はじめに
近年、大規模言語モデル(LLM)は目覚ましい発展を遂げ、医療分野においても診断支援などへの応用が期待されています。Google ResearchとGoogle DeepMindが開発した研究用の診断対話AIエージェントAMIE (Articulate Medical Intelligence Explorer) は、テキストベースの対話においては既に高い性能を示していました。しかし、実際の臨床現場では、画像や検査結果といったマルチモーダルな情報が診断において極めて重要です。
本稿では、この課題に取り組んだ最新の研究「AMIE gains vision: A research AI agent for multimodal diagnostic dialogue」を紹介します。この研究では、AMIEに視覚情報を理解し、対話の中で活用する能力を付与することに成功しました。
引用元記事
- タイトル: AMIE gains vision: A research AI agent for multimodal diagnostic dialogue
- 発行日: 2025年5月1日
- 発行: Google Research
- URL: https://research.google/blog/amie-gains-vision-a-research-ai-agent-for-multi-modal-diagnostic-dialogue/
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- Googleは、診断対話AI「AMIE」を拡張し、画像などの視覚情報を対話の中で理解・活用できる「Multimodal AMIE」を開発しました。
- 基盤モデルとしてマルチモーダル対応のGemini 2.0 Flashを採用し、対話のフェーズや不確実性に応じて応答を最適化する状態認識型推論フレームワーク (State-aware reasoning framework) を導入しました。
- このフレームワークにより、AMIEは臨床医のように構造化された問診を行い、必要に応じて画像などのマルチモーダル情報を要求・解釈し、診断精度を高めることができます。
- OSCE(客観的臨床能力試験)を模倣した専門家による評価において、Multimodal AMIEはプライマリケア医(PCP)と比較して、マルチモーダル情報の解釈、診断精度、共感性などで同等以上の性能を示しました。
- 開発効率化のために、リアルな患者シナリオ生成、対話シミュレーション、自動評価を行うシミュレーション環境を構築しました。
- 最新のGemini 2.5 Flashを用いた予備実験では、さらなる性能向上の可能性が示唆されています。
詳細解説
背景:診断対話AIにおけるマルチモーダリティの重要性
従来の診断対話AIの多くは、テキスト情報のみに基づいていました。しかし、実際の医療現場では、医師は患者の言葉だけでなく、視診、レントゲン写真、皮膚の写真、心電図、検査結果など、多様なモダリティ(情報の種類)から得られる情報を総合的に判断して診断を行います。特に、画像などの視覚情報は診断の手がかりとして不可欠です。
これまでのLLMベースのAIは、テキスト対話においては高い能力を示してきましたが、これらのマルチモーダル情報を対話の中で動的に統合し、診断推論に活かすことは大きな課題でした。本研究は、このギャップを埋めることを目指しています。
