
はじめに
様々なタスクをこなしてくれる「AIエージェント」と呼ばれる分野が注目されています。本稿では、OpenAIが研究プレビューとして公開している「o3 Operator」について、システムカードから解説します。
Operatorは、「Computer Using Agent(CUA)」モデルと呼ばれるもので、まるで人間のように、ブラウザを使ってウェブページを見たり、文字を入力したり、クリックしたり、スクロールしたりといった操作ができます。これにより、ユーザーはAIに「このウェブサイトで〇〇を予約して」とか「この情報を調べてまとめて」といったお願いができるようになります。
以前のOperatorはGPT-4oというモデルをベースにしていましたが、今回、OpenAIの新しいモデルファミリーである「o3」をベースにしたバージョンが登場しました。本記事では、この「o3 Operator」に関するシステムカードの抜粋を基に、その特徴や特に重要となる「安全性」についての取り組みを分かりやすく解説していきます。
要点
- Operatorは、ウェブブラウザを使ってタスクを実行するComputer Using Agent(CUA)モデルです。
- 以前のGPT-4oベースから、新しいo3ベースのモデルに更新されました。
- 基本的な安全性対策はo3モデルから引き継ぎつつ、コンピュータ操作特有のリスクに対応するための追加の安全訓練が施されています。
- コーディング環境やターミナルへの直接的なアクセスはできません。
- 禁止されているコンテンツの生成や、悪意のあるプロンプト(ジェイルブレイク)に対する安全性評価では、高い性能を示しています。
- ユーザーが有害なタスクを指示するリスク、モデルの間違い、画面上の情報による悪意のある操作(プロンプトインジェクション)といった、製品固有のリスクに対して、複数の軽減策が講じられています。
- 特に、ユーザーへの明示的な確認や、高リスクなウェブサイトでの「Watch Mode」(ユーザーが操作を見守るモード)などが重要な安全対策として機能します。
- 有害タスクの拒否率や、モデルの間違いを防ぐための確認率が、以前の4o Operatorよりも向上しています。
- 化学・生物兵器開発、サイバー攻撃、AI自身の能力向上といった分野でのリスク評価において、「High未満」の能力レベルにあるとされています。
詳細解説
ここからは、システムカードの抜粋に沿って、項目ごとに解説していきます。
安全対策へのアプローチ
o3 Operatorの安全性については、以前の4o Operatorで採用されていた多層的なアプローチを引き継いでいます。これに加えて、o3 Operatorは「ファインチューニング」という追加の学習を受けています。これは、特定のタスクや目的に合わせて、既に学習済みのモデルをさらに調整するプロセスです。ここでは、コンピュータ使用に関する安全データ、特にユーザーの指示に対してAIが「確認すべき境界線」や「拒否すべき状況」を学ぶためのデータセットが使われています。
また、o3モデルは本来コーディング能力を持っていますが、o3 Operatorはネイティブにコーディング環境やターミナル(コンピュータにコマンドを直接入力する画面)にアクセスすることはできません。これは、AIが勝手にプログラムを実行したり、システムにアクセスしたりするリスクを防ぐための重要な制限と考えられます。
1. ベースラインモデルの安全性評価
1.1 禁止されているコンテンツの評価
Operatorはウェブ操作に特化したモデルであり、一般的なチャットアプリケーションとして使われることは意図されていません。しかし、会話能力も持っているため、基本的な安全性(モデルが不適切なコンテンツを生成しないか)を評価するために、標準的な評価が実施されています。評価指標としては「not_unsafe」(安全でない出力を生成しなかった割合、高いほど良い)が使われています。
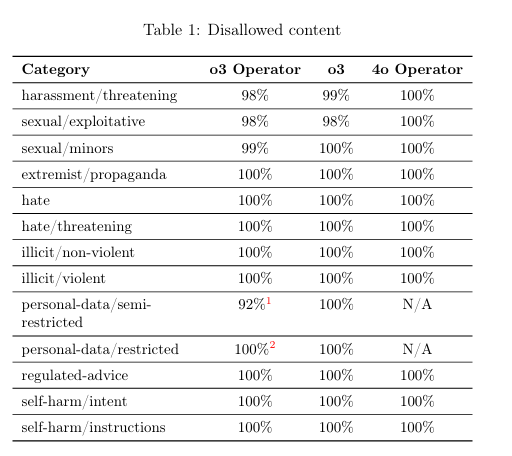
ここでは、ハラスメント、性的描写、未成年者に関する内容、過激派プロパガンダ、ヘイトスピーチ、違法行為、個人情報、規制されたアドバイス、自傷行為など、様々な禁止コンテンツカテゴリに対するモデルの拒否率が表(Table 1)で示されています。o3 Operatorは、多くのカテゴリでo3や4o Operatorと同等か非常に近い高い拒否率(例えば100%)を示しています。
