
はじめに
近年、大規模言語モデル(LLM)の目覚ましい進化は、私たちの生活やビジネスに大きな影響を与えています。しかし、これらのモデルの真の能力を引き出すためには、事前学習(pre-training)だけでなく、その後の学習後訓練(post-training)が非常に重要になってきます。特に、強化学習(Reinforcement Learning, RL)を用いた訓練は、モデルが複雑な推論能力を獲得するために強力な手法として注目されています。例えば、DeepSeek-R1-Zeroは、強化学習によってその推論能力を大きく向上させたことが報告されています。
しかし、LLMに対して強化学習を効率的に適用し、その能力を大規模に引き出すには、多くの技術的な課題が伴います。具体的には、推論のスケーリングには膨大な並列処理が必要となり、これによって遅延、メモリ、信頼性といった問題が生じるだけでなく、経済的なコストも増大する傾向にあります。従来の強化学習システムは、大規模なGPUクラスターをオーケストレーションし、訓練中にポリシーの重みを同期させる必要があったため、これらが通信のボトルネックとなり、安定した効率的な運用には高度なインフラ整備が不可欠でした。
このような課題を解決するため、Gensyn AIチームはSAPO(Swarm sAmpling Policy Optimization)という新しい強化学習の学習後訓練アルゴリズムを提案しました。SAPOは、完全に分散型かつ非同期のアルゴリズムであり、異なる種類の計算ノードがネットワーク上で協力し合う「スウォーム」という環境のために設計されています。この手法では、各ノードが自身のポリシーモデルを管理しながら、学習によって得られたロールアウト(モデルの行動履歴)を他のノードと「共有」します。これにより、ノード間の遅延、モデルの均質性、ハードウェアの種類に関する明示的な仮定なしに学習を進めることが可能になります。
本記事では、このSAPOアルゴリズムについて、論文の内容を詳細に解説していきます。SAPOがどのようにして強化学習のスケーリングにおけるボトルネックを回避し、学習プロセスに「Ahaモーメント」(閃き)を伝播させることで、モデルの性能を最大94%向上させたのか、解説します。
解説論文
- 論文タイトル:Sharing is Caring: Efficient LM Post-Training with Collective RL Experience Sharing
- 論文URL:https://arxiv.org/pdf/2509.08721
- 発行日:2025年9月10日
- 発表者:Gensyn AI Team Jeffrey Amico, Gabriel Passamani Andrade†, John Donaghy†, Ben Fielding, Tristin Forbus, Harry Grieve, Semih Kara†, Jari Kolehmainen, Yihua Lou†, Christopher Nies, Edward Phillip Flores Nuño, Diogo Ortega, Shikhar Rastogi†, Austin Virts, Matthew J. Wright
要点
- SAPO(Swarm sAmpling Policy Optimization):言語モデル(LM)の学習後訓練における強化学習の効率とスケーラビリティを向上させる分散型アルゴリズムである。
- 分散型・非同期: 各ノードが自身のモデルを独立して訓練し、互いのロールアウトを共有することで、従来の同期型システムに起因するボトルネックや高コストを回避する。
- 異種環境対応: ハードウェア、モデルアーキテクチャ、学習アルゴリズムの多様性を許容し、低遅延やモデルの均一性に関する前提が不要である。
- 経験共有による加速: 共有されたロールアウトからサンプリングすることで、あるノードが得た「Ahaモーメント」(効果的な学習経験)がネットワーク全体に伝播し、学習プロセスが大幅にブートストラップされる。
- マルチエージェント的利点: 暗黙的に多様なモデルと豊富なデータが探索能力と汎化能力を高めるマルチエージェントシステムのように機能する。
- 高い効率と性能向上: 制御された実験では、バランスの取れた経験共有(ローカルと外部のロールアウトを半々に利用)によって、ベースラインと比較して累積報酬で最大94%の性能向上が確認された。
- 中容量モデルへの恩恵: 大規模なオープンソースデモでは、SAPOが特に中容量の言語モデル(SLM、Small LMs)において顕著な効果を発揮することが示唆された。
