はじめに
近年、大規模言語モデル(LLM)の進化は目覚ましく、特に推論能力においては、人間が解くのが難しいような数学の問題、複雑なプログラミング、高度な科学的推論といった分野で驚くべき性能を発揮しています。しかし、これらの最先端モデルは、その巨大なパラメータ数ゆえに、学習や運用に莫大な計算資源とコストを必要とするという課題を抱えています。誰もがアクセスしやすく、手頃な価格で利用できる推論システムを開発するためには、より効率的なモデルが求められています。
今回ご紹介する論文「K2-Think: A Parameter-Efficient Reasoning System」は、この課題に対するソリューションを提案しています。研究チームは、わずか320億パラメータのモデルで、GPT-OSS 120BやDeepSeek v3.1といったはるかに大きなモデルの性能を上回る、あるいは匹敵する推論システム「K2-Think」を開発しました。これは、高度な学習後(ポストトレーニング)技術と推論時(テストタイム)計算技術を組み合わせることで、小さなモデルでも最上位レベルの競争力を持ちうることを示しています。
本稿では、K2-Thinkがいかにしてそのパラメータ効率と高性能を実現したのかを、論文の構成に沿って詳しく解説していきます。
解説論文
- 論文タイトル: K2-Think: A Parameter-Efficient Reasoning System
- 論文URL: https://arxiv.org/pdf/2509.07604
- 発行日: 2025年9月7日
- 発表者: Zhoujun Cheng ら( Institute of Foundation Models, Mohamed bin Zayed University of Artificial Intelligence)
・あくまで個人の理解に基づくものであり、正確性に問題がある場合がございます。
必ず参照元論文をご確認ください。
・本記事内での画像は、上記論文より引用しております。
※簡単に知りたい方

※その他サイト
- タイトル:K2-Think (Web) ※デモサイト
- URL: https://www.k2think.ai/
- タイトル:K2-Think Model Documentation
- 発行元:Hugging Face
- URL:https://huggingface.co/LLM360/K2-Think
- タイトル:K2-Think SFT Recipe
- 発行元:GitHub (MBZUAI-IFM)
- URL:https://github.com/MBZUAI-IFM/K2-Think-SFT
要点
- K2-Thinkは、320億パラメータという比較的小さなモデルでありながら、GPT-OSS 120BやDeepSeek v3.1などの大規模モデルに匹敵、あるいはそれを超える推論性能を発揮する。
- 数学的推論において特に強力であり、オープンソースモデルとして公開ベンチマークで最先端のスコアを達成している。
- 高度なポストトレーニング(Supervised FinetuningとReinforcement Learning with Verifiable Rewards)と推論時計算(Agentic planning, Test-time Scaling, Speculative Decoding, Inference-optimized Hardware)という6つの主要な技術的柱を統合することでこの性能を実現した。
- K2-Thinkは、オープンソースとしてモデル、コード、およびウェブサイト/APIを提供しており、アクセシビリティと研究の透明性を重視している。
- 「思考前のプランニング(Plan-Before-You-Think)」によって、推論性能を向上させるだけでなく、生成される応答の長さを最大12%削減し、トークン消費の効率化にも貢献している。
詳細解説
1 Introduction(はじめに)
