
はじめに
AI技術の進化は目覚ましく、大規模言語モデル(LLMs)は私たちの生活や仕事に革命をもたらしつつあります。最新モデルが次々と登場していますが、それらのモデルは、その性能向上のために、モデルサイズや学習データ、計算リソースを指数関数的に増加させる、いわゆる「スケーリング則」に従って開発されています。
しかし、このようにモデルの規模が大きくなるにつれて、現在のハードウェアアーキテクチャには様々なボトルネックが現れています。特に、メモリ容量の限界、計算効率の課題、そしてノード間・ノード内の相互接続(インターコネクト)の帯域幅不足といった問題は深刻です。
今回解説する論文「Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures」では、DeepSeek-AIが開発した大規模言語モデルDeepSeek-V3の開発を通じて得られた、これらのハードウェア課題への洞察と、それを克服するためのハードウェアとモデルの「協調設計(Co-design)」の重要性について論じられています。DeepSeek-V3は、他の大手IT企業が数万、数十万ものGPUを使用するような大規模なクラスタを構築しているのに対し、わずか2,048基のNVIDIA H800 GPUという比較的少ないリソースで、最先端レベルの性能を達成しています。
引用元記事
- タイトル: Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures
- 発行元: DeepSeek-AI
- 発行日: 2025年5月14日
- URL:https://www.arxiv.org/pdf/2505.09343
・あくまで個人の理解に基づくものであり、正確性に問題がある場合がございます。
必ず参照元論文をご確認ください。
・本記事内での画像は、上記論文より引用しております。
※概要が知りたい方はこちら
要点
- ハードウェアとモデルの協調設計の有効性: 大規模言語モデルのスケーリングに伴うハードウェアの限界に対し、ハードウェアの制約や特性を考慮に入れたモデル設計(協調設計)が、コスト効率の高い訓練と推論を実現する上で非常に重要である。
- DeepSeek-V3における主要技術: DeepSeek-V3は、メモリ効率を大幅に改善するMulti-head Latent Attention (MLA)、計算と通信のトレードオフを最適化するMixture of Experts (MoE)、ハードウェア性能を最大限に引き出すFP8混合精度訓練、そしてクラスタレベルのネットワークオーバーヘッドを削減するMulti-Planeネットワークトポロジー といった技術を組み合わせることで、限られたハードウェアリソースでも高い性能を発揮できるように設計されている。
- ハードウェアボトルネックへの洞察と将来への提言: DeepSeek-V3の開発で直面した具体的なハードウェアのボトルネック(メモリウォール、インターコネクト帯域幅、CPUボトルネック、堅牢性など) を分析し、将来のAIハードウェア(計算ユニット、インターコネクト、システムアーキテクチャなど)がどのように進化すべきかについて、学術界や産業界への提言を行っている。
詳細解説
論文の各セクションに沿って、DeepSeek-V3の開発で得られた知見や、今後のハードウェアへの提言を詳しく見ていきます。
1. 導入
1.1 背景
近年、大規模言語モデル(LLM)は急速に進化しており、モデルサイズ、学習データ、計算資源の増強が性能向上に不可欠であることが示されています(スケーリング則)。GPT-4o、LLaMa-3、Claude 3.5 Sonnet、Gemini-2、そして本論文で取り上げられるDeepSeek-V3といったモデルがその進歩を体現しています。しかし、これらのモデル開発には膨大な計算資源が必要となり、特に推論効率の向上が課題となっています。Alibaba、Google、Metaなどの巨大企業は大規模なクラスタを構築していますが、そのコストは小規模な研究チームには大きな障壁です。このような状況下で、DeepSeekのようなオープンソースのスタートアップは、ハードウェアとソフトウェアの協調設計によって、費用対効果の高い大規模モデルの学習を実現しようと努力しています。DeepSeek-V3は、2,048基のNVIDIA H800 GPUという比較的少ないリソースで最先端の性能を達成し、この方向性における新たなマイルストーンとなっています。
1.2 目的
この論文は、DeepSeek-V3のアーキテクチャやアルゴリズムの詳細を繰り返すのではなく、ハードウェアアーキテクチャとモデル設計の相互作用という二つの視点から、費用対効果の高い大規模な学習と推論を実現するための知見を探求することを目的としています。具体的には、以下の点に焦点を当てています。
- ハードウェア駆動のモデル設計: FP8低精度計算やスケールアップ/スケールアウトネットワーク特性といったハードウェア機能が、DeepSeek-V3のアーキテクチャ選択にどのように影響したかを分析します。
- ハードウェアとモデルの相互依存性: ハードウェアの能力がモデルの革新をどのように形成し、進化するLLMの要求が次世代ハードウェアの必要性をどのように促進するかを調査します。
- ハードウェア開発の将来の方向性: DeepSeek-V3から得られた実用的な洞察に基づいて、将来のハードウェアとモデルアーキテクチャの協調設計を導き、スケーラブルで費用対効果の高いAIシステムの実現を目指します。
1.3 この論文の構成
論文の残りの部分は以下のように構成されています。
- セクション2: DeepSeek-V3モデルアーキテクチャの設計原則を探求し、Multi-head Latent Attention、Mixture-of-Expertsの最適化、Multi-Token Prediction Moduleといった主要な革新技術に焦点を当てます。
- セクション3: モデルアーキテクチャがどのように低精度計算と通信を追求しているかを説明します。
- セクション4: スケールアップ相互接続の最適化、スケールアップ/スケールアウトの収束について議論し、ハードウェア機能が並列処理とエキスパート選択戦略にどのように影響するかを探ります。
- セクション5: マルチプレーンネットワーク協調設計や低遅延相互接続を含む、スケールアウトネットワークの最適化に焦点を当てます。
- セクション6: セクション3〜5で言及された現在の限界と将来の提案に加えて、DeepSeek-V3から得られたより重要な洞察を詳述し、将来のハードウェアとモデルの協調設計の方向性を示します。
2. DeepSeekモデルの設計原則
DeepSeek-V3の開発では、ハードウェアの制約を意識した上で、パフォーマンスとコスト効率を最適化するための設計判断が一つ一つ慎重に行われました。これが「ハードウェアを意識したスケーリング」と呼ばれるアプローチです。
1を見ると、DeepSeek-V3は、以前のモデルであるDeepSeek-V2 で効果が実証されたDeepSeek-MoE とMulti-head Latent Attention (MLA) のアーキテクチャを採用しています。
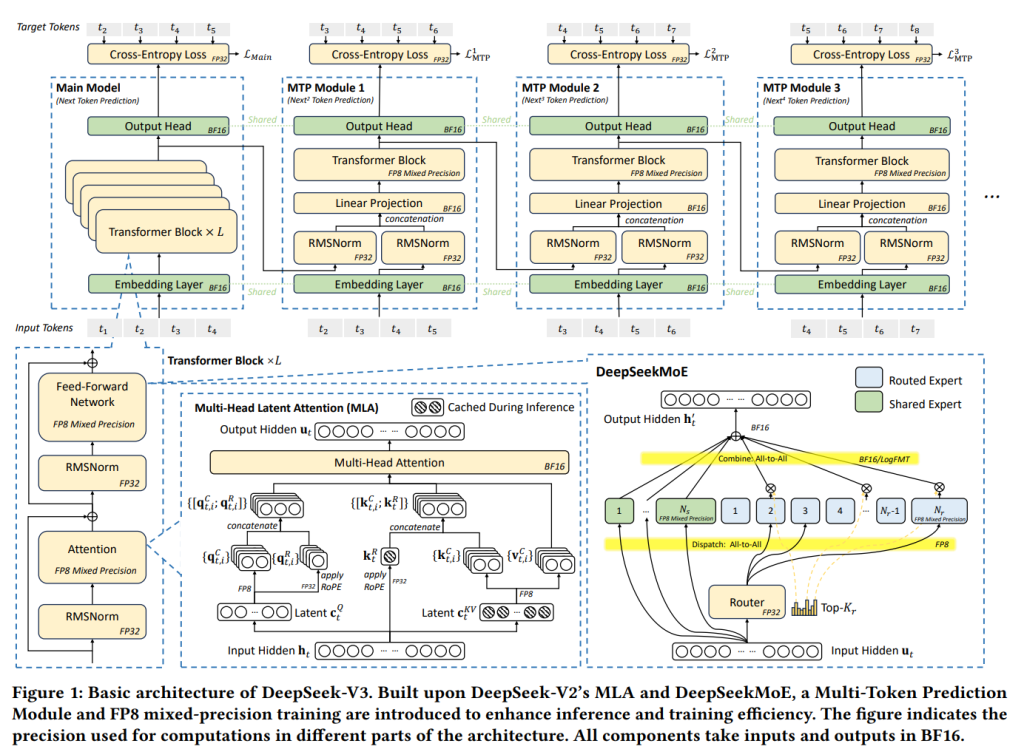
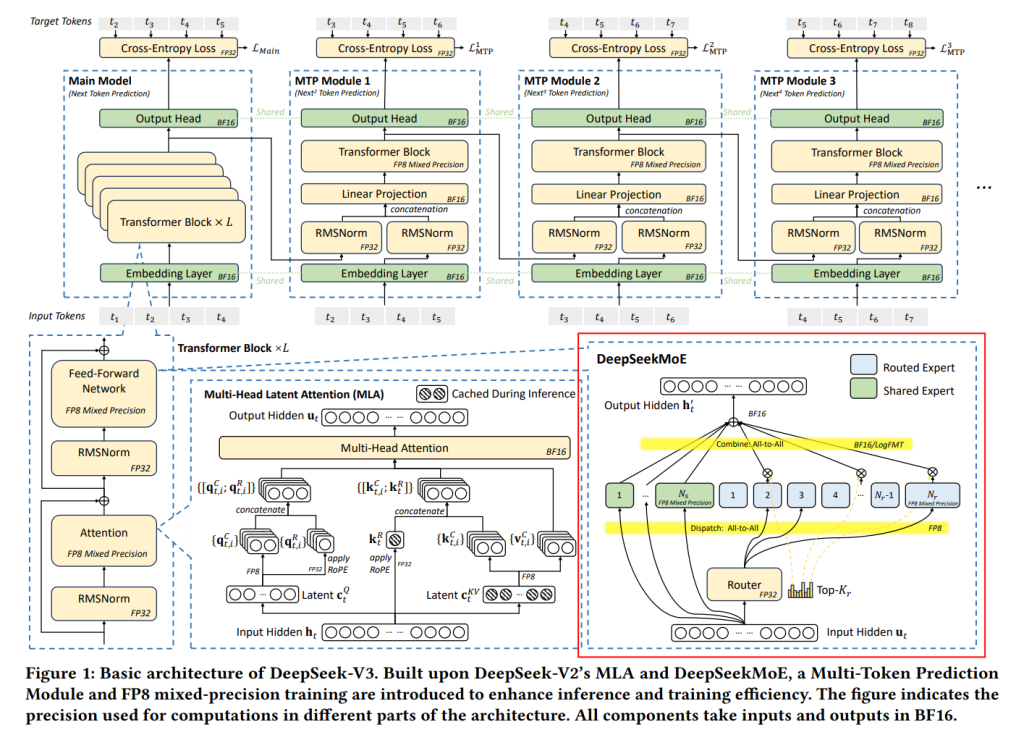
- DeepSeek-MoEは、後述するMixture of Experts (MoE)アーキテクチャの可能性を引き出すものです。MoEでは、モデル全体の一部のパラメータ(エキスパート)だけを計算に使うことで、モデルのパラメータ数を大きくしても計算量を抑えることができます。
- MLAは、Key-Value (KV) キャッシュというものを圧縮することで、メモリ消費量を大幅に削減します。KVキャッシュについては後で詳しく説明します。
さらに、DeepSeek-V3では、計算コストを大幅に削減し、大規模な訓練をより実用的にするためにFP8混合精度訓練を導入しています。また、推論(モデルを使ってテキストなどを生成すること)の速度を向上させるために、Multi-Token Prediction (MTP) モジュールに基づいた投機的デコーディング を組み込んでいます。これは、モデルが一度に複数の候補トークンを予測し、それらを並列に検証することで、生成速度を上げる技術です。
モデルアーキテクチャだけでなく、コスト効率の良いAIインフラストラクチャも模索されており、従来の3層Fat-Treeトポロジーに代わって、Multi-Plane 2層Fat-Treeネットワークを展開することで、クラスタのネットワークコストを削減しています。
これらの革新は、大規模言語モデルのスケーリングにおける3つの核となる課題、すなわちメモリ効率、費用対効果、そして推論速度に対処することを目的としています。
2.1 メモリ効率
大規模言語モデルは一般的に、非常に大きなメモリリソースを必要とします。その需要は年間1000%以上増加していますが、高速なメモリ(例えば、GPUに搭載されるHBM)の容量増加率はそれよりもはるかに遅く、通常年間50%未満にとどまっています。これは「AIメモリウォール」とも呼ばれる課題です。このメモリ制限に対処するために複数の計算ノードを使う並列化も有効ですが、メモリ使用量をモデル設計の段階で最適化することも非常に重要で効果的な戦略です。
