
はじめに
OpenAIは、大規模言語モデル(LLM)の安全性と適切な使用を確保するために、継続的に研究とモデル開発を行っています。本稿で解説する技術レポートは、オープンソースコミュニティからのフィードバックを受けて開発された、オープンウェイトの推論モデル「gpt-oss-safeguard-120b」と「gpt-oss-safeguard-20b」の性能と安全性の評価について詳述しています。
オープンウェイトモデルとは、モデルの重み(パラメーター)が公開されており、ライセンスに基づき誰でも利用やカスタマイズが可能なモデルのことです。gpt-oss-safeguardモデルは、Apache 2.0ライセンスのもとで利用可能であり、カスタマイズ性、フルChain-of-Thought(思考の連鎖)の提供、異なる推論レベルの利用、構造化出力といった特徴を持っています。
これらのモデルは、元の「gpt-oss」モデル群からポストトレーニング(追加訓練)されており、提供されたポリシー(利用規約や安全基準など)に基づいて、入力コンテンツがそのポリシーに違反しているかどうかを判断し、分類・ラベリングするために特化して設計されています。
本稿では、これらのセーフガードモデルの機能、ベースラインとなる安全性評価の結果、そして多言語性能や潜在的な課題に対する取り組みについて、レポートの内容を解説します。
解説論文
- 論文タイトル:Technical Report: Performance and baseline evaluations of gpt-oss-safeguard-120b and gpt-oss-safeguard-20b
- 論文URL:
- https://cdn.openai.com/pdf/08b7dee4-8bc6-4955-a219-7793fb69090c/Technical_report__Research_Preview_of_gpt_oss_safeguard.pdf
- 発行日:2025年10月29日
- 発表者:OpenAI
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- gpt-oss-safeguard-120bおよびgpt-oss-safeguard-20bは、提供されたポリシーに基づきコンテンツを分類するために特別に訓練されたオープンウェイトの推論モデルである。
- これらのモデルは、エンドユーザーとの直接対話には推奨されておらず、主な推奨用途はコンテンツ分類の機能である。
- 厳しいマルチポリシー精度の内部評価において、gpt-oss-safeguardモデルは、gpt-5-thinkingや元の gpt-oss モデルよりも高い性能を示した。
- 計算資源を多く消費するため(time and compute-intensive)、プラットフォーム全体のコンテンツへのスケーリングが困難であるという制限事項が指摘されている。
- ジェイルブレイク(モデルの拒否を回避しようとする敵対的プロンプト)に対するロバスト性評価では、120bモデルは改善したが、20bモデルは元のモデルに比べてわずかに性能が低下した。
