
はじめに
近年、目覚ましい発展を遂げるAI(人工知能)は、医療分野においてもその活用が期待されています。本稿では、Googleが研究開発を進める対話型診断AI「AMIE」に、医師による監督機能を組み込んだ新しい研究システム「g-AMIE」について、解説します。AIが医師の「右腕」として機能する未来像に迫ります。
参考記事
- タイトル: Enabling physician-centered oversight for AMIE
- 発行元: Google Research
- 発行日: 2025年8月12日
- URL: https://research.google/blog/enabling-physician-centered-oversight-for-amie/
要点
- Googleは、対話型診断AI「AMIE」に医師の監督機能を統合した研究システム「g-AMIE」を開発した。
- g-AMIEは、患者に直接的な医療アドバイス(診断や治療計画)を行わないガードレール機能を持つ。その役割は、対話による問診と情報収集に特化している。
- 収集された情報は、医師がレビューするためのSOAPノート形式の要約、鑑別診断案、治療計画案として生成される。
- 医師は「クリニシャン・コックピット」と呼ばれる専用インターフェースを通じて、非同期で内容を確認・編集し、最終的な意思決定を行う。
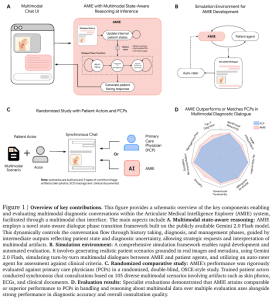
- 仮想臨床試験(OSCE)において、g-AMIEは同じ制約下の臨床医(プライマリケア医、ナースプラクティショナー等)と比較して、問診の質、診断の正確性、記録の質において高い評価を得た。
