
はじめに
本稿では、大規模言語モデル(LLM)を特定のタスクに適応させる「ファインチューニング」に必要な訓練データを、劇的に削減する新しい技術について解説します。AI、特にLLMの性能向上には大量のデータが必要不可欠ですが、その収集と品質維持には莫大なコストがかかるという課題がありました。
今回、Google Researchが発表したブログ記事「Achieving 10,000x training data reduction with high-fidelity labels」を基に、訓練データの量を最大で10,000分の1にまで削減しつつ、モデルの性能を維持、あるいは向上させる新しいアプローチを紹介します。
参考記事
- タイトル: Achieving 10,000x training data reduction with high-fidelity-labels
- 著者: Markus Krause, Nancy Chang
- 発行元: Google Research
- 発行日: 2025年8月7日
- URL: https://research.google/blog/achieving-10000x-training-data-reduction-with-high-fidelity-labels/
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- Googleは、LLMのファインチューニングに必要な訓練データを大幅に削減する新しいアクティブラーニングの手法を開発した。
- この手法により、訓練データの量を最大1/10,000(例:10万件から10件程度)に削減しつつ、モデルの性能を維持または向上させることが可能である。
- 鍵となるのは、モデルが最も「混乱」しているデータ、つまり判断の境界線上にあるデータを効率的に特定し、その価値の高いデータのみを専門家がラベリング(アノテーション)することである。
- 品質評価には、絶対的な正解の存在を前提としない「コーエンのカッパ係数」を使用し、専門家同士の一致度と、モデルと専門家の一致度を客観的に測定している。
- 実験では、より大きなモデル(32.5億パラメータ)において、この手法が特に有効であり、専門家との一致度が最大65%向上したことが示された。
詳細解説
背景:LLMファインチューニングの大きな課題
不適切な広告コンテンツの検出やフェイクニュースの分類など、複雑でニュアンスが求められるタスクにLLMを応用する試みが進んでいます。これらのタスクで高い性能を発揮させるには、LLMをそのタスク専用に調整する「ファインチューニング」というプロセスが欠かせません。