Multimodal AMIEの技術的特徴
本研究では、AMIEをマルチモーダル対応にするために、主に2つの技術的進歩を導入しました。
- マルチモーダル基盤モデルの採用 (Gemini 2.0 Flash):
- Multimodal AMIEの中核には、Googleの強力なマルチモーダルモデルであるGemini 2.0 Flashが採用されています。これにより、テキストだけでなく、画像などの視覚情報を直接理解する能力を獲得しました。
- 状態認識型推論フレームワーク (State-aware reasoning framework):
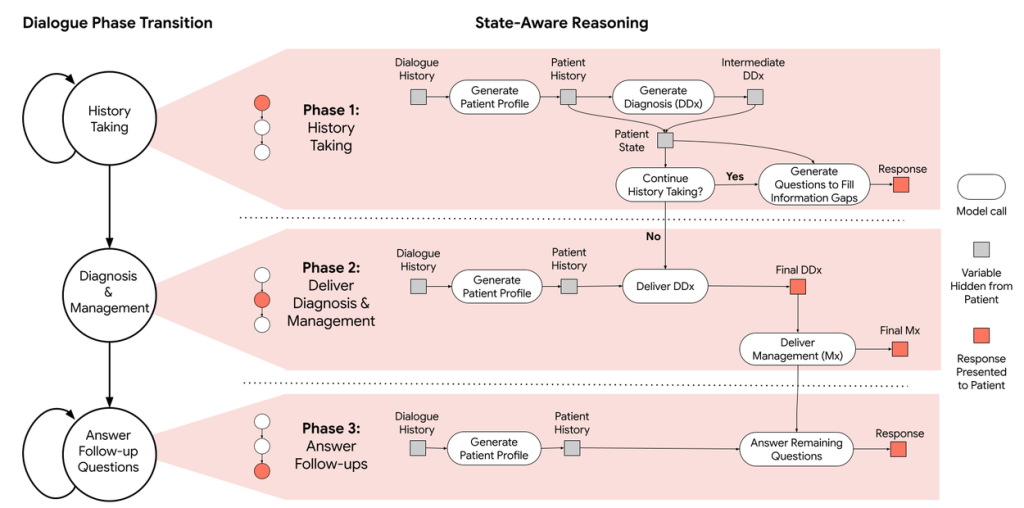
- 実際の臨床医が行う診断プロセスを模倣するために、状態認識型推論フレームワークという新しいアプローチを開発しました。これは、対話の進行状況に応じてAMIEの内部状態(患者に関する知識、診断仮説、不確実性など)を動的に管理し、応答を最適化する仕組みです。
- このフレームワークは、対話を大きく3つのフェーズ(①問診 (History Taking)、 ②診断と管理 (Diagnosis & Management)、 ③フォローアップ (Answer Follow-up Questions))に分け、各フェーズの目的に応じて動作します。
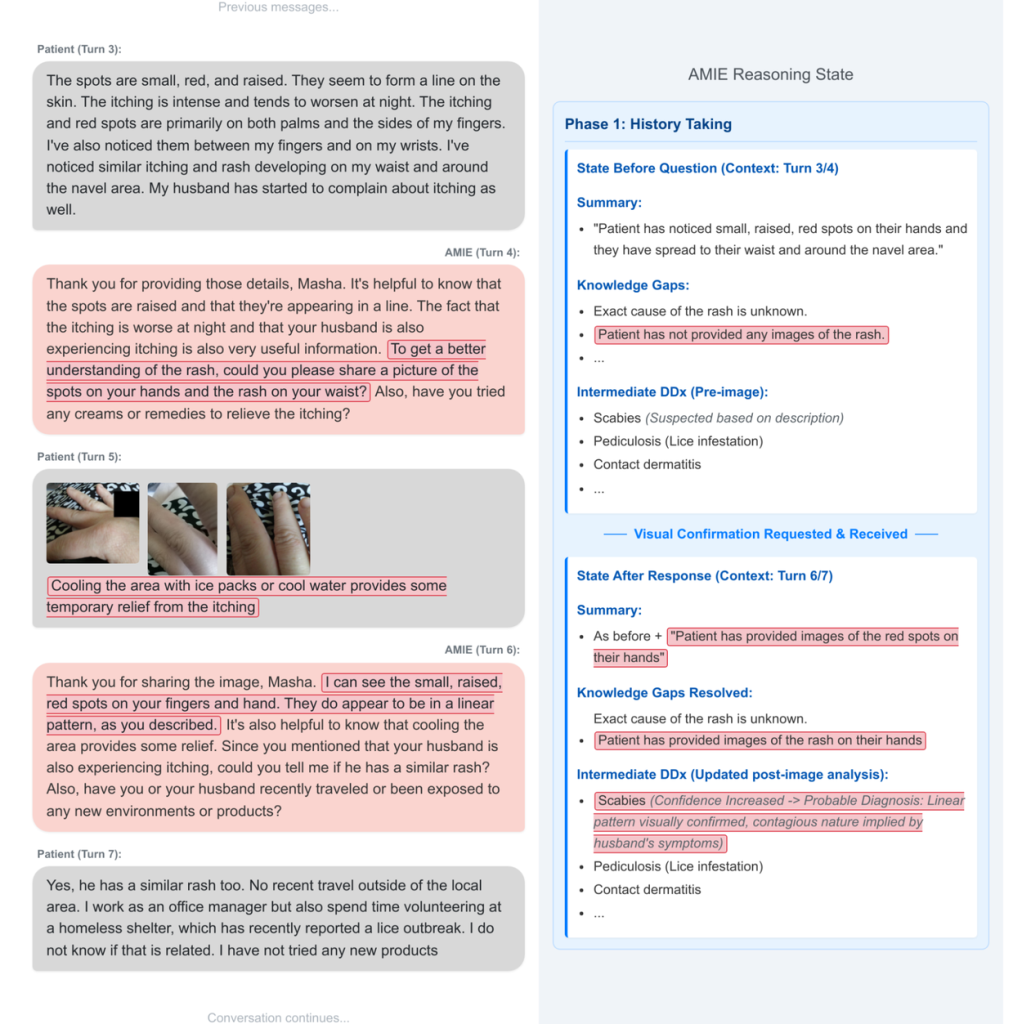
- 問診フェーズでは、AMIEは患者から情報を収集し、診断仮説を立てます。この際、知識のギャップ(例:発疹の具体的な見た目が不明)を認識すると、「手の発疹の写真を共有していただけますか?」のように、能動的にマルチモーダル情報の提供を要求します。