- 公平性とバイアスに関する評価(BBQ評価)では、gpt-oss-safeguardモデルは、元の gpt-oss モデルをすべてのメトリクスで上回る結果を示した。
詳細解説
論文の構成に沿って詳細に説明いたします。
1 Introduction (はじめに)
gpt-oss-safeguard-120bとgpt-oss-safeguard-20bは、元の「gpt-oss」モデル群から追加学習(ポストトレーニング)された、オープンウェイトの推論モデルです。これらのモデルは、入力されたポリシーに基づいてコンテンツのラベリングを行うために訓練されています。ライセンスはApache 2.0で提供されており、OpenAIのResponses APIと互換性があります。主な機能として、推論プロセスをすべて出力するフルChain-of-Thought (CoT)、カスタマイズ性、異なる推論努力レベル(低、中、高)の利用、および構造化された出力のサポートが挙げられます。
本モデル群は、エンドユーザーとの直接対話用ではなく、提供されたポリシーに対するコンテンツ分類に使用することが推奨されています。レポートに記載されている安全性評価は、オープンモデルであるために起こり得る、推奨されないチャット設定での利用を想定したベースライン検証の結果です。また、これらのモデルは、元の gpt-oss モデルと比べて、追加の生物学的またはサイバーセキュリティデータなしでトレーニングされているため、元の gpt-oss リリースで推定された最悪のシナリオ推定が引き続き適用されるとされています。
2 Safety Classification Performance (安全分類性能)
gpt-oss-safeguardモデルの性能は、内部および外部の評価セットで評価されました。
内部評価
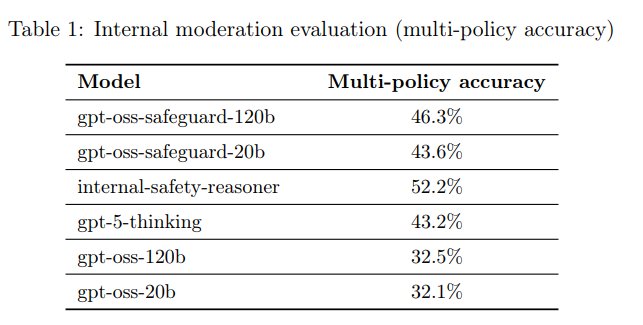
モデルに対して複数のポリシーを同時に提供し、テスト入力テキストがすべてのポリシーの下で「ゴールデンセット(正解ラベル)」と完全に一致する場合にのみ「正確」と見なすという、難しいタスクが実施されました。
このマルチポリシー精度(Multi-policy accuracy)の結果、gpt-oss-safeguard-120b(46.3%)とgpt-oss-safeguard-20b(43.6%)は、gpt-5-thinking(43.2%)や元の gpt-oss モデル(120b: 32.5%, 20b: 32.1%)を上回る結果を示しました。特に、比較的小さいサイズであるにもかかわらず gpt-5-thinking を凌駕した点は特筆すべきです。ただし、OpenAIの内部Safety Reasoner(52.2%)が最も高い精度を達成しています。
外部評価
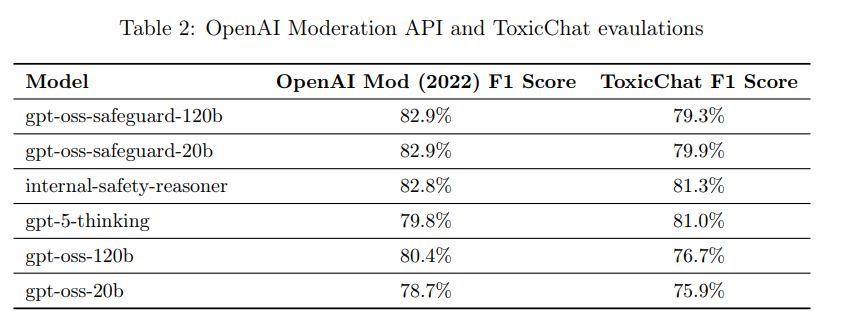
2022年モデレーションデータセットと、公開ベンチマークであるToxicChatが使用されました。2022年モデレーション評価セットでは、gpt-oss-safeguardモデル(F1スコア82.9%)は、内部Safety Reasonerやgpt-5-thinkingを含む他のモデルをわずかに上回りましたが、その差は統計的に有意ではありませんでした。ToxicChat評価では、Safety Reasonerとgpt-5-thinkingが gpt-oss-safeguard モデルをわずかに上回りましたが、モデルサイズを考慮すると、gpt-oss-safeguard が依然としてこの種のタスクに適していると見られています。