2.1.1 低精度モデル
重みにBF16(16ビット浮動小数点形式)を使用するモデルと比較して、FP8(8ビット浮動小数点形式)を使用することでメモリ消費量を半分に削減できます。これはAIメモリウォール課題を効果的に緩和します。低精度技術については、後のセクション3でさらに詳しく説明します。
2.1.2 MLAによるKVキャッシュ削減
LLMの推論では、ユーザーのリクエストが複数回のやり取り(マルチターン会話)を含むことがよくあります。これを効率的に処理するために、以前のリクエストからの文脈はKVキャッシュと呼ばれるものにキャッシュされます。KVキャッシュは、以前処理されたトークンのKeyとValueベクトルをキャッシュすることで、後続のトークンに対してこれらを再計算する必要をなくします。各推論ステップでは、モデルは現在のトークンのKeyとValueベクトルだけを計算し、履歴からキャッシュされたKey-Valueペアと組み合わせてAttention計算を行います。この増分的な計算により、各トークン生成の計算量はシーケンス長に対して線形(O(N))になり、長いシーケンスやマルチターン入力の処理効率が向上します。
しかし、KVキャッシュはメモリのボトルネックを引き起こします。計算がGEMM(行列乗算)からGEMV(行列ベクトル乗算)にシフトし、GEMVはGEMMよりも計算量あたりのメモリ使用量(Compute-to-Memory Ratio)がはるかに低いためです。最新のハードウェアが持つ膨大な計算能力(数百TFLOPS)に対して、GEMVはすぐにメモリ帯域幅によって制限され、メモリへのアクセスが主要なボトルネックとなります。
このボトルネックに対処するために、DeepSeek-V3はMulti-head Latent Attention (MLA) を採用しています。MLAは、すべてのAttentionヘッドのKV表現を、モデルと一緒に訓練される射影行列を使って、より小さな潜在ベクトルに圧縮します。推論時には、潜在ベクトルだけをキャッシュすればよく、すべてのAttentionヘッドのKVキャッシュを保存する場合と比較してメモリ消費量を大幅に削減できます。
MLA以外にも、KVキャッシュのサイズを削減するためのいくつかの手法が提案されています。これらはメモリ効率の高いAttentionメカニズムの進歩に大きな示唆を与えています。
- Shared KV (Grouped-Query Attention, GQA; Multi-Query Attention, MQA): 各Attentionヘッドが個別のKVペアを持つのではなく、複数のヘッドが単一のKVペアセットを共有することで、KVストレージを大幅に圧縮します。
- Windowed KV: 長いシーケンスの場合、KVペアのスライディングウィンドウだけをキャッシュに残し、ウィンドウ外の結果は破棄します。これはストレージを削減しますが、長い文脈の推論性能を損なう可能性があります。
- Quantized Compression: KVペアを低ビット表現で保存することで、さらにメモリ使用量を削減します。量子化は、モデル性能への影響を最小限に抑えつつ、大幅な圧縮を実現します。
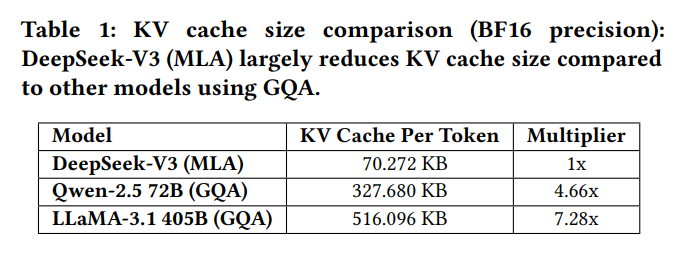
Table 1では、DeepSeek-V3、Qwen-2.5 72B、LLaMA-3.1 405B のKVキャッシュメモリ使用量(トークンあたり)を比較しています。DeepSeek-V3はMLAを採用することで、トークンあたりわずか70KBという大幅なKVキャッシュサイズの削減を達成しており、LLaMA-3.1 405Bの516KBやQwen-2.5 72Bの327KBよりも大幅に少なくなっています。この削減は、GQAベースの手法と比較して、MLAがKV表現の圧縮においていかに効率的であるかを示しています。このようなメモリ消費量の大幅な削減能力により、DeepSeek-V3は特に長い文脈の処理やリソースが限られた環境での利用に適しており、よりスケーラブルでコスト効率の高い推論を可能にします。
2.1.3 リソース効率化技術に関する将来の方向性と展望
KVキャッシュのサイズ削減はメモリ効率向上が確実な手法ですが、Transformerベースの自己回帰デコーディングに固有の二次的な計算量は、特に非常に長い文脈においては依然として大きな課題です。最近の研究では、Mamba-2 やLightning Attention のように、線形時間で動作する代替手法が模索されており、計算コストとモデル性能のバランスを取る新たな可能性を示しています。加えて、Sparse Attention のようなアプローチも、AttentionのKeyとValueを圧縮し、疎にアクティベートすることで、Attentionに関連する計算上の課題を克服しようとしています。DeepSeek-AIチームは、この分野でのさらなるブレークスルーに向けて、広範なコミュニティとの共同研究に期待を寄せています。
2.2 MoEモデルの費用対効果
スパース計算のために、DeepSeek-AIチームはDeepSeekMoE と呼ばれる高度なMixture of Experts (MoE)アーキテクチャを開発しました。これはFigure 2の右下部分に示されています。MoEモデルの利点は大きく分けて二つあります。
2.2.1 訓練における計算量削減
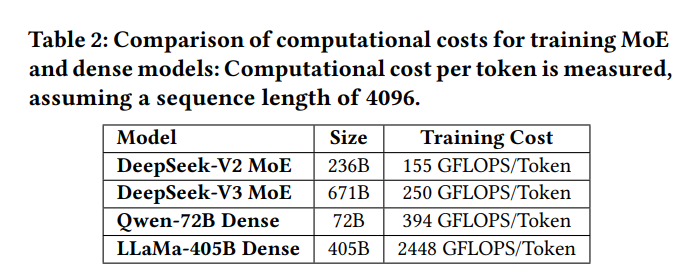
MoEアーキテクチャの最大の利点は、訓練コストを大幅に削減できることです。Expertパラメータの一部だけを選択的にアクティベートすることで、MoEモデルは合計パラメータ数を劇的にスケールアップさせつつ、計算要件を控えめに保つことができます。例えば、DeepSeek-V2は2360億のパラメータを持ちますが、トークンあたりにアクティベートされるパラメータはわずか210億です。同様に、DeepSeek-V3は6710億パラメータに拡張されています(V2のほぼ3倍のサイズ)が、トークンあたりのアクティベーションは370億に抑えられています。これに対し、Qwen2.5-72BやLLaMa3.1-405Bのような密な(Dense)モデルは、訓練中にすべてのパラメータがアクティブである必要があります。
Table 2に示すように、DeepSeek-V3の合計計算コストはトークンあたり約250 GFLOPS であるのに対し、720億パラメータの密なモデルは394 GFLOPS、4050億パラメータの密なモデルは2448 GFLOPSを必要とします。このことから、MoEモデルは密なモデルと同等あるいはそれ以上の性能を達成しつつ、計算リソースを1桁少なく消費できることがわかります。
2.2.2 個人利用およびオンプレミス展開の利点
将来的に、パーソナライズされたLLMエージェント が普及する世界では、MoEモデルは単一リクエストのシナリオでユニークな利点を提供します。リクエストごとにアクティベートされるパラメータのサブセットだけであるため、メモリと計算の要求が大幅に削減されます。例えば、DeepSeek-V2(2360億パラメータ)は推論中にわずか210億パラメータをアクティベートします。これにより、AI SoCチップ を搭載したPCでも毎秒約20トークン(TPS)、あるいはその2倍の速度 を達成でき、これは個人利用には十分すぎる速度です。対照的に、同様の能力を持つ密なモデル(例えば700億パラメータ)は、通常、同様のハードウェアでは1桁台のTPSしか達成できません。
特に注目すべきは、ますます普及しているKTransformers 推論エンジンを使うことで、DeepSeek-V3モデル全体が、消費者向けGPU(約10,000ドルのコスト)を搭載した低コストサーバーでも実行可能であり、それでも約20 TPSを達成できることです。
この効率性により、MoEアーキテクチャは、ハードウェアリソースがしばしば限られるローカル展開や単一ユーザーシナリオに適しています。メモリと計算のオーバーヘッドを最小限に抑えることで、MoEモデルは高価なインフラストラクチャを必要とせずに、高品質な推論性能を提供できます。
2.3 推論速度向上
推論速度は、システムの最大スループットと単一リクエストのレイテンシの両方を含みます。
2.3.1 計算と通信のオーバーラップ:スループット最大化
スループットを最大化するために、DeepSeek-V3モデルはDual micro-batch overlap を活用するように最初から設計されています。これは、通信レイテンシと計算を意図的に重ね合わせる手法です。DeepSeek-AIのオンライン推論システムやオープンソースのプロファイリングデータ で示されているように、MLAとMoEの計算を2つの明確なステージに分離しています。あるマイクロバッチがMLAまたはMoE計算の一部を実行している間、別のマイクロバッチは同時に対応するディスパッチ通信を実行します。逆に、2番目のマイクロバッチの計算フェーズ中には、最初のマイクロバッチが結合(Combine)通信ステップを実行します。このパイプライン化されたアプローチにより、all-to-all通信と進行中の計算との間にシームレスなオーバーラップが可能となり、GPUが常に完全に利用されることが保証されます。さらに、本番環境ではprefillとdecodeの分離(disaggregation)アーキテクチャ を採用し、バッチサイズの大きいprefillリクエストとレイテンシに敏感なdecodeリクエストを、異なるExpert Parallelism (EP)グループサイズに割り当てています。この戦略は、最終的に実際のサービス条件下でのシステムスループットを最大化します。
