はじめに
AI技術は日々進化していますが、特にLLMの分野では目覚ましい進歩が見られます。そんな中、Deep Cogito社から、既存のオープンソースモデルの性能を凌駕する可能性を秘めた「Cogito v1 Preview」がリリースされました。
本稿では、Deep Cogito社が発表した新しい大規模言語モデル(LLM)「Cogito v1 Preview」について、公開記事である「Cogito v1 Preview: Introducing IDA as a path to general superintelligence」からその驚くべき性能と、それを支える革新的な技術「Iterated Distillation and Amplification (IDA)」について解説します。
引用元情報
- 記事タイトル: Cogito v1 Preview: Introducing IDA as a path to general superintelligence
- 参照元URL: https://www.deepcogito.com/research/cogito-v1-preview
- 発行日: 2025年4月8日
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
※実際の利用方法が知りたい方は以下をご参照ください。
要点
- オープンソース最高性能: Deep Cogito社がリリースした、3B, 8B, 14B, 32B, 70Bのパラメータサイズを持つオープンソースのLLM群です。それぞれのサイズで、既存の主要なオープンソースモデル(LLaMA, DeepSeek, Qwenなど)を多くの標準的な評価(ベンチマーク)で上回る性能を示しています。特に70Bモデルは、より大規模な混合エキスパートモデル(MoE)であるLlama 4 109Bよりも高性能です。