詳細解説
Introduction (はじめに)
言語モデル(LM)の能力を事前学習後にさらに向上させることは、AI研究の中心的な目標となっています。その中でも、強化学習(RL)は、教師ありデータだけに頼るのではなく、試行錯誤を通じてモデルを改善できる強力なツールとして注目されています。最近では、DeepSeek-R1-Zeroのように、強化学習を用いてLMが複雑な推論能力を高める事例も出てきています。
しかし、LM向けに強化学習をスケールアップする従来の取り組みは、大規模なGPUクラスターを調整する分散システムに焦点を当ててきました。これらのシステムでは、訓練中にポリシーの重みを常に同期させる必要があるため、コストが高く、通信のボトルネックが生じ、安定性と効率性を保つためには入念に設計されたインフラが必要でした。
そこで、これらの課題に対処するために導入されたのが、Swarm sAmpling Policy Optimization(SAPO)です。SAPOは、異種計算ノードからなる分散ネットワークのために構築された、分散型RLアルゴリズムです。この設定は「スウォーム(swarm)」と呼ばれ、各ノードは自身のポリシー(またはモデル)を訓練しながら、デコードされたロールアウト(例えばプレーンテキスト形式)を共有します。このシンプルなメカニズムにより、フレームワークはモデルアーキテクチャ、学習アルゴリズム、ハードウェアに依存せず、異種多様な貢献者が同期オーバーヘッドなしで参加できるようになります。
結果として、このシステムはまるでマルチエージェントの設定のように振る舞い、多様なモデルと豊富なデータが探索を強化し、汎化(未知のデータへの適応能力)を改善します。制御実験では、SAPOが従来の分散RLメソッドのコスト、ボトルネック、脆弱性を回避しつつ、より高いサンプル効率と強力なタスクパフォーマンスを実現し、累積報酬を最大94%向上させることが観察されました。SAPOはどんなRL設定にも適用可能ですが、本研究では、スウォームがローカルデバイスやエッジデバイスで実装されることが多いという理由から、SLM(Small LMs)、すなわち100億パラメータ未満のLMに焦点を当てています。具体例として、GensynのRLSwarmは、何千もの異種SLMがコンシューマーグレードのハードウェア(MacBookなど)上でローカルに動作し、集合的に相互作用・訓練することを可能にしています。
2. Related Work (関連研究)
このセクションでは、SAPOの背景となる強化学習とマルチエージェント研究の状況を概観し、SAPOが既存手法とどのように関連し、異なっているのかを説明します。
Reinforcement Learning for LM Fine-Tuning (LMのファインチューニングのための強化学習)
強化学習は、LMのファインチューニングにおいて中心的な技術となり、モデルの行動を人間の好みに合わせたり、事実の正確性、コード生成、そして教師あり学習だけでは達成できない推論能力を向上させたりしています。教師あり学習が正解データに基づいてモデルを直接訓練するのに対し、RLは試行錯誤を通じてモデルを最適化します。
強化学習の中でも、主要なパラダイムとしてRLHF(Reinforcement Learning from Human Feedback)とRLVR(Reinforcement Learning with Verifiable Rewards)が挙げられます。RLHFは、人間の好みデータに基づいて報酬モデルを訓練し、その報酬モデルを使ってLMをファインチューニングします。一方、RLVRは、ルールベースでプログラム的に検証可能な報酬関数を利用します。どちらのケースでも、最終的な報酬は、PPO(Proximal Policy Optimization)などのポリシー勾配アルゴリズムを通じてLMをファインチューニングするために使用されます。最近では、GRPO(Group Relative Policy Optimization)やその派生であるDAPO、VAPOといった拡張アルゴリズムが、複雑な推論をより良く捉え、メモリや計算要件を削減するために開発されています。
Multi-Agent Methods (マルチエージェント手法)
マルチエージェント手法も、LM研究におけるモデルアーキテクチャやファインチューニング戦略に大きな影響を与え、中心的な焦点となっています。これらのアプローチは、主に議論(debate)、専門化(specialization)、そして自己改善(self-improvement)という3つのアイデアに基づいて構築されています。