- 画像などが提供されると、AMIEはそれを解釈し、得られた情報を内部状態に統合します。これにより、診断仮説の確信度を更新したり、新たな質問を生成したりして、より的確な診断に近づけていきます。
- 診断と管理フェーズでは、収集した情報に基づいて最終的な鑑別診断リストと治療計画を提示します。
- このフレームワークにより、AMIEは単に質問に答えるだけでなく、臨床医のように能動的かつ構造的に情報を収集し、マルチモーダル情報を活用しながら診断を進めることが可能になりました。
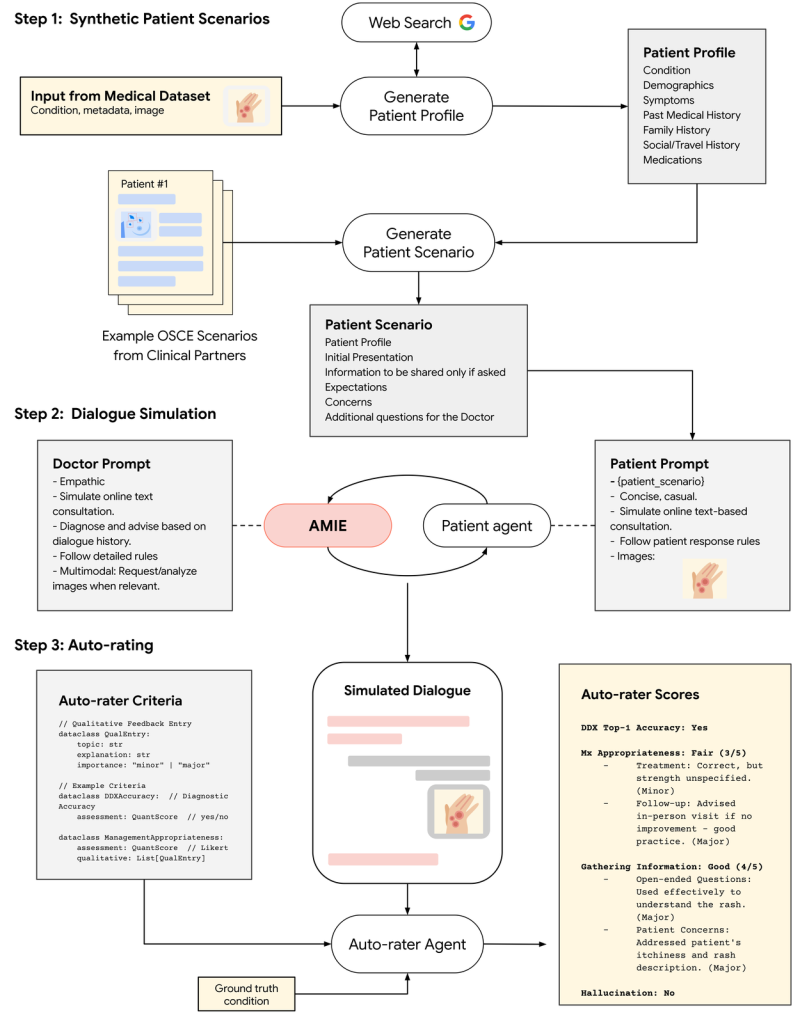
開発を加速するシミュレーション環境
Multimodal AMIEのような複雑な対話システムを効率的に開発・評価するために、研究チームは包括的なシミュレーション環境を構築しました。
- 合成患者シナリオ生成: 実世界のデータセット(皮膚画像のSCINデータセットなど)やWeb検索を利用し、Geminiモデルを用いてリアルな患者プロファイル、症状、マルチモーダルな情報(画像など)を含む患者シナリオを自動生成します。
- 対話シミュレーション: 生成されたシナリオに基づき、AMIEとシミュレートされた患者エージェントとの間で、マルチモーダル情報を含むターンバイターンの対話を自動的に実行します。
- 自動評価 (Auto-rating): シミュレートされた対話を、自動評価エージェントが、診断精度、情報収集の有効性、管理計画の適切さ、安全性(ハルシネーションの検出など)といった事前に定義された臨床基準に基づいて評価します。
このシミュレーション環境により、迅速なイテレーションと客観的な性能評価が可能になり、開発プロセスが大幅に加速されました。