2.3.2 推論速度の限界
このセクションでは、LLMサービスのdecode出力速度、通常Time Per Output Token (TPOT)で測定されるものに焦点を当てます。TPOTはユーザー体験にとって重要な指標であり、OpenAIのo1/o3 やDeepSeek-R1 といった推論モデルの応答性にも直接影響します。これらのモデルは、その知能を向上させるために推論の長さに依存しています。
MoEモデルの場合、高い推論速度を達成するには、エキスパートパラメータを計算デバイス間で効率的に展開することが不可欠です。最速の推論速度を達成するためには、各デバイスが理想的には単一のエキスパートの計算を実行する必要があります(または、必要であれば複数のデバイスが協力して単一のエキスパートを計算します)。しかし、Expert Parallelism (EP)は、トークンを適切なデバイスにルーティングする必要があり、これにはネットワークを介したall-to-all通信が伴います。結果として、MoE推論速度の上限は、インターコネクションの帯域幅によって決定されます。
CX7 400Gbps InfiniBand (IB) NICsで相互接続されたシステムを考えます。各デバイスが1つのエキスパートのパラメータを保持し、一度に約32トークンを処理すると仮定します。このトークン数は、Compute-to-Memory ratioと通信レイテンシのバランスを取るものであり、EPにおいて各デバイスが等しいバッチサイズを処理し、通信時間を簡単に計算できるようにします。EPにおける2回のall-to-all通信に必要な時間は、以下の式で計算されます。
通信時間 = (1Byte + 2Bytes) × 32 × 9 × 7K / 50GB/s = 120.96μs
ここで、ディスパッチ(Dispatch)はFP8(1バイト)、結合(Combine)はBF16(2バイト) を使用し、各トークンの隠れ層のサイズは約7Kです。因子9は、各トークンが8つのRoutedエキスパートと1つのSharedエキスパートに転送されることを示します。
セクション2.3.1で述べたように、スループットを最大化するにはDual micro-batch overlapを使用する必要があります。この戦略の下で、理論的な最良ケースの分析では、計算オーバーヘッドが最小化され、パフォーマンスの上限が通信レイテンシによって決定されると仮定しています。しかし、実際の推論ワークロードでは、リクエストの文脈がしばかに長く、MLA計算が実行時間を支配することが一般的です。したがって、この分析はDual micro-batch overlapの下での理想化されたシナリオを示しています。この仮定の下で、レイヤーごとの合計時間は次のように定式化できます。
レイヤーごとの合計時間 = 2 × 120.96μs = 241.92μs
DeepSeek-V3には61層があるため、合計推論時間は以下になります。
合計推論時間 = 61 × 241.92μs = 14.76ms
したがって、このシステムの理論的な上限は、TPOT約14.76 ms、つまり毎秒67トークンに相当します。ただし、実際には、通信オーバーヘッド、レイテンシ、帯域幅の不完全な利用、計算の非効率性といった要因により、この数値は減少します。
対照的に、GB200 NVL72(72基のGPU間で単方向900GB/sの帯域幅)のような高帯域幅のインターコネクトが使用された場合、EPステップごとの通信時間は以下のように大幅に減少します。
通信時間 = (1Byte + 2Bytes) × 32 × 9 × 7K / 900GB/s = 6.72μs
計算時間が通信時間と等しいと仮定すると、これにより合計推論時間が大幅に短縮され、TPOT 0.82ms未満、毎秒約1200トークンという理論的な上限が可能になります。この数値はあくまで理論的なものであり、経験的に検証されたものではありませんが、大規模モデルの推論を加速する上で高帯域幅スケールアップネットワークが持つ変革的な可能性を鮮明に示しています。
MoEモデルは優れたスケーラビリティを示しますが、ハードウェアリソースを増やすだけで高い推論速度を達成することは、コストがかかりすぎます。したがって、ソフトウェアとアルゴリズムも推論効率の向上に貢献する必要があります。
2.3.3 マルチトークン予測 (MTP)
DeepSeek-V3はMulti-Token Prediction (MTP)フレームワークを導入しました。これはモデル性能を向上させると同時に推論速度も改善します。従来の自己回帰モデルは、デコーディングステップごとに1トークンを生成するため、逐次的なボトルネックが生じます。MTPは、モデルがより低いコストで追加の候補トークンを生成し、以前のSelf-draftingベースの投機的デコーディング手法 と同様に、それらを並列に検証できるようにすることで、この問題を軽減します。このフレームワークは、精度を損なうことなく推論を大幅に加速します。
1の上部に示されているように、各MTPモジュールは、フルモデルよりもはるかに軽量な単一の層を使用して追加のトークンを予測し、複数の候補トークンの並列検証を可能にします [33, Figure 1]。これはスループットをわずかに損なうものの、エンドツーエンドの生成レイテンシを大幅に改善します。実際のデータでは、MTPモジュールは2番目の後続トークンを予測する際に80%から90%の受理率 を達成し、MTPモジュールがない場合と比較して生成TPSを1.8倍向上させることが実証されています。
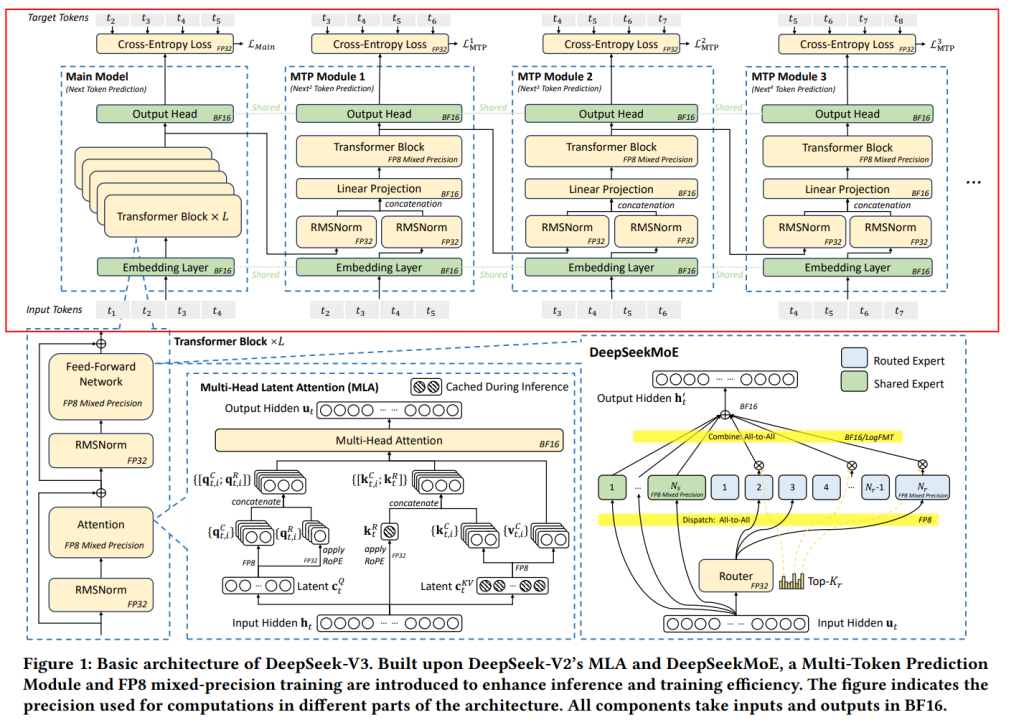
さらに、MTPはステップごとに複数のトークンを予測することで、推論バッチサイズを増加させます。これは、EP計算強度とハードウェア利用率を高める上で重要です。このようなアルゴリズムの革新は、DeepSeek-V3における高速かつコスト効率の良い推論にとって不可欠です。
2.3.4 推論モデルの高速推論とテストタイムスケーリング
OpenAIのo1/o3シリーズ に例示されるLLMにおけるテストタイムスケーリングは、推論中に計算リソースを動的に調整することで、数学的推論、プログラミング、一般的な推論において大きな進歩を可能にしました。その後のモデル(DeepSeek-R1、Claude-3.7 Sonnet、Gemini 2.5 Pro、Seed1.5-Thinking、Qwen3 を含む)も同様の戦略を採用し、これらのタスクで大きな改善を達成しています。
これらの推論モデルにとって、高速なトークン出力速度は大きな重要性を持っています。強化学習(RL)ワークフロー(PPO、DPO、GRPO など)では、大量のサンプルを迅速に生成する必要があるため、推論スループットが重大なボトルネックとなります。同様に、長時間の推論シーケンスはユーザーの待ち時間を増加させ、そのようなモデルの実用的な利用可能性を低下させる可能性があります。結果として、相乗的なハードウェアとソフトウェアの革新を通じて推論速度を最適化することは、推論モデルの効率を進化させる上で不可欠です。しかし、推論を加速し、RL訓練を迅速化するための効果的な戦略は、セクション2.1.3で議論されているように、依然として活発な研究分野です。DeepSeek-AIチームは、これらの継続的な課題に対する解決策を協同的に探索し、開発することを広範なコミュニティに奨励しています。
2.4 技術検証手法
各加速技術は、その精度への影響を評価するために経験的検証を受けています。これには、MLA、FP8混合精度計算、およびネットワーク協調設計されたMoEゲートルーティングが含まれます。フルスケールモデルに対する貪欲的ななアブレーションは大きなコストがかかるため、階層的でリソース効率の良い検証パイプラインを採用しています。各技術は、まず小規模モデルで拡張的に検証され、続いて最小限の大規模チューニングが行われ、最後に単一の包括的な訓練実行に統合されます。
例えば、最終的な統合の前に、160億および2300億パラメータのDeepSeek-V2モデルの両方でFP8訓練アブレーション研究を実施しました。これらの制御された設定の下では、高精度累積と量子化戦略の使用により、BF16と比較した相対的な精度損失は0.25%未満にとどまっています。
3. 低精度駆動設計
3.1 FP8混合精度訓練
GPTQ やAWQ のような量子化技術は、ビット幅を8ビット、4ビット、あるいはそれ以下に削減するために広く使用されており、メモリ要件を大幅に削減しています。しかし、これらの技術は主に推論時にメモリを節約するために適用され、訓練段階ではありません。NVIDIAのTransformer Engineは以前からFP8混合精度訓練をサポートしていますが、DeepSeek-V3以前にはFP8を訓練に活用したオープンソースの大規模モデルはありませんでした。DeepSeek-AIのインフラストラクチャチームとアルゴリズムチームの深い協力、そして験と革新を経て、MoEモデル向けのFP8互換訓練フレームワークを開発しました。Figure 1は訓練パイプラインにおいてFP8精度の順伝播および逆伝播プロセスが利用される計算コンポーネントを示しています。細粒度量子化が適用されており、具体的にはアクティベーションに対して tile-wise 1×128 量子化、モデル重みに対して block-wise 128×128 量子化が行われます。FP8フレームワークのさらなる技術詳細はDeepSeek-V3テクニカルレポート に記載されており、FP8 GEMM実装はDeepGEMM としてオープンソース化されています。