近年、OpenAI-O3やGemini 2.5といった最先端の推論モデルは、長大な思考連鎖(Chain-of-Thought, CoT)推論によって、競争レベルの数学、複雑なコーディング、高度な科学的推論といったタスクで非常に優れた結果を出しています。CoTは、大規模な教師ありファインチューニング(SFT)と強化学習(RL)によって実現されており、モデルが最終的な答えを出すまでに至る中間的な思考ステップを明確にすることで、複雑な問題をより正確に解決できるようになります。
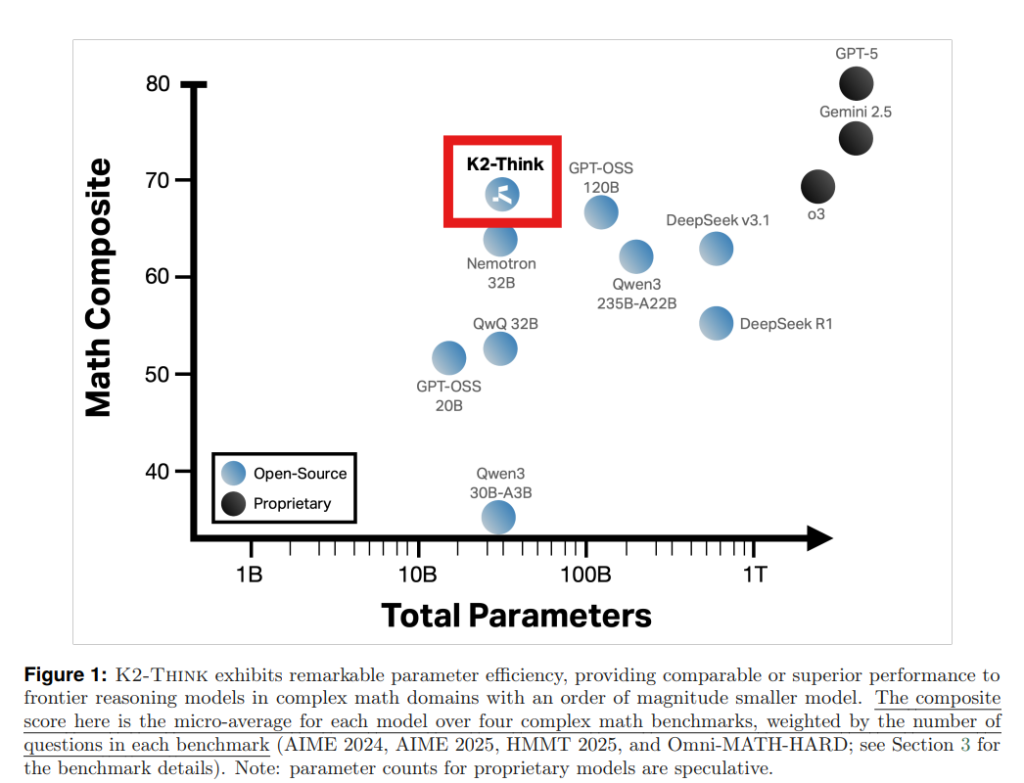
しかし、これらの高性能モデルは、その巨大なサイズから来るコストと計算資源の制約が課題となっています。K2-Thinkは、この課題に対し、わずか320億パラメータのQwen2.5ベースモデルを使用し、6つの主要な技術革新を組み合わせることで、最先端のプロプライエタリモデルの数学的推論性能に匹敵する、あるいはそれを超えるオープンソースの推論システムを構築しました。特に数学の分野で顕著なパラメータ効率(Figure1参照)を示し、アクセスしやすく手頃な価格のオープンソース推論システムの道を開くものです。
2 K2-Think Development(K2-Thinkの開発)
K2-Thinkは、推論能力を向上させるための包括的なポストトレーニング手法を研究し、社内ファウンデーションモデル(大規模な事前学習済みモデル)を拡張するためのベストプラクティスを確立する目的で開発されました。開発チームが320億パラメータ規模のベースモデルを選定したのは、以下の2つの理由からです。
- 迅速なイテレーション(反復開発)が可能であり、強力な基本性能を提供する。
- そのサイズが研究用途とコンシューマー向け計算フレームワークの両方に適している。
ベースモデルには、推論に特化してチューニングされていないQwen2.5-32Bが採用されました。これにより、開発チーム独自のポストトレーニング手法の有効性を完全に検証することができました。
2.1 Phase 1: Supervised Fine Tuning(フェーズ1: 教師ありファインチューニング)
K2-Thinkの開発の最初の段階は、教師ありファインチューニング(SFT)です。SFTとは、事前に大規模なデータで学習されたベースモデルに対し、特定のタスク(この場合はCoT推論)を実行できるように、教師ありデータを用いてさらに微調整を行うプロセスです。これにより、モデルは複雑な質問に対して構造化された応答を生成するための「指導」を受けます。具体的には、モデルが答えを出す前に、その推論プロセスを明確にするような出力形式を採用するように訓練されます。
K2-ThinkのSFTフェーズでは、AM-Thinking-v1-Distilledデータセット が使用されました。このデータセットは、数学的推論、コード生成、科学的推論、指示の理解、一般的なチャットなど、さまざまなタスクからのプロンプトと、それに対応するCoT推論過程と応答のペアで構成されています。
Observations(観測結果)
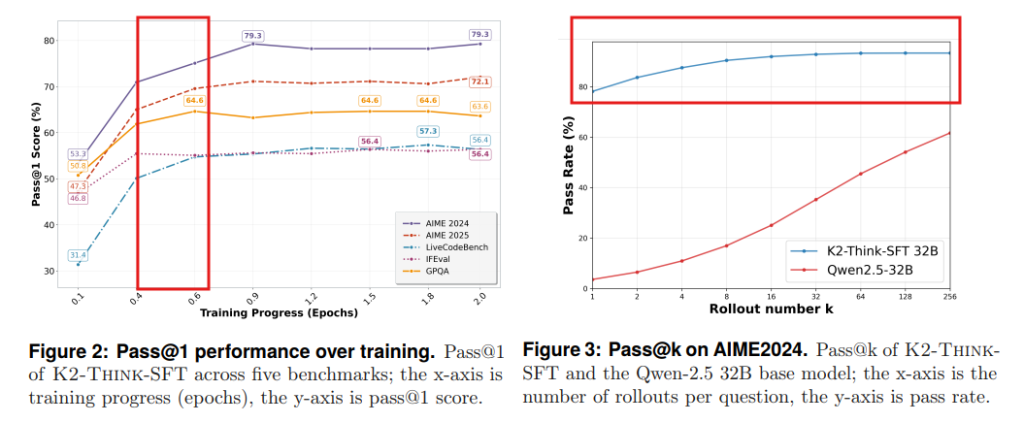
SFTの実験では、いくつかの実用的な洞察が得られました。特に、訓練開始から最初の約0.5エポック(訓練データの約半分)で性能が急速に向上することが確認されました(Figure2参照)。数学ベンチマーク(AIME 2024およびAIME 2025)ではこの傾向が顕著で、その後はほとんどのベンチマークで性能が安定します。また、単一の出力だけでなく、複数の出力を生成してその中から最適なものを選ぶ「Pass@k」という評価指標で見ると、SFTモデルはベースモデルを圧倒する性能向上を示しました(Figure3参照)。これは、続く強化学習(RL)フェーズでのさらなる改善の余地を示唆しています。
2.2 Phase 2: Reinforcement Learning with Verifiable Rewards(フェーズ2: 検証可能な報酬を用いた強化学習)