- 議論: 複数のLMが独立してクエリに回答し、その後、反復的な対話を通じて回答を洗練させる手法です。最終的な出力は投票または専用の検証器によって選択され、より高品質な回答が生成されます。
- 専門化: エージェントに定義された役割が与えられるアプローチです。例えば、MALT(Motwani et al., 2025)は、生成、検証、洗練のために別々のエージェントを使用する典型的な例です。
- 自己改善: ブートストラップと反復的な自己プレイに重点を置いた手法です。SPIN(Chen et al., 2024)は、人間が提供した出力と自己生成した出力を区別することを学びながら、人間によるアノテーションに近い応答を繰り返し生成するようにモデルを訓練します。
これらのマルチエージェント戦略には、モデルの堅牢性や安全性を向上させるために、敵対的技術を組み込むことも可能です。また、これらのマルチエージェント手法の多くは、モデルパラメータを更新するために強化学習を利用しています。
Comparing SAPO (SAPOの比較)
SAPOは、RLHFやRLVRのような強化学習ベースのファインチューニング手法を基盤としており、報酬駆動型の試行錯誤を通じてLMを改善します。しかし、従来のRLアプローチとは異なり、SAPOはすべてのロールアウトを単一のポリシーが生成する必要がなく、複数のポリシー間の同期も不要です。
マルチエージェントの観点から見ると、SAPOは最小限の追加計算で協調的な振る舞いを自然に示します。構造化されたマルチエージェントフレームワークのように、専門化されたノードや協調的なオーケストレーションを目指すものではありません。しかし、経験を共有することで、ノードは互いの探索と推論から間接的に利益を得て、より豊かな訓練シグナルを得ることができます。 この点で、SAPOは単一エージェントのRLファインチューニングと構造化されたマルチエージェントフレームワークとの間を橋渡しする位置づけにあります。経験共有を通じて、SAPOはマルチエージェント手法の多くの利点を捉え、訓練を加速します。そして、RLファインチューニングを通じて、個々のノードがこれらの利益を享受し、最終的にはスウォーム内の他のノードにそれらを伝播することを促します。スウォームとの通信やサンプリングされたロールアウトの再エンコードには通信および計算上のオーバーヘッドが伴いますが、後述の実験 (§5) で示されるように、集団的な利益が個々の追加コストを上回ります。
3. Methodology (方法論)
このセクションでは、SAPOの基本的な構成要素とその動作原理を詳細に説明します。
3.1. The Swarm (スウォーム)
SAPOの中心にあるのは、N個のノードからなる分散ネットワーク、すなわちスウォームです。このスウォームでは、ノードは離散的な時間ステップ \(t \in [T]\) (ここで \(T > 0)\)で互いにロールアウトを生成・通信します。
各ノード \(n\) は、質問(またはタスク)のセット \(Q_n\) を持ち、それぞれの質問 \(q \in Q_n\) には正解 \(y_q \in Y_n\) が存在します。ノード \(n\) のデータセットは、これらの質問と正解のペアで構成され、\(D_n := {(q, y_q) | q \in Q_n}\) と表されます。
重要な要件として、このデータセット内のタスクは検証可能(verifiable)である必要があります。つまり、その回答が効率的かつアルゴリズム的に正誤チェックできるということです。また、ノード \(n\) によって生成されるロールアウトは、スウォーム内の他のノードと同じ(または互換性のある)モダリティである必要があります。例えば、画像生成ノードとテキスト生成ノードが混在するマルチモーダルなスウォームの場合、ノードは互換性のないモダリティのロールアウトをローカルで無視する、といった運用が考えられます。
ノード \(n\) は、このデータセット \(D_n\) のメタデータ \(M_n\) も保持しており、これはデータセット内の各タスクをどのように検証するかを具体的に指定します。さらに、ノード \(n\) は、強化学習の用語で言えばポリシー \(\pi_n\)によって表現されるモデル(例えばLM)を持っています。このポリシー \(\pi_n\) は、適切な入力形式(例えばプロンプト)を回答にマッピングする役割を担います。
