
はじめに
近年、大規模言語モデル(LLM)は文章の生成や要約、翻訳といったタスクで大きな進歩を遂げています。しかし、その能力はテキスト処理だけに留まりません。言語モデルを使い、複雑なシステムの性能といった「数値」を直接予測する新しいアプローチがGoogleによって発表されました。
Google Researchが2025年7月29日に公開したブログ記事「Simulating large systems with Regression Language Models」を基に、テキストを入力して数値を予測する「回帰言語モデル(Regression Language Model, RLM)」という技術について、その仕組み、利点、そして今後の可能性を簡単に解説します。

参考記事
- タイトル: Simulating large systems with Regression Language Models
- 発行元: Google Research
- 発行日: 2025年7月29日
- URL: https://research.google/blog/simulating-large-systems-with-regression-language-models/
要点
- 大規模言語モデル(LLM)を数値予測(回帰)に応用する新手法「回帰言語モデル(RLM)」が提案された。
- RLMは、システムの設定ファイルやログといった複雑な非構造化データをテキストのまま入力として受け取り、予測したい数値をテキストとして出力する。
- 従来手法で必要だった面倒なデータの前処理(特徴量エンジニアリング)が不要になる可能性がある。
- 単一の予測値だけでなく、予測のばらつき(確率分布)や、その予測に対するモデルの自信度(不確実性)も定量化できる。
- Googleの巨大な計算基盤「Borg」の性能予測において、少ない計算リソースで高精度な予測を実現し、その有効性と汎用性の高さを示した。
詳細解説
なぜ今、言語モデルで数値予測なのか?
まず前提として、機械学習における「回帰」とは、ある入力データ(x)から、連続する数値(y)を予測するタスクを指します。例えば、「家の広さや築年数(x)」から「家の価格(y)」を予測するのが典型的な回帰です。
従来の回帰手法では、入力データ(x)を「表形式(tabular data)」に整える必要がありました。これは、各行が個別のデータサンプルを、各列が決まった特徴量(家の広さ、部屋数など)を表す、Excelシートのような形式です。
しかし、現実世界のデータは、システムの設定ファイル(YAMLやJSON形式)、サーバーのログ、実験記録など、構造が複雑で定まっていない「非構造化データ」であることがほとんどです。これらのデータを表形式に変換するには、「特徴量エンジニアリング」と呼ばれる専門的な知識と多大な労力が必要でした。どの情報を抽出し、どのように数値化すればモデルが学習しやすくなるかを人間が設計する必要があったのです。このプロセスは、新しい種類のデータが登場するたびに、一からやり直さなければならないという課題を抱えていました。
回帰言語モデル(RLM)のシンプルな仕組み
今回Googleが提案した回帰言語モデル(RLM)は、この課題を根本から解決する可能性を秘めています。そのアイデアは非常にシンプルで、「数値予測の問題を、言語モデルが得意なテキスト生成の問題として解く」というものです。