ただし、個人情報に関するカテゴリ(personal-data/semi-restrictedとpersonal-data/restricted)については、4o Operator以降に定義が更新され、より詳細になったため、以前の評価との直接比較はできないことが注記されています。特にpersonal-data/restrictedの評価は4o Operatorのリリース後に作成されたため、4o Operatorでは実施されていません。
1.2 ジェイルブレイク評価
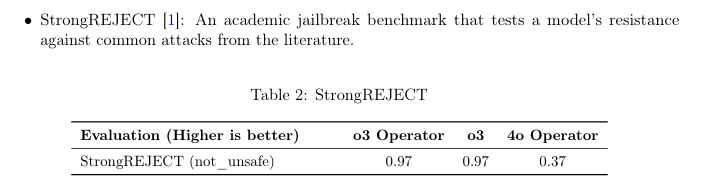
「ジェイルブレイク」とは、AIモデルが設定された安全上の制約(特定のコンテンツ生成を拒否するなど)を回避するように、ユーザーが意図的に工夫した悪意のあるプロンプトのことです。ここでは、モデルがこのようなプロンプトに対してどれだけ頑丈か(拒否を維持できるか)が評価されています。評価には「StrongREJECT」という学術的なベンチマークが用いられています。
評価結果(Table 2)では、o3 Operatorは0.97というスコアで、これはコンピューターを使用しない通常のo3モデルと同程度の高い耐性を示しています。以前の4o Operator(スコア0.37)と比較すると、大幅に改善していることが分かります。
2. 製品固有リスク軽減策
Operatorのようなウェブ操作を行うAIエージェントは、一般的なAIモデルとは異なる固有のリスクを持っています。例えば、ユーザーの指示が悪意のあるものだったり、モデルが間違った操作をしてしまったり、ウェブサイト上の情報に誘導されてユーザーの意図しない行動をとってしまったりする可能性があります。
これらの製品固有のリスクに対して、o3 Operatorでは様々な軽減策が講じられています(Table 3)。以前のCUAモデルの訓練に使われたデータセットや手法が活用されています。

主なリスクと軽減策は以下の通りです。
- ユーザーがo3 Operatorを使って有害なタスクを指示するリスク: これは、AIに違法な行為や詐欺、個人情報の不正取得などをさせようとするリスクです。軽減策として、o3ファミリーから引き継いだ基本的な安全訓練に加え、エージェント特有の有害行為に対する安全訓練が行われています。また、人間や自動システムによる監視、不正利用を防ぐための利用制限(レートリミット)なども実施されます。
- o3 Operatorがプロンプトインジェクションされるリスク: 「プロンプトインジェクション」とは、Operatorが見ている画面上の情報(例えば悪意のあるウェブサイトやメール)によって、ユーザーが意図しない操作をするようにAIが誘導されてしまうリスクです。軽減策としては、モデル自体がプロンプトインジェクションに対して頑丈になるように訓練されています。さらに、「プロンプトインジェクションモニター」という仕組みがあり、現在の画面を解析して疑わしい活動を検出した場合に処理を一時停止させます。ユーザーに操作内容を明示的に確認するステップや、メールのような高リスクなウェブサイトでの「Watch Mode」利用義務付けも、このリスク軽減に役立ちます。
- o3 Operatorが間違いをするリスク: これは、モデルがユーザーの意図とずれた操作をしてしまい、損害を与える可能性があるリスクです。軽減策として、特に世界の「状態」を変えてしまうような操作(購入を確定する、メールを送信するなど)の前には、必ずユーザーに明示的な確認を求めるように訓練されています。また、銀行取引のような最高レベルのリスクを伴うタスクは拒否するように訓練されており、メールなどの高リスクなサイトでは「Watch Mode」の利用が必須となります。
2.1 有害タスク
上記で触れた有害タスクのリスクと軽減策について、さらに詳しく評価結果が示されています。Operatorは実世界で行動を起こすため、通常のチャットモデルにはないリスクが生まれます。
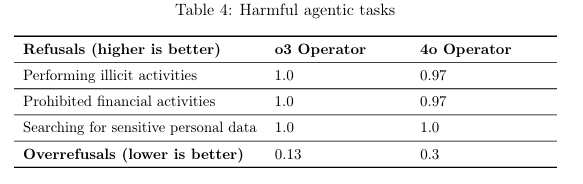