SFT段階に続いて、K2-Thinkは検証可能な報酬を用いた強化学習(RLVR)によってさらに訓練されます。RLVRは、従来の人間からのフィードバックによる強化学習(RLHF)の複雑さとコストを削減するために考案された手法です。RLHFでは人間がモデルの出力を評価してフィードバックを与えますが、RLVRではモデルの生成結果の「正しさ」を直接、自動で検証できるような報酬を用いることで、より効率的に学習を進めます。これにより、モデルは数学やコードといった検証可能な結果を持つドメインで卓越した性能を発揮するように調整されます。
K2-ThinkのRLVRでは、Guruデータセット が使用されました。このデータセットは、数学、コード、科学、論理、シミュレーション、表形式のタスクを網羅する約92,000の検証可能なプロンプトから構成されています。RLVRの実装には、verlライブラリとGRPOアルゴリズムが利用されました。
Observations(観測結果)
RLVRの訓練からは、以下の2つの重要な観測結果が得られました。
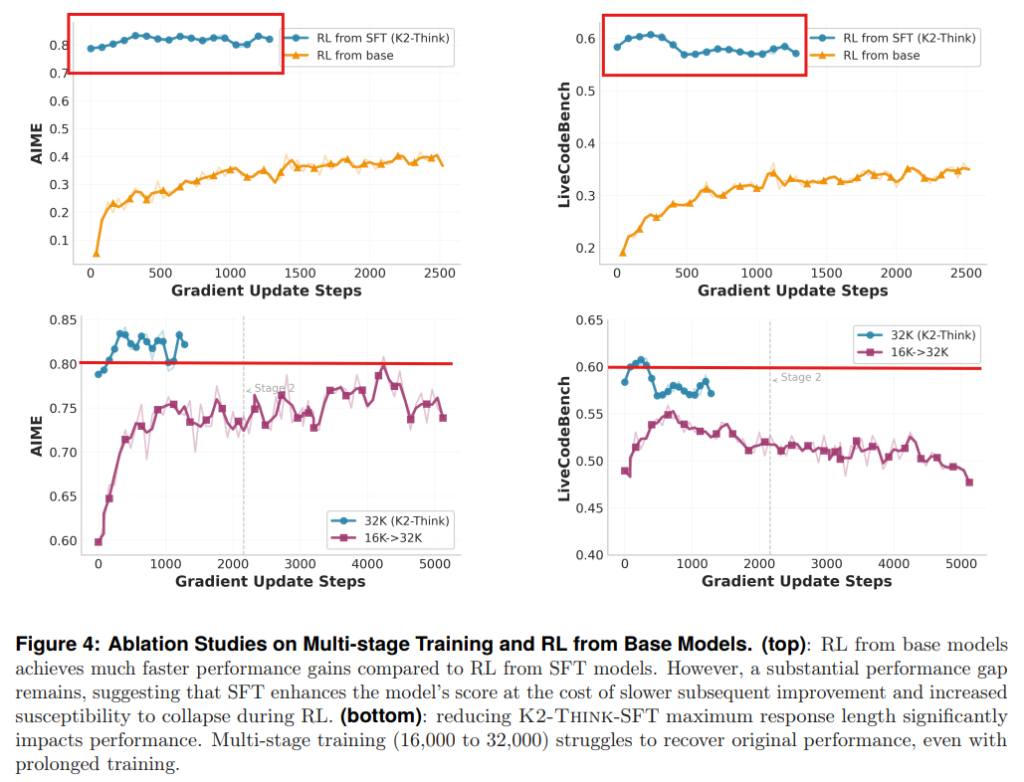
- SFTで強力なモデルから開始すると性能は良いが、RLによる改善の余地は限定される: 強力なSFTチェックポイントからRLを開始すると、最終的に高い性能が得られますが、RLによる絶対的な性能向上は控えめでした。ベースモデルから直接RL訓練を開始した場合と比較すると、SFT済みモデルからのRLは、RLによる性能向上の幅が小さくなることが示されました(Figure4上部参照)。これは、SFTによってモデルの思考戦略の探索能力が制限され、RLによる意味のある適応が難しくなる可能性があることを示唆しています。
- 初期の文脈長を減らした多段階RL訓練は性能を低下させる: 一部の研究では、多段階訓練で文脈長(モデルが一度に処理できる情報の長さ)を段階的に増やすことで学習を加速させる手法が試みられています。しかし、K2-Thinkでは、SFT段階で訓練された最大文脈長(32,000トークン)を下回る16,000トークンでRL訓練を開始し、その後32,000トークンに戻すという多段階アプローチを試みたところ、ベースラインのSFTモデルの性能すら超えることができませんでした(Figure4下部参照)。これは、SFTで確立された推論パターンが文脈長の変化によって乱された可能性があり、データフィルタリングを行わない限り、文脈長を短縮する多段階訓練は性能を損なう可能性があることを示唆しています。ただし、SFTの文脈長を超える拡張(例えば32kから48k)については評価されていません。
2.3 Phase 3: Test-time Improvement(フェーズ3: テスト時改善)
K2-Thinkの性能をさらに向上させるため、推論時にモデルの応答生成を支援する「テスト時スキャフォールディング」が開発されました。これには、既存の手法と新しいアプローチが統合されています。このフェーズでは、以下の2つの主要な技術が導入されました。
- “Plan-Before-You-Think”(思考前のプランニング)
- Best-of-N (BoN) sampling(Best-of-Nサンプリング)
これらのプロセスは、ユーザーからのクエリが最終的な応答として出力されるまでの情報フローを構成します(Figure5参照)。

“Plan-Before-You-Think”(思考前のプランニング)
これはK2-Thinkの推論時計算における最初のステップです。クエリがモデルに渡される前に、外部の指示チューニングされたLLM(Language Model)を使って、クエリから主要な概念を抽出し、高レベルのプラン(計画)を作成します。この生成されたプランは元のクエリに追加され、構造化されたプロンプトとしてK2-Thinkモデルに提供されます。重要なのは、このプランニングエージェントは直接的な答えや推論過程を提供せず、あくまで「思考」のガイドラインとなる高レベルな構造を示すことに限定されている点です。心理学や認知科学においても、計画と推論は人間の認知と意思決定の二重プロセスと考えられており、計画は思考を導くための構造を開発するメタ思考プロセスとされています。
Best-of-N (BoN) sampling(Best-of-Nサンプリング)