- 新技術IDAを採用: トレーニングにはIterated Distillation and Amplification (IDA) という新しい手法が用いられています。これは、AI自身が反復的に学習・改善を繰り返すことで、人間(教師)の能力に縛られずに知能を高めていくことを目指す、スケーラブルで効率的なアプローチです。
- 2つの動作モード: 通常のLLMのように直接回答するモードに加え、回答前に自己反省(推論)を行うモードも搭載しています。
- 今後の展開: 今後数週間から数ヶ月以内に、さらに大規模なモデル(109B, 400B, 671B)や、各サイズの改良版がリリースされる予定です。
- 利用方法: モデルはHugging FaceやOllamaからダウンロード可能で、Fireworks AIやTogether AIのAPIを通じても利用できます。
詳細解説
1. Cogito v1 Preview の驚異的な性能
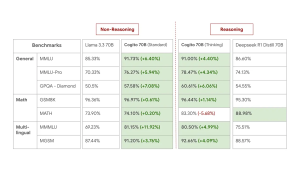
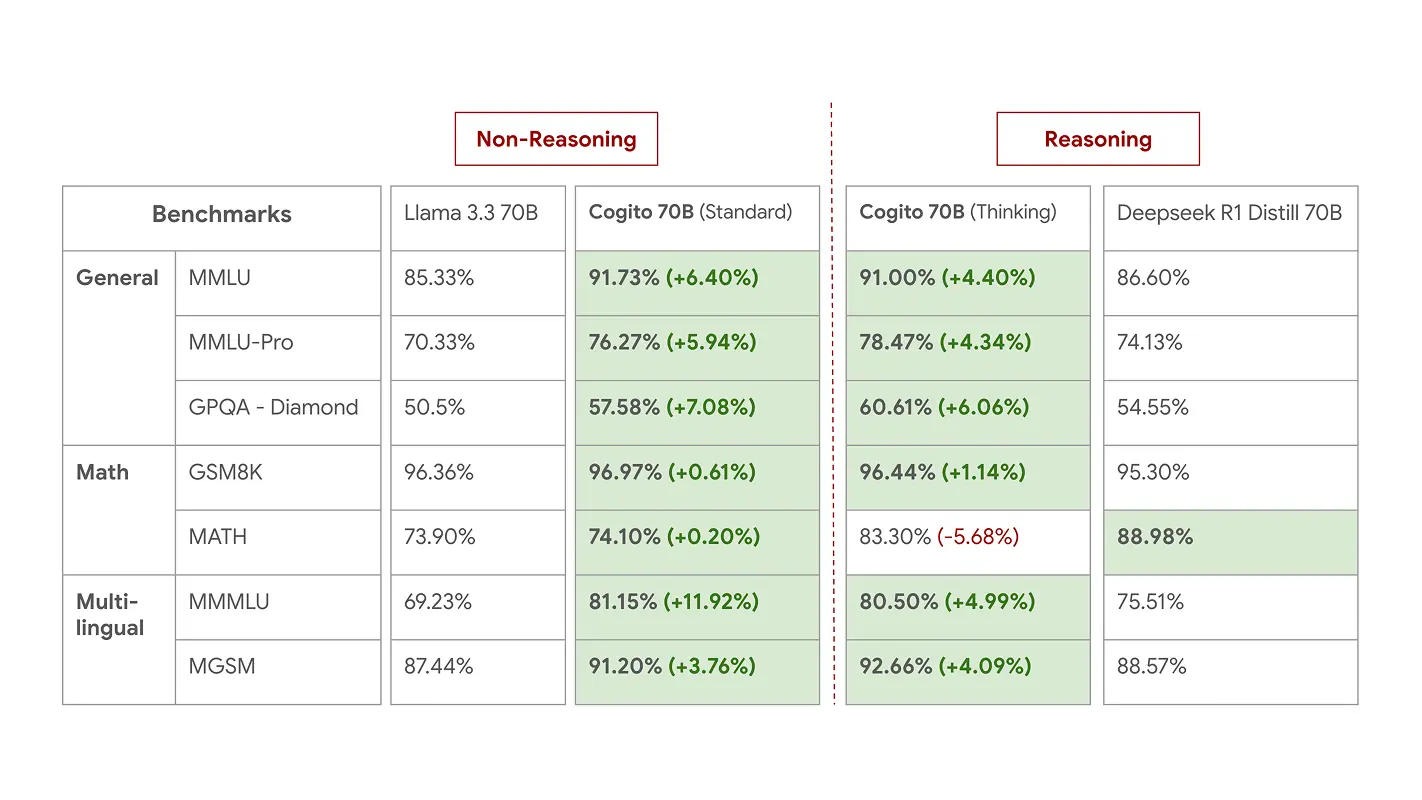
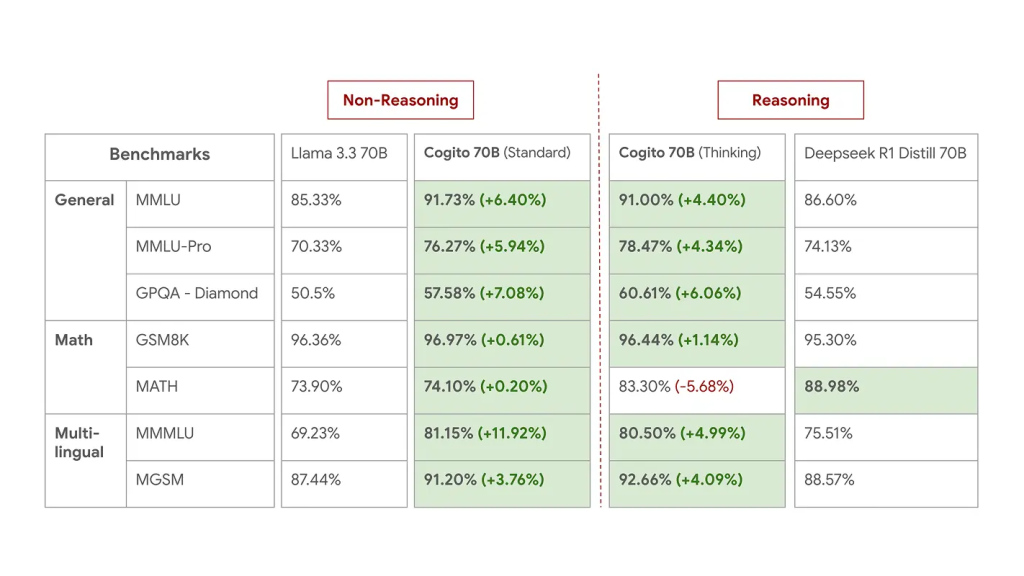
まず、Cogito v1 Previewがどれほど凄いのかを見てみましょう。「パラメータサイズ」とは、モデルの規模や複雑さを示す指標のようなもので、一般に大きいほど高性能になる傾向があります。Cogito v1 Previewは、3B(30億)から70B(700億)までの複数のサイズでリリースされましたが、注目すべきはその性能です。