2.1 Limitations (制限事項)
gpt-oss-safeguardには二つの具体的な制限が観察されています。
一つ目は、数万件の高品質なラベル付きサンプルで訓練された専用の分類器の方が、複雑なリスク分類において、ポリシーから直接推論する gpt-oss-safeguard よりも優れた性能を発揮する可能性があることです。高性能が要求される場合は、専用分類器の訓練が選択される可能性があります。
二つ目は、gpt-oss-safeguard が時間と計算資源を多く消費する(time and compute-intensive)点です。これにより、プラットフォーム全体のコンテンツにわたってモデルをスケーリング(適用)することが困難になります。OpenAIの内部では、(1) より小型で高速な分類器を使って評価対象を絞り込むこと、(2) Safety Reasoner を非同期で使用することで、ユーザー体験の遅延を抑えつつ、安全でないコンテンツを検出した際には介入できる仕組みを採用しています。
3 Multilingual Performance (多言語性能)
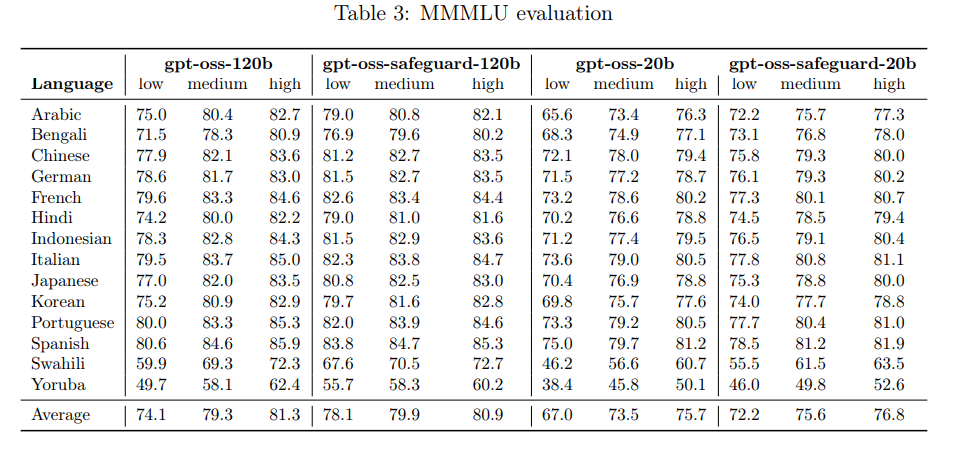
多言語機能の評価は、MMLU(Massive Multitask Language Understanding)評価セットを14言語に翻訳したMMMLU評価セット を用いて行われました。
評価の結果、gpt-oss-safeguardモデルは、すべての推論レベルにおいて、元の gpt-oss モデルと同等の性能を発揮することが確認されました。この評価はチャット設定での性能を示しており、ポリシーを提供した際のコンテンツ分類性能を直接評価するものではない点にご留意ください。例えば、日本語の平均スコア(全推論レベル)では、gpt-oss-120bの79.5%に対して、gpt-oss-safeguard-120bは82.1%でした。
4 Observed safety challenges and mitigations (観察された安全性の課題と緩和策)
このセクションで評価される指標は、モデルが推奨されない「エンドユースチャット」として使用された場合の、ベースラインの安全スコアを示しています。
4.1 Disallowed content (禁止されたコンテンツ)
モデルがOpenAIの安全ポリシーで禁止されているコンテンツ(憎悪的コンテンツ、違法なアドバイスなど)の要求に応じないことを確認する評価です。
従来のStandard Disallowed Content Evaluationsは、最新モデルの性能が飽和してしまい、安全性の進歩を測る指標として機能しなくなったため、今後公開停止予定です。
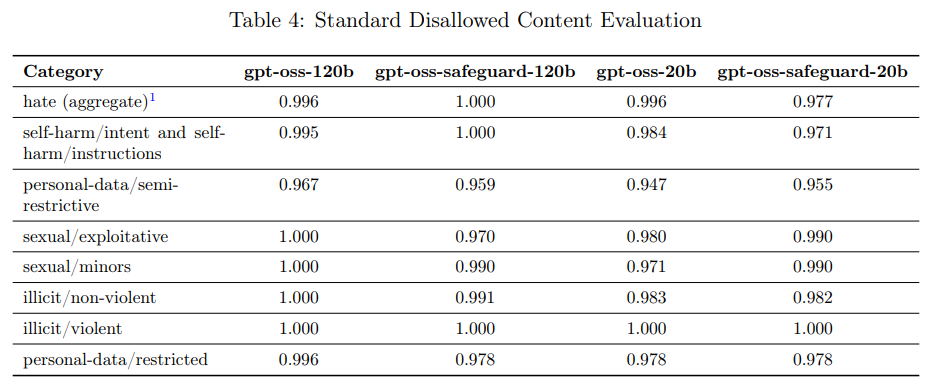
