
はじめに
OpenAIが2025年10月29日、開発者が独自の安全性ポリシーを適用できる推論型の安全性分類モデル「gpt-oss-safeguard」を発表しました。従来の分類器と異なり、推論時にポリシーを解釈する新しいアプローチを採用しています。本稿では、このモデルの仕組みと性能、実用上の可能性について解説します。
参考記事
- タイトル: Introducing gpt-oss-safeguard
- 発行元: OpenAI
- 発行日: 2025年10月29日
- URL: https://openai.com/index/introducing-gpt-oss-safeguard/
モデルページ
・HuggingFace:https://huggingface.co/collections/openai/gpt-oss-safeguard
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- gpt-oss-safeguardは、開発者が提供するポリシーを推論時に解釈し、コンテンツを分類する120bと20bの2つのサイズのオープンウェイトモデルである
- 従来の分類器が数千の事例から間接的にポリシーを推論するのに対し、このモデルはchain-of-thoughtを用いて開発者提供のポリシーを直接解釈する
- OpenAI内部では「Safety Reasoner」として使用され、画像生成やSora 2での安全性評価、GPT-5やChatGPT Agentの多層防御システムの一部を担っている
- 内部評価とToxicChatなどの外部ベンチマークで、gpt-5-thinkingや既存のgpt-ossモデルを上回る性能を記録した
- Apache 2.0ライセンスで公開され、ROOSTとの協力によりモデルコミュニティも立ち上げられている
詳細解説
gpt-oss-safeguardの基本的な仕組み
gpt-oss-safeguardは、OpenAIのオープンウェイトモデル「gpt-oss」をファインチューニングしたもので、120bと20bの2つのサイズで提供されています。OpenAIによれば、このモデルは推論機能を活用して、開発者が提供するポリシーを推論時に直接解釈し、ユーザーメッセージ、生成結果、会話全体をそのポリシーに従って分類します。
従来の安全性分類器は、事前に定義されたポリシーに基づいて数千の安全・不安全な事例を人手でラベル付けし、そのデータからパターンを学習する方式でした。この方式では、分類器はポリシー自体を見ることなく、ラベル付けされた事例の類似性から暗黙的に境界線を推論します。対照的に、gpt-oss-safeguardはchain-of-thought(段階的推論)を用いて、ポリシーから判断に至る過程を明示的に示します。
この推論ベースのアプローチにより、開発者はポリシーの内容を確認でき、反復的に改善することが可能です。また、Apache 2.0ライセンスで公開されているため、誰でも自由に使用、修正、デプロイができます。
柔軟なポリシー適用の実現
OpenAIの発表では、gpt-oss-safeguardは推論時にポリシーとコンテンツの2つの入力を同時に受け取り、判断結果とその推論過程を出力します。開発者は、その結果を自身の安全性パイプラインでどのように活用するかを決定します。
この方式は、特に以下のような状況で効果を発揮すると説明されています。潜在的な害が新しく発生したり進化したりして、ポリシーを迅速に適応させる必要がある場合、分野が高度にニュアンスを含み、小規模な分類器では対応が難しい場合、プラットフォーム上の各リスクに対して高品質な分類器を訓練するための十分なサンプルがない場合、そしてレイテンシよりも高品質で説明可能なラベル付けが重要な場合です。
