
はじめに
DeepSeek-AIが2025年、高効率な推論性能とエージェント機能を両立した大規模言語モデル「DeepSeek-V3.2」をリリースしました。本稿では、Hugging Faceで公開されたモデル情報をもとに、DeepSeek-V3.2の3つの技術的ブレークスルー、実装方法、ローカル実行の具体的な手順について解説します。
参考記事
- タイトル: DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
- 発行元: DeepSeek-AI (Hugging Face)
- 発行日: 2025年12月1日
- URL: https://huggingface.co/deepseek-ai/DeepSeek-V3.2
要点
- DeepSeek-V3.2は、DeepSeek Sparse Attention (DSA)、スケーラブルな強化学習フレームワーク、大規模エージェントタスク生成パイプラインという3つの技術的ブレークスルーを実現している
- 高計算量バリアントのDeepSeek-V3.2-SpecialeはGPT-5を上回り、Gemini-3.0-Proと同等の推論性能を示す。2025年の国際数学オリンピック(IMO)と国際情報オリンピック(IOI)で金メダル級の性能を記録した
- チャットテンプレートが大幅に変更され、ツール呼び出しフォーマットの刷新と「thinking with tools」機能が追加された。OpenAI互換フォーマットとの変換スクリプトが提供されている
- ローカル実行時の推奨パラメータはtemperature=1.0、top_p=0.95。V3.2-Specialeは深い推論タスク専用でツール呼び出しには非対応である
- MITライセンスで提供され、商用利用が可能。オリンピック問題の最終提出物もコミュニティ検証用に公開されている
詳細解説
DeepSeek Sparse Attention (DSA)
DeepSeek-AIによれば、DeepSeek Sparse Attention (DSA)は計算複雑度を大幅に削減しながらモデル性能を維持する効率的なアテンション機構です。特に長文コンテキストのシナリオに最適化されています。
スパースアテンションは、従来の全トークン間でアテンションを計算する手法と異なり、重要度の高いトークン間のみで計算を行う技術です。これにより、入力長に対する計算量の増加を抑えることができます。長文処理が求められるコードレビューや技術文書の分析などで、実用的な速度向上が期待できると考えられます。
スケーラブルな強化学習フレームワークとSpecialeバリアント
DeepSeek-AIによれば、堅牢な強化学習プロトコルの実装と学習後の計算量拡大により、DeepSeek-V3.2はGPT-5に匹敵する性能を達成しました。さらに、高計算量バリアントのDeepSeek-V3.2-SpecialeはGPT-5を上回り、Gemini-3.0-Proと同等の推論能力を示しています。
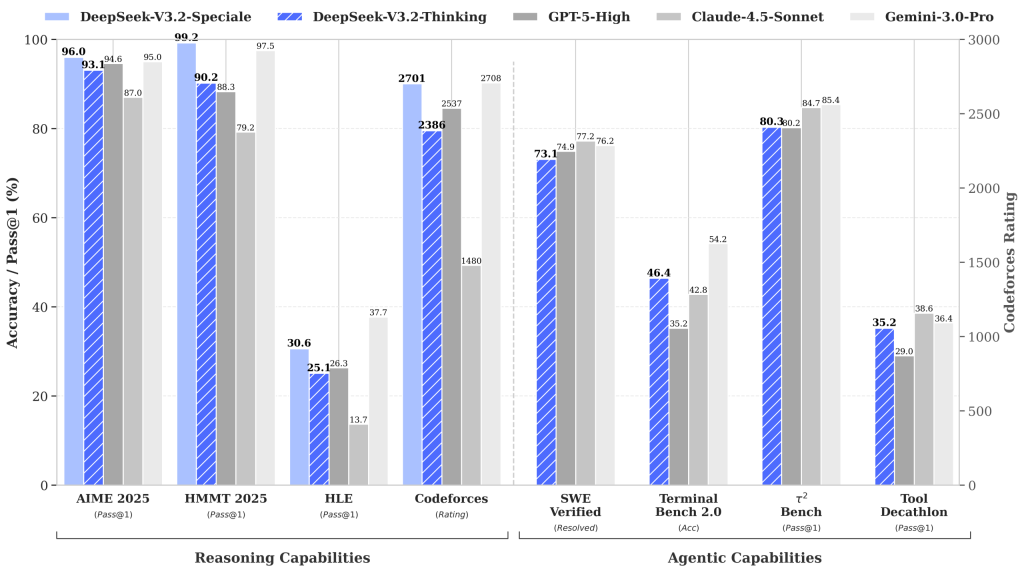
具体的な成果として、2025年の国際数学オリンピック(IMO)と国際情報オリンピック(IOI)で金メダル級の性能を記録しました。これらのオリンピック問題は、高度な数学的推論やアルゴリズム設計能力を要求するため、実際の開発現場における複雑な問題解決能力の指標となると考えられます。
2つのバリアントの使い分けは明確です。通常版のDeepSeek-V3.2は推論とツール呼び出しの両方に対応し、汎用的なエージェント開発に適しています。一方、Specialeバリアントは深い推論タスク専用で、ツール呼び出し機能には対応していません。複雑な論理的推論や数学的問題に特化したい場合はSpecialeを、実際のシステム統合やAPI連携が必要な場合は通常版を選択することになります。
エージェントタスク生成パイプライン
DeepSeek-AIによれば、推論機能をツール使用シナリオに統合するため、大規模な学習データを体系的に生成する新しい合成パイプラインを開発しました。これにより、スケーラブルなエージェント学習後の訓練が可能となり、複雑な対話環境での遵守性と汎化性能が向上しています。
