
はじめに
本稿では、Google Researchが開発した大規模言語モデル(LLM)の課題であるハルシネーション(事実に基づかない情報の生成)を抑制し、回答の事実精度を向上させるデコーディング手法「SLED (Self Logits Evolution Decoding)」について、その仕組みから利用方法までを解説します。
参考記事
- 発行元: Google Research
- タイトル: Making LLMs more accurate by using all of their layers
- 発行日: 2025年9月17日
- URL: https://research.google/blog/making-llms-more-accurate-by-using-all-of-their-layers/
参考論文
- 論文: SLED: Self Logits Evolution Decoding for Improving Factuality in Large Language Models
- 論文URL: https://arxiv.org/abs/2411.02433
参考コード
- 公式GitHubページ: https://github.com/JayZhang42/SLED
要点
- SLEDは、LLMのハルシネーション問題に対処するために開発された新しいデコーディング手法である。
- 外部の知識データベースや追加のファインチューニングを必要とせず、モデルが元々持っている内部知識のみを利用して事実精度を高める。
- テキストを生成する際、一般的な手法が利用する「最終層」の情報だけでなく、モデル内部にある「すべての中間層」の情報を活用する。
- 各層の予測を統合することで、より事実に即した、信頼性の高い回答を生成することが可能になる。
- 既存の多くのオープンソースLLMに適用可能でありながら、推論速度への影響は軽微である。
詳細解説
LLMの課題「ハルシネーション」とは
大規模言語モデル(LLM)は、非常に流暢で人間らしい文章を生成できますが、時として事実と異なる内容を、さも真実であるかのように自信を持って回答してしまうことがあります。この現象は「ハルシネーション」と呼ばれ、LLMを実用的なアプリケーションで利用する上での大きな課題となっています。
ハルシネーションは、不完全または偏った学習データ、曖昧な質問など、様々な要因で発生します。この問題への対策として、外部の信頼できるデータベースを参照しながら回答を生成する「RAG (Retrieval Augmented Generation)」などの技術がありますが、システムが複雑になるという側面も持ち合わせています。
回答生成の最終工程「デコーディング」に着目
SLEDが着目したのは、LLMが回答を生成するプロセスの最終段階である「デコーディング」です。デコーディングとは、モデル内部の複雑な数値データ(予測スコア)を、私たちが読める実際のテキスト(単語や文字)に変換する工程を指します。
SLEDは、このデコーディングのプロセスに介入し、モデルが持つ知識を最大限に引き出すことで、ハルシネーションを抑制しようと試みます。
SLEDの仕組み:すべての層から知識を引き出す
LLMは、入力されたテキストを理解し、次の単語を予測するために、複数の「層(レイヤー)」で情報を処理します。従来のデコーディング手法では、この多層構造の最後の層(最終層)の出力だけを使って、次にどの単語が来る確率が高いかを判断していました。
しかし、最終層の予測は、時に一般的でよく知られているが、文脈上は不正確な回答に偏ってしまうことがあります。
一方でSLEDは、最終層だけでなく、そこに至るまでのすべての中間層の出力も活用します。各層が持つ予測情報を重み付けして平均することで、モデル全体の「総意」を形成し、より慎重で事実に即した単語を選択するのです。
具体例:ブリティッシュコロンビアの州都は?
