
はじめに
本稿では、遺伝病の解明や進化の謎を探る上で不可欠なゲノム解析の分野で、その精度を大きく向上させる新しいツールについて解説します。
Google Researchが2025年8月6日に公開したブログ記事「Highly accurate genome polishing with DeepPolisher: Enhancing the foundation of genomic research」を元に、深層学習(ディープラーニング)を活用したゲノムアセンブリ修正ツール「DeepPolisher」の仕組みと、それがゲノム研究全体にどのような意義を持つのかをご紹介します。
参考記事
- タイトル: Highly accurate genome polishing with DeepPolisher: Enhancing the foundation of genomic research
- 発行元: Google Research
- 発行日: 2025年8月6日
- URL: https://research.google/blog/highly-accurate-genome-polishing-with-deeppolisher-enhancing-the-foundation-of-genomic-research/
GitHub
要点
- Googleが開発した「DeepPolisher」は、深層学習を用いてゲノムアセンブリに含まれる塩基レベルのエラーを正確に修正するオープンソースのツールである。
- ゲノムアセンブリ全体のエラー数を約50%削減し、特に遺伝子の機能を損なう可能性のある挿入・欠失(インデル)エラーを70%以上も削減する。
- 自然言語処理などで利用されるTransformerアーキテクチャを応用し、複数のDNA配列データからエラーのパターンを学習して修正候補を提示する。
- すでにヒトの多様なゲノム情報を集める「ヒトパゲノム参照コンソーシアム(HPRC)」で採用され、より高品質な参照ゲノムの構築に貢献している。
詳細解説
ゲノム解析の基礎:なぜ正確な「生命の設計図」が必要か?
私たちの体の設計図であるゲノムは、DNAという物質にA(アデニン)、T(チミン)、G(グアニン)、C(シトシン)という4種類の塩基の配列として記録されています。この膨大な塩基配列(ヒトの場合は約30億個)を正確に読み解くことは、遺伝病の原因を特定したり、がんの治療法を開発したり、生命の進化の歴史を辿ったりと、現代の生命科学や医療において極めて重要です。
しかし、現在の技術ではゲノム全体を一度に読み取ることはできません。そのため、DNAを細かく断片化して、それぞれの断片の塩基配列を読み取り(シーケンシング)、後からコンピュータで繋ぎ合わせる「ゲノムアセンブリ」という作業を行います。このアセンブリの過程で、どうしても読み取りエラーや繋ぎ合わせのミスが発生してしまいます。
このエラーは、いわば設計図の「誤植」のようなものです。たった一つの塩基が間違っているだけでも、ある遺伝子が見つけられなくなったり、病気の原因となる変異が見過ごされたりする可能性があります。そのため、アセンブルされたゲノム配列をいかにして「磨き上げ(ポリッシング)」、エラーをなくしていくかが大きな課題でした。
ゲノムを読む技術の進化と課題
ゲノムシーケンシング技術は大きく分けて2種類あります。一つは、数百塩基程度の短い断片を高精度に大量に読み取る「ショートリードシーケンシング」です。もう一つは、数万塩基にも及ぶ長い断片を読み取れるものの、エラー率が比較的高かった「ロングリードシーケンシング」です。
ロングリード技術は、ゲノムの複雑な繰り返し構造などを解明するのに有利ですが、そのエラー率が課題でした。この課題に対し、Googleは以前にも、複数の読み取りデータからAI(Transformerモデル)を使ってより正確な配列を構築する「DeepConsensus」という技術を開発し、ロングリードシーケンシングの精度向上に貢献してきました。
しかし、個々のDNA分子の読み取り精度が向上しても、それらを繋ぎ合わせたゲノムアセンブリ全体には、まだ修正すべきエラーが残っています。DeepPolisherは、このアセンブリ後のゲノム全体を対象として、さらに高い精度でエラーを修正するために開発されました。
DeepPolisherの仕組み:AIはどのようにエラーを見つけるのか?
