プロンプトのKVキャッシュはこれらの物理ブロックに格納されます。 続く自己回帰生成フェーズでは、新しいトークンが生成されるたびに、そのKVキャッシュを格納するための領域が必要になります。 最後の論理ブロック(論理ブロック1)に空きスロットがあれば、そこに格納し、ブロックテーブルの「#filled」(使用済みスロット数)を更新します。 もし最後の論理ブロックが満杯であれば、新しい論理ブロックが必要になります。
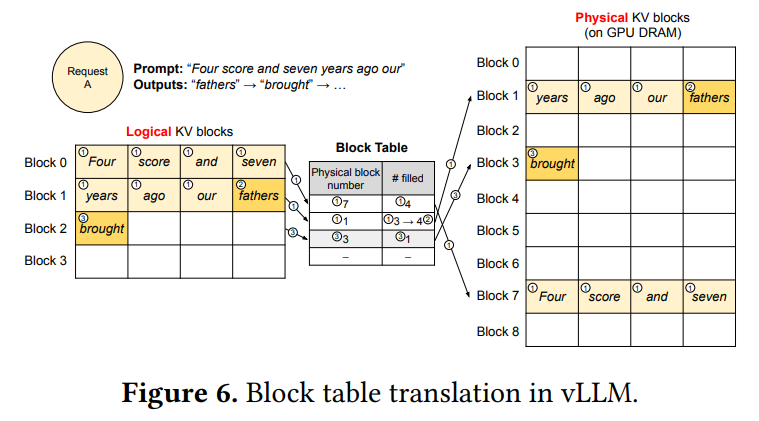
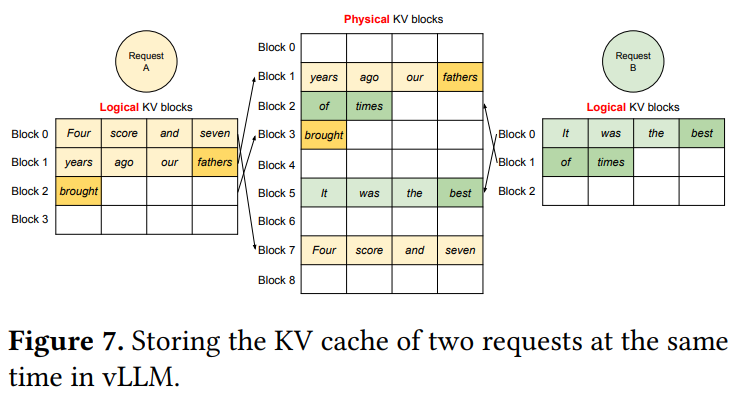
vLLMは、この新しい論理ブロックに対応する空いている物理ブロック(物理ブロック3)をGPUメモリから探し、割り当て、ブロックテーブルにマッピングを記録します。 デコーディングの各イテレーションでは、vLLMはバッチ処理するシーケンスを選択し、必要な新しい論理ブロックに物理ブロックを割り当てます。 そして、バッチ内の全トークンをまとめてLLMに入力し、PagedAttentionカーネルを使って前のKVキャッシュを物理ブロックから読み込み、新しいKVキャッシュを物理ブロックに書き込みます。 ブロックサイズを1より大きくすることで、KVキャッシュ処理のGPU並列処理を効率化できますが、大きすぎると内部断片化が増えるトレードオフがあります。 vLLMでは、物理ブロックが左から右へ完全に埋まってから次のブロックが割り当てられるため、リクエストごとのメモリ無駄が最大でも1ブロック内に収まり、メモリを効率的に利用できます。 これにより、より多くのリクエストをバッチに含めることができ、スループットが向上します。 リクエストが完了すると、使用していた物理ブロックは解放され、他のリクエストに再利用されます。 Figure 7 は、2つのリクエストのKVキャッシュが、物理メモリ上で非連続に配置された物理ブロックを効率的に共有している様子を示しています。
4.4 Application to Other Decoding Scenarios:
vLLMは、基本的なサンプリングだけでなく、並列サンプリングやビームサーチといった複雑なデコーディングアルゴリズムにも柔軟に対応できます。 これらのアルゴリズムは、同じプロンプトや中間結果を共有するため、KVキャッシュの共有機会が多くあります。
Parallel sampling (並列サンプリング):
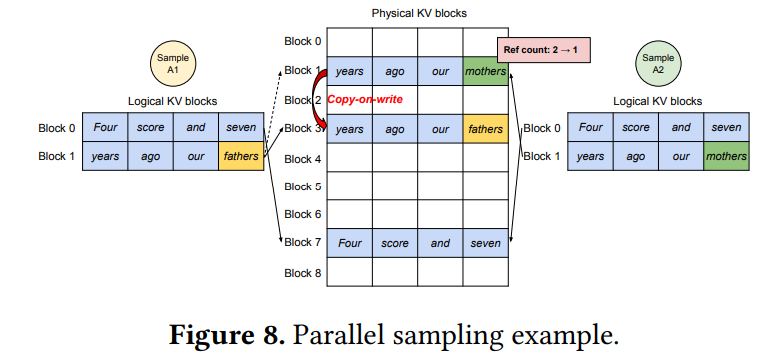
一つの入力プロンプトから複数の独立したサンプルを生成する手法です。 この場合、全てのサンプルは同じプロンプトを共有するため、プロンプト部分のKVキャッシュは共有できます。 vLLMでは、複数のシーケンスの論理ブロック(プロンプト部分)を同じ物理ブロックにマッピングし、物理ブロックごとに「参照カウント」を設けることでメモリ共有を実現します。 生成フェーズで異なる出力が生成されると、各シーケンスは独自のKVキャッシュを必要とします。 このとき、OSの仮想記憶におけるCopy-on-Write(書き込み時コピー)と同様のメカニズムがブロック単位で適用されます。 Figure 8 のように、共有されている物理ブロックに書き込みが必要になった場合、vLLMはその物理ブロックを新しい物理ブロックにコピーし、そのシーケンスのマッピングを新しいブロックに変更します。 これにより、プロンプトのKVキャッシュの大部分を共有でき、メモリ使用量を大幅に削減できます。
