はじめに
スマートウォッチなどのウェアラブルデバイスは、心拍数や睡眠、活動量といった私たちの健康に関するデータを24時間記録し続け、健康管理に大きな変化をもたらしました。しかし、そのデータは常に完全なわけではありません。デバイスの充電や着脱、センサーのズレなどによって、データにはどうしても「欠損」が生まれてしまいます。実は、この不完全なデータが、AIによる正確な分析を難しくする大きな壁となっていました。
本稿では、この「データ欠損」という現実的な課題に対し、新しいアプローチで挑んだGoogle Researchの取り組みに関しての発表「LSM-2: Learning from incomplete wearable sensor data」を基に解説します。
参考記事
- タイトル: LSM-2: Learning from incomplete wearable sensor data
- 発行元: Google Research
- 発行日: 2025年7月22日
- URL: https://research.google/blog/lsm-2-learning-from-incomplete-wearable-sensor-data/
要点
- ウェアラブルセンサーのデータは、デバイスの着脱などによりデータ欠損が頻繁に発生するのが現実である。
- 従来のAIモデルは完全なデータを前提としており、データ欠損への対応が大きな課題であった。
- Googleが開発した新モデル「LSM-2」は、「AIM」という手法を用いて、データ欠損を「補完」するのではなく、欠損したままの不完全なデータから直接学習する。
- AIMは、元々存在するデータ欠損と学習用に意図的に作る欠損を区別なく扱い、モデルに現実世界のデータの性質を学ばせる。
- 結果として、LSM-2は従来モデルより高い精度と、データがさらに欠損した場合でも性能が落ちにくい堅牢性を実現した。
詳細解説
前提:なぜ「不完全なデータ」が問題だったのか?
ウェアラブルデバイスは非常に便利ですが、一日中完璧に装着し続けるのは困難です。例えば、お風呂に入る時や充電する時にはデバイスを外しますし、運動でずれてしまうこともあります。こうした瞬間に、データは記録されず「欠損」となります。
従来のAI、特に大量のデータからパターンを自ら学ぶ自己教師あり学習(SSL)という技術は、途切れのない完全なデータを前提として設計されていました。そのため、不完全なデータを扱うには、主に2つの方法が取られてきました。
- 補完(Imputation): 欠損している部分を、前後のデータから予測して埋める方法。しかし、これは不正確な予測でデータを歪めてしまうリスクがあります。
- 除去(Filtering): 欠損を含むデータサンプルを丸ごと学習から除外する方法。しかし、これは貴重なデータを大量に捨てることになり、AIの学習効率を下げてしまいます。
発表によると、収集した160万日分のデータの中で、データ欠損が全くないサンプルは一つもなかったと報告されており、この問題の普遍性を示しています。どちらの方法も一長一短で、根本的な解決策とは言えませんでした。
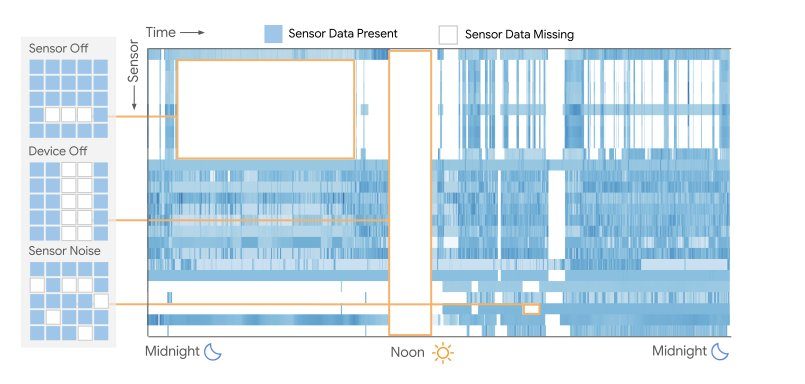
発想の転換:欠損を「エラー」から「特徴」へ
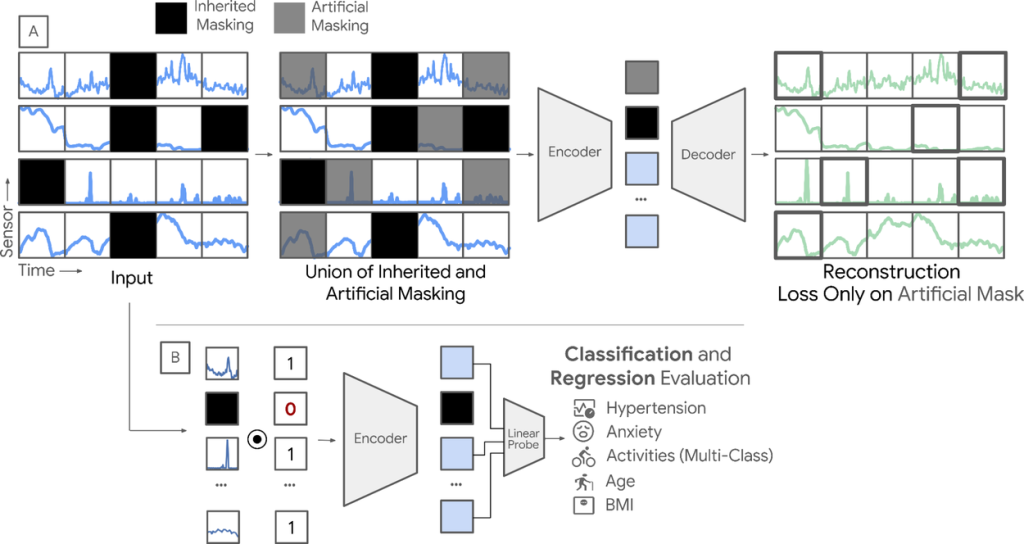