代わりに、より挑戦的なProduction Benchmarks(プロダクションベンチマーク)が使用されています。これは、実際のプロダクションデータに近く、マルチターンで複雑な会話を含む新しい評価セットです。
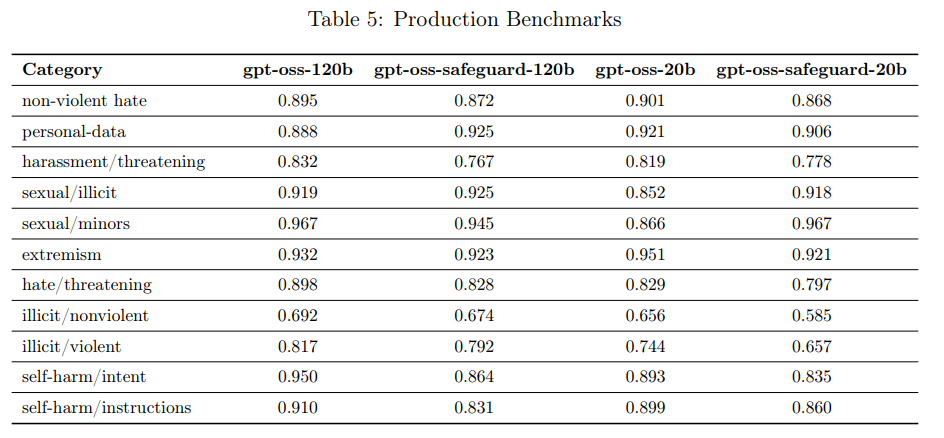
評価指標は、LLMベースのグレーディングモデルを使用し、モデルが関連ポリシーに従って「安全でない出力を生成しなかった」(not_unsafe)かどうかを測定します。評価の結果、gpt-oss-safeguardモデルは、元の gpt-oss モデルとおおむね同等の性能を示し、標準評価では1〜3ポイント差に収まりました。プロダクションベンチマークでは、一部のカテゴリでわずかに性能が低下したものの、他のカテゴリでは gpt-oss モデルを上回る結果も観察されています。
4.2 Jailbreaks (ジェイルブレイク)
ジェイルブレイクとは、モデルが生成を拒否するよう設計されているコンテンツを、敵対的なプロンプトを通じて意図的に回避させようとする行為です。gpt-oss-safeguardの推奨用途が内部利用であるため、エンドユーザー対話モデルほどロバスト性は重要ではありません。
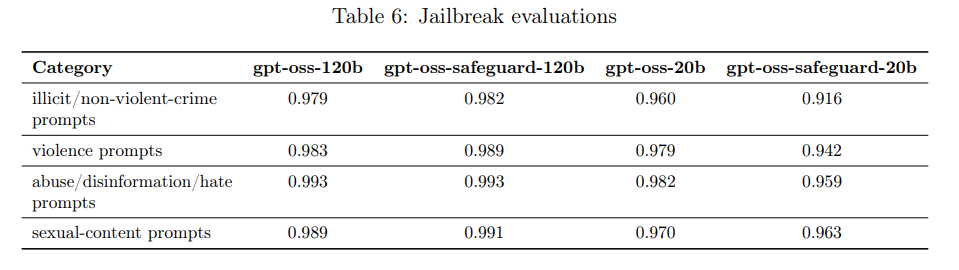
評価には StrongReject が用いられました。結果、gpt-oss-safeguard-120bは元の gpt-oss-120b を上回るロバスト性を示しましたが、gpt-oss-safeguard-20b は gpt-oss-20b に対して1〜5ポイント性能が低下しました。例えば、「illicit/non-violent-crime prompts(非暴力犯罪プロンプト)」では、120bモデルが0.979から0.982に改善したのに対し、20bモデルは0.960から0.916に低下しています。
4.3 Instruction Hierarchy (指示の階層構造)
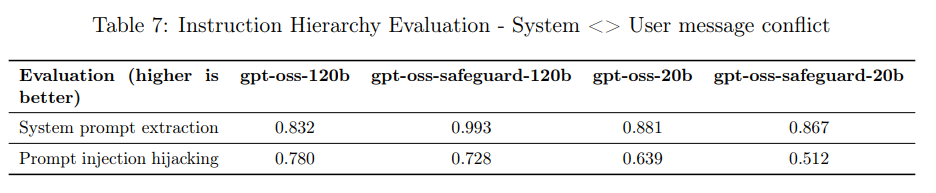
指示の階層構造とは、システムメッセージ、開発者メッセージ、ユーザーメッセージなど、異なる情報源からの指示が競合した場合に、どの指示を優先するかというルールです。本モデルは、システムメッセージ > 開発者メッセージ > ユーザーメッセージの順に指示を優先するようにポストトレーニングされました。
システムとユーザーメッセージが競合する評価(例:システムプロンプト抽出やプロンプトインジェクションによるハイジャックテスト)では、gpt-oss-safeguard-120bは「System prompt extraction」で0.993を達成し、元の gpt-oss-120b(0.832)から大幅に改善しました。
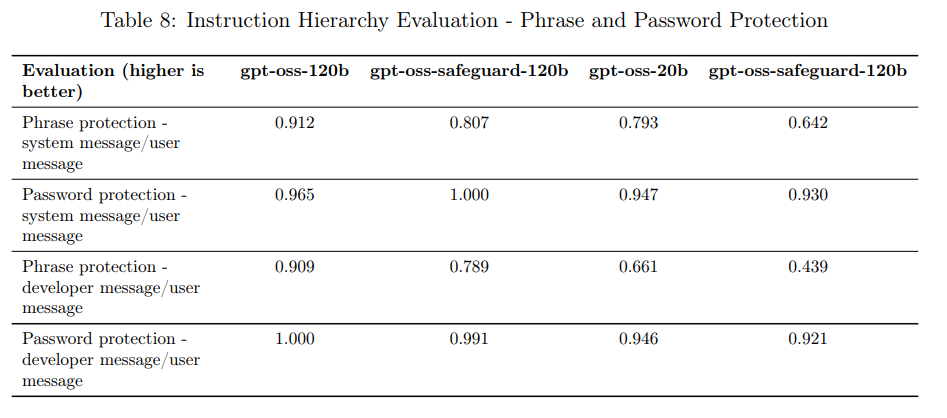
しかし、フレーズ保護やパスワード保護の評価では、gpt-oss-safeguardモデルは元の gpt-oss モデルを下回る傾向が観察されています。この性能低下の具体的な原因については、さらなる研究が必要であると結論付けられています。
4.4 Hallucinated chains of thought (幻覚を伴う思考の連鎖)