Beam search (ビームサーチ):
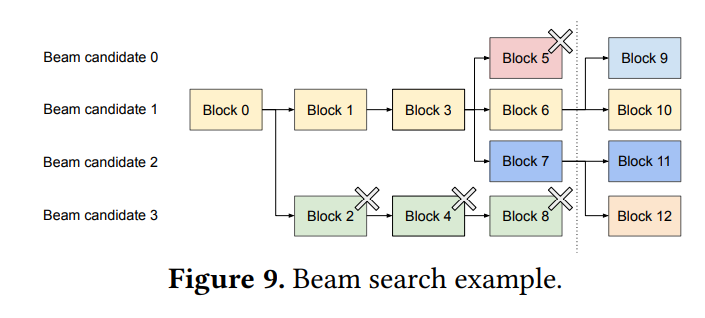
各生成ステップで最も確率の高い上位k個の候補(ビーム)を保持し、探索を進める手法です。 並列サンプリングと異なり、初期プロンプトだけでなく、途中の生成結果が一致している部分も共有できます。 共有パターンは生成プロセスに応じて動的に変化します。 Figure 9 は、ビームサーチにおける動的なブロック共有の例を示しています。 vLLMは、論理ブロックを物理ブロックにマッピングし、参照カウントで管理する仕組みにより、この動的な共有に効率的に対応します。 探索から外れた候補のブロックは解放され、参照カウントが0になった物理ブロックは再利用可能になります。 既存システムで必要だった頻繁なKVキャッシュのメモリコピーは、vLLMではブロック単位のCopy-on-Writeで済むため、オーバーヘッドが大幅に削減されます。
Shared prefix (共有プレフィックス):
多くのユーザーリクエストが共通の長い指示や例(システムプロンプトなど)を含む場合、その共通部分のKVキャッシュを事前に計算してキャッシュしておくことで、リクエストごとの計算量を削減できます。 vLLMでは、サービス提供者が定義した共有プレフィックスに対し、物理ブロックのセットを予約しておき、対応するユーザープロンプトの論理ブロックをこの予約済み物理ブロックにマッピングすることで実現します。 これもCopy-on-Writeメカニズムと組み合わせて使用されます。
Mixed decoding methods (混在するデコーディング手法):
vLLMは、異なるデコーディング手法(サンプリング、ビームサーチなど)を持つリクエストを同時にバッチ処理できます。 これは、論理ブロックと物理ブロックのマッピングという共通の抽象化レイヤーを介しているため、LLMやその実行カーネルは複雑な共有パターンを意識する必要がないからです。 これにより、バッチ処理の機会が広がり、システム全体の高スループットにつながります。
4.5 Scheduling and Preemption (スケジューリングとプリエンプション):
システムの容量を超えるリクエストが来た場合、vLLMはどのリクエストを優先するかを決めます。 vLLMでは、公平性と待ち時間回避のため、基本的にFCFS(First-Come-First-Serve、先着順)ポリシーを採用し、メモリが不足した場合は最新のリクエストからプリエンプト(処理を中断)します。 LLMサービング特有の課題は、入出力長が大きく変動し、出力長が事前に分からないため、生成が進むにつれてGPUメモリが不足する可能性があることです。 