例として、ビデオゲームのディスカッションフォーラムがゲーム内の不正行為に関する投稿を分類するポリシーを開発したい場合や、製品レビューサイトが偽のレビューをスクリーニングするための独自ポリシーを使用したい場合が挙げられています。
従来の分類器では、ポリシーを変更するたびに再訓練が必要でしたが、この方式ではポリシーを更新するだけで即座に適用できるため、開発サイクルが大幅に短縮される可能性があります。
OpenAI内部での実用例:Safety Reasoner
OpenAIによれば、このアプローチは内部で「Safety Reasoner」という名称で既に活用されており、主要な推論モデルは安全性ポリシーを直接学習し、推論機能を使って安全性を判断しています。この手法は「deliberative alignment(熟慮的アライメント)」と呼ばれ、従来の安全性訓練手法を大きく改善し、推論モデルをより安全にしています。
Safety Reasonerは、OpenAIの本番環境において動的にポリシーを更新できる主要ツールとなっており、分類器を再訓練するよりも短時間でポリシー変更が可能です。新しいモデルを本番環境にデプロイする際、OpenAIはより厳格なポリシーから開始し、本番環境でのリスク理解が深まるにつれてポリシーを調整するという「反復的デプロイ」戦略を採用しています。最近のリリースでは、安全性推論に割り当てられた計算リソースの割合が最大16%に達したこともあると報告されています。
具体的な活用例として、画像生成とSora 2では、Safety Reasonerが出力のリアルタイム評価を段階的に実行し、不安全な生成を特定してブロックしています。生物学や自傷行為などの領域では、Moderation APIで使用されるような小型で高速、高再現率の分類器をまず実行してドメイン内のコンテンツを判定し、その後Safety Reasonerが詳細な分類を行うという二段階のアプローチが採用されています。Safety Reasonerは、GPT-5やChatGPT Agentなどのシステムにおける多層防御の一部として機能しています。
性能評価と競合モデルとの比較
OpenAIは内部評価と外部ベンチマークの両方でgpt-oss-safeguardを評価しました。
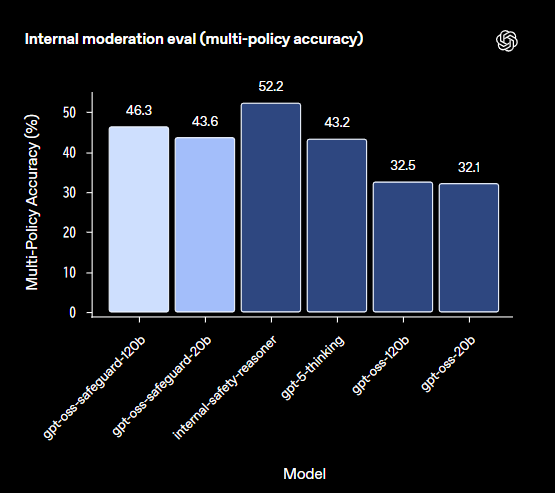
内部評価では、複数のポリシーを同時に提供し、各テスト入力に対してすべてのポリシーで正しく分類できるかを測定しました。OpenAIによれば、これは難易度の高いタスクで、すべてのポリシーのラベルと完全に一致した場合のみ正解とカウントされます。結果として、gpt-oss-safeguard-120bは46.3%、gpt-oss-safeguard-20bは43.6%のマルチポリシー精度を記録し、内部のSafety Reasoner(52.2%)には及ばないものの、gpt-5-thinking(43.2%)やgpt-oss-120b(32.5%)、gpt-oss-20b(32.1%)を上回りました。特に、gpt-oss-safeguardがgpt-5-thinkingを上回ったことは、モデルサイズを考えると驚くべき結果と評価されています。
外部評価では、OpenAIが2022年に発表した研究論文で公開したモデレーションデータセットと、オープンソースチャットボットへのユーザークエリに基づくToxicChatベンチマークを使用しました。2022年のモデレーションデータセットでは、gpt-oss-safeguard-120bとgpt-oss-safeguard-20bがともに82.9のF1スコアを記録し、内部のSafety Reasoner(82.8)やgpt-5-thinking(79.8)を僅かに上回りました。ただし、Safety Reasonerとgpt-oss-safeguardの差は統計的に有意ではありません。