このパイプラインは、実際のツール使用パターンを大量に生成することで、モデルが多様な状況に対応できるよう訓練されています。ウェブスクレイピング、API呼び出し、データベース操作など、実務で頻繁に発生するタスクにおいて、より自然で適切なツール選択と実行が期待できます。
チャットテンプレートの変更点と実装方法
DeepSeek-AIによれば、DeepSeek-V3.2では前バージョンと比較してチャットテンプレートが大幅に更新されました。主な変更点は、ツール呼び出しフォーマットの刷新と「thinking with tools」機能の導入です。
開発者がこの新しいテンプレートに適応できるよう、専用のエンコーディングフォルダが提供されており、OpenAI互換フォーマットのメッセージをモデルの入力文字列に変換する方法と、モデルのテキスト出力を解析する方法を示すPythonスクリプトとテストケースが含まれています。
実装例は以下の通りです:
import transformers
# encoding/encoding_dsv32.py
from encoding_dsv32 import encode_messages, parse_message_from_completion_text
tokenizer = transformers.AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-V3.2")
messages = [
{"role": "user", "content": "hello"},
{"role": "assistant", "content": "Hello! I am DeepSeek.", "reasoning_content": "thinking..."},
{"role": "user", "content": "1+1=?"}
]
encode_config = dict(thinking_mode="thinking", drop_thinking=True, add_default_bos_token=True)
# messages -> string
prompt = encode_messages(messages, **encode_config)
# Output: "<|begin▁of▁sentence|><|User|>hello<|Assistant|></think>Hello! I am DeepSeek.<|end▁of▁sentence|><|User|>1+1=?<|Assistant|><think>"
# string -> tokens
tokens = tokenizer.encode(prompt)
# Output: [0, 128803, 33310, 128804, 128799, 19923, 3, 342, 1030, 22651, 4374, 1465, 16, 1, 128803, 19, 13, 19, 127252, 128804, 128798]
このコード例では、encode_messages関数を使用してメッセージをプロンプト文字列に変換し、tokenizerでトークン化しています。reasoning_contentフィールドにより、モデルの推論過程を含めることができます。
重要な注意点として、以下の3点が挙げられています:
- Jinjaフォーマットの非対応: 今回のリリースではJinja形式のチャットテンプレートは含まれていないため、上記のPythonコードを参照する必要があります。
- 出力パース関数の制限: 提供されている出力パース関数は整形された文字列のみを処理し、モデルが時折生成する可能性のある不正な形式の出力を修正または復元する機能は持っていません。本番環境で使用する場合は、堅牢なエラーハンドリングが必要です。
- developerロールの用途制限: チャットテンプレートに新しくdeveloperロールが導入されましたが、これは検索エージェントシナリオ専用で、他のタスクには使用できません。公式APIではdeveloperロールに割り当てられたメッセージを受け付けません。