vLLMは、メモリが不足した場合に、どのブロックを追い出す(evict)か、そして必要になった場合にどう回復するかという問題を扱います。 追い出しポリシーとしては、シーケンス処理にはその全てのトークン状態が必要なことから、「All-or-Nothing」(シーケンス単位でまとめて追い出す)を採用しています。 ビームサーチの候補のような、リクエスト内で関連付けられたシーケンスグループもまとめて処理されます。 回復方法としては、OSと同様の「Swapping」(CPUメモリへのKVキャッシュの退避と、必要になった場合のGPUへの読み込み)と、「Recomputation」(プリエンプトされたシーケンスのKVキャッシュを破棄し、必要になった場合に再計算する)の2つをサポートしています。 再計算は、デコーディング済みのトークンとプロンプトを合わせて新しいプロンプトとして扱うことで、効率的に行える場合があります。 どちらの方法が効率的かは、CPUとGPU間の帯域幅やGPUの計算能力に依存します。
4.6 Distributed Execution (分散実行):
1つのGPUのメモリ容量を超えるほど大きなLLM(例えば175Bパラメータなど)を扱うためには、モデルを複数のGPUに分割して実行する「モデル並列」という手法が必要です。 vLLMは、Megatron-LMで使われているような、モデルをテンソル単位で分割し、複数のGPUワーカーが協調して計算を行うスタイル(テンソルモデル並列)をサポートしています。 モデルが分割されていても、各GPUワーカーは同じ入力トークンセットを処理するため、同じ位置のKVキャッシュが必要です。 vLLMでは、中央集権型スケジューラ内に単一のKVキャッシュマネージャを配置し、複数のGPUワーカーがこのマネージャと論理ブロックから物理ブロックへのマッピング情報を共有します。各ワーカーは、担当するアテンションヘッドに対応する部分のKVキャッシュのみを物理ブロックに格納します。 各処理ステップでは、スケジューラがバッチ内のリクエストの入力トークンIDとブロックテーブルをワーカーにブロードキャストし、ワーカーはこれに基づいて計算を行い、KVキャッシュにアクセスします。 ワーカー間では、スケジューラの介入なしにall-reduceのような通信プリミティブを使って中間結果を同期します。 GPUワーカーはメモリ管理の同期を個々に行う必要はなく、各ステップ開始時に必要な全ての情報をスケジューラから受け取るシンプルな構成になっています。
5 Implementation (実装)
vLLMは、ユーザーインターフェースから推論エンジンまでを含むエンドツーエンドのサービングシステムとして実装されています。 OpenAI APIと互換性のあるFastAPIベースのフロントエンドを持ち、最大シーケンス長やビーム幅などをリクエストごとに指定できます。 システムの主要部分はPython(スケジューラやブロックマネージャなど)と、性能が重要なカスタムカーネル部分はC++/CUDAで記述されています。 PyTorchとTransformersライブラリを使って、GPT、OPT、LLaMAといった主要なLLMが実装されており、分散GPU間の通信にはNCCLが使用されています。