評価:Multimodal Virtual OSCE Study
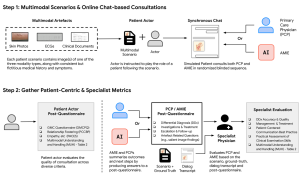
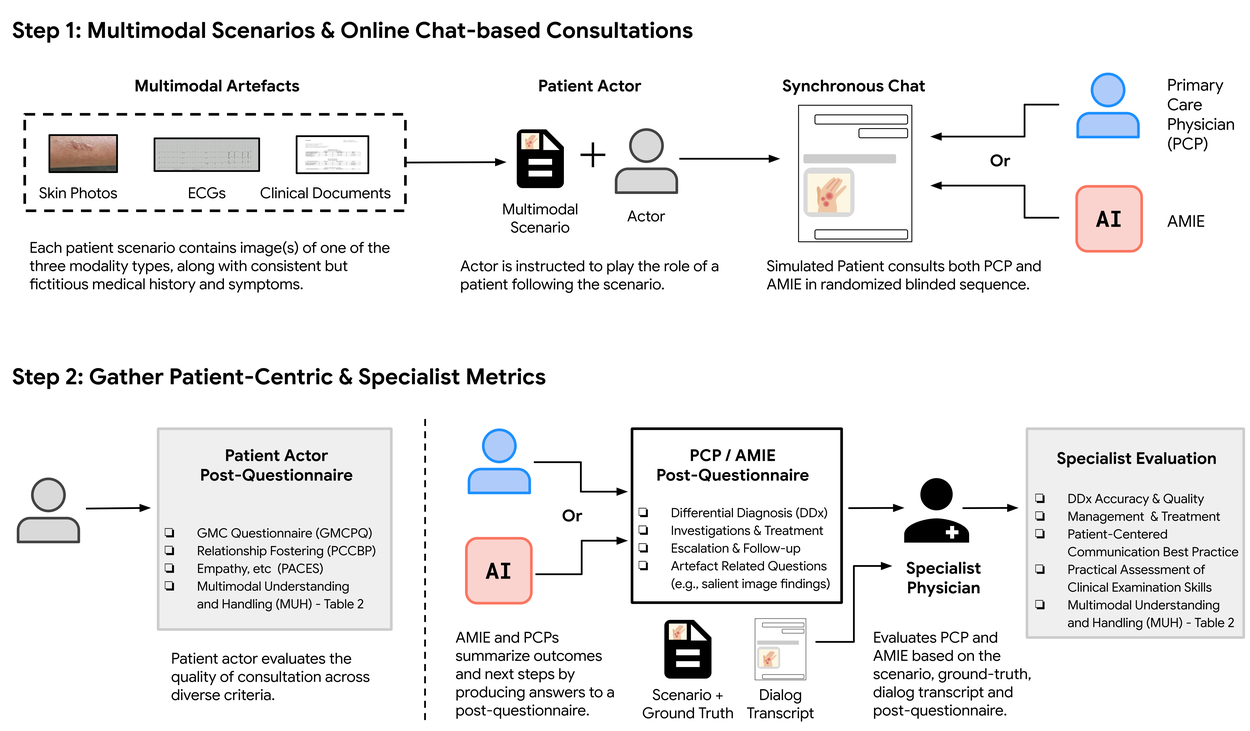
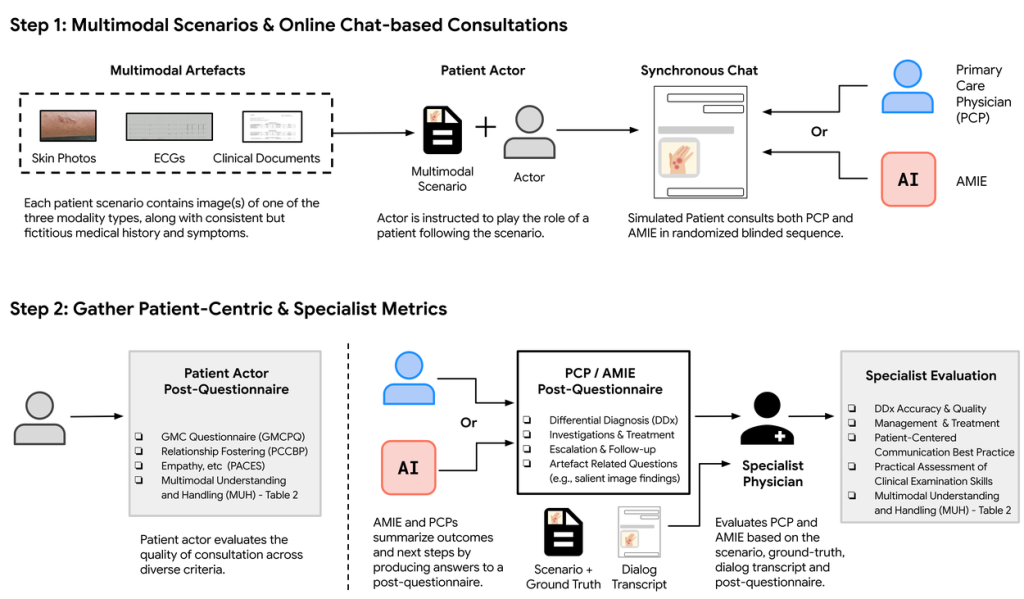
Multimodal AMIEの性能を評価するため、研究チームはOSCE(Objective Structured Clinical Examinations: 客観的臨床能力試験) と呼ばれる、医学教育で標準的に用いられる評価方法を模倣した、リモートでの専門家評価を実施しました。
- 方法: 105の患者シナリオを用意し、訓練を受けた模擬患者が、Multimodal AMIEまたは実際のプライマリケア医(PCP)と、画像などをアップロードできるチャットインターフェースを通じて対話を行いました。対話内容は、皮膚科、循環器科、内科の専門医によって評価されました。
- 評価項目: マルチモーダル情報の解釈能力、問診、診断精度、管理推論、コミュニケーションスキル、共感性など、臨床的に重要な複数の指標で評価されました。
結果:PCPに匹敵、または上回る性能
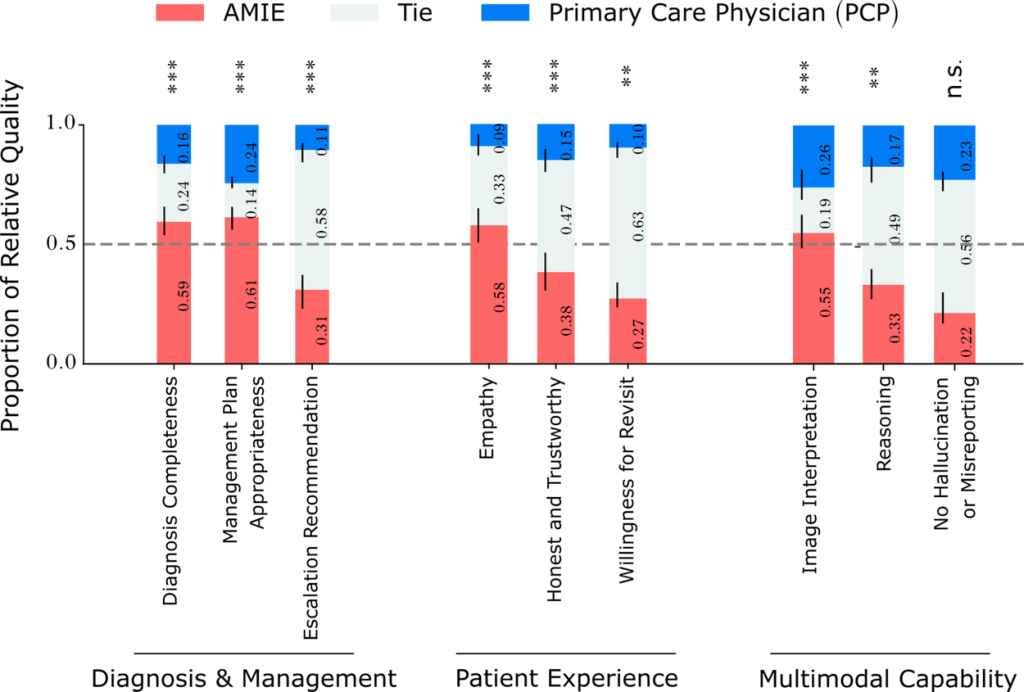
評価の結果、Multimodal AMIEは多くの評価項目でPCPに匹敵、またはそれを上回る性能を示しました。
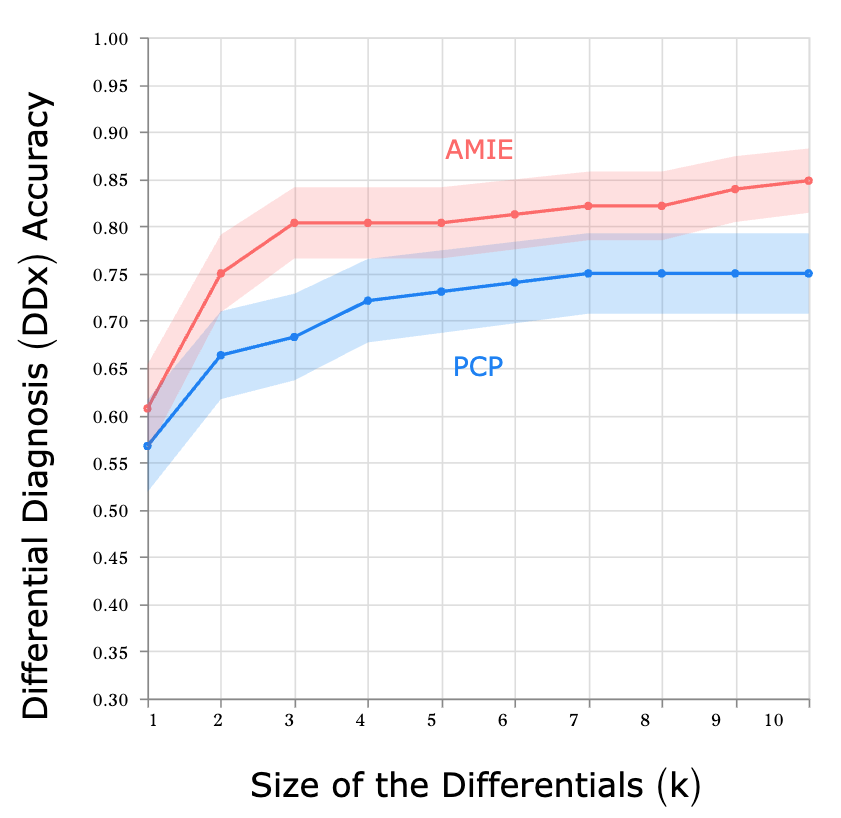
- 診断精度: AMIEはPCPよりも正確で完全な鑑別診断リストを作成しました。特に、提示された診断候補の上位に含まれる正解診断の割合(Top-k Accuracy)で優位性が見られました。