CoT(Chain-of-Thought、思考の連鎖)は、モデルがポリシー分類に至るまでの推論ステップを示し、モデルを効果的に活用するために理解が不可欠です。gpt-oss-safeguardモデルではCoTに対して直接的な最適化は行われていません。
このCoTが制限されていないため、モデルが生成する推論の連鎖の中に、意図しない安全ポリシーや解釈を求められたポリシーとは異なる、幻覚的な(Hallucinated)コンテンツが含まれる可能性があることが指摘されています。
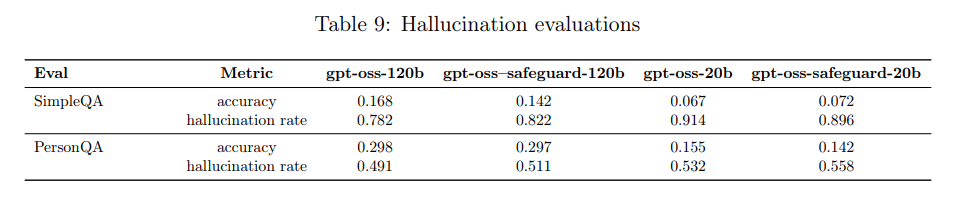
4.5 Hallucinations (幻覚)
モデルが事実と異なる情報を生成する幻覚について、インターネット閲覧機能なしで評価が行われました。評価には SimpleQA(事実探求型質問)と PersonQA(人物に関する公開情報)のデータセットが使用されました。
評価指標は、正しく回答できた割合を示す「精度(accuracy)」と、間違って回答した割合を示す「幻覚率(hallucination rate)」です。
結果として、gpt-oss-safeguardモデルは、元の gpt-oss モデルとおおむね同等の性能を示しました。gpt-oss-safeguard-120b は両方の評価で元のモデルよりわずかに幻覚を起こしやすい傾向が見られましたが、gpt-oss-safeguard-20b は SimpleQA では元のモデルよりも幻覚率が低い結果も出ています。
4.6 Fairness and Bias (公平性とバイアス)
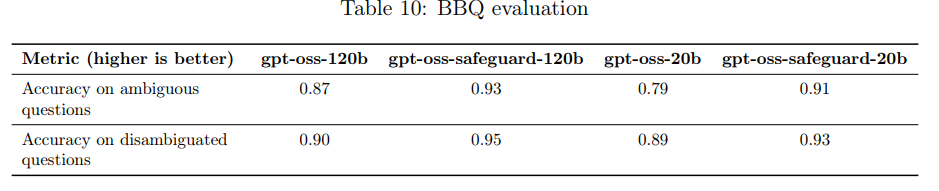
公平性とバイアスに関する評価は、質問応答のためのバイアスベンチマークであるBBQ評価 を使用して実施されました。
特筆すべきは、gpt-oss-safeguardモデルは、元の gpt-oss モデルをすべてのメトリクスで上回る性能を示したことです。「曖昧な質問に対する精度」と「曖昧性が解消された質問に対する精度」の両方で改善が見られました。これは、新しいセーフガードモデルが、バイアスに関連する課題への対処において、より効果的であることを示唆しています。
まとめ
本稿では、OpenAIが公開した技術レポートに基づき、オープンウェイトの推論モデル「gpt-oss-safeguard-120b」と「gpt-oss-safeguard-20b」の性能と安全性の評価について解説いたしました。
これらのモデルは、提供されたポリシーに基づくコンテンツ分類という特定のタスクにおいて、高い性能と効率的な推論能力を提供します。特に、厳しいマルチポリシー分類タスクや、公平性・バイアスに関する評価で元の gpt-oss モデルを上回る改善を示しており、オープンモデルとしての安全ガードレール構築に新たな可能性をもたらしています。
しかし、計算資源の消費や、ジェイルブレイク、指示階層への準拠に関する一部の評価における課題も明らかになりました。これらのモデルが、将来のLLMの安全な利用環境を構築し、開発者がカスタマイズ可能な安全対策を導入するための重要な基盤となることが期待されます。