- これはAIと医師の協業における重要な一歩であるが、臨床医がこの特殊なワークフローに習熟していない点など、結果の解釈には注意が必要である。
詳細解説
なぜ「医師の監督」が必要なのか?
Googleが以前に発表した対話型AI「AMIE」は、テキストベースの対話で高い診断精度を示し、大きな注目を集めました。しかし、実際の医療現場では、患者の診断や治療計画の決定は、法律に基づき免許を持つ医療専門家が行わなければならない、極めて専門的で責任の重い行為です。AIがどれだけ高性能であっても、単独で最終的な医療判断を下すことは許されません。
そこでGoogleの研究者たちは、医療現場で既に行われている「監督(Oversight)」という考え方に着目しました。例えば、経験豊富な指導医が研修医の診療を監督し、最終的な責任を負う体制です。この「人間の専門家による監督」という枠組みをAIに適用することで、AIの能力を安全に活用しようというのが、今回の「g-AMIE」研究の出発点です。
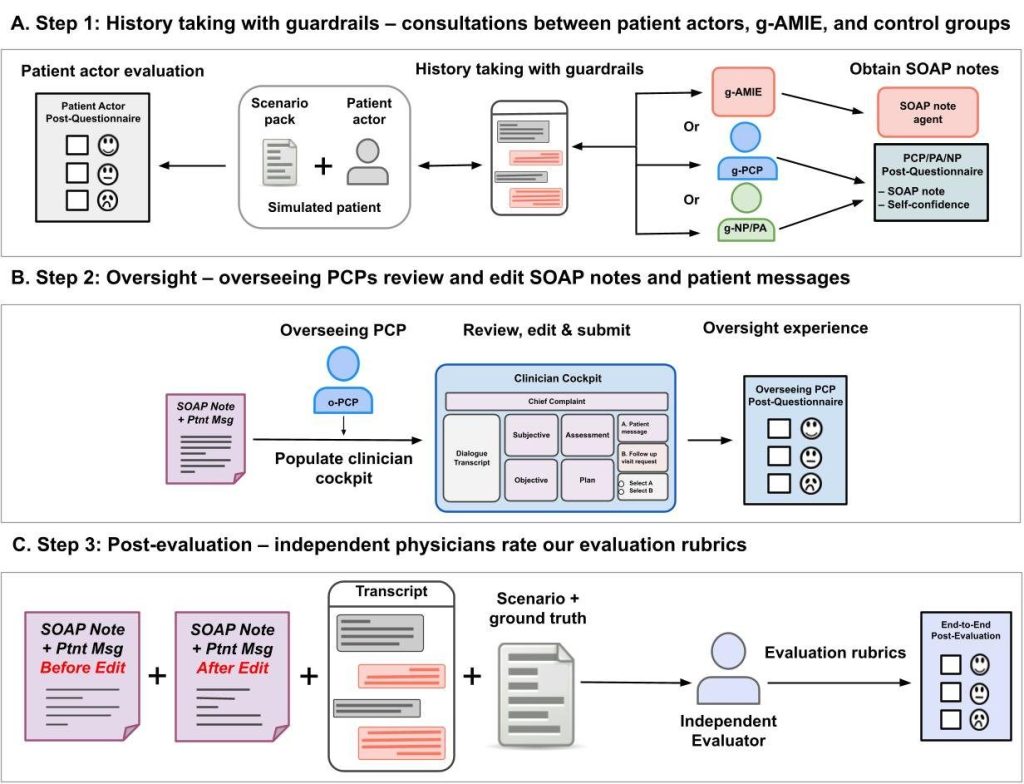
g-AMIEの仕組み:安全性を確保する「非同期監督フレームワーク」
g-AMIEの最大の特徴は、「問診(情報収集)」と「医療判断(意思決定)」を明確に分離している点です。
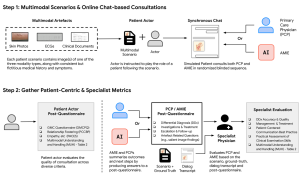
1. g-AMIE(または比較対象の臨床医)が、医療アドバイスをせずに患者役から問診を行う。
2. 問診内容を基に、SOAPノートと鑑別診断案などを作成。