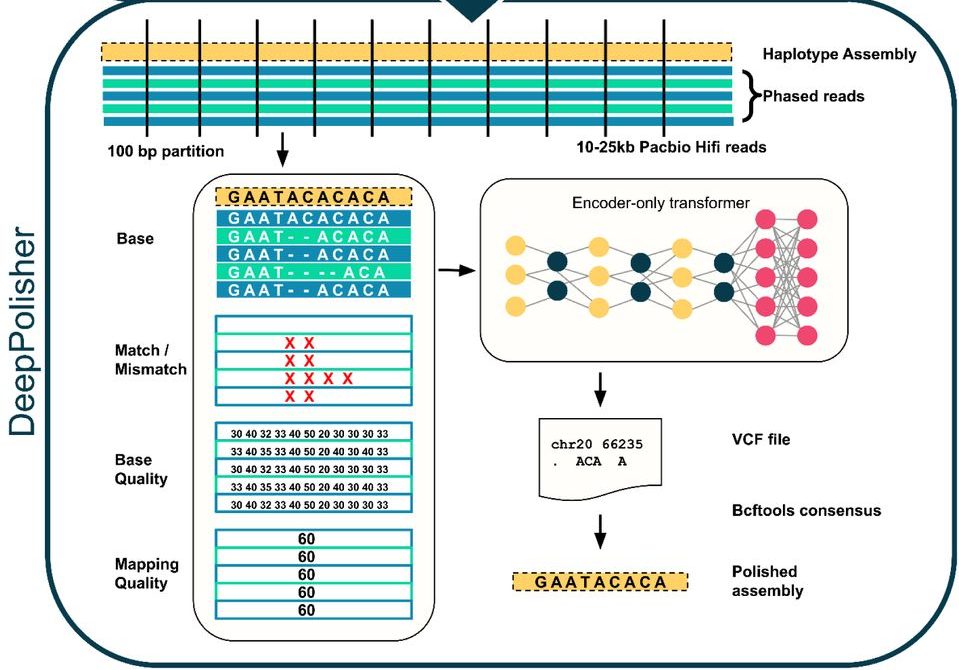
DeepPolisherは、Googleが先行開発したDeepConsensusのアイデアを応用し、ゲノムアセンブリの修正に特化させたツールです。その中核をなすのが「Transformer」という深層学習モデルです。
Transformerは、文章の文脈を理解する能力に長けていることから、主に機械翻訳などの自然言語処理で大きな成果を上げてきました。DeepPolisherは、このモデルをゲノム配列に応用しています。ゲノム配列を一種の「言語」とみなし、エラーのありそうな箇所の周辺配列の「文脈」を読み解くことで、どこがどのように間違っている可能性が高いかを判断します。
具体的には、以下のような情報をモデルに入力します。
- アセンブリされたゲノム配列(修正対象)
- そのアセンブリの元になった多数のシーケンスリード(DNA断片の読み取りデータ)
- 各塩基の品質スコア(シーケンサーが報告する信頼度)
- マッピング品質(各リードがゲノム上の特定の位置にどれだけ確信を持って配置できたか)
これらの多様な情報を元に、Transformerモデルが「この位置の塩基は、本当はCではなくGであるべきだ」「ここにAが一つ挿入されるべきだ」といった修正案を出力します。このプロセスを経て、ゲノムアセンブリはより正確なものへと磨き上げられていきます。
性能向上とその意義
DeepPolisherの効果は非常に大きく、ゲノムアセンブリのエラー数を約半分に削減することが報告されています。
特に重要なのは、挿入・欠失(インデル)エラーを70%以上も削減できる点です。インデルエラーは、塩基が一つ抜け落ちたり、余分に挿入されたりするエラーで、遺伝子の「読み枠」をずらしてしまう(フレームシフト)原因となります。読み枠がずれると、それ以降のアミノ酸配列が全く異なったものになり、遺伝子そのものが機能しない、あるいはプログラム上で認識されなくなってしまうことがあります。この致命的なエラーを大幅に減らせることは、遺伝子機能の正確な解明に直結します。
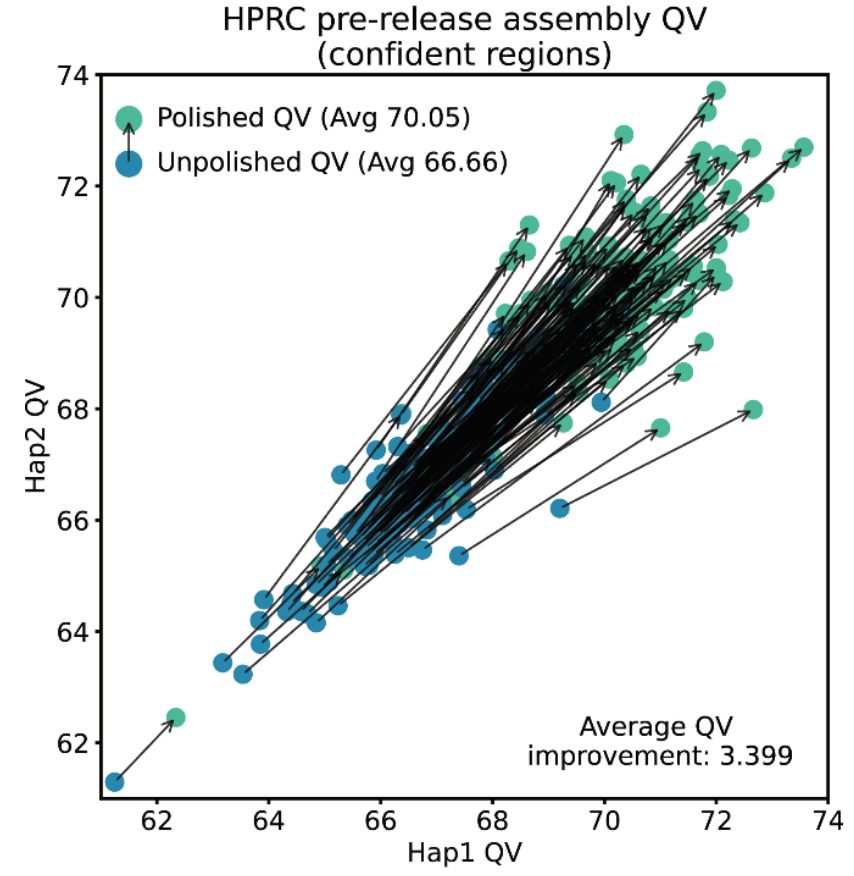
ゲノムの品質は、エラーの確率を対数で示した「Q値」で評価されます。Q値が10上がるごとに、精度は10倍になります。DeepPolisherを適用することで、ヒトパゲノム参照コンソーシアム(HPRC)のサンプルのQ値が平均でQ66.7からQ70.1へと向上しました。これは、エラー率がさらに半分以下になったことを意味し、極めて高品質なゲノムデータが得られたことを示しています。
実用化と今後の展望
DeepPolisherはすでに、多様な人々のゲノム情報を網羅した新しい参照ゲノムを作成するプロジェクト「ヒトパゲノム参照コンソーシアム(HPRC)」で正式に採用されています。このプロジェクトによって作成される高精度なパゲノム(集団のゲノム多様性全体を表す参照情報)は、これまで標準的だった単一の参照ゲノムでは見逃されてきた、多様な人種や民族に特有の遺伝的特徴の理解を深める上で不可欠です。