具体的には、以下のように動作します。
- 入力 (x): 予測の基となるシステムの状態(設定ファイル、パラメータ、関連情報など)を、すべて連結して一つの長いテキスト文字列としてモデルに与えます。
- 出力 (y): モデルは、そのテキスト入力を読んで、予測結果の数値をテキスト文字列として書き出します。
例えば、サーバーの性能を予測する場合、入力は「サーバー設定: {CPU: 8コア, メモリ: 32GB}, 実行中のジョブ: [A, B, C]」のようなテキストになり、出力は「予測性能: 1450.75」のようなテキストになります。
モデルの学習は、この入力テキストをプロンプト、出力テキストを正解として、通常の言語モデルと同じように「次の単語(トークン)を予測する」タスクとして行われます。これにより、人間による面倒な特徴量エンジニアリングや、数値を特定の範囲に収める正規化といった前処理が原則不要になります。
RLMがもたらす3つの重要な能力
この新しいアプローチは、単に予測が簡単になるだけでなく、従来の回帰手法では難しかった、より豊かで実用的な情報を引き出すことができます。発表では、Googleの巨大な計算クラスタ管理システム「Borg」の性能予測を例に、RLMの3つの重要な能力が示されています。
1. 予測のばらつきを捉える(確率密度の推定)
RLMは、予測を複数回行うことで、単一の数値(点予測)だけでなく、予測値がどの範囲にどのくらいの確率で分布するのか(確率密度)を捉えることができます。例えば、「性能は1500です」と断定的に予測するのではなく、「性能は1400から1600の間に収まる可能性が最も高い」といった、より現実的な示唆を得られます。これは、システムに内在するランダムな変動などを考慮した、信頼性の高い意思決定に繋がります。
2. 予測の自信度を測る(不確実性の定量化)
RLMは、予測の不確実性、つまりモデルが自身の予測にどれだけ自信を持っているかを数値化できます。予測の分布が広ければ「自信がない」、狭ければ「自信がある」と判断できます。この情報は非常に重要で、例えばモデルが「自信がない」と示した場合、人間はより慎重な判断を下したり、より時間のかかる正確なシミュレーションを実行したりするなど、状況に応じた対応を取ることができます。
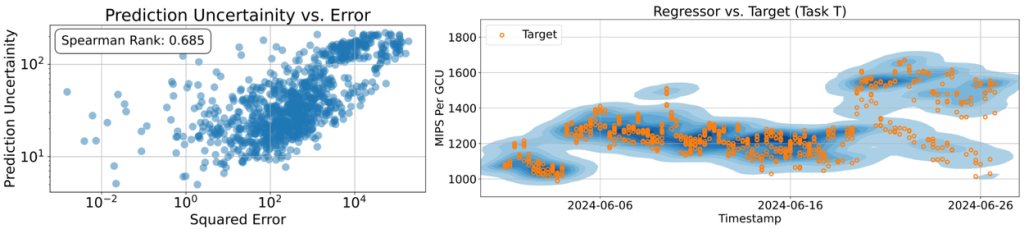
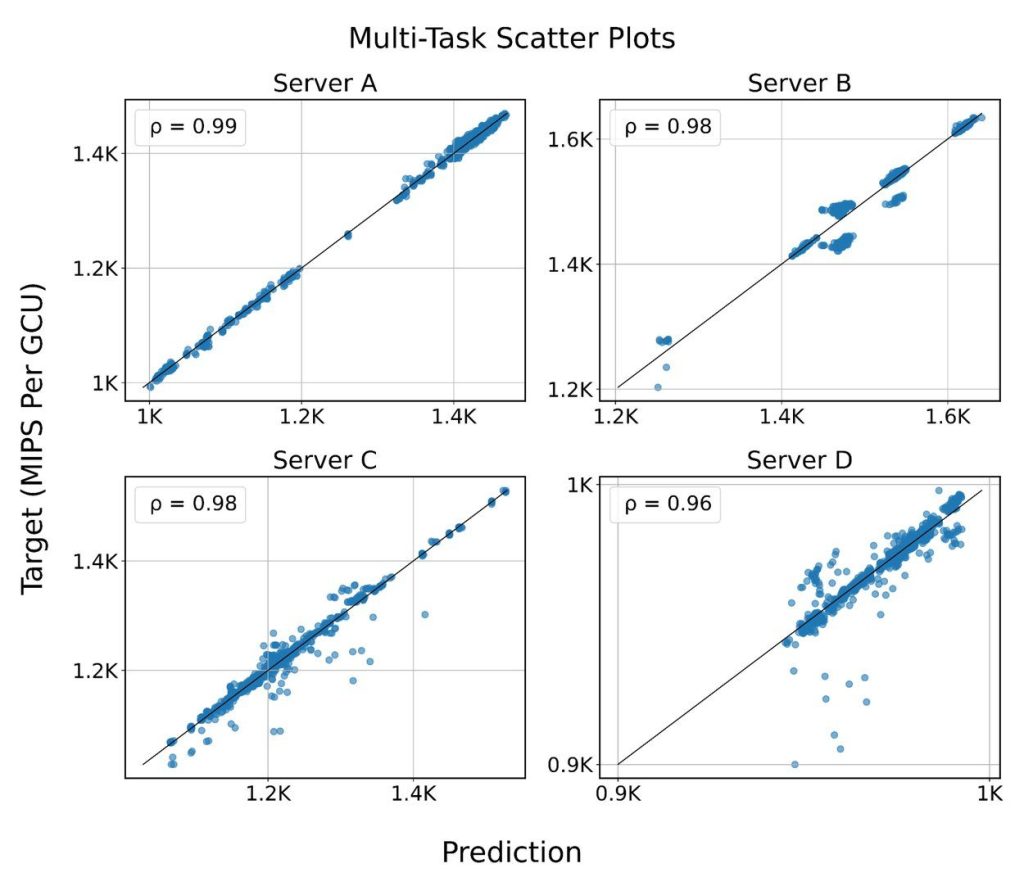
3. 高精度・高効率な予測と汎用性
Googleの事例では、RLMは現在の超巨大LLMと比較して6000万パラメータと比較的小規模なモデルでありながら、非常に高い精度で性能予測を達成しました。これは、少ない計算リソースで効率的に運用できることを意味します。
さらに、このモデルは「Few-shot適応」能力も備えています。これは、あるタスクで事前学習させた後、全く新しい種類のサーバーや異なるワークロードの予測タスクに対して、ごく少数のデータで再学習させるだけで素早く適応できる能力です。この高い汎用性により、様々な予測タスクに一つのモデルで対応できる「汎用予測器」としての可能性が示されています。
実用上の工夫:巨大な入力データをどう扱うか?
RLMが扱うシステムの状態データは、詳細な情報を含めると100万トークンを超えることもあります。しかし、モデルが一度に処理できるトークン数には上限があります(この研究では8000トークン)。