既存のOpenAI APIベースの実装からDeepSeek-V3.2に移行する際は、このテンプレート変更に対応するため、メッセージエンコーディング部分の書き換えが必要になると考えられます。
ローカル実行方法
DeepSeek-AIによれば、DeepSeek-V3.2とDeepSeek-V3.2-Specialeのモデル構造はDeepSeek-V3.2-Expと同じです。ローカル実行の詳細情報については、DeepSeek-V3.2-ExpのGitHubリポジトリを参照することが推奨されています。ローカル実行には、HuggingFaceの推論デモコード、SGLang、vLLMという3つの選択肢が提供されています。
HuggingFaceでの実行方法
DeepSeek-AIによれば、inferenceフォルダに更新された推論デモコードが提供されており、コミュニティがモデルをすぐに使い始め、アーキテクチャの詳細を理解できるようになっています。
実行手順は2ステップです。まず、Hugging Faceのモデルウェイトを推論デモに必要な形式に変換します。MPは利用可能なGPU数に合わせて設定します:
cd inference
export EXPERTS=256
python convert.py --hf-ckpt-path ${HF_CKPT_PATH} --save-path ${SAVE_PATH} --n-experts ${EXPERTS} --model-parallel ${MP}次に、対話型チャットインターフェースを起動します:
export CONFIG=config_671B_v3.2.json
torchrun --nproc-per-node ${MP} generate.py --ckpt-path ${SAVE_PATH} --config ${CONFIG} --interactiveこの方法は、モデルの内部構造を理解したい研究者や、細かいカスタマイズが必要な開発者に適していると考えられます。推論デモコードは教育目的にも活用でき、アテンション機構やMoEアーキテクチャの実装を学ぶ良い教材になります。
SGLangでの実行方法
DeepSeek-AIによれば、SGLangを使用することで、より簡単にモデルをデプロイできます。Dockerイメージが各ハードウェア向けに提供されています:
# H200 GPU向け
docker pull lmsysorg/sglang:dsv32
# AMD MI350 GPU向け
docker pull lmsysorg/sglang:dsv32-rocm
# NPU向け
docker pull lmsysorg/sglang:dsv32-a2
docker pull lmsysorg/sglang:dsv32-a3サーバーの起動コマンドは以下の通りです:
python -m sglang.launch_server --model deepseek-ai/DeepSeek-V3.2-Exp --tp 8 --dp 8 --enable-dp-attention --tp 8はTensor Parallelism(テンソル並列化)で8つのGPUに分散、--dp 8はData Parallelism(データ並列化)で8つのレプリカを作成することを意味します。--enable-dp-attentionフラグは、データ並列化時のアテンション計算を最適化します。
SGLangは、本番環境でのデプロイメントを想定した設計になっており、スループットとレイテンシのバランスが取れています。複数のユーザーからの同時リクエストを効率的に処理したい場合に適していると考えられます。
vLLMでの実行方法
DeepSeek-AIによれば、vLLMはDeepSeek-V3.2-Expのday-0サポートを提供しています。day-0サポートとは、モデルリリースと同時に対応が完了していることを意味し、待ち時間なくすぐに利用開始できます。
vLLMは高速な推論エンジンとして知られており、PagedAttentionなどの最適化技術により、長文コンテキストでも効率的にメモリを使用します。詳細な実行手順については、vLLMの公式recipesドキュメントを参照することが推奨されています。