5.1 Kernel-level Optimization:
PagedAttentionは、既存システムでは効率的にサポートされていない特殊なメモリアクセスパターン(非連続なブロックへのアクセス)を必要とします。 そこで、vLLMではそのためのカスタムGPUカーネルを開発しています。 例えば、新しいKVキャッシュの整形とブロックへの書き込みを融合したカーネル、ブロックテーブルに基づいたKVキャッシュの読み込みとアテンション計算を融合したカーネル、Copy-on-Writeで発生する複数のブロックコピー操作をまとめて行うカーネルなどです。 これらのカーネルは、ブロックテーブルアクセスや分岐、可変長処理などのオーバーヘッドを伴いますが、論文ではこのオーバーヘッドは小さく、全体性能への影響は限定的だと述べています。
5.2 Supporting Various Decoding Algorithms:
vLLMは、fork、append、freeという3つの基本的なメソッドの組み合わせによって、様々なデコーディングアルゴリズムをサポートしています。 forkは既存のシーケンスから新しいシーケンスを作成し、appendはシーケンスに新しいトークンを追加し、freeはシーケンスを削除します。 例えば、並列サンプリングではforkで複数の出力シーケンスを作成し、各イテレーションでappendを使ってトークンを追加、完了したシーケンスはfreeで削除します。 ビームサーチやプレフィックス共有なども同様にこれらのメソッドで表現できるとしています。
6 Evaluation (評価)
このセクションでは、様々なモデルとワークロードを用いてvLLMの性能が評価されています。
6.1 Experimental Setup:
評価には、OPTモデル(13B, 66B, 175B)とLLaMA-13Bが使用され、NVIDIA A100 GPUを搭載したサーバーで実験が行われました。(Table 1)ワークロードは、実際のLLMサービスの会話データであるShareGPTとAlpacaデータセットの入出力長分布に基づいて合成されています。(Figure 11)ShareGPTはAlpacaよりも平均入出力長が長く、ばらつきが大きい特徴があります。 リクエストの到着はポアソン分布に従うように生成されました。 比較対象として、高速なTransformer推論エンジンであるFasterTransformer(動的バッチングは行うがメモリ管理は静的)と、状態アートのLLMサービングシステムであるOrca(論文著者が3つの異なるメモリ過剰予約設定で実装)が用いられました。 性能指標は、スループットを示す「正規化レイテンシ」(リクエストの平均エンドツーエンドレイテンシをその出力長で割った値)です。 低い正規化レイテンシをより高いリクエストレートで維持できるシステムが高スループットと評価されます。
6.2 Basic Sampling:
単一シーケンス生成タスクでの評価結果が Figure 12に示されています。 ShareGPTデータセットでは、リクエストレートがある閾値を超えるとレイテンシが急増するという典型的な混雑挙動が見られます。 vLLMは、Orcaの理想的なケース(Orca (Oracle))と比較しても1.7倍から2.7倍、メモリを最大限に予約するOrca (Max) と比較すると2.7倍から8倍も高いリクエストレートを維持できることが示されています。 これは、vLLMのPagedAttentionがメモリ使用効率を大幅に向上させ、より多くのリクエストをバッチ処理可能にしたためです。
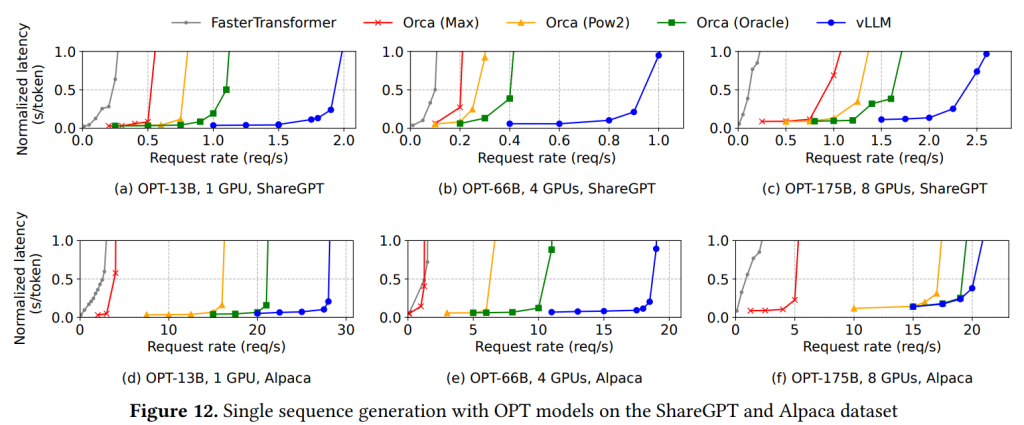
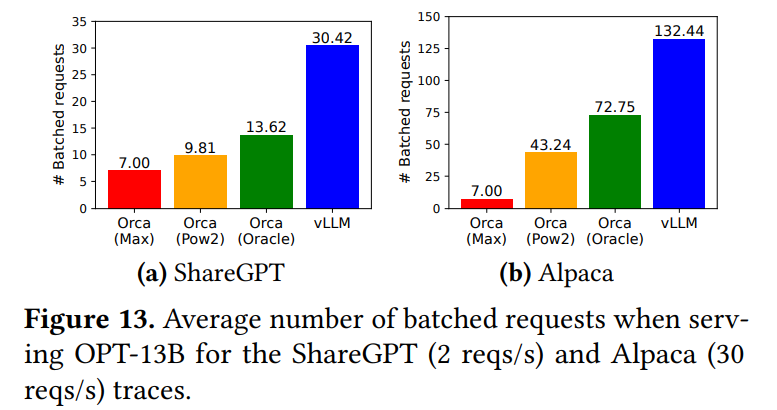
Figure 13aでは、OPT-13Bの例で、vLLMがOrca (Oracle) の2.2倍、Orca (Max) の4.3倍ものリクエストを同時にバッチ処理していることが示されています。 細粒度スケジューリングと効率的なメモリ管理を行わないFasterTransformerとの比較では、vLLMは最大で22倍高いリクエストレートを維持できました。Alpacaデータセットでも同様の傾向が見られますが、OPT-175BとAlpacaの組み合わせ(Figure 12f)では、vLLMとOrca (Oracle/Pow2) の差が小さくなっています。 これは、この設定ではGPUメモリに余裕があり、Alpacaのシーケンス長が短いため、Orcaのメモリ非効率の影響が比較的少なくなり、性能が計算能力によって制限されるようになったためです。
6.3 Parallel Sampling and Beam Search:
メモリ共有機能の効果を評価するため、並列サンプリングとビームサーチでの性能が評価されました。 Figure14a-cの並列サンプリングの結果は、生成する並列シーケンス数が増えるほど、vLLMのOrcaベースラインに対する優位性が増すことを示しています。 同様に、Figure14d-fのビームサーチの結果は、ビーム幅が大きいほどvLLMの性能向上が顕著になることを示しています。 OPT-13BとAlpacaデータセットのビーム幅6のビームサーチでは、基本サンプリングの1.3倍向上に対し、2.3倍の向上を達成しています。
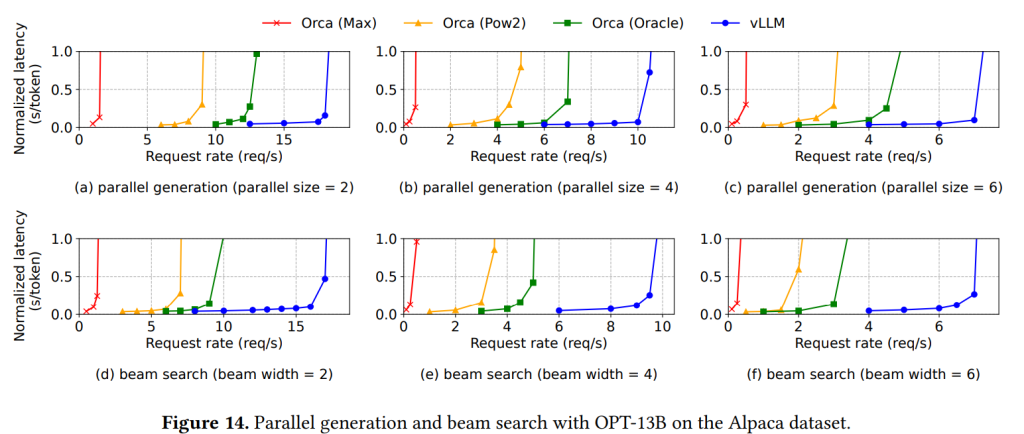
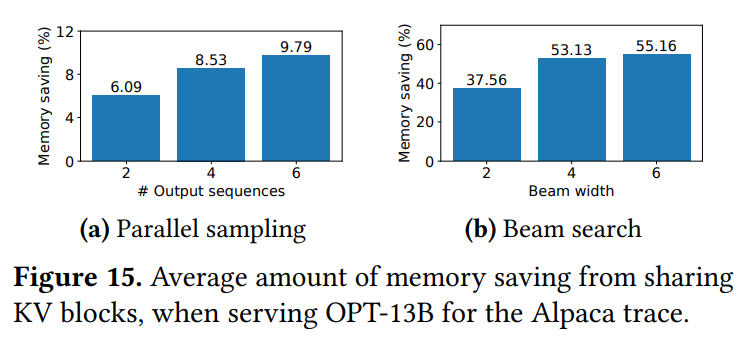
Figure15は、これらのシナリオにおけるKVブロック共有によるメモリ削減量を示しており、並列サンプリングで6.1%から9.8%、ビームサーチで37.6%から55.2%のメモリ削減が達成されています。 ShareGPTのような長いシーケンスのデータセットでは、さらに大きな削減率が見られました。
6.4 Shared prefix:
共通の長いプレフィックスを持つワークロード(例えばFew-shot推論のためのタスク説明など)に対するvLLMの効果が評価されました。 Figure 16は、翻訳タスクにおいて、共通のプレフィックス(1例または5例を含む)が共有されている場合の性能比較を示しています。 プレフィックスが長いほど(5例 vs 1例)、vLLMのOrca (Oracle) に対するスループット向上が大きくなることが示されています(1.67倍 → 3.58倍)。 これは、vLLMが共有プレフィックスのKVキャッシュを効率的に共有できるため、リクエストごとの計算量が減り、より多くのリクエストを処理できるようになるためです。

6.5 Chatbot:
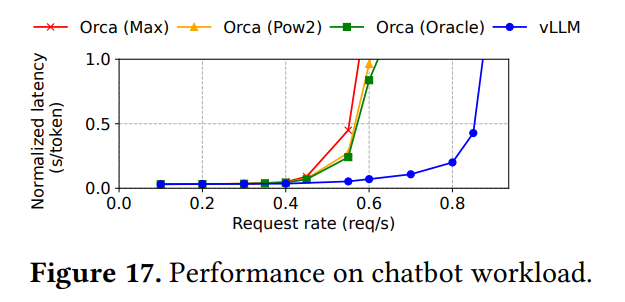
LLMの重要なアプリケーションであるチャットボットワークロードでの評価も行われています。 チャット履歴と最新のユーザー入力を結合してプロンプトとするシナリオです。 Figure 17は、vLLMが3つのOrcaベースライン全てに対し、2倍高いリクエストレートを維持できることを示しています。ShareGPTのような長い会話履歴を含むデータセットでは、プロンプトが最大コンテキスト長(ここでは1024トークン)近くまで長くなることがよくあります。 既存のOrcaベースラインは、出力分のメモリ空間を最大長で予約してしまうため、どのバージョンでも性能に大きな差が出ません。 対照的にvLLMは、PagedAttentionによりメモリの断片化と予約の問題を解消するため、長いプロンプトの場合でも効率的にメモリを使用でき、高い性能を発揮します。
7 Ablation Studies (アブレーション研究)
このセクションでは、vLLMの設計における様々な要素の効果を確認するためのアブレーション研究(特定の要素を取り除いたり変更したりして評価する実験)が行われています。
7.1 Kernel Microbenchmark:
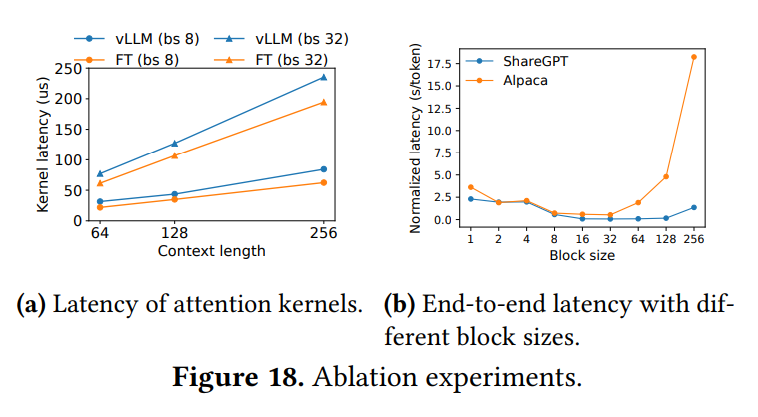
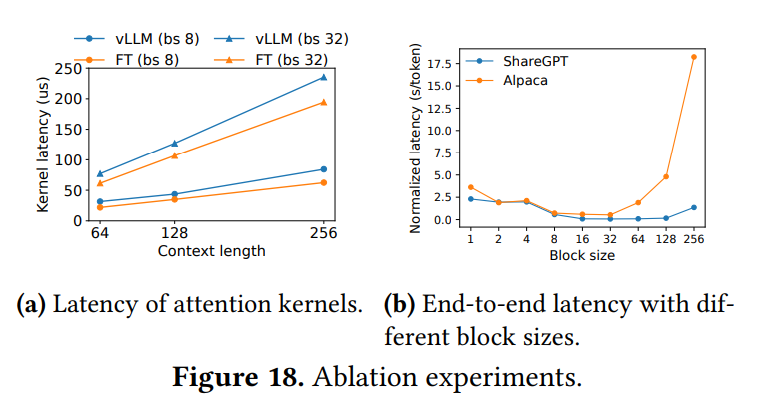
PagedAttentionのカスタムGPUカーネルの性能が評価されています。 ブロックテーブルの参照や可変長の処理などのオーバーヘッドにより、アテンションカーネル単体のレイテンシは、最適化されたFasterTransformerの実装と比較して20%から26%高くなることが示されています。(Figure 18a) しかし、このオーバーヘッドはモデル全体の一部の演算子にしか影響しないため、エンドツーエンドの性能ではvLLMがFasterTransformerを大幅に上回ります。
7.2 Impact of Block Size:
PagedAttentionにおけるKVブロックサイズの選択が性能に与える影響が評価されています。 ブロックサイズが小さすぎると、GPUの並列処理を十分に活用できない可能性があります。 一方、大きすぎると、最後のブロックの内部断片化が増加したり、メモリ共有の機会が減ったりする可能性があります。Figure 18bの結果は、ワークロードによって最適なブロックサイズが異なることを示しています。 ShareGPTのような平均シーケンス長が比較的長いワークロードでは16から128の範囲で良好な性能を示し、Alpacaのような短いワークロードでは16や32が良い性能を示しています。 特にAlpacaでは、ブロックサイズが大きいとシーケンス長より大きくなってしまうことが多く、性能が著しく低下します。 論文では、デフォルトのブロックサイズとして16が多くのワークロードで効率的なGPU利用と断片化抑制のバランスを取れると結論付けています。
