はじめに
OpenAIが2026年1月23日、ソフトウェアエージェント「Codex CLI」の内部動作を解説する技術記事「Unrolling the Codex agent loop」を公開しました。本稿では、エージェントループの基本構造、プロンプトの構築方法、パフォーマンス最適化の工夫について、OpenAIの技術スタッフMichael Bolinによる解説をもとに詳しく紹介します。
参考記事
- タイトル: Unrolling the Codex agent loop
- 著者: Michael Bolin
- 発行元: OpenAI
- 発行日: 2026年1月23日
- URL: https://openai.com/index/unrolling-the-codex-agent-loop/
要点
- Codex CLIは、ユーザー入力、モデル推論、ツール実行を繰り返す「エージェントループ」を中核としたソフトウェアエージェントである
- プロンプトは、システムメッセージ、ツール定義、ユーザー入力などの複数要素から構成され、Responses APIを通じてモデルに送信される
- 会話が進むにつれてプロンプト長が増加するが、プロンプトキャッシングにより計算コストを線形に抑える工夫がなされている
- コンテキストウィンドウ管理のため、一定のトークン数を超えると自動的に会話を圧縮する仕組みが実装されている
詳細解説
エージェントループの基本構造
OpenAIによれば、Codex CLIの中核を担う「エージェントループ」は、ユーザー入力を受け取り、モデルに推論を実行させ、必要に応じてツールを呼び出すという一連の処理を繰り返す仕組みです。
具体的には、まずユーザーからの入力がプロンプトに組み込まれ、Responses API経由でモデルに送信されます。モデルは推論を実行し、(1)ユーザーへの最終応答を生成するか、(2)ツール呼び出しをリクエストするかのいずれかを返します。ツール呼び出しがリクエストされた場合、エージェントはそれを実行し、結果を元のプロンプトに追加して再度モデルに問い合わせます。
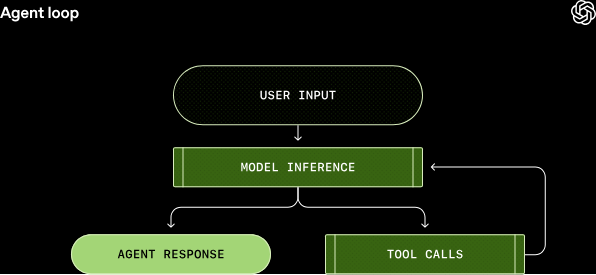
このプロセスは、モデルがツール呼び出しを停止し、ユーザーへのメッセージ(アシスタントメッセージ)を生成するまで繰り返されます。ユーザー入力からエージェント応答までの一連の流れが「ターン」と呼ばれ、新しいメッセージが送信されるたびに、過去の会話履歴がプロンプトに含まれる形で次のターンが開始されます。
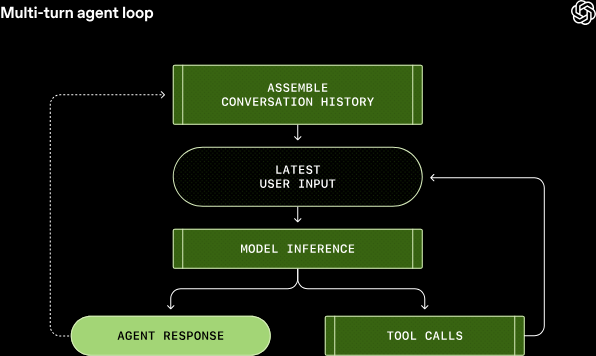
エージェントループの概念は、LLMを活用したアプリケーション開発において広く用いられる設計パターンと言えます。このループ構造により、単純な質問応答を超えた、複雑なタスクの段階的な実行が可能になると考えられます。
プロンプトの構築プロセス
OpenAIの説明では、Codex CLIがResponses APIに送信するプロンプトは、複数の要素から構成されています。APIリクエストには主に3つのパラメータがあります。
まず「instructions」パラメータは、システムレベルまたは開発者レベルのメッセージとして、モデルのコンテキストに挿入されます。Codexでは、ユーザーの~/.codex/config.tomlファイルで指定されたmodel_instructions_fileから読み込まれるか、デフォルトのモデル固有の指示が使用されます。
次に「tools」パラメータは、モデルが呼び出せるツールのリストを定義します。これには、Codex CLI自体が提供するツール(shellコマンド実行、プラン更新など)、Responses APIが提供するツール(Web検索など)、そしてユーザーがMCPサーバー経由で追加したカスタムツールが含まれます。
最後に「input」パラメータは、実際の会話内容を含むメッセージのリストです。Codexは初回のプロンプトに以下の要素を順番に挿入します:
- サンドボックス環境の説明(role=developer)
- ユーザーの開発者向け指示(オプション、role=developer)
- プロジェクト固有の指示やスキル情報(オプション、role=user)
- 現在の作業ディレクトリやシェル情報(role=user)
- ユーザーの実際のメッセージ(role=user)
プロンプト構築における「role」の概念は、各メッセージの優先度や重要性を示す指標として機能します。system、developer、user、assistantの順に優先度が設定されており、モデルはこれらの役割に応じて情報を解釈すると考えられます。
モデル推論とストリーミング応答
OpenAIによれば、Responses APIへのHTTPリクエストが送信されると、サーバーはServer-Sent Events(SSE)形式でストリーミング応答を返します。このストリーミングにより、モデルが生成する出力をリアルタイムで表示できます。