しかし、ファインチューニングには大きな課題があります。それは、専門家によって注意深く作成された高品質な訓練データが、膨大な量必要になるという点です。質の高いデータを大量に集める作業は、非常にコストと時間がかかります。特に、広告の安全基準のようにポリシーが頻繁に変わったり、新しいタイプの不適切コンテンツが次々と現れたりする(このような現象をコンセプトドリフトと呼びます)分野では、その都度モデルを再学習させる必要があり、コストの問題はさらに深刻化します。この「データ収集のボトルネック」をいかに解消するかが、LLMを社会実装する上で重要な鍵となっていました。
提案手法:賢くデータを選ぶ「キュレーションプロセス」
この課題を解決するため、Googleはアクティブラーニングという考え方に基づいた、新しいデータ選別(キュレーション)プロセスを開発しました。アクティブラーニングとは、学習アルゴリズムが人間(または他の情報源)に対話的に問い合わせを行い、新しいデータポイントに望ましい出力をラベル付けしてもらう、機械学習の特殊な手法です。ここでは、モデルの学習に最も効果的だと考えられるデータをモデルが能動的に選び出した上で、人間にラベルをつけてもらうことで、効率的に学習を進めます。
提案されたプロセスの流れは以下の通りです。
- 初期モデルによる仮ラベリング
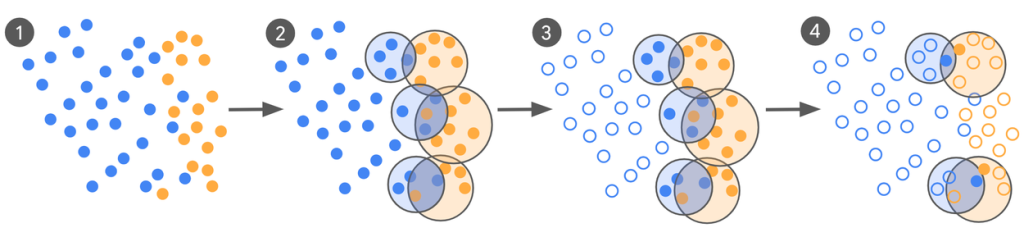
まず、簡単な指示を与えただけの初期モデル(ゼロショットまたはフューショットLLM)を使って、手元にある大量のデータに仮のラベルを付けます。例えば、「この広告はクリックベイトか?」という問いに対して、「クリックベイト」か「良性」かを判断させます。この段階では、モデルはまだ賢くないため、間違いも多く含まれます。 - クラスタリングと「混乱領域」の特定
次に、「クリックベイト」とラベル付けされたデータ群と、「良性」とラベル付けされたデータ群を、それぞれ似たもの同士でグループ分け(クラスタリング)します。すると、下の図のように、両方のクラスタが重なり合う部分が見つかります。この重なりは、モデルが「クリックベイト」と「良性」の区別に迷っている、いわば判断の境界線上のデータが集まっている領域を示しています。 - 情報価値の高いデータの抽出と専門家によるラベリング
この「混乱領域」から、異なるラベルを持つにもかかわらず、特徴が非常に似ているデータのペアを探し出します。これらはモデルが最も判断に迷った事例であり、学習にとって情報価値が非常に高いと考えられます。この選び抜かれたデータだけを人間の専門家に渡し、正確なラベルを付けてもらいます。 - 評価と再学習のサイクル
専門家によってラベリングされた貴重なデータを2つに分け、一方はモデルの性能評価に、もう一方はモデルを賢くするためのファインチューニング(再学習)に使います。このプロセスを繰り返すことで、モデルは効率的に賢くなっていきます。