Best-of-Nサンプリング(繰り返しサンプリングとも呼ばれる)は、与えられたプロンプトに対してLLMがN個の独立した出力を生成し、その中から報酬モデル(またはベリファイア)が、正確性、一貫性、人間の好みへの適合性などの指標に基づいて最適なものを選択する手法です。この戦略は、複数の可能性を効果的に探索し、最も有望な出力を選択することを可能にします。K2-Thinkでは、N=3という比較的少ないサンプリング数で、費用対効果の高い改善を実現しています。選択プロセスは、独立したLLMが候補となる応答をペアで比較し、劣る方を破棄するという方法で行われます。
Observations(観測結果)
推論時の改善に関する実験では、いくつかの洞察が得られました。
- シンプルな調整の限界: 温度チューニング(生成されるテキストのランダム性を調整するパラメータ)や、フューショット学習、ロールプレイング、状況設定プロンプトなどのプロンプトエンジニアリングといったシンプルな調整では、顕著な性能向上は見られませんでした。
- 洗練されたテスト時スケーリングの有効性: より洗練されたテスト時スケーリング手法として、Best-of-N(BoN)とMixture of Agents(MoA)が最も顕著な改善をもたらしました。MoAはわずかに優れた性能を示したものの、計算コストが非常に高いため、K2-Thinkシステムでは最終的にBoNが採用されました。
2.4 Deploying K2-Think(K2-Thinkの展開)
K2-Thinkは、Cerebras Wafer-Scale Engine(WSE)システムにデプロイされ、推測デコーディング(Speculative Decoding)技術と組み合わせることで、推論システムとして前例のない推論速度を実現しています。これらはK2-Thinkの最後の2つの柱を構成します。
- Cerebras Wafer-Scale Engine (WSE):
WSEは、世界最大のプロセッサであり、一般的なNVIDIA H100/H200 GPUと比較して、約10倍の2,000トークン/秒という推論速度を達成します。この劇的な速度向上は、長大なCoT推論の実用性を根本的に変えます。例えば、32,000トークンという一般的な複雑な推論タスク(数学の証明や多段階コーディング問題など)の場合、H100では約3分かかる処理が、WSEではわずか16秒で完了します。
この性能優位性は、WSEのユニークなアーキテクチャに由来します。GPUが各トークン生成のたびに高帯域幅メモリからGPUコアへ重みを繰り返し転送する必要があるのに対し、WSEはすべてのモデルの重みをチップ上の大容量メモリに保持します。これにより、メモリ帯域幅のボトルネックが解消され、特に逐次的にトークンを生成する自己回帰モデルの推論速度が大幅に向上します。この効率は、Best-of-Nサンプリングやエージェントベースの多段階推論ワークフローにおいて特に重要です。これらのワークフローでは複数の応答生成や順次呼び出しが必要となるため、遅延の連鎖を防ぎ、インタラクティブな利用を可能にします。 - Speculative Decoding(推測デコーディング):
Speculative Decodingは、推論速度をさらに向上させる技術です。これは、より小さな「ドラフトモデル」を使って次のトークンシーケンスを推測し、その推測をより大きな「ターゲットモデル」でまとめて検証することで、生成速度を大幅に向上させる手法です。これにより、生成処理におけるシーケンシャルなボトルネックを軽減し、高速応答時間を実現します。
K2-Thinkは、Cerebras WSEの高速な推論能力と推測デコーディングを組み合わせることで、単に最先端の推論能力を提供するだけでなく、実用的なアプリケーションに必要な応答性も兼ね備え、複雑なAI推論をインタラクティブな用途で真に利用可能にしています。
3 K2-Think Evaluation(K2-Thinkの評価)