この制約に対応するため、研究チームは「最も重要な特徴量(情報)をテキスト文字列の先頭に配置する」という工夫を行いました。これにより、テキストが上限トークン数で切り捨てられても、予測に不可欠な情報は保持され、影響の少ない情報のみが失われるようにしています。これは、RLMを実世界の問題に適用する上で非常に重要なテクニックです。
実践的な使い方
GoogleはRLMの実装をオープンソースとして公開しており、実際にこの技術を試すことができます。ここでは、GitHub上で公開されているライブラリ「RegressLM」を使った具体的な実装方法を紹介します。
基本的な推論(inference)の流れ
RLMを使った最もシンプルな予測は、以下のような手順で行います:
from regress_lm import core
from regress_lm import rlm
# 最大入力トークン長を指定してRLMを作成
reg_lm = rlm.RegressLM.from_default(max_input_len=2048)
# 学習用データの例(テキスト入力xと数値出力yのペア)
examples = [
core.Example(x='サーバー設定: CPU=8コア, メモリ=32GB', y=1450.75),
core.Example(x='サーバー設定: CPU=4コア, メモリ=16GB', y=720.50)
]
# 少量のデータでファインチューニング
reg_lm.fine_tune(examples)
# 新しいデータで予測を実行
query = core.ExampleInput(x='サーバー設定: CPU=16コア, メモリ=64GB')
samples = reg_lm.sample([query], num_samples=128)[0]
# 予測結果の統計情報を取得
predicted_mean = samples.mean()
predicted_std = samples.std()
print(f"予測性能: {predicted_mean:.2f} ± {predicted_std:.2f}")より実用的な活用方法
1. カスタム語彙の構築
特定の分野のデータを扱う場合、専門用語に特化した語彙を構築することで予測精度を向上させることができます:
from regress_lm.vocab import SentencePieceVocab
# 自分の分野のデータから語彙を構築
encoder_vocab = SentencePieceVocab.from_corpus(
corpus_path='システムログデータ.txt',
vocab_size=1024
)2. 多目的回帰への対応
一つの入力から複数の数値を同時に予測したい場合(例:CPUとメモリの両方の使用率を予測):
# 複数の目的変数に対応
reg_lm = rlm.RegressLM.from_default(max_num_objs=2)
# 目的変数の数が異なるデータも混在可能
examples = [
core.Example(x='設定A', y=[0.2]), # CPU使用率のみ
core.Example(x='設定B', y=[-0.2, 0.3]) # CPU使用率とメモリ使用率
]
reg_lm.fine_tune(examples)