質問 \(q \in Q_n\) が与えられると、ノード \(n\) は \(L_n\) 個の回答を生成します。これを \(R_n(q) := {a_{n1}(q), \ldots, a_{nL_n}(q)}\) と表現し、これが質問 \(q\) に対するノード \(n\) のロールアウトとなります。本論文では、モデルはSLMであると仮定し、質問は簡略化のためプロンプトとして直接提示されます。しかし、このフレームワークは任意のプロンプトジェネレーターもサポートしており、質問/タスクの難易度やフォーマットを学習によって制御することも可能です。
なお、スウォーム内のノードは必ずしも訓練に参加する必要はなく、互換性のある任意のポリシーを使用することができます。つまり、スウォームのメンバーとして活動するノードは、必ずしも常に自身の言語モデルを強化学習で訓練し続ける必要はなく、単に質問に対する回答を、どのようなモデル(ポリシー)を使ってでも良いので互換性のある形(同じモダリティ)で生成し、それを他のノードと共有する役割だけを担うことができる、ということです。
これは突き詰めると、人間自身も「ポリシー」としてロールアウト(回答)を生成して学習に参加できる、と考えられます。難しい問題に対して人間が考えた模範解答や、特定の専門知識に基づく意見をテキストとしてスウォームに提供する、といったことが可能であるということです。これは、人間や他の非伝統的なポリシー(ルールベースのシステムや、特定のタスクに特化した別の種類のAI、あるいはすでに訓練が完了していて更新されない(フリーズされた)モデルなど)がスウォームのジェネレーターとして機能する可能性を示唆しており、非常に興味深い点です。
3.2. Swarm Sampling Policy Optimization (SAPO) (スウォームサンプリングポリシー最適化 (SAPO))
SAPOの訓練プロセスは、標準的な強化学習の学習後訓練と多くの点で共通しています。各訓練ラウンドにおいて、各ノードはまず自身の質問セット \(Q^n\) から質問のバッチ \(B^n \subseteq Q^n\) をサブサンプリングし、それらの質問に回答することでロールアウトを生成します。
ここでSAPOの核心的な部分が登場します。ロールアウトが生成され、報酬計算に進む前に、各タスクとロールアウトのデータポイントは他のノードと「共有」されたり、「サンプリング」されたりすることができます。具体的には、各ノード \(n\) は、バッチ内の質問のサブセット \(\mathcal{S}^n \subseteq B^n\) について、質問、そのメタデータ、正解、および対応するロールアウトをブロードキャストします。これを形式的に \(C^n(q) := (q, y_q, R^n(q), M^n)) for (q \in S^n \subseteq B^n\) と表します。
重要なのは、これらのロールアウトがデコードされた形式(エンコードされていない形式)で共有されることです。(もしデコードされた形式で共有されない場合、各モデルは同じトークナイザーやアーキテクチャを利用していないといけなくなり、同期が必要となってしまいます。)これにより、スウォーム内の個々のノードは、たとえ自身のポリシーがそのロールアウトを生成する可能性が低かったとしても、自身のポリシーが生成したかのようにこれらのロールアウトをエミュレートし、トークンレベルの値を再エンコードして計算することができます。
次に、ノード \(n\) は、自身のロールアウトから \(I_n\) 個のデータポイントと、スウォーム内で他のノード \(m \neq n\) によって共有されたロールアウトから \(J^n\) 個のデータポイントをサブサンプリングすることで、訓練セット \(T^n\) を構築します。 数式で書くと、以下のようになります。
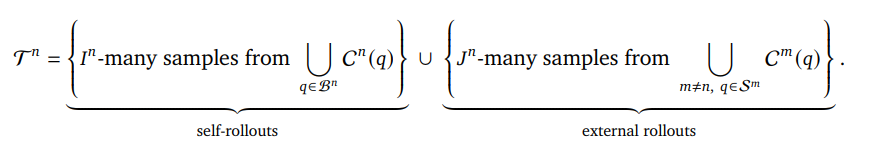
ここで重要なのは、個々のノードがローカルで生成されたロールアウトとスウォームからサンプリングされたロールアウトのどちらを選択するかについて、サンプリング方法を完全に制御できる点です。これは、スウォーム内で共有される経験を各ノードが自身のポリシーモデルに合わせて調整し、フィルタリングするための重要なメカニズムとなります。例えば、本論文の実験では、すべてのノードがまずゼロアドバンテージ(報酬と価値関数の差が0で、特に改善の余地が少ないロールアウト)のロールアウトを破棄し、残りのスウォームロールアウトから一様にサンプリングしています。