3.1.1 制限
FP8は訓練を加速する大きな可能性を秘めていますが、その潜在力を完全に活用するには、いくつかのハードウェア制限に対処する必要があります。
- FP8累積精度: FP8はTensor Coresにおける累積精度が制限されており、特にNVIDIA Hopper GPU 上での大規模モデル訓練の安定性に影響します。最大指数に基づいて32の仮数積を右シフトして位置合わせした後、Tensor Coreはその中で最も高い13の小数部ビットだけを保持して加算し、この範囲を超えるビットは切り捨てられます。加算結果はFP22レジスタ(1ビットの符号部、8ビットの指数部、13ビットの仮数部)に累積されます。
- 細粒度量子化の課題: tile-wise や block-wise 量子化のような細粒度量子化は、Tensor CoresからCUDA Coresへの 倍率乗算のための部分結果の転送において大きな 逆量子化オーバーヘッドを引き起こします。これにより頻繁にデータ移動が発生し、計算効率が低下し、ハードウェア利用が複雑になります。
3.1.2 提言
既存のハードウェアの制限に対処するために、将来の設計に対して以下の提言を行っています。
- 累積精度の向上: ハードウェアは累積レジスタ精度を適切な値(例: FP32) に向上させるか、設定可能な累積精度をサポートすべきです。これにより、様々なモデルにおける訓練と推論の異なる要件に対して、パフォーマンスと精度の trade-off を可能にします。
- 細粒度量子化のネイティブサポート: ハードウェアは細粒度量子化をネイティブにサポートし、Tensor Coresが倍率を受け取り、グループのスケーリング付きの行列乗算を実行できるようにすべきです。これにより、部分和累積と 逆量子化 の全体のプロセスを、最終結果が生成されるまでTensor Cores内で直接完了させることができ、逆量子化 オーバーヘッドを削減するための頻繁なデータ移動を回避できます。このアプローチの注目すべき産業的実装例としては、NVIDIA Blackwellのマイクロスケーリングデータ形式サポートがあり、大規模なネイティブ量子化の実践的な利点を示しています。
3.2 LogFMT:通信圧縮
現在のDeepSeek-V3アーキテクチャでは、ネットワーク通信のために低精度圧縮を採用しています。EP並列処理中、トークンは FP8量子化を使用してディスパッチされ、通信量をBF16と比較して50%削減します。これにより通信時間が大きく短縮されます。結合(Combine)ステージは精度要件のために依然としてより高い精度(例: BF16)を使用していますが、さらなる削減のためにFP8、カスタム精度フォーマット(例: E5M6)、およびFP8-BF16の混合を積極的にテストしています。
これらの従来の浮動小数点フォーマットに加えて、DeepSeek-AIチームはLogarithmic Floating-Point Formats (LogFMT-nBit)という新しいデータ型も試しました。これは、nが符号ビットSを含むビット数です。アクティベーションを元の線形空間から対数空間にマッピングすることで、アクティベーションの分布がより均一になります。具体的には、実装では1×128の要素のタイル [𝑥1, · · · , 𝑥𝑚] が与えられた場合、絶対値を取り、すべての要素の対数を計算し、最小値 min = log(abs(𝑥𝑖 )) と最大値 max = log(abs(𝑥 𝑗 )) を見つけます。最小値はS.00…01として、最大値はS.11…11としてエンコードされ、間隔は Step = (max-min) / (2^n-1-2) で表現されます。ゼロ値は特別にS.00…00で表現されます。残りの値は Step の最も近い整数K倍に丸められます。デコードプロセスは、符号ビットと exp(min + Step × (K-1)) を組み合わせることでシンプルに行われます。
局所的にminとStepを計算することで、このデータ型は異なるブロックに対して動的な表現範囲をサポートし、静的な浮動小数点フォーマットと比較して、より広い範囲をカバーしたり、より高い精度を提供したりできます。さらに、非バイアスのアクティベーション量子化のために、対数空間ではなく元の線形空間で丸めることが重要であることがわかりました。また、最大表現範囲がE5(5ビットの指数部を持つ浮動小数点)に類似するように、minをmax – log(2^32) より大きく制限しています。DeepSeek-AIチームは、MoEモデルのCombineステージをシミュレートするために残差枝の出力を定量化することで、約70億パラメータの密な言語モデルでLogFMT-nBitを検証しました。n=8(FP8と同じビット数)に設定した場合、LogFMT-8BitはE4M3 やE5M2 と比較して 優れた訓練精度を示しました。nを10ビットに増やした場合、BF16のCombineステージと同様の精度が得られることがわかりました。
3.2.1 制限
LogFMTを使用する当初の目的は、伝送中またはアクティベーション関数の近くでアクティベーションに適用することでした。これは同じビット幅でFP8よりも高い精度を提供するためです。しかし、その後の計算では、Hopper GPUのTensor Coresのデータ型に対応するために、BF16またはFP8への再変換が必要です。log/exp演算のためのGPU帯域幅不足とencode/decode中のレジスタ圧迫のため、encode/decode演算がall-to-all通信と融合された場合、オーバーヘッドは substantial になる可能性があります(50%〜100%)。したがって、実験結果でこのフォーマットの有効性は検証されていますが、最終的には採用していません。
3.2.2 提言
将来のハードウェアにおいて、FP8またはカスタム精度フォーマットに特化した圧縮・解凍ユニットをネイティブサポートすることは、有効なアプローチです。これにより、帯域幅要件を最小限に抑え、通信パイプラインを効率化できます。通信オーバーヘッドの削減は、MoE(Mixture of Experts)訓練のような帯域幅集約的なタスクにおいて特に有益です。
4. インターコネクション駆動設計
4.1 現在のハードウェアアーキテクチャ
現在使用されているNVIDIA H800 GPU SXMアーキテクチャ は、Figure 2に示されているように、H100 GPU と同様にHopperアーキテクチャに基づいています。ただし、規制遵守のためにFP64計算性能とNVLink帯域幅が削減されています。具体的には、H800 SXMノードのNVLink帯域幅は900 GB/sから400 GB/sに削減されています。この intra-node(ノード内)のスケールアップ帯域幅の大きな削減は、高性能ワークロードにとって課題となります。これを補うために、各ノードには8つの400G Infiniband (IB) CX7 NICが装備されており、帯域幅赤字を軽減するためにスケールアウト(ノード間)力 を強化しています。
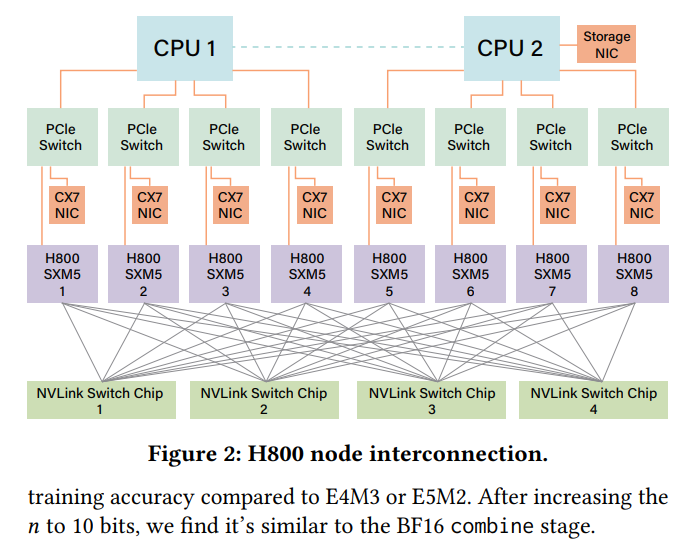
これらのハードウェア制約に対処するため、DeepSeek-V3モデルは、ハードウェアの強みと制約に合わせた設計上の考慮事項をいくつか取り入れています。
4.2 ハードウェアを意識した並列化
H800アーキテクチャの制約に合わせて、DeepSeek-V3のパフォーマンスを最適化するために以下の並列化戦略が考慮されました。
- Tensor Parallelism (TP) の回避: Tensor Parallelismは、NVLink帯域幅が限られているため、訓練中には非効率であるとして回避されています。ただし、推論中には、レイテンシを削減しTPOTパフォーマンスを向上させるために、TPを選択的に使用することは可能です。
- Enhanced Pipeline Parallelism (PP): DualPipe が使用され、AttentionとMoE計算をMoE通信とオーバーラップさせています。これによりパイプラインのバブルも削減され、GPU間のメモリ使用バランスが改善し、全体的なスループットが向上します。詳細についてはテクニカルレポート を参照してください。
- Accelerated Expert Parallelism (EP): 8つの400Gbps Infiniband (IB) NICsにより、システムは40GB/sを超える速度でall-to-all通信を実現しています。特に、all-to-all EP実装であるDeepEP はオープンソース化されており、以下のサブセクションで議論されているように、非常に効率的な Expert Parallelism を可能にします。
4.3 モデル協調設計:ノード制限ルーティング