# 予測結果は2次元配列として取得
samples = reg_lm.sample([core.ExampleInput(x='設定C')], num_samples=128)[0]
cpu_prediction = samples[:, 0] # CPU使用率の予測分布
memory_prediction = samples[:, 1] # メモリ使用率の予測分布3. 既存の事前学習済みモデルの活用
T5やGemmaといった既存の大規模言語モデルを基盤として利用することも可能です:
from regress_lm.models.pytorch import t5gemma_model
# 事前学習済みT5Gemmaモデルを使用
model = t5gemma_model.T5GemmaModel('google/t5gemma-s-s-prefixlm')実用化に向けた注意点
入力データの設計
RLMの性能は、入力テキストの品質に大きく依存します。以下の点に注意してデータを準備することが重要です:
- 重要な情報を先頭に配置:前述のとおり、トークン制限により入力が切り詰められる可能性があるため、予測に最も重要な情報をテキストの最初に配置します
- 一貫性のある形式:学習データと予測時のデータで、同じ形式やキーワードを使用します
- 適切な詳細レベル:あまりに詳細すぎると重要な情報が埋もれ、簡潔すぎると予測に必要な情報が不足する可能性があります
計算リソースとスケーラビリティ
RLMは従来の言語モデルと比較して軽量ですが、大規模なシステムで運用する際は以下を考慮する必要があります:
- バッチ処理:複数の予測を同時に処理することで効率を向上
- モデルサイズの調整:予測精度と計算コストのバランスを考慮したモデルサイズの選択
- キャッシュ戦略:類似した入力に対する予測結果のキャッシュによる高速化
適用分野の例
RLMは様々な分野で活用が期待されています:
- ITインフラ管理:サーバー性能、ネットワーク負荷、ストレージ使用量の予測
- 製造業:設備の稼働率、品質指標、メンテナンス時期の予測
- 金融:リスク指標、取引量、市場変動の予測
- 研究開発:実験結果、シミュレーション計算時間、材料特性の予測
これらの分野では、従来の機械学習手法では扱いにくかった複雑な構造を持つデータを、そのままテキストとして扱える利点が特に活かされると考えられます。
まとめ
本稿では、Google Researchが提案する新しい数値予測の手法「回帰言語モデル(RLM)」について解説しました。
RLMは、複雑なシステムの状態をテキストとして直接読み解き、性能などの数値を予測する新しいパラダイムです。このアプローチの最大の利点は、従来必須であった専門的で時間のかかる特徴量エンジニアリングのプロセスを大幅に削減、あるいは不要にする可能性を秘めている点です。
さらに、単一の予測値だけでなく、その予測のばらつきや不確実性までを定量化できるため、より信頼性の高い、データに基づいた意思決定を支援します。
この技術は、本稿で紹介した計算基盤の性能予測に留まらず、工場の生産効率の最適化、科学実験の結果予測、さらには言語モデル自身の能力を向上させるための強化学習における報酬設計など、科学技術から産業応用に至るまで、極めて幅広い分野での活躍が期待されます。RLMは、言語モデルが「経験」から学び、現実世界の問題を解決する能力を、新たな次元へと引き上げる一歩となるでしょう。