訓練セットを構築した後、ノードは自身のローカル報酬モデル \(\rho_n\)を使用して \(T^n\) 上の報酬を計算し、PPOやGRPOといった任意のポリシー勾配アルゴリズムを用いて自身のポリシーを更新します。この、ローカル生成データとスウォームからサンプリングされたデータから訓練セットを構築し、ポリシーを更新するプロセスは、各ノードが設定した訓練ラウンド数だけ繰り返されます。なお、外部サンプル数 \(J^n\) を0に設定すると、ノード \(n\) の訓練は標準的な強化学習のファインチューニングと全く同じになります。
SAPOの擬似コードを以下に示します。

4. Controlled Experiment Setup (制御実験の設定)
このセクションでは、SAPOの有効性を評価するために実施された制御実験の詳細な設定について説明します。
研究チームは、0.5Bパラメータを持つ8つのQwen2.5モデル(Qwen Team, 2024)からなるスウォームを構築し、実験を行いました。訓練プロセスはPyTorchを用いて実装され、モデルはDockerコンテナ内で実行されました。Docker Composeスクリプトを使用してコンテナのオーケストレーションを行い、スケーラブルなデプロイメントを可能にしました。マルチGPU並列処理はPyTorchの分散パッケージで管理され、各エージェントに1つのGPUが割り当てられ、NCCL(NVIDIA Collective Communications Library)がスウォーム内の通信を担いました。
4.1. Dataset (データセット)
実験には、ReasoningGYMデータセット(Stojanovski et al., 2025)を使用しました。このデータセットのユニークな点は、代数、論理、グラフ推論といった様々な領域の問題をオンデマンドで生成できることです。問題を要求するたびに、ドメイン固有のジェネレーターが新しいインスタンスを生成するため、ReasoningGYMは実質的に無限の多様な訓練および評価タスクを提供でき、サイズ、構造、難易度を調整することが可能です。さらに、各ドメイン固有ジェネレーターには、プログラム可能な検証器がペアになっており、回答の正誤を信頼性高くチェックできます。
ReasoningGYMのタスクカタログから、以下の専門分野(specialties)を選択しました。
- base_conversion: 異なる基数間の数値変換
- basic_arithmetic: 初等算術演算
- arc_1d: 1次元シーケンスに対する抽象推論(ARCベンチマークの簡易版)
- bf: Brainf*ckプログラムや類似のアルゴリズム推論タスク
- propositional_logic: 命題論理の問題解決
- fraction_simplification: 分数の最大限の簡略化
- decimal_arithmetic: 小数を含む算術演算における適切な演算子優先順位の強制
- calendar_arithmetic: カレンダーの日付に関する単語問題のパズル解決
- binary_matrix: 二値正方行列に関する抽象推論
この選定により、記号、数値、抽象的な領域にわたる多様な推論タスクでの評価が保証されます。各訓練ラウンドで、各エージェントは上記リストから専門分野をランダムにサンプリング(復元抽出)し、専門分野ごとに1つのReasoningGYM質問を受け取ります。そして、自身の質問ごとに8つの完了を生成し、その結果、質問ごとに8エントリのロールアウトが生成されます(つまり、すべてのノードで \(L^n = 8)\)。実験では、エージェントは「ジェネラリスト」として機能し、すべての専門分野から等しい確率で質問を受け取りました。
4.2. Policy Update (ポリシー更新)
各ノードのポリシー更新には、GRPO(Group Relative Policy Optimization)を使用しました。初期の実験でDAPO(Yu et al., 2025)と同様に、KLダイバージェンスペナルティの重みをゼロに設定すると、訓練がより効率的になることが判明したため、そのように設定しました。また、クリッピングには非対称な閾値を使用し、下限比率\(\epsilon_{low} = 0.2\) および上限比率 \(\epsilon_{high} = 0.28\) としました。訓練は2000ラウンド実行され、Adamオプティマイザがデフォルトのハイパーパラメータ(学習率0.001など)で使用されました。
4.3. Reward Model (報酬モデル)