H800アーキテクチャにおけるスケールアップ(intra-node)通信とスケールアウト(inter-node)通信の帯域幅格差は約4:1です。具体的には、NVLinkは200GB/sの帯域幅を提供しますが(そのうち約160GB/sが実際に達成可能)、各400Gbps IB NICはわずか50GB/sの帯域幅を提供します(小メッセージサイズとレイテンシの影響を考慮し、有効帯域幅として40GB/sを使用します)。より高い intra-node 帯域幅のバランスを取り、完全に活用するために、モデルアーキテクチャはハードウェアと協調設計されており、特にTopK Expert Selection Strategyにおいて考慮されています。
8ノード(合計64 GPU)と256のRoutedエキスパート(GPUあたり4エキスパート)のセットアップを考えます。DeepSeek-V3の場合、各トークンは1つのSharedエキスパートと8つのRoutedエキスパートにルーティングされます。その8つのターゲットエキスパートが8つのノードすべてに分散されている場合、IBを介した通信時間は8tになります(tはIBを介して1トークンを送信する時間)。しかし、より高いNVLink帯域幅を活用することで、同じノードにルーティングされたトークンはIBを介して一度送信され、その後intra-node GPUにNVLink経由で転送できます。NVLink転送により、IBトラフィックの重複排除が可能になります。所与のトークンのターゲットエキスパートがMノードに分散されている場合、重複排除されたIB通信コストはMt(M < 8)に削減されます。
IBトラフィックがMだけに依存するため、DeepSeek-V3はTopKエキスパート選択戦略にNode-Limited Routingを導入しています。具体的には、256のRoutedエキスパートを8つのグループに分け、グループあたり32のエキスパートを含み、各グループを単一のノードに展開します。この展開の上に、各トークンが最大4つのノードにルーティングされるようにアルゴリズム的に保証しています。このアプローチにより、IB通信のボトルネックが軽減され、訓練中の有効通信帯域幅が向上します。
4.4 スケールアップとスケールアウトの収束
4.4.1 現在の実装の制限
Node-Limited Routing戦略は通信帯域幅要件を削減しますが、intra-node (NVLink) と inter-node (IB) インターコネクト間の帯域幅格差により、通信パイプラインカーネルの実装が複雑になります。実際には、GPUのStreaming Multiprocessors (SM)スレッドは、ネットワークメッセージ処理(例: QPsとWQEsの filling)とNVLinkを介したデータ転送の両方に使用され、計算リソースを消費します。例えば、訓練中には、H800 GPU上のSMsの最大20が通信関連操作に割り当てられ、実際の計算に利用できるリソースが少なくなります。オンライン推論でのスループットを最大化するために、EP all-to-all通信はNIC RDMAを介して完全に行われ、SMリソース競合を回避し計算効率を向上させています。これは、RDMAの非同期通信モデルが計算と通信のオーバーラップにもたらす利点を強調しています。
以下は、現在EP通信中、特に結合(Combine)ステージのReduce操作やデータ型変換のためにSMsによって実行されている主要なタスクです。これらのタスクを専用の通信ハードウェアにオフロードできれば、SMsを計算カーネルのために解放し、全体的な効率を 大幅に向上させることができます。
- データ転送 (Forwarding Data): 同じノード内の複数のGPU宛てのIBトラフィックを、IBとNVLinkドメイン間で集約します。
- データ転送 (Data Transport): RDMAバッファ(登録されたGPUメモリ領域)と入力/出力バッファ間でデータを移動します。
- Reduce操作: EP all-to-all結合通信に必要なReduce操作を実行します。
- メモリレイアウト管理: IBとNVLinkドメイン間での chunked データ転送のための fine-grained なメモリレイアウトを処理します。
- データ型キャスト: all-to-all通信の前後にデータ型を変換します。
4.4.2 提言
これらの非効率性に対処するために、将来のハードウェアは intra-node(スケールアップ)通信と inter-node(スケールアウト)通信を統合されたフレームワークに組み込むことを強く推奨します。ネットワークトラフィック管理とNVLinkとIBドメイン間のシームレスな転送のための専用コプロセッサを組み込むことで、そのような設計はソフトウェアの複雑さを軽減し、帯域幅利用を最大化できます。例えば、DeepSeek-V3で採用されている node-limited routing 戦略は、動的なトラフィック重複排除に対するハードウェアサポートによりさらに最適化できます。
また、Ultra Ethernet Consortium (UEC)、Ultra Accelerator Link (UALink) のような新しいインターコネクトプロトコルも認識しており、これらはスケールアップおよびスケールアウト通信の進歩を推進する態勢が整っています。さらに最近では、Unified Bus (UB) がスケールアップおよびスケールアウト収束への新しいアプローチを導入しています。セクション6では、UECとUALinkによって提案された 技術的な革新についてさらに探求しています。しかし、このセクションでは、プログラミングフレームワークレベルでのスケールアップおよびスケールアウト収束の達成に主な焦点を当てています。
- 統合ネットワークアダプタ: 統合されたスケールアップおよびスケールアウトネットワークに接続されたNICs(ネットワークインターフェースカード)またはI/O Dieを設計します。これらのアダプタは、ポリシーベースのルーティングを備えた単一のLID(Local Identifier)またはIPアドレスを使用して、スケールアウトネットワークからスケールアップネットワーク内の特定のGPUにパケットを転送するような基本的なスイッチ機能もサポートすべきです。
- 専用通信コプロセッサ: ネットワークトラフィックを処理するための専用コプロセッサまたはプログラム可能なコンポーネント(例えば、I/O Die)を導入します。このコンポーネントはGPU SMsからのパケット処理をオフロードし、パフォーマンス低下を防ぎます。加えて、効率的なバッファ管理のためのハードウェア加速メモリコピー機能を含めるべきです。
- 柔軟な転送、ブロードキャスト、Reduceメカニズム: ハードウェアは、スケールアップおよびスケールアウトネットワークをまたいだ柔軟な転送、ブロードキャスト操作(EPディスパッチ用)、およびReduce操作(EP結合用)をサポートすべきです。これは現在のGPU SMベースの実装を真似するものであり、有効帯域幅を向上させるだけでなく、ネットワーク固有操作の計算複雑さを削減します。
- ハードウェア同期プリミティブ: メモリ一貫性の問題やハードウェアレベルでの out-of-order パケット到着を処理するための fine-grained なハードウェア同期命令を提供します。これにより、余分なレイテンシを導入し、プログラミング複雑さを増加させるRDMA完了イベントのようなソフトウェアベースの同期メカニズムの必要性が排除されます。acquire/releaseメカニズムを備えた memory-semantic communication は 確実な実装です。
これらを実装することにより、将来のハードウェア設計は、ソフトウェア開発を簡素化しつつ、大規模分散AIシステムの効率を大幅に向上させることができます。
4.5 帯域幅競合とレイテンシ
4.5.1 制限
加えて、現在のハードウェアは、NVLinkとPCIe上で異なる種類のトラフィック間で帯域幅を動的に割り当てる柔軟性に欠けています。例えば、推論中には、CPUメモリからGPUへのKVキャッシュデータの転送が数十GB/sを消費し、PCIe帯域幅を saturating させる可能性があります。GPUが同時にEP通信のためにIBを使用する場合、KVキャッシュ転送とEP通信間のこの競合が全体的なパフォーマンスを低下させ、レイテンシスパイクを引き起こす可能性があります。
4.5.2 提言
- 動的NVLink/PCIeトラフィック優先順位付け: ハードウェアは、そのタイプに基づいてトラフィックの動的優先順位付けをサポートすべきです。例えば、EP、TP、KVキャッシュ転送に関連するトラフィックには、インターコネクト効率を最大化するために異なる優先順位を割り当てるべきです。PCIeに関しては、ユーザーレベルプログラミングにトラフィッククラス(TC)を公開すれば十分でしょう。
- I/O Die チップレット統合: NICsを直接I/O Dieに統合し、従来のPCIeを介するのではなく、同じパッケージ内でCompute Dieに接続することは、通信レイテンシを substantially に削減し、PCIe帯域幅競合を軽減します。
- スケールアップドメイン内のCPU-GPUインターコネクト: intra-node通信をさらに最適化するために、CPUとGPUは、PCIeのみに依存するのではなく、NVLinkまたは同様の専用高帯域幅ファブリックを使用して相互接続すべきです。NICをI/O Dieに統合することで得られる利点と同様に、このアプローチは、訓練および推論中のGPUメモリとCPUメモリ間のパラメータまたはKVキャッシュの offloading のようなシナリオを大幅に改善できます。