3. 監督医が「クリニシャン・コックピット」で内容をレビュー・編集する。
4. 監督医が最終的な判断を下し、患者に返信する。
g-AMIEはまず患者(この研究では模擬患者)と対話し、症状などの情報を集めることに徹します。この際、「ガードレール」と呼ばれる制約により、診断名を示唆したり、治療法を提案したりといった個別の医療アドバイスを患者に直接伝えることは固く禁じられています。
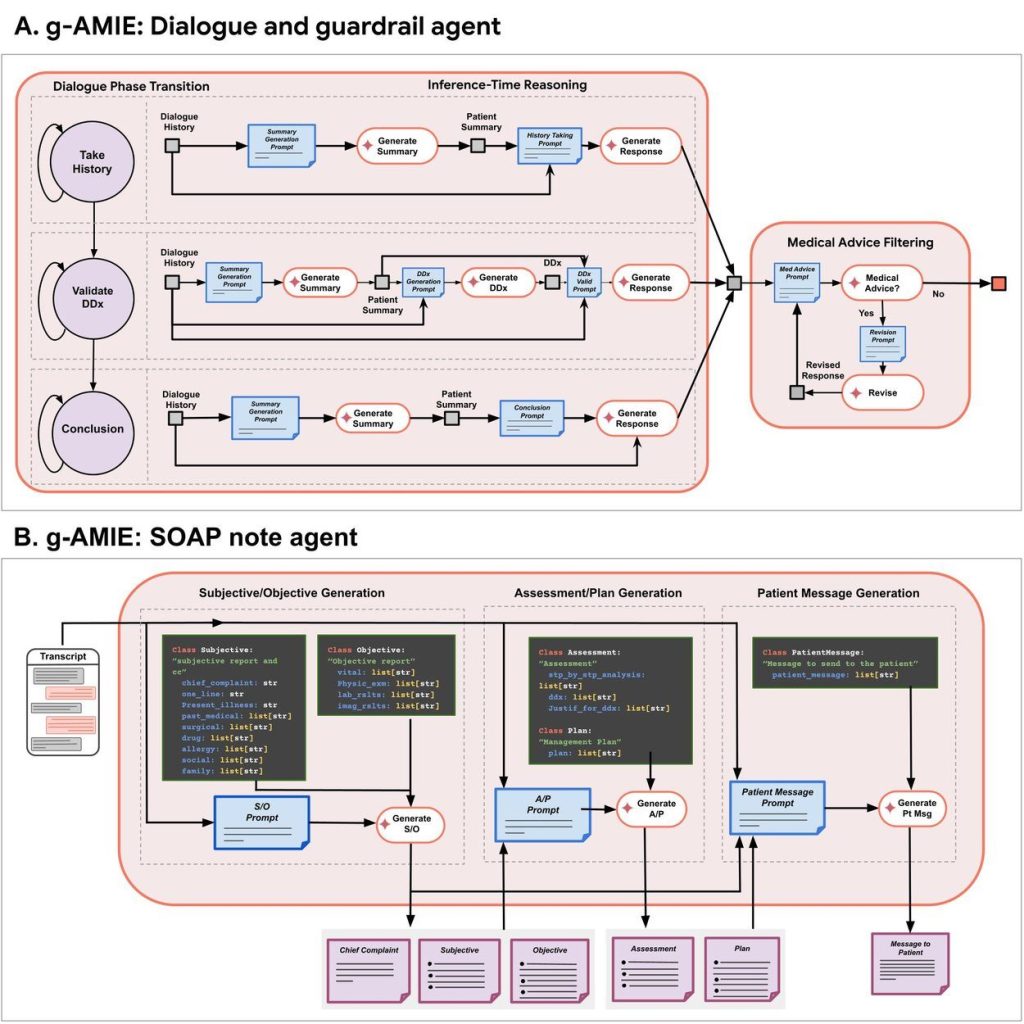
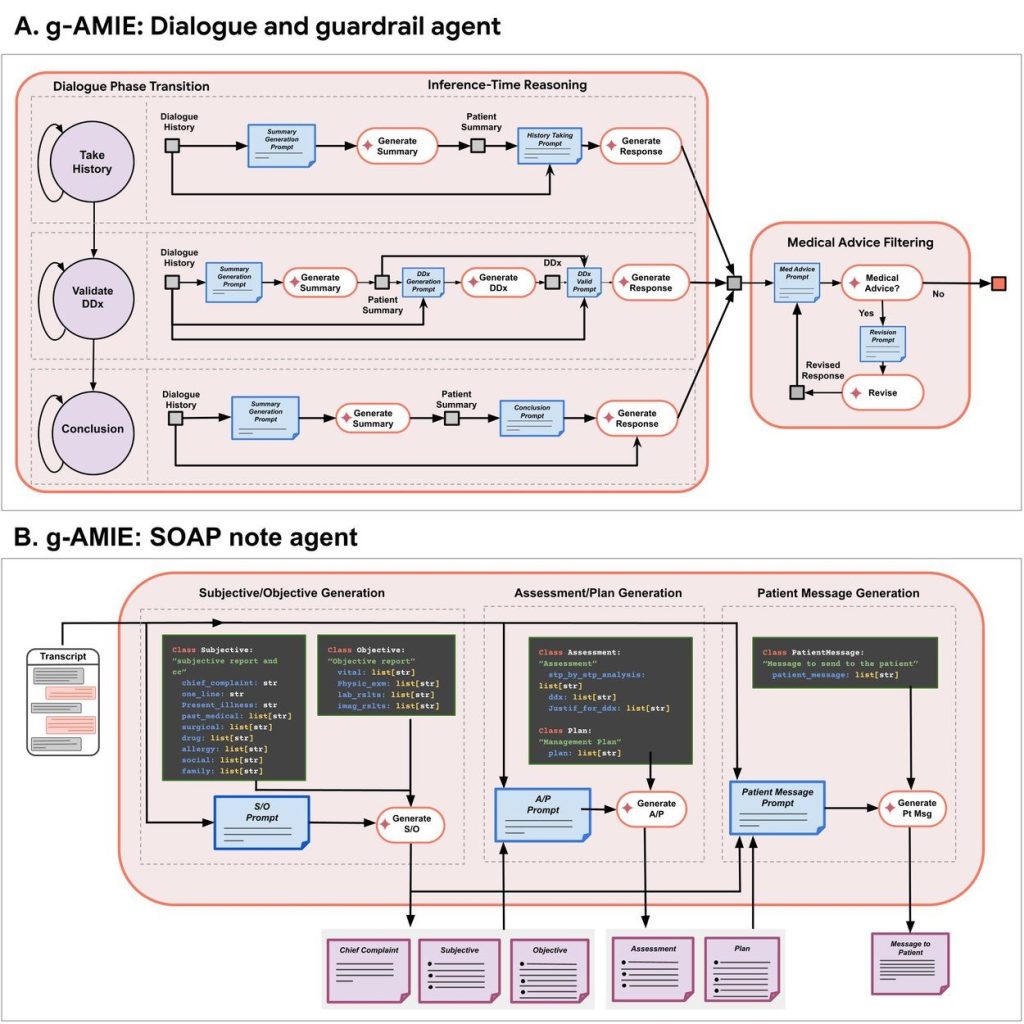
問診が終わると、g-AMIEは収集した情報を基に、医療現場で標準的に用いられる「SOAPノート」という形式で要約を作成します。これには、考えられる病気のリスト(鑑別診断)や治療計画の案も含まれます。
そして、このSOAPノートを、監督役の医師が「クリニシャン・コックピット」という専用のウェブ画面で確認します。医師は内容をレビューし、必要に応じて加筆・修正を行い、最終的な診断と治療方針を決定して患者に伝えます。問診とレビューが別の時間に行える「非同期」であるため、医師は自分の都合の良いタイミングで、じっくりと内容を吟味することができます。
技術的な心臓部:3つの役割を持つエージェントシステム
この一連の流れを実現するため、g-AMIEの内部は3つの異なる役割を持つAIエージェントで構成されています。
- 対話エージェント: 患者から共感的に話を聞き出し、必要な医学情報を効率的に収集する役割を担います。
- ガードレールエージェント: 対話エージェントが生成する返答を常に監視し、医療アドバイスにあたる表現が含まれていないかをチェックする「門番」の役割を果たします。もし不適切な表現があれば、安全な言い回しに修正します。