7.3 Comparing Recomputation and Swapping:
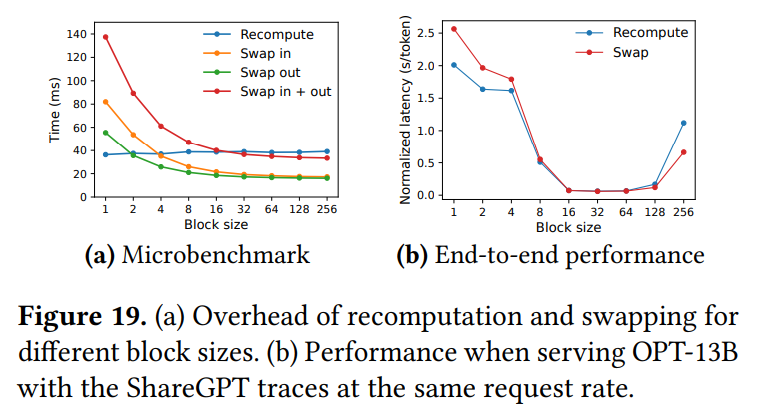
プリエンプトされたリクエストの回復方法として、スワッピングと再計算のどちらが優れているかの比較が行われています。 Figure 19aのマイクロベンチマーク結果は、スワッピングはブロックサイズが小さい場合に大きなオーバーヘッドが発生することを示しています。 これは、多数の小さなデータ転送が発生し、PCIe帯域幅の利用効率が低下するためです。 対照的に、再計算のオーバーヘッドはブロックサイズによらず一定です。 結果として、ブロックサイズが小さい場合は再計算が効率的であり、大きい場合はスワッピングが効率的です。 ただし、再計算のオーバーヘッドはスワッピングの20%以下に収まることが多いようです。 Figure 19bのエンドツーエンド性能比較では、ブロックサイズが16から64程度の中程度の場合、両者の性能は同程度であることが示されています。
8 Discussion (議論)
このセクションでは、本研究の意義や今後の展望、関連技術との比較などが議論されています。
- Applying the virtual memory and paging technique to other GPU workloads: OSの仮想記憶とページングの技術は、LLMサービングのKVキャッシュ管理に非常に有効でした。 これは、LLMサービングが「出力長が未知のため動的なメモリ割り当てが必要」であり、かつ「性能がGPUメモリ容量によって制限される(メモリバウンド)」という特性を持っているためです。 しかし、この技術が全てのGPUワークロードにそのまま有効とは限りません。 例えば、DNNトレーニングのようにテンソルの形状が静的で事前にメモリ割り当てを最適化できる場合や、LLM以外のDNNサービングのように計算能力がボトルネック(計算バウンド)でメモリ効率を上げても性能向上に繋がりにくい場合もあります。 そのようなシナリオでは、メモリインダイレクション(論理アドレスから物理アドレスへの変換)のオーバーヘッドにより、かえって性能が低下する可能性もあります。 一方で、LLMサービングと同様の特性を持つ他のワークロードへの応用は期待できるとしています。
- LLM-specific optimizations in applying virtual memory and paging: vLLMは、OSの仮想記憶・ページングのアイデアをそのまま適用するだけでなく、LLM特有のセマンティクス(意味論)を活用して拡張しています。 例えば、リクエスト処理にはその全てのトークン状態がGPUメモリに必要であるという事実を利用した「All-or-Nothing」のスワップアウトポリシー や、OSでは一般的に行われない「Recomputation」による追い出しブロックの回復 などです。また、カーネル融合によって、ページングに伴うメモリインダイレクションのオーバーヘッドを緩和しています。