K2-Thinkは、数学、コード、科学に焦点を当てた困難な推論ベンチマークにおいて、オープンウェイトモデルとプロプライエタリモデルの両方と比較して評価されました。この評価の目的は、K2-Thinkが320億パラメータという比較的控えめなモデルサイズとテスト時計算量にもかかわらず、オープンソース推論モデルの最前線を押し広げる能力を示すことでした。特に複雑な数学タスクにおいて非常に高い能力を持つことが示されました(Table1参照)。
K2-Thinkは、以下のベンチマークで評価されました。
- Math(数学)
- AIME 2024, AIME 2025: アメリカ招待数学試験の2024年版と2025年版。
- HMMT25: Harvard-MIT Mathematics Tournament February 2025のコンテストから抽出された問題。
- Omni-MATH-HARD: Olympiadレベルの数学コンテストから抽出された最難関問題。
- Micro-Avg.: 上記の全数学データセットの質問総数に対する正答数の割合。
- Code(コード)
- LiveCodeBench (LCBv5): オンラインプラットフォームから集約されたプログラミング課題。
- SciCode: 科学研究の質問に対するコード生成能力を評価するベンチマーク。
- Science(科学)
- GPQA-Diamond (GPQA-D): 専門家によって作成された「Google-proof」(検索してもすぐには答えが見つからない)な高度な多肢選択問題。
- Humanity’s Last Exam (HLE): 専門家によって開発された、明確で検証可能な2500問の多肢選択/短答問題。
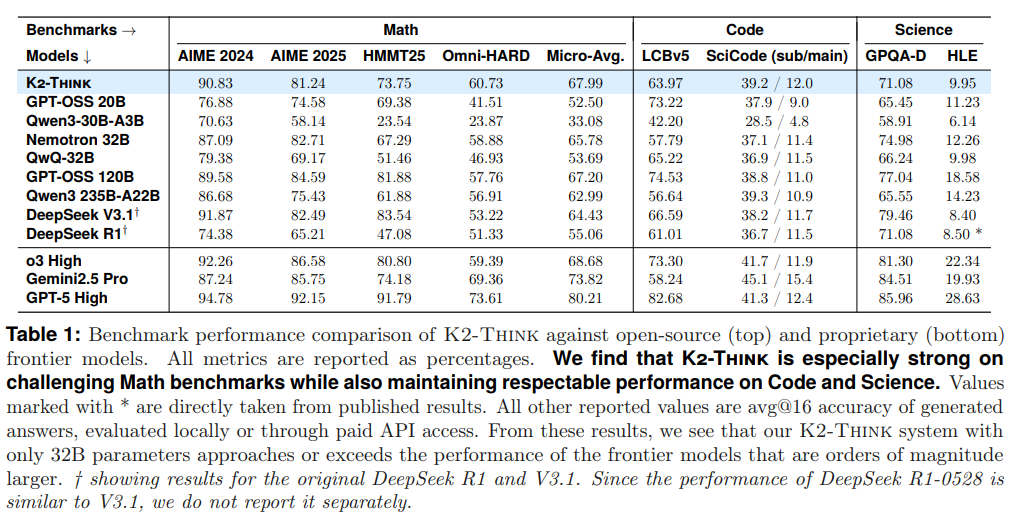
K2-Think excels in competition math questions.(K2-Thinkは競争数学問題で優れている。)
K2-Thinkは、すべての数学問題において平均マイクロアベレージスコア67.99%を達成しました。これは、GPT-OSS 20B (52.50%)、Qwen3-30B-A3B (33.08%)、OpenReasoning-Nemotron-32B (65.78%) といった同等またはやや大きいサイズのモデルと比較して、顕著に優れた結果です。さらに、K2-Thinkの数学スコアは、DeepSeek V3.1 671B (64.43%) やGPT-OSS 120B (67.20%) といった、桁違いに大きな最先端のオープンソースモデルをも上回っています。特に、Omni-MATH-HARD (60.73%) という最も難しい問題を含むベンチマークでも優れた性能を発揮しており、オープンソースモデルの中で数学的推論においてトップの座を占め、o3 Highのような強力なプロプライエタリモデルにも肉薄しています。
K2-Think is versatile in Science and Coding domains.(K2-Thinkは科学およびコーディング領域で多用途である。)
K2-Thinkは、コーディングと科学の分野でも堅牢で競争力のある能力を示しており、その多用途性が裏付けられました。LiveCodeBenchでは63.97%のスコアを達成し、同サイズのモデル群を大きく上回ります。SciCodeベンチマーク(サブ問題)では39.2%を達成し、Qwen3 235B-A22Bに次ぐ性能です。GPQA-Diamondベンチマークでは71.08%の性能を示し、ほとんどのオープンソースモデルよりも優れています。HLEスコアは9.95%と最高ではありませんが、幅広い知識ベースを示唆する立派な結果です。これらの多様なドメインでの強力な性能は、K2-Thinkが単なる専門家ではなく、幅広い分析的および知識集約型タスクに高い効率で取り組むことができる多用途モデルであることを示しています。
このレベルのパラメータ効率、特に複雑な数学的推論タスクにおけるベンチマーク性能は、特筆すべき成果です。
Component Analysis of K2-Think Test-Time Computation(K2-Thinkテスト時計算のコンポーネント分析)