各ノードおよびタスクの報酬計算には、ReasoningGYMが提供する柔軟なルールベースの検証器を使用しました。タスク固有の検証器が完了(モデルの出力)から正しい回答を解析できた場合、報酬として1が割り当てられ、そうでなければ0が割り当てられます。興味深いことに、初期の実験ではフォーマット報酬を追加していましたが、SAPOの経験共有によってこれが不要であることがすぐに判明し、その後削除しました。ReasoningGYMの検証器が期待する正しいフォーマットに関する知識が、明示的な報酬シグナルなしにスウォーム全体にほぼ即座に広まったためです。
4.4. GenRL (GenRL)
実験には、GensynのRLSwarmプラットフォームのバックエンドであるGenRL(Gensyn, 2025)を使用しました。GenRLは、スケーラブルなマルチエージェント、マルチステージ強化学習のために設計された分散型でモジュール式のフレームワークです。集中型システムとは異なり、ピアツーピアの協調と通信をサポートし、システムアーキテクチャを完全に制御できます。特に注目すべきは、GenRLがReasoningGYMとシームレスに統合されており、100以上の手続き的に生成された検証可能な推論タスクにすぐにアクセスできる点です。
5. Controlled Experiment Results (制御実験結果)
SAPOの有効性を評価するため、§4で説明したスウォームを、異なる程度の経験共有を用いて訓練しました。比較のためのベースラインは、共有なし、つまり標準的な強化学習のファインチューニングに相当します (§3)。条件を公平に保つため、各エージェントにはラウンドごとに8つのタスク(質問)が割り当てられ、すべての設定で訓練サンプルの総数は固定されました。
ベースライン設定では、各エージェントは専門分野を一様にサンプリングし、専門分野ごとに1つの質問を受け取り、質問ごとに8つの完了を生成し、自身のロールアウトのみ(かつ全て)を使用してポリシーを更新します。一方、SAPO設定(\(I\) ローカル / \(J\) 外部ロールアウト、ここで \(I, J > 0\) かつ \(I+J=8\))では、各エージェントは \(I\) 個の専門分野をサンプリングし、専門分野ごとに1つの質問を受け取り、質問ごとに8つの完了を生成します(完了数はすべての実験で固定)。その後、各エージェントは自身のすべてのロールアウトをスウォームと共有します。共有プールから、ゼロアドバンテージのロールアウトを削除し、残りのロールアウトから \(J\) 個をサンプリングして、自身のローカルロールアウトと組み合わせてポリシーを更新します。SAPOは、ベースラインではできない、より大きなプールからサブサンプリングし、情報量の少ない0アドバンテージサンプルを削除する柔軟性をエージェントに与えています。
今回の実験では、合計4つの設定を評価しました。
- 8ローカル / 0外部 (ベースライン、共有なし)
- 6ローカル / 2外部
- 4ローカル / 4外部
- 2ローカル / 6外部
各設定について、訓練中に得られた報酬の軌跡を調べました。
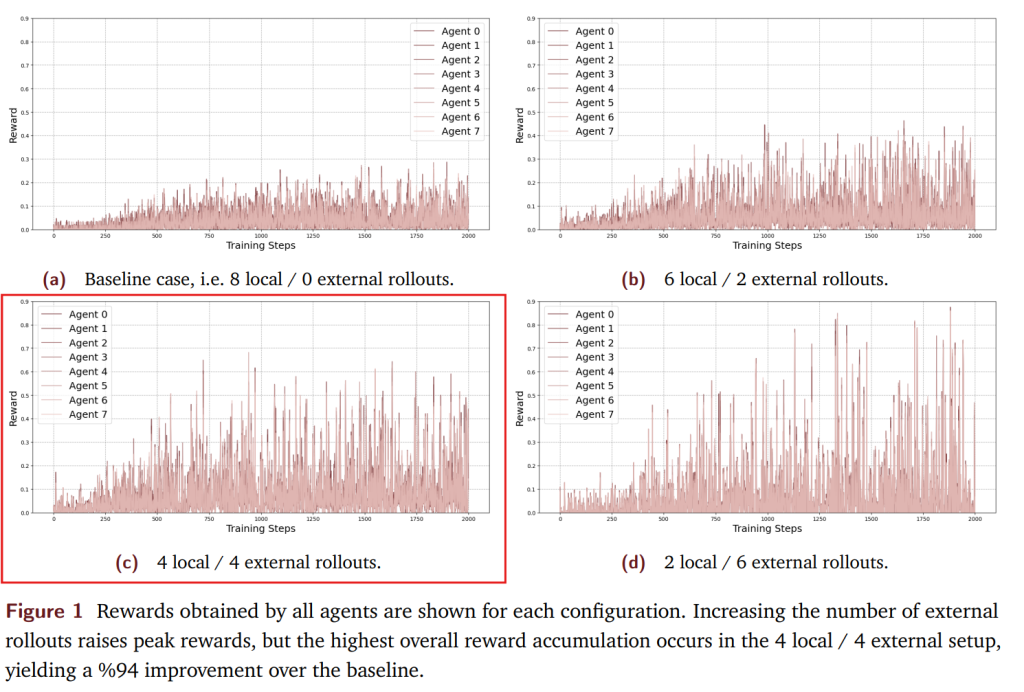
Figure1は、各設定における全エージェントが訓練ラウンド全体で得た報酬を示しています。グラフが示しているように、4ローカル / 4外部と2ローカル / 6外部のスキームが最も高いピーク報酬を達成し、共有なしのベースラインを明らかに上回りました。全設定の中で、4ローカル / 4外部の構成が、エージェントとラウンドを通じて累積された合計報酬で最大の1093.31を達成しました。これに続いて、2ローカル / 6外部が945.87、6ローカル / 2外部が854.43となりました。一方、ベースラインはわずか561.79でした。全体として、4ローカル / 4外部のスキームが最も優れたパフォーマンスを示し、ベースラインと比較して94%の改善を達成しました。
さらに深い洞察を得るため、各設定のエージェント平均報酬を調査しました。また、カーブを滑らかにするために、100サンプルのウィンドウで移動平均を適用しました。ポリシーパラメータは個々の訓練ステップよりもゆっくりと変化するため、移動平均はポリシーが固定されているかのように報酬を平均する効果があります。このため、平滑化されたカーブは、タスク全体での期待平均報酬の合理的な推定値として機能します。結果はFigure2に示されており、信頼区間はエージェント間の最小値と最大値で与えられています。