DeepPolisherはオープンソースとして公開されており、世界中の誰もが利用できます。これにより、ゲノム研究コミュニティ全体が高品質なゲノムデータを容易に得られるようになり、遺伝病の診断精度の向上や、個人のゲノム情報に基づいた創薬(個別化医療)の発展が加速することが期待されます。
使い方
公式GitHubより利用方法を説明します。
動作環境(前提条件)
- Unix系OS(Windowsでは動作不可)
- Python 3.8
DeepPolisher のインストール方法
DeepPolisher は以下の2つの方法でインストールできます。
- Dockerコンテナ を利用する方法
- pip を利用して直接インストールする方法
Docker を使う場合
Dockerイメージを取得して利用します。
sudo docker pull google/deepconsensus:polisher_v0.1.0pip を使う場合
(1) pip のセットアップ
sudo -H apt-get -qq -y update
sudo -H apt-get -y install python3-dev python3-pip
sudo -H apt-get -y update
python3 -m pip install --upgrade pip(2) 仮想環境のセットアップ
sudo apt install python3-venv
python3 -m venv ~/workspace/polisher-venv/
source ~/workspace/polisher-venv/bin/activate
# 仮想環境が有効化されたことを確認します。
echo "$(pip --version)"(3) 必要ライブラリのインストール
pysam のために環境変数を設定し、依存関係をインストールします。
export HTSLIB_CONFIGURE_OPTIONS=--enable-plugins
pip install -r requirements.txt(4) DeepPolisher のインストール
pip install .[cpu]
(5) インストール確認
polisher --version
# 出力例: 0.1.0
which polisher
# 出力例: /path/to/workspace/polisher-venv/bin/polisherまとめ
本稿では、Googleが開発した深層学習ツール「DeepPolisher」についてご紹介しました。このツールは、ゲノムアセンブリというゲノム研究の根幹をなすプロセスにおいて、これまで課題であったエラー、特に遺伝子発見を困難にするインデルエラーを大幅に削減します。Transformerという先進的なAI技術をゲノム解析に応用することで、生命の設計図をかつてないレベルの正確さで描き出すことを可能にしました。
DeepPolisherによってもたらされる高精度なゲノム情報は、今後の遺伝病研究、がん研究、そして創薬開発など、あらゆる生命科学分野における研究の土台をより強固なものにしていくでしょう。