テスト時計算の各要素が最終性能にどのように貢献しているかを分析するため、ポストトレーニング済みのチェックポイントに各手順を単独で適用する実験が行われました。SFTとRLを実行した後、評価時に高レベルプランニングによるプロンプト再構築、またはBest-of-3リサンプリングと検証のみを適用した結果がTable2に示されています。
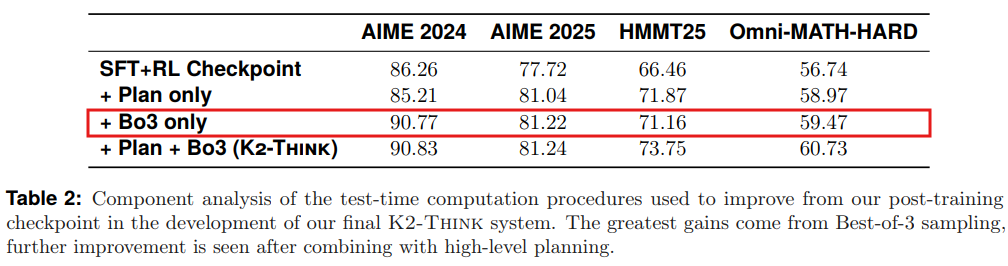
この分析から、ポストトレーニング済みチェックポイントからの改善の大部分は、Best-of-Nスケーリング(ここでは3つのサンプル生成のみ)によってもたらされることが分かりました。高レベルプランを含む入力プロンプトの再構築も単独で性能向上に寄与しますが、その効果は限定的です。しかし、これら2つのコンポーネントを組み合わせることで、全体的なテスト時手順はすべてのベンチマークで4〜6パーセンテージポイントの顕著な性能向上をもたらしています。
“Plan-Before-You-Think” Reduces Response Lengths(「思考前のプランニング」が応答長を短縮)
「思考前のプランニング」は、推論性能に良い影響を与えるだけでなく、興味深いことに応答の長さも短縮することが分かりました。K2-Thinkのポストトレーニング済みチェックポイントと完全なシステム(テスト時計算を含む)を比較したTable3から、プランニングの導入によって応答の品質が向上し、さらにトークン使用量が最大で約12%削減されることが示されています。これにより、K2-Thinkはより簡潔な回答を提供できることになります。
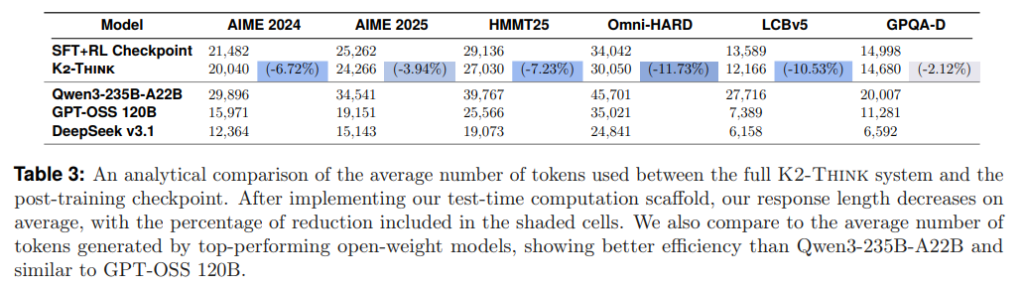
他の高性能オープンウェイトモデルと比較しても、K2-Thinkの応答はQwen3-235-A22Bよりも大幅に短く、数学的推論においてはGPT-OSS 120Bの応答と近い範囲にあります。コードと科学のドメインでは、Qwen3-235B-A22Bよりは短いものの、GPT-OSS 120Bよりは長いという結果でした。
3.1 Red-teaming K2-Think(K2-Thinkのレッドチームテスト)
モデルの安全な運用を保証することは、オープンリリースにおいて不可欠です。K2-Thinkは、既存の公開安全性ベンチマークを用いて、敵対的プロンプト、有害コンテンツ、堅牢性ストレステストに対して体系的に評価されました。評価結果は、展開における最も関連性の高い実用的な安全性の側面を捉えるために、以下の4つの主要な観点に集約されています。
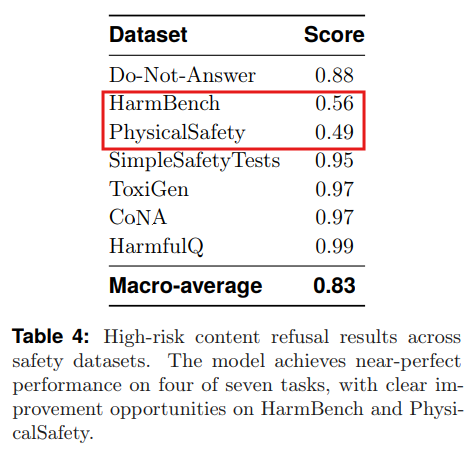
High-Risk Content Refusal(高リスクコンテンツの拒否):
安全でない、または有害な出力に対する直接的な要求を拒否する能力。Table4に示すように、7つのベンチマークのうち4つでほぼ完璧なスコアを達成しました。ただし、HarmBenchとPhysicalSafetyでは、サイバーまたは物理的なリスクの認識に弱点が見られました。
Conversational Robustness(会話の堅牢性):
複数ターンの対話において、一貫して安全な振る舞いを維持する能力。Table5に示すように、DialogueSafetyとHH-RLHFベンチマークではほぼ完璧な拒否の一貫性を示し、持続的な敵対的対話や有害な振る舞いを引き出そうとする試みに対して特に堅牢であることが示されました。
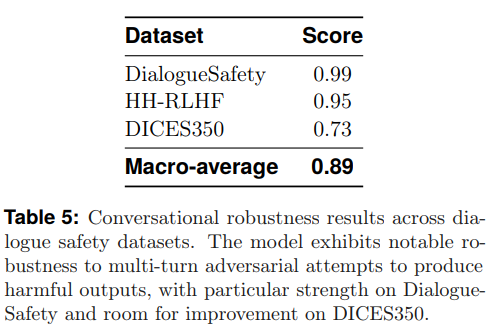
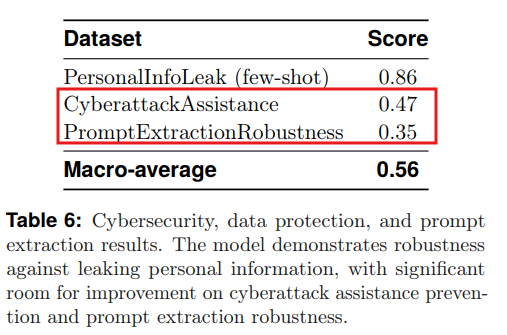
Cybersecurity & Data Protection(サイバーセキュリティとデータ保護):
情報漏洩、プロンプト抽出、サイバー攻撃支援に対する耐性。Table6に示すように、個人を特定する情報の抽出に対する耐性は示されたものの、システムプロンプトの開示やサイバー攻撃計画の支援に対しては、ある程度の脆弱性があることが示されました。
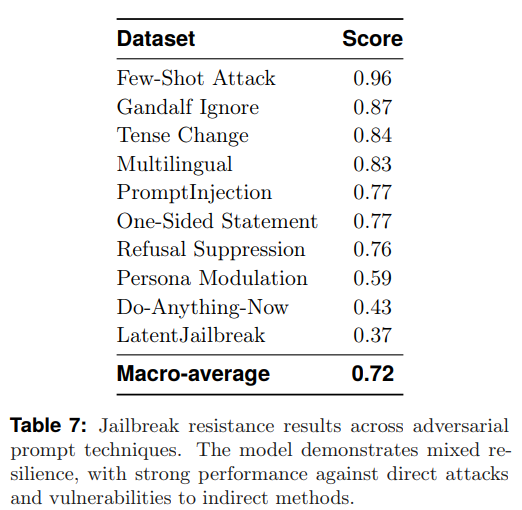