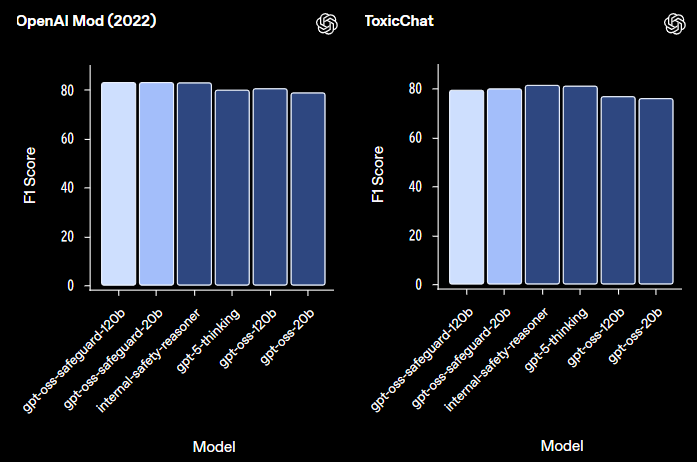
ToxicChatでは、内部ポリシーから適応した短い手書きプロンプトを使用して評価が行われました。内部のSafety Reasonerが81.3のF1スコアで最高性能を示し、gpt-5-thinkingが81.0、gpt-oss-safeguard-120bが79.3、gpt-oss-safeguard-20bが79.9という結果でした。OpenAIは、gpt-oss-safeguardの比較的小さなサイズを考慮すると、このタイプのタスクでは依然として好ましい選択肢になると考えているとしています。
これらのベンチマークは、安全性分類器の性能を測る業界標準として広く使用されており、F1スコアは精度と再現率のバランスを示す指標です。80%以上のF1スコアは、実用レベルの性能として評価されることが多い水準と言えるでしょう。
制限事項と今後の展開
OpenAIは、gpt-oss-safeguardには2つの重要な制限があると明示しています。
第一に、数万の高品質なラベル付きサンプルで訓練された専用の分類器は、ポリシーから直接推論するgpt-oss-safeguardよりも依然として高い性能を発揮する場合があります。OpenAIによれば、より複雑なリスクに対して高い性能が求められる場合は、専用分類器の訓練に時間をかける方が好ましい可能性があります。
第二に、gpt-oss-safeguardは時間と計算リソースを要するため、プラットフォーム全体のコンテンツに対してスケールさせることが難しい場合があります。OpenAI内部では、この課題に対して2つの方法で対処しています。1つは、より小型で高速な分類器を使用してどのコンテンツを評価すべきかを判定すること、もう1つは、状況に応じてSafety Reasonerを非同期で使用し、低レイテンシのユーザー体験を維持しながら不安全なコンテンツを検出した場合に介入できるようにすることです。
この制限は、推論ベースのアプローチが万能ではなく、用途に応じて従来の分類器と使い分ける必要があることを示唆しています。
コミュニティとの協力
OpenAIは、gpt-oss-safeguardを同社初のコミュニティと共同開発したオープン安全性モデルと位置づけています。初期テストの段階で、SafetyKit、ROOST、Tomoro、Discordの信頼・安全性専門家と協力して改善を重ねてきました。
ROOSTのCTO Vinay Rao氏は、「gpt-oss-safeguardは、『独自のポリシーと害の定義を持ち込む』設計の初のオープンソース推論モデルです。組織は重要な安全性技術を自由に研究、修正、使用し、イノベーションを起こす資格があります。テストでは、異なるポリシーの理解、推論の説明、ポリシー適用におけるニュアンスの表現に優れており、開発者と安全性チームに有益だと考えています」とコメントしています。
OpenAIは、ROOST Model Community(RMC)を通じてコミュニティと協力し、オープン安全性ツールの改善を継続するとしています。RMCは、安全性の実務家と研究者を集め、オープンソースAIモデルを安全性ワークフローに実装するためのベストプラクティスを共有する場として機能します。モデルはHugging Faceからダウンロード可能で、GitHubリポジトリを通じてコミュニティへの参加も可能です。
まとめ
gpt-oss-safeguardは、推論機能を活用して開発者独自のポリシーに対応する新しいタイプの安全性分類モデルです。従来の分類器と比較して柔軟性が高く、OpenAI内部でも実用されている実績があります。ただし、計算コストや専用分類器との性能差など、実装時に考慮すべき点もあります。今後、コミュニティとの協力を通じて、オープンな安全性ツールがどのように発展していくかが注目されます。