9 Related Work (関連研究)
一般的なモデルサービングシステム、Transformerに特化したサービングシステム、メモリ最適化技術など、関連する様々な研究が紹介されています。
特に、状態アートのLLMサービングシステムであるOrca との比較が詳しく述べられています。 Orcaは、Iteration-levelスケジューリングによってリクエストをきめ細かくインターリーブ(交互に処理)し、GPUの計算能力を最大限に利用することでスループットを向上させています。 これに対し、vLLMはPagedAttentionによってメモリ利用率を高めることで、より多くのリクエストのワーキングセット(処理に必要なデータ)をメモリに収め、バッチサイズを増やすことでスループットを向上させています。 論文では、OrcaのスケジューリングとvLLMのPagedAttentionは補完関係にあり、vLLMはメモリ効率向上によってOrcaと比較して2倍から4倍の高速化を達成したと述べています。 Orcaのような細粒度スケジューリングはメモリ管理をより複雑にするため、vLLMの技術はさらに重要になるとも指摘されています。
10 Conclusion (結論)
本論文は、LLMサービングの高スループット化のために、OSの仮想記憶・ページング技術から着想を得た新しいアテンションアルゴリズムPagedAttentionと、それに基づくvLLMシステムを提案しました。 vLLMはKVキャッシュを効率的に管理し、様々なデコーディングアルゴリズムにおけるメモリ共有を可能にすることで、既存の最先端システムと比較して2倍から4倍のスループット向上を実証しました。 この技術は、LLMサービングのコスト削減と普及に大きく貢献するものと言えるでしょう。
まとめ
今回の論文では、LLMサービングにおけるKVキャッシュのメモリ管理という、スループット向上のための隠れた、しかし非常に重要なボトルネックに対し、OSの古典的な技術である仮想記憶とページングを応用するというアプローチを取ったvLLMというシステムを開発し、発表されました。
KVキャッシュを固定サイズのブロックに分割し、物理メモリ上の非連続な場所に柔軟に配置できるPagedAttentionアルゴリズムと、それを可能にするブロックベースのメモリマネージャ、そしてCopy-on-Writeやメモリ不足時のスワッピング/再計算といった機構によって、vLLMは既存システムで大きな無駄となっていたメモリ断片化を劇的に削減し、さらにビームサーチや並列サンプリングにおけるKVキャッシュ共有を効率的に実現しました。その結果、GPUメモリを最大限に活用して、より多くのリクエストを同時に処理できるようになり、既存システムに比べ2倍〜4倍という驚異的なスループット向上を達成しました。