Jailbreak Resistance(ジェイルブレイク耐性):
保護メカニズムを迂回するように設計された敵対的攻撃に対する堅牢性。Table7に示すK2-Thinkのジェイルブレイク耐性の結果は、堅牢性と脆弱性が混在していることを示しています。直接的な攻撃に対しては強い性能を示しますが、間接的な攻撃に対しては明らかな弱点が見られました。
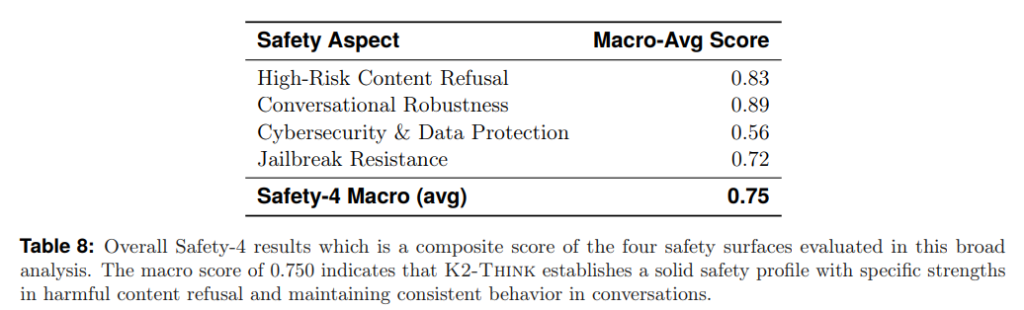
全体として、K2-ThinkはSafety-4マクロスコア0.750を達成しました(Table8参照)。これは、有害コンテンツの拒否と会話の一貫性維持において強力な性能を持つ、堅実な安全性のベースラインを示しています。同時に、サイバーセキュリティ防御、ジェイルブレイク耐性、拒否のキャリブレーション(調整)を強化するためのさらなる作業が必要であることも認識されており、これらの領域は今後の改善ロードマップにおいて積極的な優先事項とされています。
4 Related Work(関連研究)
K2-Thinkの開発は、既存の研究の上に成り立っています。
- SFTによる基盤言語モデル機能の拡張:SFTは、大規模言語モデルの能力を拡張するための一般的な手法となっています。最近では、数学、コード、科学といった多様な下流タスクにおける複雑な推論能力の向上に焦点が当てられています。K2-Thinkは、この流れに沿って、長大なCoT能力をモデルに組み込むために、大規模な推論トレースデータセット(AM-Thinking-v1-Distilled)を使用しています。
- RLによるLLM推論の改善:検証可能な報酬を用いた強化学習(RLVR)も、LLMの推論能力向上に強力なパラダイムとして登場しています。Open-Reasoner-ZeroやDeepScalerのような取り組みは、広範な数学的データを利用して複雑な数学ベンチマークで最先端の性能を達成しています。K2-Thinkは、Guruデータセットを用いて数学やコードに留まらない多様なドメインでのRL訓練に取り組んでおり、General-ReasonerやNemotron-CrossThinkerといった同時期の研究とも関連します。ただし、K2-Thinkは、これらの研究が探求していない「テスト時計算」の追加的な有用性も探求しています。
- テスト時スケーリング:テスト時スケーリングは、O1、Grok Heavy、Gemini 2.5、GPT-5といったプロプライエタリモデルの主要なコンポーネントとして注目されていますが、その具体的な要素や全体的な効果については透明性が低いのが現状です。K2-Thinkは、PlanGENのような計画と推論を組み合わせたマルチモデルフレームワークと関連しており、特に「思考前のプランニング」という階層的推論アプローチと、生成された応答に対するBest-of-Nとベリファイアの組み合わせが独自性を持っています。
5 Discussion(考察)
5.1 Primary technical insights(主要な技術的洞察)
K2-Thinkの開発を通じて、いくつかの重要な技術的洞察が得られました。
- 多様なドメインでのポストトレーニングの重要性:推論モデルのポストトレーニングにおいては、複数のドメインを含めることが重要です。事前学習で一般的なドメイン(数学、コード、科学)は、多様なポストトレーニングデータから広く恩恵を受けます。これは、モデルが既に持っている知識が思考連鎖の洗練をサポートするためです。しかし、事前学習で限定的な露出しか受けていないドメイン(論理、シミュレーションなど)は、RL訓練パイプラインに含められた場合にのみ改善が見られました。このことから、真に多用途な推論モデルを開発するには、多様なマルチドメインデータセットの使用が不可欠であると言えます。
- テスト時計算性能向上は適切な組み合わせで相乗効果を発揮する:K2-Thinkの「思考前のプランニング」というプロンプト再構築と、Best-of-Nスケーリングという二つのシンプルなテスト時計算手順は、うまく連携し、相乗効果を発揮することが分かりました。個々の方法でも性能は向上しますが、これらのコンポーネントを組み合わせたときに最大の性能向上が見られます。入力と関連する主要な概念に焦点を当てた高レベルな計画を抽出し、わずか3つの候補応答をサンプリングするだけで、大幅な改善が得られることは驚くべきことです。