例えば、LLMに「ブリティッシュコロンビアの州都は?」と質問したとします。
- 通常のLLM: 世界的に有名な「バンクーバー」という単語が予測されやすい傾向があります。これは、最終層が最も一般的で人気の高い回答を選びがちだからです。
- SLEDを使ったLLM: 中間層の多くは、文脈をより正確に捉え、正しい州都である「ビクトリア」を予測しています。SLEDはこれらの中間層の「声」を拾い上げ、最終的な回答を「ビクトリア」へと導きます。
このように、SLEDはモデル内部の多様な視点を取り入れることで、一時的な人気の高さに惑わされず、より本質的な知識に基づいた回答を生成します。
SLEDの有効性
SLEDの有効性は、様々なLLM(Gemma, GPT-OSS, Mistralなど)と、事実精度を測るための複数のベンチマークテスト(FACTOR, TruthfulQAなど)で実証されています。
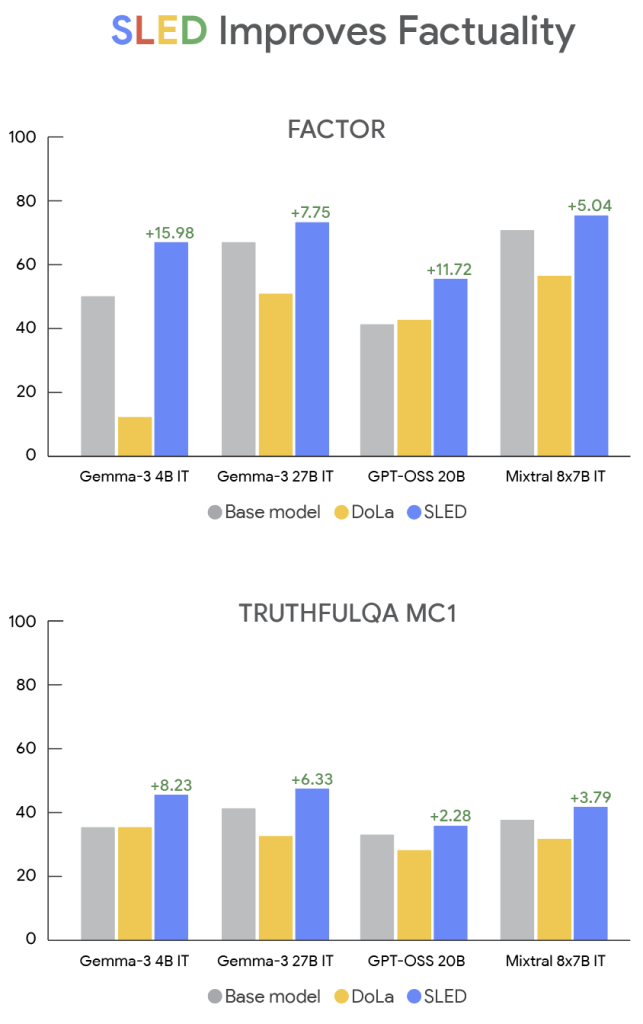
実験結果によると、SLEDはベースとなるモデルや、既存の他のデコーディング手法と比較して、事実精度を最大で16%向上させました。また、これだけ精度を向上させながらも、回答生成にかかる時間(推論レイテンシ)の増加はごくわずかに留まっています。
SLEDを実際に利用する方法
SLEDはオープンソースとしてコードが公開されており、誰でも利用することができます。以下に、GitHubリポジトリに記載されている実行コマンドの一例を紹介します。
1. 環境設定
まず、公式のGitHubリポジトリからコードをクローンし、必要なライブラリをインストールします。
# PyTorchのインストール (バージョン指定)
pip3 install torch==2.0.1 --index-url [https://download.pytorch.org/whl/cu118](https://download.pytorch.org/whl/cu118)
# Transformersライブラリのインストール
pip install -e transformers
# その他の依存関係
pip install -r requirements.txt2. 評価の実行
run_factor.pyなどのスクリプトを用いて、任意のモデルでSLEDを適用した評価を実行できます。
# Llama-2-7bモデルを使い、FACTORデータセットでSLEDを評価する例
python run_factor.py \
–model-name meta-llama/Llama-2-7b-hf \
–data-path Data/FACTOR/wiki_factor.csv \
–output-path output-path.json \
–num-gpus 1 \
–decoding_method SLED \
–evolution_rate 2 \
–evolution_scale 10
decoding_methodにSLEDを指定し、evolution_rateやevolution_scaleといったパラメータを調整することで、SLEDの挙動を制御できます。
まとめ
本稿で紹介したSLEDは、外部データや追加学習に頼ることなく、LLMが本来持つポテンシャルを最大限に引き出すことで、ハルシネーションを抑制し、事実精度を向上させる画期的なデコーディング手法です。
既存の多くのモデルに簡単に適用でき、計算コストの増加も軽微であるため、LLMの信頼性を高めるための実用的な選択肢となる可能性があります。今後の研究では、画像認識やコード生成といった、さらに多様なタスクへの応用が期待されています。