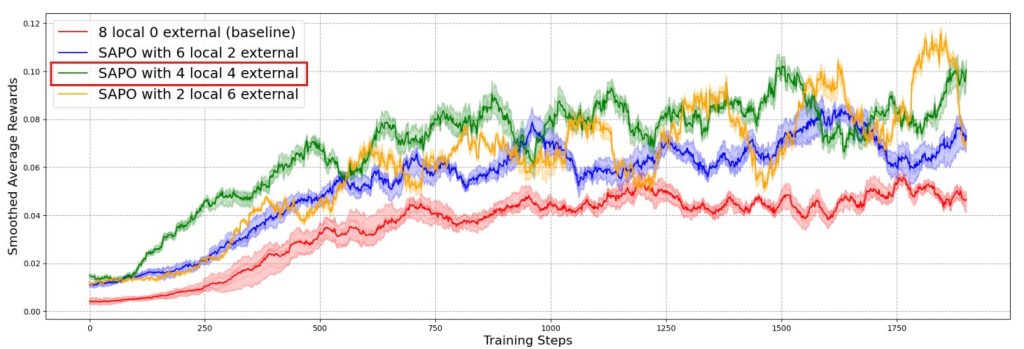
Figure2は、4ローカル / 4外部の構成がベースラインよりも一貫して高い期待平均報酬を達成していることを示しています。また、ほぼすべての訓練ラウンドで、6ローカル / 2外部の構成よりも優れています。2ローカル / 6外部の設定と比較しても、ほとんどのラウンドで4ローカル / 4外部の構成が優れていますが、その差は他のケースよりも小さいです。これらの結果は、経験共有の利点を明確に示しています。つまり、1つのエージェントが「Ahaモーメント」(閃きや効果的な解法)を得ると、それがスウォーム全体に広がり、全体的なパフォーマンスを向上させることができるのです。注目すべきは、この効果がエージェントに特定の役割や異なるモデルを与えなくても現れることです。さらに多様性を追加すれば、スウォーム効果はさらに強まる可能性があり、SAPOの将来の研究において有望な方向性を示唆しています。
一方で、4ローカル / 4外部の構成が2ローカル / 6外部のケースを上回ったことから、外部ロールアウトに過度に依存すると、かえってパフォーマンスが阻害される可能性があることも分かりました。また、ベースラインは変動がはるかに低く、外部ロールアウトの割合が増加するにつれて、振動のレベルも増加していることが分かります。特に2ローカル / 6外部のセットアップは、訓練が進むにつれて強い振動を示しています。
これは、次の2つの興味深いネットワーク効果によるものと解釈されます。
- (i) 高性能なエージェントが外部ロールアウトに過度に依存すると、低性能なエージェントの回答によってその進捗が悪影響を受ける可能性がある。
- (ii) エージェントがスウォームから多くのロールアウトを引き出すにもかかわらず、全体として貢献するロールアウトが少なすぎると、共有プールの品質が低下する。
これらの効果が組み合わさることで、急激な学習と忘却行動が生じ、観察された振動パターンを説明できます。なお、移動平均ウィンドウはタスクレベルの特異性を平滑化するため(Figure1参照)、これらの振動はタスクに関連するランダム性ではなく、意味のある大規模な訓練ダイナミクスを反映していると考えられます。
6. Training in a Large Swarm: Insights from an Open-Source Demo (大規模スウォームでの訓練:オープンソースデモからの洞察)
SAPOをより現実的で異種的な条件下で評価するため、研究チームは大規模なオープンソースデモからデータを収集しました。このデモには、数千ものGensynコミュニティメンバーが参加し、多様なハードウェアとモデル構成で訓練を実行しました。各参加ノードは、訓練されるモデルタイプなどのメタデータと関連付けられた固有のピア識別子を持っていました。
各ラウンド後、ノードは研究チームが管理する「ジャッジ」と以下のやり取りを行いました。
(i) ノードが評価を要求する。
(ii) ジャッジは§4.1で導入されたReasoningGYMタスクのいずれかから質問をランダムにサンプリングしてノードに送信する。
(iii) ノードは質問に回答(pass@1)し、ジャッジに提出する。
(iv) ジャッジは適切なReasoningGYM検証器で回答を採点する。
これらのジャッジ評価の結果を、固有のピア識別子と関連付けて分析することで、スウォーム内で共同訓練されたモデルと単独で訓練されたモデルを比較することができました。その結果、スウォームベースの訓練は測定可能な性能向上をもたらすものの、その効果はモデルに依存することが分かりました。
0.5BパラメータのQwen2.5モデルの場合、スウォームへの参加は、時間の経過とともに単独訓練と比較して累積的なパフォーマンスを一貫して向上させました。Figure3に示すように、統計的テストによって、およそ175正規化ラウンド5以降、スウォームで訓練されたモデルが単独で訓練されたモデルを統計的に有意に上回ることが確認されました。ここでいう「正規化ラウンド」とは、大規模デモのスウォームが一時的な環境であり、ノードが頻繁に出入りしたり、停止・再起動したりしたため、個々のノードが参加した総ラウンド数に基づいて訓練ラウンドを正規化したものです。
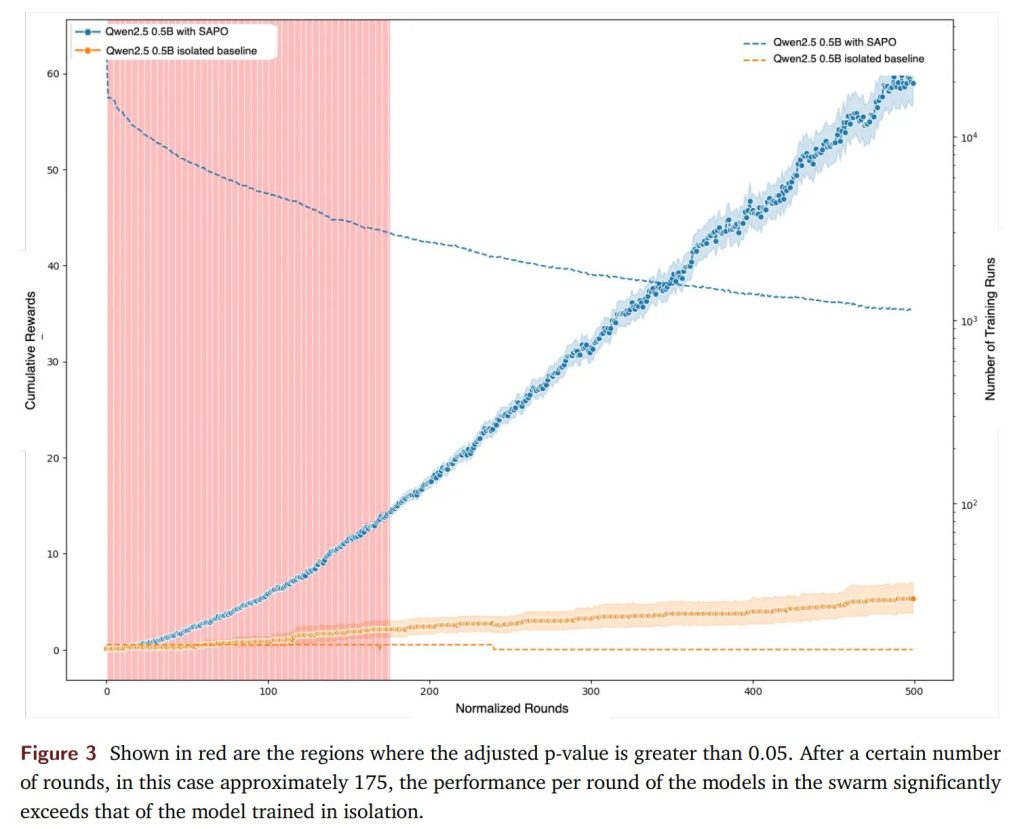
対照的に、0.6BパラメータのQwen3のようなより強力なモデルは、スウォーム内外で同様のパフォーマンスを達成しました。これは、SAPOの恩恵が、多様なロールアウトを積極的に「吸収」して伝播できる中容量モデル(mid-capacity models)で最も顕著であることを示唆しています。