ブログ記事によると、各サイズのCogito v1 Previewは、同じサイズの既存の有名なオープンソースモデル、例えばMeta社のLLaMAや、DeepSeek、Qwenといったモデルよりも、多くのベンチマークで優れたスコアを記録しています。ベンチマークとは、AIの能力を測るための標準化されたテストのようなものです。例えば、一般的な知識を問う「MMLU」や、数学の問題を解く「GSM8K」などがあります。
特に驚くべきは、Cogito 70Bモデルが、より大きなパラメータを持つLlama 4 109B MoEモデルをも上回った点です。MoE(Mixture of Experts)は、複数の専門家(小さなモデル)を組み合わせて効率的に性能を高める比較的新しい技術ですが、それを用いた最新モデルを超える性能を、より小さなモデルで達成したことは、Cogito v1 Previewの効率の良さを示唆しています。
Smaller Models – 3B and 8B
Performance of 3B models

Performance of 8B models

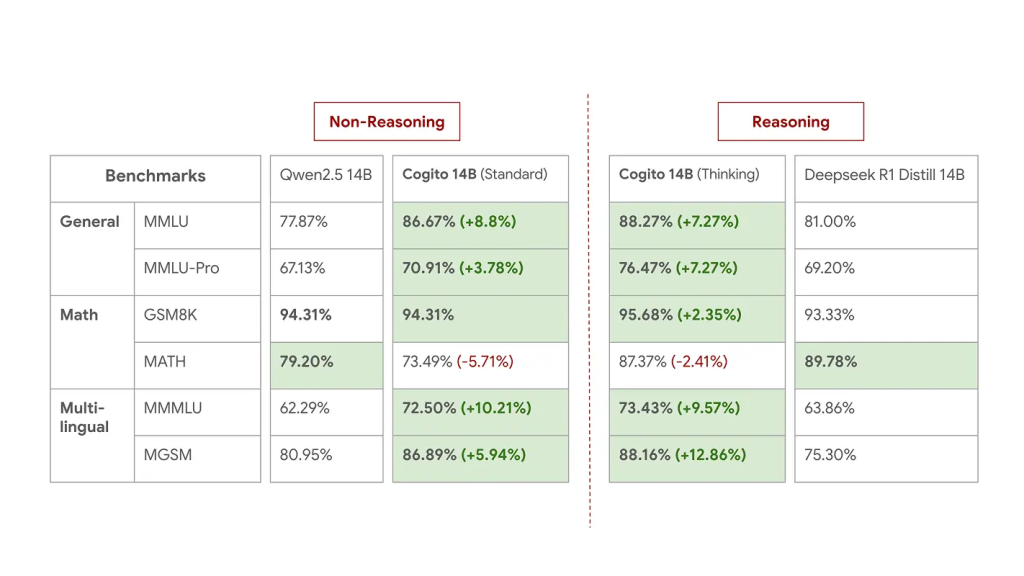
Medium Models – 14B and 32B
Performance of 14B models
Performance of 32B models

Larger Models – 70B
Performance of 70B models
Livebench Scores

2. 鍵となる新技術:Iterated Distillation and Amplification (IDA)
Cogito v1 Previewの高性能を支えるのが、Iterated Distillation and Amplification (IDA) という独自のトレーニング手法です。これは、AIが自己改善を繰り返すことで、人間が教えられる範囲を超えた知能、いわゆる超知能(Superintelligence) を目指すためのアプローチです。
なぜIDAが必要なのか?