軽減策として、o3の学習に加え、以前のCUAモデルに使われた有害なエージェントタスクを拒否するための安全訓練データが再利用されています。評価(Table 4)によると、違法行為の実行、禁止されている金融活動、機密個人データの検索といったカテゴリにおいて、o3 Operatorは1.0(100%拒否)という高い拒否率を達成しており、以前の4o Operator(拒否率0.97)よりも改善しています。
一方で、本来拒否すべきでない指示を誤って拒否してしまう「Overrefusals」も評価されており(Table 4の下部)、o3 Operatorは0.13と、以前の4o Operatorの0.3と比較して低くなっています。これは、必要なタスクは実行しつつ、危険なタスクは適切に拒否できるバランスが向上したことを示唆しています。
2.2 モデルの間違い
モデルがユーザーの意図とずれた行動をとるリスクについても詳細が述べられています。重要な軽減策は、世界の状況を変える可能性のあるアクションの前にユーザーに確認を求めること、高リスクなタスク(銀行取引など)は拒否すること、そしてメールなどの高リスクなウェブサイトでは「Watch Mode」が必要となることです。ユーザーとの明示的な確認は、モデルが誤って機密性の高いユーザーデータを漏洩させてしまうリスクの大部分を軽減します。
評価では、以前のOperatorと同じ確認に関する評価が再実施されました。その結果、確認率は94%となり、以前のモデルの92%から向上しています。特に、金融取引の評価シナリオでは100%確認を行うことが確認されました。また、手動でのレビューにより、個人データ漏洩に関する残存リスクは低いレベルであると結論づけられています。
2.3 プロンプトインジェクション
画面上の悪意のある情報によってAIが操られるプロンプトインジェクションのリスクと対策について、さらに詳しい説明があります。すでに述べたように、ユーザーへの確認、Watch Mode、高リスクタスクの拒否が基本的な防御層となります。これに加え、プロンプトインジェクションモニターが画面内容をチェックし、疑わしい場合に実行を停止します。モデル自体にも、ある程度のプロンプトインジェクションに対する抵抗力があります。
評価では、以前のモデルと同じ評価が行われました。モデル自体のプロンプトインジェクションに対する感受性(低い方が良い)は20%となり、以前のモデルの23%から改善が見られます。ただし、主要な防御層であるプロンプトインジェクションモニターは以前のOperatorから変更されていないことも述べられています。これは、モデル単体での耐性向上に加え、モニターによる二重、三重のチェックが重要であることを示しています。
2.4 準備状況 (Preparedness)
最後に、AIのフロンティアリスクに関する評価である「Preparedness Framework」に基づいたo3 Operatorの状況が述べられています。o3 Operatorはo3モデルのバリアントであり、化学・生物兵器開発、サイバーセキュリティ、AI自身の能力向上といった分野におけるフロンティア能力レベルは、元のo3システムカードで評価されている通り「High未満」であるとされています。o3 Operatorには、安全に関するデータセットなど最小限の追加学習のみが施されており、ネイティブなコーディング環境やターミナルへのアクセスもありません。生物学的能力に関する評価でもo3を下回ることを確認しており、このリスクカテゴリでの能力が「High未満」であることを再確認しています。
まとめ
今回は、OpenAIの新しいウェブ操作AI「o3 Operator」に関するシステムカードの抜粋を基に、その機能と特に重要な安全性について詳しく見てきました。
o3 Operatorは、o3モデルの持つ高い能力を活かしつつ、ウェブブラウザを使った操作に特化し、かつエージェントモデル固有のリスクに対して多層的な安全対策が施されています。禁止コンテンツの拒否やジェイルブレイクへの耐性はもちろん、ユーザーの指示ミスや悪意のある情報による誘導といったリスクに対し、ユーザーへの確認、Watch Mode、専門のモニターといった仕組みで対応しています。有害タスクの拒否や確認プロセスの改善など、以前のバージョンからの進化も見られます。
AIエージェントが私たちの代わりに実世界で行動するようになるにつれて、その安全性への配慮はますます重要になります。