vLLMは特に推論速度を重視する場合に適しており、リアルタイム性が求められるチャットボットやコード補完などのアプリケーションで威力を発揮すると考えられます。
推奨パラメータと注意事項
ローカルデプロイメントでの推奨パラメータは以下の通りです:
- temperature: 1.0
- top_p: 0.95
これらのパラメータは、創造性と一貫性のバランスを考慮した設定です。temperatureが1.0の場合、モデルは確率分布に従ってより多様な出力を生成します。top_pが0.95の場合、累積確率が95%に達するまでのトークンから選択するため、極端に低確率なトークンを排除しながら十分な多様性を保てます。
重要な実装上の注意点として、DeepSeek-AIは2025年11月17日に、Rotary Position Embedding (RoPE)の実装に関する不具合を修正しました。具体的には、indexerモジュールのRoPEへの入力テンソルは非インターリーブレイアウトを必要とする一方、MLAモジュールのRoPEはインターリーブレイアウトを期待するという実装の不一致がありました。この問題は修正されており、最新版の推論デモコードを使用することが推奨されています。
繰り返しになりますが、DeepSeek-V3.2-Specialeバリアントは深い推論タスク専用に設計されており、ツール呼び出し機能には対応していません。エージェント開発やAPI統合が必要な場合は、通常版のDeepSeek-V3.2を使用する必要があります。
オープンソースカーネルの公開
DeepSeek-AIによれば、DeepSeek-V3.2の高性能実装を支えるカーネルもオープンソースで公開されています。これにより、研究者や開発者はモデルの内部実装を詳細に理解し、独自の最適化を行うことができます。
公開されているカーネルは以下の3種類です:
- TileLang: 可読性が高く、研究目的に適したカーネル実装。TileLangリポジトリで公開されており、アルゴリズムの理解や教育目的での利用に適しています。
- DeepGEMM: 高性能なCUDAカーネルで、indexer logitカーネル(ページング版を含む)が提供されています。本番環境での高速化を目指す開発者向けです。
- FlashMLA: スパースアテンションカーネルが実装されており、長文コンテキスト処理の高速化に寄与します。
これらのカーネルは、DeepSeek Sparse Attention (DSA)の実装を理解する上で重要な資料となります。特に、自社のユースケースに合わせた最適化やカスタマイズを検討する際、これらのオープンソース実装を参考にすることで、効率的な開発が可能になると考えられます。
ライセンスとコミュニティ資料
DeepSeek-AIによれば、このリポジトリとモデルウェイトはMITライセンスで提供されています。MITライセンスは最も制約の少ないオープンソースライセンスの一つで、商用利用、改変、再配布が自由に認められています。企業でのプロダクション利用を検討する際、ライセンス面での障壁が低いことは大きな利点と言えます。
さらに、IOI 2025、ICPC World Finals、IMO 2025、CMO 2025の最終提出物も公開されています。これらの資料はパイプラインに基づいて選択されたもので、コミュニティによる二次検証のために提供されています。ファイルはassets/olympiad_casesからアクセス可能です。
これらの実際の提出物を確認することで、モデルの推論プロセスや問題解決アプローチを具体的に理解でき、自社のユースケースでの活用可能性を評価する材料になると思います。
まとめ
DeepSeek-V3.2は、GPT-5級の推論性能を実現しながらMITライセンスで商用利用可能なオープンモデルとして注目されます。エンジニアは、HuggingFaceの推論デモコード、SGLang、vLLMという3つの実行方法から、自身のユースケースに適した選択肢を選べます。提供されているPythonスクリプトを用いてチャットテンプレートを実装し、通常版とSpecialeバリアントの特性を理解した上で、実際のプロジェクトへの統合を検討できます。