従来のLLMの多くは、人間が作成したデータで学習したり、より大きな高性能モデルから知識を「蒸留(Distillation)」して作られます。「蒸留」とは、教師役の大きなモデルの賢さを、生徒役の小さなモデルに効率よく移転するようなイメージです。しかし、これらの方法では、元となる人間や教師モデルの能力が、最終的なAIの知能の上限になってしまうという課題がありました。超知能を目指すには、この「教師の限界」を超える仕組みが必要です。IDAは、そのための有力な候補として提案されています。
IDAの仕組み:増幅と蒸留の反復
IDAは、大きく分けて2つのステップを繰り返します。
- Step 1: 増幅 (Amplification)
モデルが通常よりも多くの計算資源(時間やコンピュータパワー)を使って、より良い答えや思考プロセスを導き出すステップです。例えば、一つの質問に対して複数の回答案を生成し、それらを比較検討して最良のものを選択する、といった具合です。これにより、モデル単体の能力よりも一時的に高い知能(Higher Intelligence)を生み出します。 - Step 2: 蒸留 (Distillation)
増幅ステップで得られた「より賢い思考プロセス」や「より良い答え」を、モデル自身のパラメータ(知識や能力の源泉)に学習させるステップです。これにより、一時的だった高い知能がモデルに内部化され、恒久的な能力向上につながります。
この「増幅→蒸留」のサイクルを繰り返す(Iterated)ことで、モデルは段階的に自己改善していきます。重要なのは、改善が進むにつれて、増幅ステップで生み出される思考プロセス自体もより強力になり、さらなる高みを目指せるようになる点です。これにより、理論上は、元の教師(人間や初期モデル)の能力に縛られずに、投入する計算資源とIDAプロセスの効率次第で知能を向上させ続けられる可能性があります。
Deep Cogito社によれば、IDAは、LLMの性能調整によく使われるRLHF(人間のフィードバックに基づく強化学習) や、単純な大規模モデルからの蒸留といった他のアプローチよりも、時間的にも効率が良く、スケールしやすい(大規模化しやすい) とのことです。実際、Cogitoモデル群は比較的小規模なチームによって約75日間で開発されたと述べられています。
3. Cogito v1 Preview の特徴と用途
Cogito v1 Previewモデルは、特にコーディング(プログラミング)、関数呼び出し(他のツールやAPIと連携する能力)、エージェント的なユースケース(自律的にタスクを計画・実行するような使い方) に最適化されているとのことです。
また、前述の通り、Cogito v1 Previewは2つのモードで動作します。
- 標準モード: 通常のLLMのように、質問に対して直接回答します。
- 推論モード (Thinking Mode): 回答する前に、モデル自身が内部で思考プロセス(自己反省)を実行します。これにより、より複雑な問題に対して、より正確で質の高い回答が期待できます。記事中のベンチマーク結果を見ると、推論モードの方が多くのタスクで高いスコアを出しています。
まとめ
Deep Cogito社が発表したCogito v1 Previewは、既存のオープンソースLLMの性能を塗り替える可能性を持つ、非常に注目すべきモデル群です。その成功の鍵は、Iterated Distillation and Amplification (IDA) という、AIの自己改善を促し、教師の限界を超える可能性を秘めた新しいトレーニング手法にあります。
IDAは、計算資源を使って一時的に高い知能を生み出し(増幅)、それをモデル自身に学習させる(蒸留)というサイクルを繰り返すことで、効率的かつスケーラブルにAIの能力を向上させることを目指します。これは、汎用的な超知能への道筋を示すものかもしれません。
Cogito v1 Previewはまだ初期段階であり、今後さらに改良されたモデルや、より大規模なモデルの登場が予定されています。全てのモデルがオープンソースとして公開される点も、AIコミュニティ全体の発展にとって非常に重要です。
本稿で紹介したCogito v1 PreviewとIDAは、LLMの進化における新たなマイルストーンとなる可能性があります。今後のDeep Cogito社の動向、そしてIDAのような自己改善技術がAIの未来をどう変えていくのか、引き続き注目していく必要があるでしょう。