応答には様々なイベントタイプが含まれます。例えば、response.reasoning_summary_text.deltaイベントはモデルの推論過程のテキスト断片を、response.output_text.deltaイベントは最終的な出力テキストの断片を示します。Codex CLIはこれらのイベントを消費し、UI表示用に内部イベントとして再発行します。
ツール呼び出しが発生した場合、その結果は次のAPIリクエストの入力配列に追加されます。具体的には、推論情報を含むtype=reasoning項目、ツール呼び出し情報を含むtype=function_call項目、そしてツールの実行結果を含むtype=function_call_output項目が追加されます。
重要な点として、新しいプロンプトは常に前回のプロンプトの完全な接頭辞となるよう設計されています。この構造により、次のセクションで説明するプロンプトキャッシングの恩恵を最大限に受けることができます。
パフォーマンス最適化の工夫
OpenAIの説明では、会話が進むにつれてResponses APIに送信するJSONのサイズが二次関数的に増加する問題が指摘されています。しかし、実際のコスト面では、ネットワーク通信よりもモデルサンプリングのコストが支配的であるため、最適化の焦点はサンプリング効率に置かれています。
その鍵となるのがプロンプトキャッシングです。プロンプトの完全一致する接頭辞部分については、以前の推論結果を再利用できるため、実質的な計算コストを線形に抑えることができます。OpenAIのドキュメントでは、静的なコンテンツ(指示や例)をプロンプトの先頭に配置し、可変的なコンテンツ(ユーザー固有の情報)を末尾に配置することが推奨されています。
Codex開発チームは、キャッシュミスを引き起こす可能性のある変更に細心の注意を払っています。例えば、会話途中でのツールリストの変更、モデルの切り替え、サンドボックス設定の変更などは、すべてキャッシュミスの原因となります。初期のMCPツール実装では、ツールを一貫した順序で列挙しないバグがあり、これがキャッシュミスを引き起こしていたとのことです。
設定変更が必要な場合、Codexは既存のメッセージを修正するのではなく、新しいメッセージを追加することでキャッシュヒット率を維持します。例えば、サンドボックス設定が変更された場合は新しいrole=developerメッセージが、作業ディレクトリが変更された場合は新しいrole=userメッセージが挿入されます。
プロンプトキャッシングは、大規模言語モデルを使用したアプリケーションにおいて、コスト削減と応答速度向上の両面で重要な技術と考えられます。Codexの実装は、この技術を最大限に活用する設計の好例と言えます。
コンテキストウィンドウ管理
もう一つの重要な課題が、モデルのコンテキストウィンドウ管理です。OpenAIによれば、すべてのモデルには1回の推論呼び出しで使用できるトークン数の上限があり、これには入力トークンと出力トークンの両方が含まれます。
Codexの初期実装では、ユーザーが手動で/compactコマンドを実行することで会話を圧縮していました。このコマンドは、既存の会話と要約用の特別な指示を使ってResponses APIにクエリを送信し、生成された要約を新しい入力として使用する仕組みでした。
その後、Responses APIは専用の/responses/compactエンドポイントを提供するようになりました。このエンドポイントは、より効率的に会話を圧縮し、元の会話に対するモデルの潜在的な理解を保持する特別なtype=compaction項目(不透明なencrypted_contentを含む)を返します。
現在のCodexは、トークン数がauto_compact_limitを超えると自動的にこのエンドポイントを使用して会話を圧縮します。この自動圧縮により、長時間の会話でもコンテキストウィンドウの制約に達することなく継続できる仕組みが実現されています。
コンテキストウィンドウの効率的な管理は、長期的な対話を必要とするエージェントアプリケーションにおいて不可欠な要素と言えます。Codexのアプローチは、ユーザー体験を損なうことなくこの課題に対処する実践的な解決策を示していると思います。
まとめ
OpenAIのCodex CLIは、エージェントループを中核とした洗練されたソフトウェアエージェントです。プロンプト構築の詳細、プロンプトキャッシングによるパフォーマンス最適化、コンテキストウィンドウの自動管理など、実用的なエージェント開発における重要な設計判断が示されています。今後の記事では、CLI アーキテクチャやツール実装、サンドボックスモデルなどがさらに詳しく解説される予定とのことです。