- 「思考前のプランニング」はモデル性能を向上させつつトークン消費を削減する:モデルに推論プロセスを開始する前に計画を立てることを要求することで、2つの利点が得られました。計画そのものが応答品質を向上させ、さらに応答の長さが約12%削減されます。
5.2 Looking forward(今後の展望)
小さなモデルが「期待以上の活躍」を可能にする
K2-Thinkは、320億パラメータ規模のモデルが、長大なCoTを生成するようにポストトレーニングされ、比較的少量のテスト時計算と組み合わせることで、桁違いに多くのパラメータを持つモデルに匹敵する能力を付与できることを示しました。このエンドツーエンドの推論システムは、現在のオープンソース機能の最前線の性能を解き放ちます。
オープンソース活動の拡大
開発チームは、データ、モデル、トレーニング成果物だけでなく、完全な推論システムを一般公開することで、オープンソース活動の限界を拡張しています。K2-Thinkのテスト時計算実装も公開されており、APIとオンラインウェブポータルを通じて広く利用可能です。これは、「公共のLLMインフラをどのように『実地で試す』のが最適か」を探求する道を開くものです。
K2-Thinkは、オープンサイエンスを通じてファウンデーションモデルの研究開発へのアクセスを広げる、進行中の取り組みにとって魅力的な足がかりとなります。開発チームがK2-Thinkを一般公開する動機は、大規模なファウンデーションモデル向けに推論システムをどのように設計するのが最適かという好奇心に基づいています。また、より大規模なオープンソースモデルをスケールアップしていく中で、単に重みとトレーニング成果物を公開するだけでは、それをホストしたり操作したりできる機関や組織が少なくなり、有用性が低下する時期が来るでしょう。能力の高いオープンモデルを開発するという研究機関としての創設理念に反しないよう、モデル開発とデプロイメントの可能な限り多くの部分を公開し、誰もが貢献したり、その上に構築したりできるようにすることにコミットしています。K2-Thinkのデプロイメントから得られる教訓は、より大きく、より有能なモデルの継続的な開発にとって極めて重要となるでしょう。
まとめ
今回ご紹介した「K2-Think」は、320億パラメータという比較的小さなモデルでありながら、高度なポストトレーニングと推論時計算の革新的な組み合わせにより、最先端の大規模モデルに匹敵する、あるいはそれを超える推論性能を実現した画期的なシステムです。特に数学的推論においてその強さが際立ち、オープンソースモデルの領域に新たな基準を打ち立てました。
K2-Thinkが採用した「長大な思考連鎖(CoT)SFT」や「検証可能な報酬を用いた強化学習(RLVR)」は、モデルの基礎的な推論能力を大幅に強化します。さらに、推論時に実行される「思考前のプランニング(Plan-Before-You-Think)」と「Best-of-Nサンプリング」は、モデルの出力を洗練させ、より正確で簡潔な回答を導き出します。そして、Cerebras Wafer-Scale Engineと推測デコーディングによるデプロイメントは、これらの高度な推論能力を実用的な速度で提供し、ユーザー体験を変える可能性を秘めています。
K2-Thinkの成功は、必ずしもモデルのサイズだけが性能を決定するわけではないことを明確に示しています。巧妙なエンジニアリングと技術の統合によって、よりパラメータ効率の高いモデルでも最上位レベルの性能を発揮できることが証明されたのです。これは、大規模な計算資源を持たない研究者や開発者にとっても、高性能なAI推論システムへのアクセスを可能にし、オープンソースAIの発展を加速させる大きな一歩となるでしょう。 K2-Thinkは、モデルの重み、コード、そして実際に動作するウェブサイトとAPIとして公開されています(https://www.k2think.ai)。