- SOAPノートエージェント: 対話の全記録から、要約(主観的・客観的情報)、推論(評価・計画)、患者へのメッセージ案を構造的に生成する役割を担います。
性能評価:g-AMIEは人間を上回ったのか?
研究チームは、g-AMIEの性能を客観的に評価するため、「仮想OSCE(客観的臨床能力試験)」という手法を用いました。これは、模擬患者を相手に、g-AMIEと、比較対象となる人間の医療専門家(プライマリケア医、ナースプラクティショナーなど)が、全く同じ「ガードレール」の制約下で問診を行うという実験です。
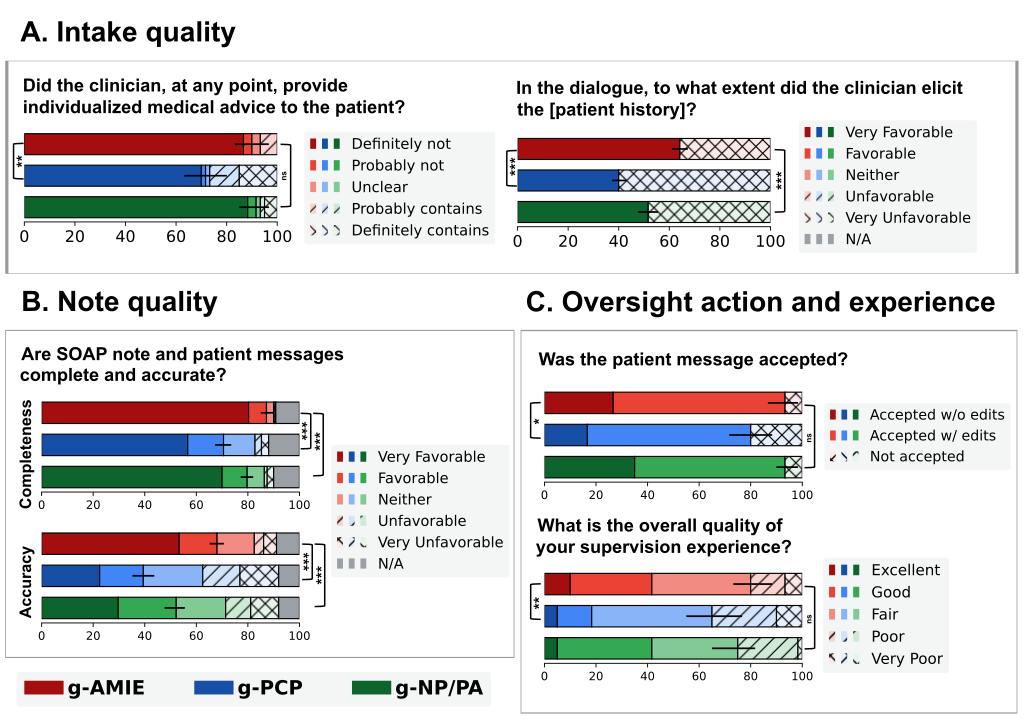
その結果は非常に興味深いものでした。独立した医師による評価において、g-AMIEは多くの項目で人間の専門家グループを上回る評価を受けました。具体的には、診断の正確性、治療計画の適切さ、患者からの情報収集能力、記録の質、そして共感性といった点で、より優れていると判断されたのです。また、監督役の医師たちも、g-AMIEが作成したレポートの方が監督しやすく、g-AMIEが作成した患者へのメッセージを承認する割合が高い、と評価しました。
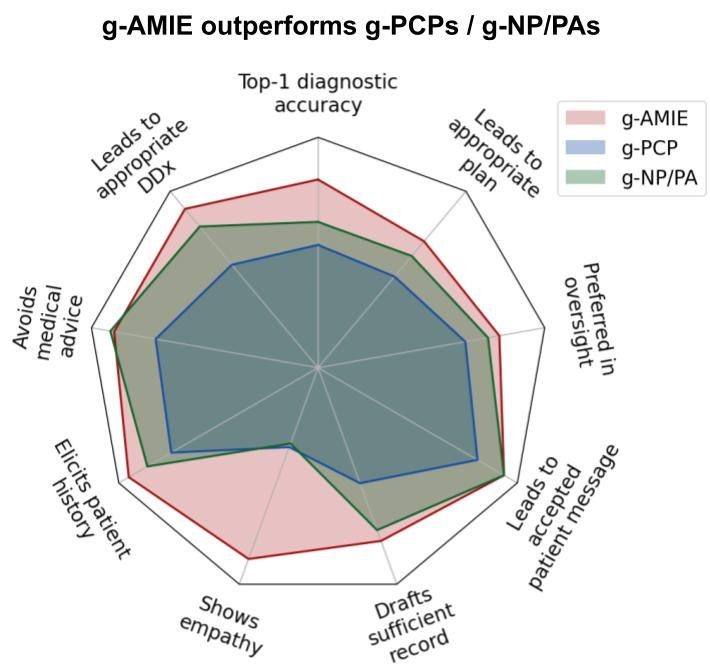
g-AMIE(赤)が、g-PCP(青)やg-NP/PA(緑)と比較して、多くの評価項目で高いスコアを示している。
結果をどう解釈すべきか?重要な注意点