なお、このデモでは、モデルがスウォームからロールアウトを単純な一様ランダムサンプリングで選択し、何のフィルタリングも行いませんでした。これにより、有用な報酬シグナルを持たないロールアウトがスウォーム内で過剰に表現されてしまいました。より良いサンプリング戦略を用いることで、より高性能なモデルもSAPO下でのスウォーム参加から利益を得られる可能性がある、と仮説を立てています。
7. Conclusion (結論)
本論文では、完全に分散型で非同期な強化学習の学習後訓練アルゴリズムであるSAPOを導入しました。SAPOは、多くの集中型アプローチとは異なり、異なる種類のノードが自身のモデルを管理しながらロールアウトを共有することを可能にし、遅延、モデルの均一性、ハードウェアに関する前提なしに、学習をスウォーム全体に広げることができます。
ReasoningGYMデータセットを用いた実験は、バランスの取れた経験共有(4ローカル / 4外部)が、共有なしのベースラインと比較して性能をほぼ倍増させることを示しました。しかし、外部ロールアウトへの過度な依存は学習を不安定にし、急激な学習と忘却行動を引き起こす可能性があることも明らかになりました。全体として、SAPOは経験共有を核となる利点に変え、協調的な学習後訓練を通じてモデルの推論能力を向上させる、スケーラブルで実践的な道筋を提供します。
Future Directions (将来の方向性)
今後の研究では、いくつかの興味深い方向性が考えられます。
- 異種性の深化: §4.1と§5で議論したように、次のステップとして、より大きな異種性(例えば、特殊なタスクや異なる基盤モデル)の下でSAPOを評価することが自然です。§6では、いくつかの異なる基盤モデルが大規模スウォームに参加する予備結果を示しましたが、より体系的な研究が必要です。
- 非伝統的なポリシーの参加: これらの異種性の探求を極限まで進めると、§3で述べたように、非伝統的な非訓練ポリシー(例えば、人間)がスウォーム内でジェネレーターとして機能する影響を探ることが興味深いでしょう。誠実な貢献を促す適切なインセンティブメカニズムが導入されれば、この可能性はさらに広がります。
- 安定性の向上: 外部ロールアウトへの過度な依存は、しばしば学習の振動や忘却を引き起こすため、安定性の問題は依然として重要な未解決の課題です。報酬ガイド付き共有、RLHF、または生成的検証器(Zhang et al., 2025)とSAPOを統合するハイブリッドアプローチが、この問題の解決に役立つかもしれません。
- メタ戦略の開発: これらのハイブリッドアプローチを補完するものとして、特に信頼が前提とされない大規模なスウォーム設定において、ローカルと共有ロールアウトのバランスを適応的に調整したり、スウォームサンプルを戦略的にフィルタリングしたりするためのメタ戦略を開発することが有望な方向性です。
- マルチモーダルな応用: 本論文の焦点は言語モデルでしたが、SAPOはデータモダリティに依存せず、非常に一般的に適用可能です。マルチモーダルなSAPOの応用は、従来の単一エージェント学習では想像しにくい、興味深い方向性を示唆しています。例えば、画像ベースのスウォームでは、個々のノードが個人的な「美的感覚」をコード化したローカル報酬メカニズムを定義し、それが他のノードの報酬メカニズムによって「良い」と判断されれば、スウォーム内の他のモデルが生成する画像のスタイルに間接的に影響を与える好循環を生み出す可能性があります。
より広く言えば、SAPOのようなマルチエージェント経験共有アルゴリズムは、異種モデル間での独自の自己組織化フィードバックループを活用するように設計された新しい学習パラダイムを探求することを可能にします。
まとめ
この論文で紹介されたSAPO(Swarm sAmpling Policy Optimization)は、従来の強化学習における同期型システムの限界を打破する可能性を秘めたアプローチです。各計算ノードが独立してモデルを訓練しながら学習経験を共有することで、通信ボトルネックや高コストといった課題を解決し、最大94%の性能向上を実現しました。
特に注目すべきは、一つのノードが獲得した「Ahaモーメント」がスウォーム全体に瞬時に伝播し、集合的な知能を創発する点です。このような分散型協調学習は、リソースに制約のある環境でも高性能なモデル開発を可能にする新たなパラダイムとして、今後の AI研究に大きな影響を与えることが期待されます。