5. 大規模ネットワーク駆動設計
5.1 ネットワーク協調設計:マルチプレーンFat-Tree
DeepSeek-V3の訓練中に、3 に示すように、Multi-Plane Fat-Tree (MPFT)スケールアウトネットワークを展開しました。各ノードには8つのGPUと8つのIB NICがあり、各GPU-NICペアは distinct なネットワークプレーンに割り当てられています。加えて、各ノードには、3FS 分散ファイルシステムにアクセスするための別のストレージネットワークプレーンに接続された400Gbps Ethernet RoCE NICがあります。スケールアウトネットワークでは、64ポート400G IBスイッチを使用しており、理論的には16,384 GPUまでサポート可能なトポロジーでありながら、2層ネットワークのコストとレイテンシの利点を維持しています。しかし、ポリシーおよび規制上の制約により、最終的には2000台強のGPUが展開されました。
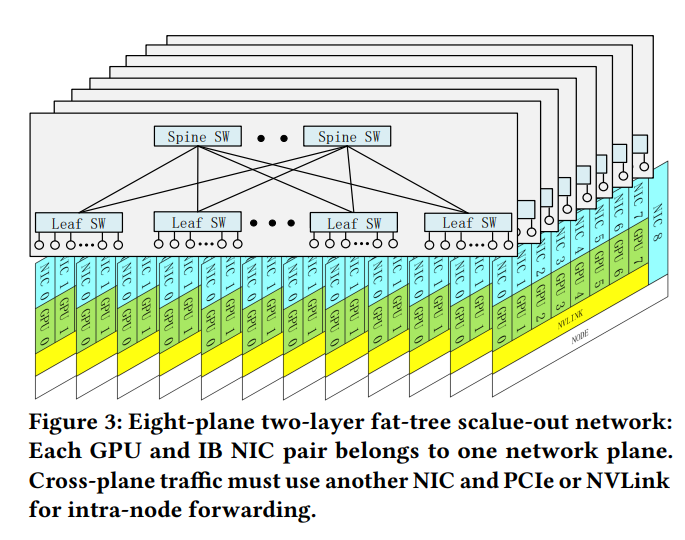
さらに、現在のIB ConnectX-7の制限により、展開されたMPFTネットワークは envisioned されたアーキテクチャを完全に実現していません。理想的には、Figre 4 に示されているように、各NICは複数の物理ポートを備え、それぞれが separate なネットワークプレーンに接続されているにもかかわらず、ポートボンディングを通じてユーザーには単一の論理インターフェースとして公開されます。ユーザー視点では、単一のQueue Pair (QP) が利用可能なすべてのポートを seamlessly に使用してメッセージを送受信できます。これはパケットスプレイングに似ています。結果として、同じQPから発信されたパケットは異なるネットワークパスを経由し、受信側で out of order に到着する可能性があるため、メッセージの一貫性を保証し、正しい順序付けセマンティクスを維持するために、NIC内での out-of-order 配置のネイティブサポートが必要になります。例えば、InfiniBand ConnectX-8はネイティブに4つのプレーンをサポートしています。将来のNICが高度なマルチプレーン 能力を完全にサポートし、2層Fat-Treeネットワークがより大規模なAIクラスタに効率的にスケールできるようになることはアドバンテージでしょう。全体として、マルチプレーンアーキテクチャは、フォルト分離、堅牢性、ロードバランシング、および大規模システムのスケーラビリティにおいて大きな利点を提供します。
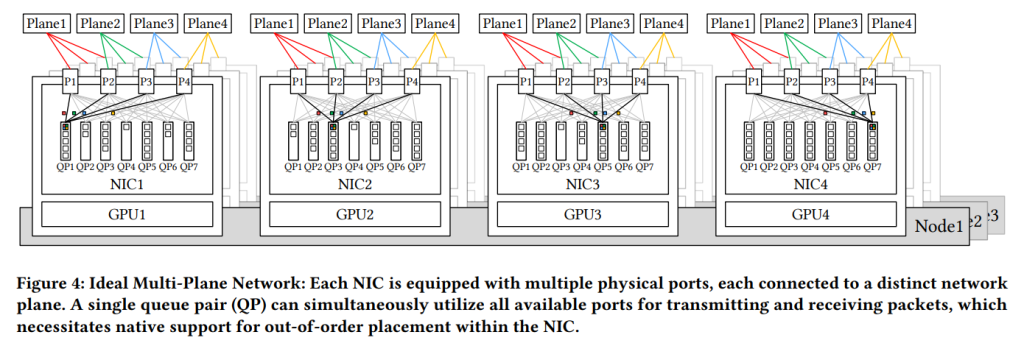
5.1.1 マルチプレーンFat-Treeネットワークの利点
- Multi-Rail Fat-Tree (MRFT) のサブセット: MPFTトポロジーは、より広範なMRFTアーキテクチャの特定のサブセットを構成します。結果として、NVIDIAおよびNCCLによってMulti-Railネットワーク向けに開発された既存の最適化を、マルチプレーンネットワーク展開内でシームレスに活用できます。さらに、NCCLのPXN テクノロジー のサポートは、プレーン間の直接相互接続がない場合でも効率的な通信を可能にし、inherent な inter-plane 分離の課題に対処します。
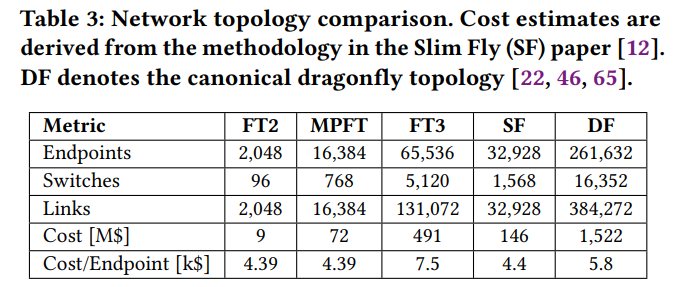
- コスト効率: Table 3 に示すように、マルチプレーンネットワークは2層Fat-Tree (FT2) トポロジーを使用して10kを超えるエンドポイントを可能にし、3層Fat-Tree (FT3) と比較してネットワークコストを削減します。エンドポイントあたりのコストは、コスト効率の高いSlim Fly (SF) トポロジー よりもわずかに適合的します。
- トラフィック分離: 各プレーンは独立して動作し、あるプレーンの輻輳が他のプレーンに影響しないことを保証します。この分離により全体的なネットワーク安定性が向上し、連鎖的なパフォーマンス低下を防ぎます。
- レイテンシ削減: 2層トポロジーは、DeepSeek-AIの実験で実証されているように、3層Fat-Treeよりも低いレイテンシを達成します。これにより、MoEベースの訓練および推論のようなレイテンシに敏感なアプリケーションに特に適しています。
- 堅牢性: Figure 4 に示すように、マルチポートNICは複数の uplinks を提供するため、シングルポート障害が接続を 中断させず、迅速で透明な障害復旧が可能です。現在の400G NDR InfiniBand の制限により、cross-plane 通信には intra-node 転送が必要であり、これが推論中に追加的なレイテンシを導入することに注意することが重要です。将来のハードウェアが前述のようにスケールアップおよびスケールアウトネットワーク収束を達成できれば、このレイテンシは削減され、マルチプレーンネットワークの実現可能性がさらに向上します。
5.1.2 性能分析
Multi-Plane Network設計の有効性を検証するために、クラスタで実世界の実験を実施し、Multi-Plane Two-Layer Fat Tree (MPFT) と Single-Plane Multi-Rail Fat Tree (MRFT) のパフォーマンスを比較しました。以下は、DeepSeek-AIの実験からの主要な発見です。
1. All-to-All通信とEPシナリオ:
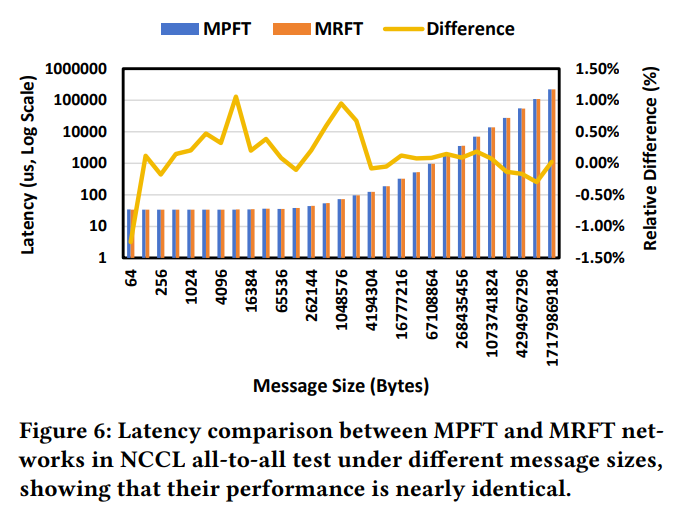
Figure 5 に示すように、マルチプレーンネットワークのall-to-allパフォーマンスは、シングルプレーンmulti-railネットワークのそれと非常に似ています。このパフォーマンスの類似性は、multi-railトポロジーでNVLinkを介したトラフィック転送を最適化するNCCLのPXN メカニズムによるものです。マルチプレーンもこのメカニズムから利益を得ています。Figure 6 に示すように、16基のGPUで実施されたall-to-all通信テストの結果は、MPFTとMRFTトポロジー間のレイテンシに無視できる違いを示しています。
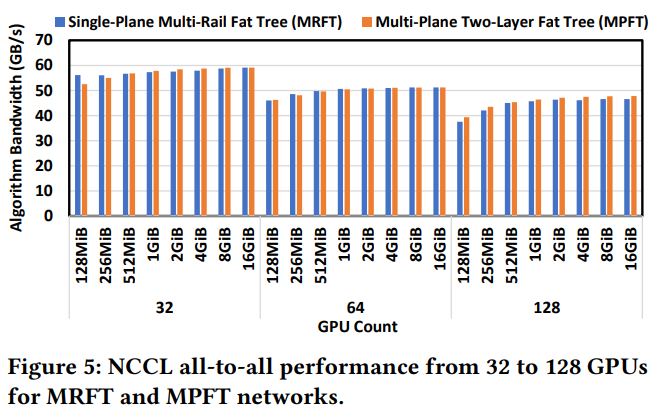
実践的な訓練シナリオでのall-to-all通信のMPFTのパフォーマンスを評価するために、訓練中に一般的に使用されるEP通信パターンをテストしました。Figure 7 に示すように、各GPUはマルチプレーンネットワークで40GB/sを超える高い帯域幅を達成しており、訓練の要求を満たす信頼性の高いパフォーマンスを提供しています。
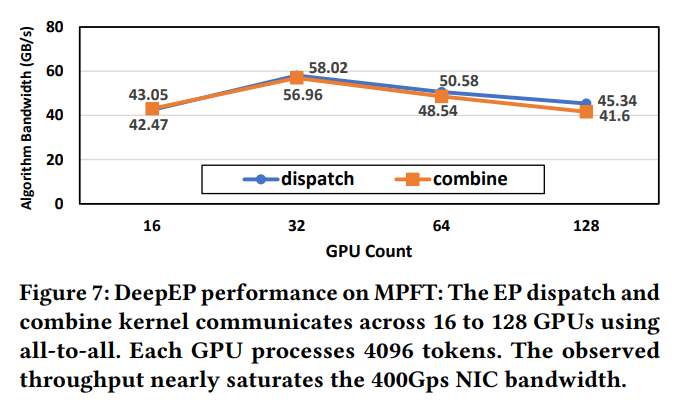
2. DeepSeek-V3モデルの訓練スループット:
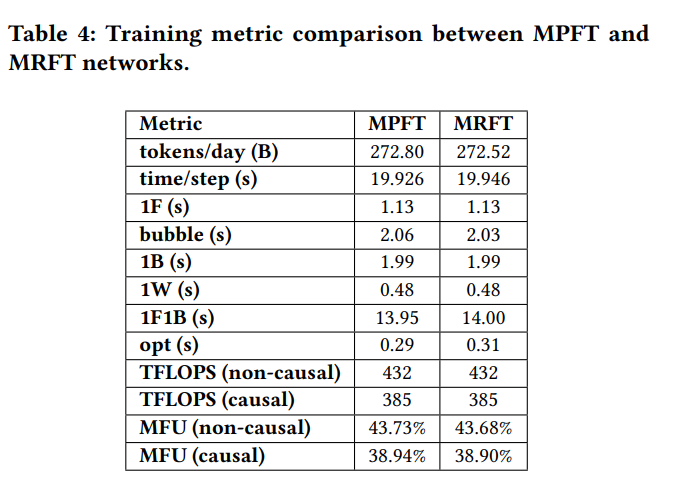
Table 4 では、MPFTとMRFT間のDeepSeek-V3モデルの訓練メトリックも比較しています。MFU(Model Flops Utilization)は、BF16ピーク性能に基づいて計算されます。Causal MFUはAttention行列の下三角部分のflopsのみを考慮し(FlashAttention に沿ったもの)、non-causal MFUはAttention行列全体のflopsを含みます(Megatron に沿ったもの)。1F、1B、1Wはそれぞれ順伝播時間、入力逆伝播時間、重み逆伝播時間を示します。V3モデルを2048基のGPUで訓練した場合、MPFTのパフォーマンスはMRFTとほぼ同一であり、観測された違いは一般的な変動と測定誤差の範囲内に収まっています。
5.2 低レイテンシネットワーク
DeepSeek-AIのモデル推論では、大規模なEPがall-to-all通信に重度に依存しており、これは帯域幅とレイテンシの両方に非常に敏感です。セクション2.3.2で議論された典型的なシナリオを考えると、ネットワーク帯域幅が50GB/sの場合、データ転送は理想的には約120 μsかかるはずです。したがって、microseconds order の intrinsic なネットワークレイテンシは、システムパフォーマンスに致命的に影響する可能性があり、その影響は無視できません。
5.2.1 IBかRoCEか
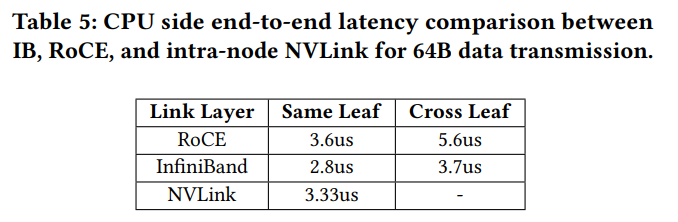
Table 5に示すように、IBは一貫して低いレイテンシを達成しており、分散訓練や推論のようなレイテンシに敏感なワークロードには 適した選択肢です。IBはRDMA over Converged Ethernet (RoCE) よりも優れたレイテンシパフォーマンスを持ちますが、特定の制限も伴います。
- コスト: IBハードウェアはRoCEソリューションよりも高価であり、その広範な採用を制限しています。
- スケーラビリティ: IBスイッチは通常、スイッチあたり64ポートしかサポートしておらず、RoCEスイッチで一般的に見られる128ポートと比較して少なくなっています。これは、特に大規模展開において、IBベースのクラスタのスケーラビリティを制限します。