- マルチモーダル能力: 専門医による評価では、AMIEは画像解釈の質や推論能力において、PCPよりも高く評価されました。
- その他の評価項目: 診断の完全性、管理計画の適切性、緊急治療の必要性判断(Escalation Recommendation)などでも、AMIEが高い評価を得ました。
- 患者体験: 模擬患者による評価では、AMIEはPCPよりも共感的で信頼できると評価される傾向がありました。
- ハルシネーション: 提供された画像と矛盾する所見を報告してしまうハルシネーション(誤報告)の程度については、AMIEとPCPの間で統計的に有意な差は見られませんでした。
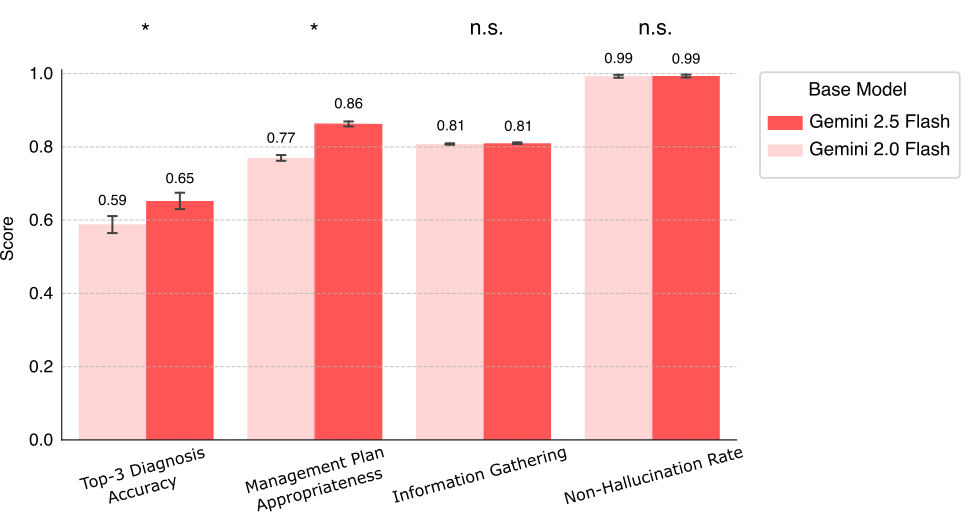
最新モデル (Gemini 2.5 Flash) での予備実験
研究チームは、より新しく高性能なGemini 2.5 Flashを基盤モデルとしてMultimodal AMIEを構築した場合の性能を、シミュレーション環境で予備的に評価しました。その結果、Gemini 2.0 Flash版と比較して、Top-3診断精度と管理計画の適切さにおいて統計的に有意な改善が見られました。情報収集能力やハルシネーション率は同等レベルを維持しており、基盤モデルの進化によってAMIEがさらに高性能化する可能性が示唆されました。ただし、これは自動評価による予備的な結果であり、専門家による厳密な評価が不可欠であると述べられています。
限界と今後の方向性
本研究は非常に有望な結果を示していますが、研究チームはいくつかの限界と今後の課題を挙げています。