そこでGoogleの研究者たちが開発したのが、新しい学習フレームワーク「AIM(Adaptive and Inherited Masking)」です。AIMの最も重要な点は、データ欠損を修正すべきエラーとして扱うのではなく、現実世界のデータが持つ自然な特徴として捉え、AIに直接学ばせるという発想の転換にあります。
AIMは、マスク付きオートエンコーダ(MAE)という自己教師あり学習の手法を応用しています。MAEを簡単に説明すると、「データの一部を意図的に隠し(マスクし)、AIにその隠された部分を復元させる」という課題を解かせることで、データの構造や本質的な関係性を学習させる技術です。
AIMはこの「マスク」の概念を拡張し、2種類のマスクを巧みに利用します。
- 継承マスキング (Inherited Masking): デバイスの着脱などによって元々データが存在しない部分を、そのままマスクとして扱います。
- 人工マスキング (Artificial Masking): MAEと同様に、学習のためにAIが意図的に隠す部分です。
AIMは、この2つのマスクを区別なく扱います。これにより、AIは「データが欠けている状態」そのものに慣れ、不完全な情報からでも全体像を正確に推測する能力を身につけていきます。これは、私たちが会話の中で一部の単語が聞き取れなくても、文脈から内容を理解するのに似ています。
LSM-2が示した優れた性能と堅牢性
このAIMを用いて訓練された新しい基盤モデルが「LSM-2」です。LSM-2は、従来モデル(LSM-1)と比較して、様々なタスクでその有効性を示しました。
- 高い分類・回帰性能:
高血圧や不安症の分類、20種類の活動認識、さらにはBMI(体格指数)の推定といったタスクにおいて、LSM-1を上回るスコアを記録しました。これは、不完全なデータからでも、より正確に健康状態を読み取れることを意味します。 - 現実的な状況での堅牢性:
特に注目すべきは、LSM-2の堅牢性です。研究では、意図的に「特定のセンサー(加速度計など)が丸ごと故障した」「朝の時間帯のデータが全て失われた」といった、より過酷な状況をシミュレーションしました。
上のグラフが示すように、このような状況下で従来モデルのLSM-1は性能が大きく低下したのに対し、LSM-2の性能低下はごくわずかでした。これは、ユーザーが異なるセンサーを持つデバイスを使っていたり、一日のうち限られた時間しかデバイスを装着しなかったりする現実の利用シーンにおいて、非常に重要な利点です。 - 優れた拡張性(スケーラビリティ):
さらに、LSM-2は学習させるデータ量やモデルの規模を大きくすればするほど、性能が向上し続ける傾向を示しました。これは、将来的にさらに多くのデータを学習させることで、モデルがより賢くなる可能性を秘めていることを示唆しています。
まとめ
本稿で解説したGoogleの「LSM-2」と、その学習手法である「AIM」は、ウェアラブルデータ活用の長年の課題であった「データ欠損」に対するアプローチを変える可能性があるものです。
欠損データを無理に補ったり捨てたりするのではなく、ありのままの不完全なデータから直接学ぶという革新的なアイデアによって、AIはより現実に即した、安定した分析能力を獲得しました。これにより、私たちがデバイスを常に完璧に装着していなくても、AIが私たちの健康状態をより深く、そして信頼性高く見守ってくれる未来が期待されます。この技術は、今後のパーソナルヘルスケア分野の発展に大きく貢献していくことでしょう。