5.2.2 RoCE改善への提言
RoCEはIBに代わるコスト効果的な選択肢となる potential を秘めていますが、現在のレイテンシとスケーラビリティの制限により、大規模AIシステムの要求を完全に満たすことができていません。以下に、RoCE改善のための specific な提言を概説します。
1. 専用低レイテンシRoCEスイッチ: Ethernetベンダーが、不要なEthernet機能を削除することでRDMAワークロード向けに 特化し最適化されたRoCEスイッチを開発することを推奨します。Slingshotアーキテクチャ は、Ethernetベースの設計がIBに匹敵するレイテンシパフォーマンスを達成できる方法を実証してしています。同様に、Broadcom からの最近の革新(AI Forwarding Header (AIFH) や今後登場する低レイテンシEthernetスイッチを含む)は、AIに特化した高性能Ethernetファブリックの実現可能性を示しています。DeepSeek-AIチームは、この方向での継続的な革新に期待しています。
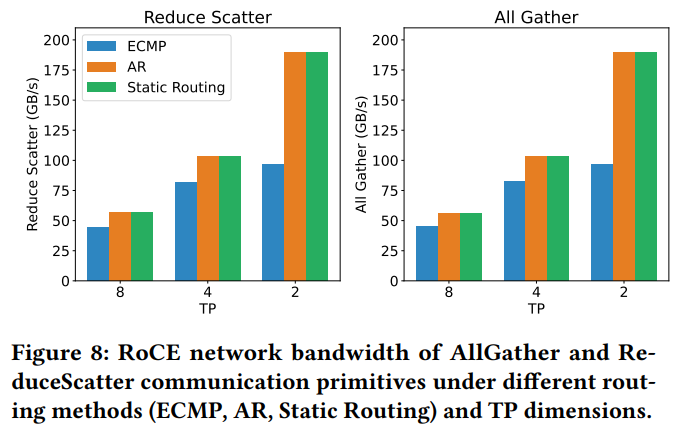
2. 最適化ルーティングポリシー: Figure 8 に示すように、RoCEのデフォルトのEqual-Cost Multi-Path (ECMP)ルーティングポリシーは、インターコネクト全体にトラフィックを効率的に分散するのに苦労しており、NCCL collective communicationテストで深刻な輻輳パフォーマンス低下を引き起こします。DP(Data Parallelism)のようなLLM訓練トラフィックは、ランダム性が不足する傾向があり、複数のフローが同じインターコネクトリンクに収束する原因となります。対照的に、Adaptive Routing (AR) は、複数のパスにパケットを動的にスプレイングすることでネットワークパフォーマンスを大幅に向上させることができます。手動で設定されたルートテーブルに基づく静的ルーティングは、特定の宛先へのリンク競合を回避できますが、柔軟性に欠けます。大規模なall-to-all通信では、アダプティブルーティングが優れたパフォーマンスとスケーラビリティを提供します。
3. 改善されたトラフィック分離または輻輳制御メカニズム: 現在のRoCEスイッチは限られた数の優先キューしかサポートしておらず、EPのall-to-allやDPのall-reduceのような同時に発生する通信パターンを含む複雑なAIワークロードには不十分です。そのような混合ワークロードでは、all-to-allトラフィックがバースト的なmany-to-one 転送によりincast輻輳を引き起こす可能性があり、全体的なネットワークパフォーマンスを低下させる可能性があります。他のトラフィックへのインキャスト輻輳に対処する一つのアプローチは、Virtual Output Queuing (VOQ) を採用し、各QPに専用の仮想キューを割り当てることでトラフィックフローを分離することです。あるいは、RTTベースのCC (RTTCC) やユーザープログラム可能なCC (PCC) のような、より効果的な輻輳制御 (CC)メカニズムが採用でき、動的なトラフィック条件下で低レイテンシと高スループットを維持するためにNIC-スイッチ協調最適化が可能になります。
5.2.3 InfiniBand GPUDirect Async (IBGDA)
ネットワーク通信のレイテンシを削減するためにIBGDA を利用しています。従来、ネットワーク通信にはCPUプロキシスレッドの作成が伴いました。GPUがデータを準備した後、CPUプロキシに通知する必要があり、CPUプロキシがwork request (WR)の制御情報を設定し、doorbellメカニズムを介してNICにデータ伝送を開始するように信号を送ります。このプロセスは追加の通信オーバーヘッドを生じさせます。。
IBGDAは、GPUが直接WRの内容を記入し、RDMA doorbell MMIOアドレスに書き込むことを可能にすることでこの問題に対処します。GPU内で制御プレーン全体を管理することで、IBGDAはGPU-CPU通信に伴う重大なレイテンシオーバーヘッドを排除します。さらに、多数の小さなパケットを送信する場合、制御プレーンプロセッサが容易にボトルネックとなる可能性があります。GPUには複数の並列スレッドがあるため、送信側はこれらのスレッドを活用してワークロードを分散させ、そのようなボトルネックを回避できます。DeepSeek-AIのDeepEP を含む様々な研究 がIBGDAを活用し、著しいパフォーマンス向上を報告しています。したがって、DeepSeek-AIチームは、そのような機能がアクセラレータデバイス全体で広くサポートされることを推奨しています。
6. 将来のハードウェアアーキテクチャ設計に関する考察と洞察
これまでのセクションに基づいて、大規模AIワークロードに特化したハードウェア設計のための主要なアーキテクチャ上の知見を要約し、将来の方向性を概説します。セクション2.3.2では、モデル推論を加速するための大規模なスケールアップネットワークの重要性が強調されました。セクション3では、低精度計算および通信のための効率的なサポートの必要性が議論されました。セクション4では、スケールアップおよびスケールアウトアーキテクチャの収束と、提案されたいくつかの拡張機能が探求されました。セクション5では、マルチプレーンネットワークトポロジーに焦点を当て、Ethernetベースのインターコネクトに必要な主要な改善点が特定されました。
これらのセクションは総じて、具体的なアプリケーション文脈におけるハードウェア制限を特定し、対応する提言を提供しています。その基礎の上に、このセクションではより広範な考慮事項に議論を拡大し、将来のハードウェアアーキテクチャ設計に向けた将来を見据えた方向性を提案します。
6.1 堅牢性の課題
6.1.1 制限
- インターコネクト障害: 高性能インターコネクト(例: InfiniBandおよびNVLink)は、断続的な切断が発生しやすく、ノード間の通信を中断させる可能性があります。これはEP(エキスパート並列処理)のような通信負荷の高いワークロードでは特に深刻な問題であり、たとえ短時間の中断でも重大なパフォーマンス低下やジョブ失敗につながる可能性があります。
- 単一ハードウェア障害: ノードクラッシュ、GPU障害、またはECC(エラー訂正コード)メモリエラーは、長期間実行される訓練ジョブを危険にさらす可能性があり、しばしばコストのかかる再起動が必要になります。そのような障害の影響は、システムのサイズに比例して単一点障害の確率が増加するため、大規模展開では深刻化します。
- サイレントデータ破損: ECCメカニズムによって検出されないエラー(多ビットメモリフリップや計算上の不正確さなど)は、モデル品質に重大なリスクをもたらします。これらのエラーは、検出されずに伝播し、下流の計算を破損させる可能性があるため、長期間実行されるタスクでは特に潜行性で厄介です。現在の軽減戦略は、アプリケーションレベルのヒューリスティックに依存しており、システム全体の堅牢性を保証するには不十分です。
6.1.2 高度なエラー検出・訂正への提言
サイレントデータ破損に関連するリスクを軽減するために、ハードウェアは従来のECCを超える高度なエラー検出メカニズムを組み込む必要があります。チェックサムベースの検証やハードウェアアクセラレーションによる冗長性チェックのような技術は、大規模展開に対してより高い信頼性を提供できます。
さらに、ハードウェアベンダーは、エンドユーザーに包括的な診断ツールキットを提供するべきです。これにより、ユーザーはシステムの整合性を厳密に検証し、潜在的なサイレントデータ破損を予防的に特定できるようになります。このようなツールキットは、標準のハードウェアパッケージの一部として組み込まれると、運用ライフサイクル全体にわたる透明性と継続的な検証を促進し、全体的なシステム信頼性を強化します。
6.2 CPUボトルネックとインターコネクト
アクセラレータ設計がしばしば注目の的となりますが、CPUは計算の協調、I/O管理、システムスループットの維持にとって不可欠なままです。しかし、現在のアーキテクチャはいくつかの重大なボトルネックに直面しています。
まず、セクション4.5で議論されたように、CPUとGPU間のPCIeインターフェースはしばしば帯域幅ボトルネックとなり、特に大規模なパラメータ、勾配、またはKVキャッシュ転送中に顕著です。これを軽減するために、将来のシステムはCPU-GPU間の直接インターコネクト(NVLinkやInfinity Fabricなど)を採用するか、CPUとGPUの両方をスケールアップドメインに統合し、ノード内ボトルネックを排除すべきです。
PCIeの制限に加えて、そのような高いデータ転送速度を維持するためには、非常に高いメモリ帯域幅も必要です。例えば、160レーンのPCIe 5.0を飽和させるには、ノードあたり640 GB/sを超える帯域幅が必要であり、これはノードあたり約1 TB/sのメモリ帯域幅要件に換算され、従来のDRAMアーキテクチャにとって重大な課題となります。
最後に、カーネル起動やネットワーク処理のようなレイテンシに敏感なタスクは、高いシングルコアCPUパフォーマンスを要求し、通常4 GHz以上の基本周波数が必要です。さらに、現代のAIワークロードは、制御側のボトルネックを防ぐために、GPUあたり十分なCPUコア数を要求します。チップレットベースのアーキテクチャでは、キャッシュを意識したワークロード分割と分離をサポートするために、追加のコアが必要です。