- 実世界での検証の重要性: 今回の評価は、模擬患者を用いたOSCE形式であり、実世界の医療の複雑さ(多様な疾患、患者背景、利用可能なマルチモーダルデータの種類や量など)を完全には再現していません。また、臨床医の専門知識も、慣れない環境下では十分に発揮されない可能性があります。実用化に向けては、実際の臨床現場でのさらなる検証が不可欠です。
- リアルタイムの音声・ビデオ対話: 遠隔医療では、チャットよりもリアルタイムの音声・ビデオ通話が一般的であり、非言語的な情報や視覚的な診察が重要になります。AMIEをこのようなリッチなインタラクションに対応させることは、今後の重要な課題です。
- AMIEシステムの進化: 今回のマルチモーダル機能は、継続的なAMIE開発の一部であり、今後は長期的な疾患管理など、他の機能との統合も進められていく予定です。
まとめ
本稿で紹介したMultimodal AMIEは、診断対話AIに「視覚」を与えるという画期的な研究成果です。Geminiモデルの高度なマルチモーダル能力と、臨床プロセスを模倣した状態認識型推論フレームワークを組み合わせることで、画像を含む多様な情報を対話の中でインテリジェントに扱い、より正確な診断支援を行うAIの実現可能性を示しました。
OSCE形式の評価では、プライマリケア医に匹敵、あるいは上回る性能を示し、特にマルチモーダル情報の解釈能力において高い評価を得ました。これは、AIが医療現場において、医師を支援し、より質の高いケアを提供するための重要な一歩と言えるでしょう。
もちろん、実用化に向けては、実環境での厳密な検証や、安全性・信頼性の確保など、さらなる研究開発が必要です。しかし、本研究は、AIが医療分野にもたらす可能性を大きく広げるものであり、今後の発展が大いに期待されます。