この結果だけを見ると「AIが人間を超えた」と捉えられがちですが、研究チームは慎重な解釈を促しています。最も重要な点は、この実験はAIと人間の能力を単純に比較するものではないということです。
人間の臨床医、特に医師は、通常、診断仮説を立てながら問診を進めるように訓練されています。医療アドバイスを完全に制限されるという今回の実験環境は、彼らにとって非常に不自然で、能力を発揮しにくい状況だった可能性があります。
また、g-AMIEが生成する記録は、人間よりも詳細で冗長(長すぎる)な傾向があり、これが監督医の確認時間を増やすという課題も指摘されています。
したがって、この結果は「AIが医師に取って代わる」ことを示すのではなく、「医師の監督」という安全な枠組みの下で、AIが医師の診断業務を質の高いレベルで支援できるツールになる可能性を示したものと解釈するのが適切です。
まとめ
本稿では、Googleが開発した医師監督下の対話型診断AI「g-AMIE」について解説しました。
g-AMIEは、ガードレール機能によって安全性を確保しつつ、質の高い問診と医療記録の作成を行います。そして、医師は「クリニシャン・コックピット」を通じてAIの生成した情報を監督・修正し、最終的な診断と治療の責任を負います。
この「問診の分業」と「非同期での監督」という新しい協業モデルは、医師の認知的な負担を軽減し、より多くの患者に質の高い医療を届ける一助となる可能性を秘めています。
もちろん、実用化に向けては、AIが生成する情報の冗長性の改善や、実際の臨床現場でのさらなる検証など、多くの課題が残されています。しかし、本研究は、AIを医療現場で責任ある形で活用していくための、具体的で重要な一歩を示していると言えるでしょう。