6.3 AIのためのインテリジェントネットワークへ
レイテンシに敏感なワークロードの要求を満たすために、将来のインターコネクトは低レイテンシとインテリジェントネットワークの両方を優先すべきです。
- コパッケージドオプティクス (Co-Packaged Optics): シリコンフォトニクスを組み込むことで、スケーラブルな高帯域幅スケーラビリティと向上したエネルギー効率が可能になり、これは大規模分散システムにとって不可欠です。
- ロスレスネットワーク: クレジットベースフローコントロール (CBFC) メカニズムはロスレスなデータ伝送を保証しますが、単純にフロー制御をトリガーすると深刻なヘッドオブラインブロッキングを誘発する可能性があります。したがって、投入レートを予防的に制御し、病的な輻輳シナリオを回避する高度な、エンドポイント駆動の輻輳制御 (CC) アルゴリズムを導入することが不可欠です。
- アダプティブルーティング: セクション5.2.2で強調されたように、将来のネットワークは、リアルタイムネットワークの状態を継続的に監視し、トラフィックをインテリジェントに再分散する動的なルーティングスキーム(パケットスプレイングや輻輳認識パス選択など)の採用を標準化すべきです。これらの適応的な戦略は、all-to-allやreduce-scatter操作を含む集団通信ワークロード中のホットスポットを軽減し、ボトルネックを緩和する上で特に効果的です。
- 効率的な耐障害性プロトコル: 障害に対する堅牢性は、自己修復プロトコル、冗長ポート、および迅速なフェイルオーバー技術の展開を通じて大幅に向上できます。例えば、リンク層リトライメカニズムや選択的再送信プロトコルは、大規模ネットワーク全体で信頼性をスケーリングする上で不可欠であり、断続的な障害にもかかわらずダウンタイムを最小限に抑え、シームレスな操作を保証します。
- 動的リソース管理: 混合ワークロードを効果的に処理するために、将来のハードウェアは動的な帯域幅割り当てとトラフィック優先順位付けを可能にすべきです。例えば、推論タスクは統合されたクラスタ内の訓練トラフィックから分離され、レイテンシに敏感なアプリケーションの応答性を保証すべきです。
6.4 メモリセマンティック通信と順序問題に関する考察
ロード/ストアメモリセマンティクスを使用したノード間通信は効率的でプログラマフレンドリーですが、現在の実装はメモリ順序付けの課題によって妨げられています。例えば、データを書き込んだ後、送信側は受信側に通知するためにフラグを更新する前に、明示的なメモリバリア(フェンス)を発行してデータの一貫性を保証する必要があります。この厳密な順序付けは追加の往復時間(RTT)レイテンシを導入し、発行スレッドを停止させ、処理中のストアを阻害し、スループットを削減します。同様の順不同同期問題はメッセージセマンティックRDMAでも発生します。例えば、InfiniBandまたはNVIDIA BlueField-3上で通常のRDMA書き込みの後でパケットスプレイングを伴うRDMAアトミック加算操作を実行すると、追加のRTTレイテンシが発生する可能性があります。
これらに対処するために、DeepSeek-AIチームは、メモリセマンティック通信に対する組み込み順序保証を提供するハードウェアサポートを提唱しています。そのような一貫性は、プログラミングレベル(例: acquire/releaseセマンティクスを介して)および受信側のハードウェアによって強制されるべきであり、追加オーバーヘッドなしの順序通りの配信を可能にします。
いくつかの方法が考えられます。例えば、受信側はアトミックメッセージをバッファリングし、パケットシーケンス番号を使用して順序通りの処理を行うことができます。しかし、acquire/releaseメカニズムはより洗練されていて効率的です。DeepSeek-AIチームは、簡単な概念的メカニズムとして、Region Acquire/Release (RAR) メカニズムを提案しています。これは、受信側ハードウェアがRNRメモリ領域の状態を追跡するためにビットマップを保持し、acquire/release操作がRARアドレス範囲に範囲が限定されます。最小限のビットマップオーバーヘッドで、これにより効率的な、ハードウェア強制の順序付けが可能になり、明示的な送信側フェンスが排除され、順序付けがハードウェアに委ねられます(理想的にはNICまたはI/Oダイ上)。重要なことに、RARメカニズムはメモリセマンティック操作だけでなく、メッセージセマンティックRDMAプリミティブにも利益をもたらし、したがってその実用的な適用範囲を広げます。
6.5 インネットワーク計算と圧縮
EP(エキスパート並列処理)は2つの重要なall-to-allステージ(ディスパッチと結合)を含み、インネットワーク最適化の大きな機会を提示しています。ディスパッチステージは小規模なマルチキャスト操作に似ており、単一のメッセージが複数のターゲットデバイスに転送される必要があります。自動パケット複製と複数の宛先への転送を可能にするハードウェアレベルのプロトコルは、通信オーバーヘッドを劇的に削減し、効率を向上させることができます。
結合ステージは、小規模なReduction操作として機能し、インネットワーク集約技術から利益を得ることができます。ただし、EP結合におけるReductionスコープが小さいこととワークロードの不均衡により、インネットワーク集約を柔軟な方法で実装するのは困難です。
さらに、セクション3.2で強調されたように、LogFMTはモデルパフォーマンスへの影響を最小限に抑えつつ、低精度トークン伝送を可能にします。ネットワークハードウェア内にLogFMTをネイティブに組み込むことは、エントロピー密度を増加させ、帯域幅使用量を削減することで通信をさらに最適化できます。ハードウェアアクセラレーションされた圧縮・解凍は、LogFMTを分散システムにシームレスに統合することを可能にし、全体的なスループットを向上させます。
6.6 メモリ中心の革新
6.6.1 メモリ帯域幅の制限
モデルサイズの指数関数的な成長は、高帯域幅メモリ(HBM)技術の進歩を追い越しています。この格差はメモリボトルネックを生み出しており、特にTransformerのようなアテンション処理の多いアーキテクチャで顕著です。
6.6.2 提言
- DRAMスタック型アクセラレータ: 高度な3Dスタッキング技術を活用することで、DRAMダイをロジックダイの上に垂直に統合でき、非常に高いメモリ帯域幅、超低レイテンシ、そして実用的なメモリ容量(スタックに制限されるが)を可能にします。このアーキテクチャパラダイムは、メモリ帯域幅が重大なボトルネックであるMoEモデルでの超高速推論に著しくな利点があることが証明されています。SeDRAMのようなアーキテクチャは、メモリバウンドなワークロードに対して前例のないパフォーマンスを提供し、このアプローチの可能性を実証しています。
- System-on-Wafer (SoW): ウェハスケール統合は、計算密度とメモリ帯域幅を最大化でき、超大規模モデルのニーズに対応します。
7. 結論
DeepSeek-V3は、大規模AIシステムのスケーラビリティ、効率、および堅牢性を推進する上で、ハードウェア-ソフトウェア協調設計が持つ変革の可能性を実証しています。現在のハードウェアアーキテクチャの制限に対処し、実行可能な提言を提案することにより、本論文は次世代のAI最適化ハードウェアのためのロードマップを提供します。これらの革新は、AIワークロードが複雑さと規模を増し続ける中で不可欠となり、インテリジェントシステムの未来を推進するでしょう。
まとめ
DeepSeek-V3の開発事例を通して、大規模言語モデルのスケーリングにおけるハードウェアの課題と、それを解決するためのハードウェアとモデルの協調設計の重要性について解説しました。
DeepSeek-V3は、MLAによるメモリ効率の向上、MoEによる計算コストの削減、MTPによる推論速度の向上といったモデル側の革新に加え、FP8混合精度訓練やMulti-Planeネットワーク、Node-Limited Routingといったインフラ・ハードウェア側の工夫を組み合わせることで、限られたGPUリソースでも高い性能を達成しました。これは、単にモデルを大きくするだけでなく、ハードウェアの特性を理解し、それに合わせた設計を行う「協調設計」がいかに重要であるかを示す好例です。
そして、この開発経験から、将来のAIハードウェアが備えるべき機能(FP8累積精度の向上、細粒度量子化のネイティブサポート、統合されたスケールアップ/スケールアウト通信、動的な帯域幅割り当て、高度なエラー検出・訂正、CPUボトルネック解消、インテリジェントネットワーク機能、メモリセマンティクス順序保証、インネットワーク計算・圧縮、メモリ中心の革新など)について、具体的な提言がなされています。
AI技術がさらに発展し、より大規模で複雑なモデルが登場するにつれて、これらのハードウェア課題はますます重要になります。本論文で示されたDeepSeek-V3の成果とそこから得られた洞察は、今後のAIシステム、特にハードウェアとソフトウェアの協調設計の方向性を考える上で、貴重な資料となるでしょう。