評価指標:「コーエンのカッパ係数」とは?
広告が「不適切」かどうか、といった判断には、唯一絶対の正解が存在しないことがよくあります。専門家の間でも意見が分かれることがあるため、「正解率」のような単純な指標ではモデルの性能を正しく評価できません。
そこで本研究では、コーエンのカッパ係数 (Cohen’s Kappa) という統計指標を用いています。これは、2人の評価者(例えば、専門家Aと専門家B、あるいはモデルと専門家)の意見が、偶然の一致を除いてどの程度一致しているかを示す指標です。値は-1から1の範囲をとり、1に近いほど意見の一致度が高いことを意味します。これにより、客観的な正解がない問題に対しても、モデルがどれだけ専門家の判断基準に近づいたかを測定できるのです。
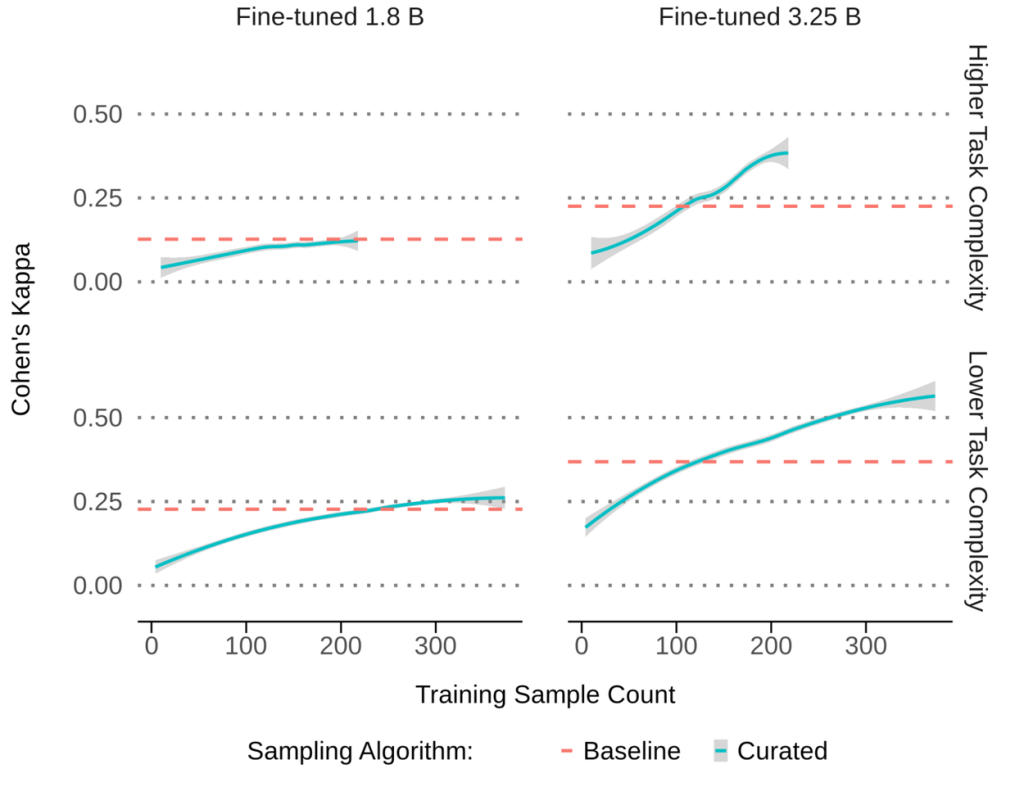
実験結果:少ないデータで大きな成果
この新しい手法の効果を検証するため、サイズの異なる2つのLLM(パラメータ数が18億と32.5億)を使って実験が行われました。
- 比較対象(ベースライン): 約10万件の、クラウドソーシングで集められたデータで学習。
- 提案手法: 上記のプロセスで厳選した、わずか数百件の専門家によるデータで学習。
その結果、特にサイズの大きいモデル(32.5億パラメータ)で、提案手法が劇的な効果を発揮しました。10万件のデータを使ったベースラインモデルよりも、わずか数百件の厳選データで学習したモデルの方が、専門家との判断の一致度(カッパ係数)が最大で65%も向上したのです。
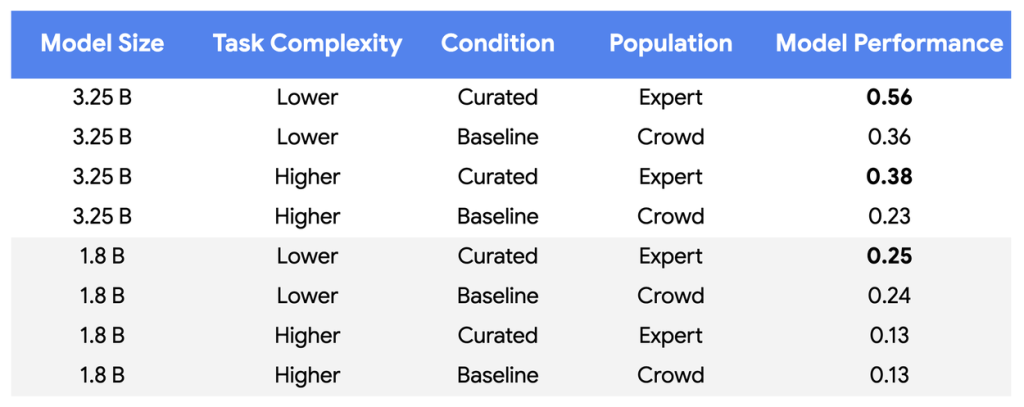
発表によれば、実際の製品に使われているさらに大きなモデルでは、訓練データを4桁、つまり10,000分の1に削減しても、品質を維持または向上させることができたと報告されています。
まとめ
本稿では、Googleが開発した、LLMのファインチューニングに必要な訓練データを劇的に削減する新しい手法について解説しました。
このアプローチの核心は、やみくもにデータの「量」を追うのではなく、モデルの学習に本当に役立つ「質」の高いデータを見極めることにあります。モデルが判断に迷う境界線上のデータ、すなわち情報価値の高いデータにリソースを集中させ、専門家の知見を最大限に活用することで、データ収集・作成のコストを大幅に削減しつつ、より高性能なモデルを育成することが可能になります。
これは、今後のAI開発において「データ中心のアプローチ」がいかに重要かを示す好例と言えるでしょう。この考え方は、LLMをより多くの分野で、より低コストで活用していくための重要な鍵となりそうです。








