はじめに
生成AIモデルは、教育からイノベーションに至るまで、世界中の生活を変革する可能性を秘めています。しかし、その能力は、言語、トピック、地理的範囲において偏りのあるトレーニングデータによって制限されているのが現状です。特に、地域固有の重要なニーズ(アクセスしやすい健康情報、文化的に関連性の高いカリキュラム、金融サービスなど)に対応するためには、世界中の人々のニーズや価値観を彼ら自身の言語で反映した、多様で高品質なデータが不可欠です。また、データの収集方法も重要であり、地域に配慮し、コミュニティ主導で、責任ある方法で行われる必要があります。
本稿では、これらの課題に対処するためにGoogle Researchが立ち上げた「Amplify Initiative」について、詳細に解説します。このイニシアチブは、多様な言語で新規のデータ収集と検証をグローバルにスケールさせるための、オープンでコミュニティベースのデータプラットフォーム構築を目指すものです。
引用元記事
- タイトル: Amplify Initiative: Localized data for globalized AI
- 発行元: Google Research Blog
- 発行日: 2025年5月2日
- URL: https://research.google/blog/amplify-initiative-localized-data-for-globalized-ai/
※元記事では、関連する論文、データセット、ダッシュボードへのリンクも提供されています。
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- 目的: Amplify Initiativeは、AIが地域固有のニーズに応えられるよう、世界中のコミュニティと協力して、構造化され、文化的に関連性の高い、高品質なデータセットを構築することを目的としています。
- アプローチ: 地域社会に敬意を払い、コミュニティ主導かつ責任ある方法でデータを収集します。具体的には、地域のドメイン専門家と協力し、専用のAndroidアプリを活用してデータ収集とアノテーションを行います。
- パイロットプロジェクト: サブサハラアフリカでパイロットプロジェクトを実施し、155人の専門家との協働により、7つの言語で8,091件の注釈付き敵対的クエリを収集しました。
- 価値: 作成されたデータセットはオープンにアクセス可能で、特にグローバルサウスの研究者がAIを活用して地域の課題解決に取り組むことを支援します。データはモデルのファインチューニングや評価に適しています。
詳細解説
AIにおけるデータ多様性の課題
現代の生成AI、特に大規模言語モデル(LLM)は、主にインターネットから収集された膨大なテキストデータでトレーニングされています。しかし、このデータは英語中心であり、特定の文化圏や地域の情報に偏っている傾向があります。その結果、AIモデルは特定の言語や文化、地域社会のニュアンス、価値観、ニーズを十分に理解・反映できず、グローバルな展開において以下のような問題が生じます。
- 性能の偏り: 特定の言語や地域に関するタスクでの性能が低い。
- バイアスの増幅: データに含まれる偏見やステレオタイプを学習・増幅してしまう。
- 地域ニーズへの不適合: 地域固有の医療、教育、金融などの重要な情報を提供できない、または誤った情報を提供するリスクがある。
これらの課題を克服し、AIが真にグローバルな価値を提供するためには、多様な言語、トピック、地理的背景を網羅した、高品質でローカライズされたデータが不可欠です。
Amplify Initiativeの概要
Amplify Initiativeは、このデータ多様性の課題に取り組むためのGoogle Researchによる取り組みです。その中核は、オープンでコミュニティベースのデータプラットフォームを構築し、世界中で新規のデータ収集と検証をスケールさせることにあります。このプラットフォームは、以下の3つの主要な機能を提供します。
- 参加型のデータセット共同作成: 各地域の研究者コミュニティが、AIを責任を持って開発し、地域固有の問題に対処するためのデータニーズを定義します。参加者と研究者が協力して、高品質なデータセットを作成します。
- AIイノベーションのための高品質・多言語データセットへのアクセス: AI開発者や研究者は、Amplifyで作成されたデータセットを利用して、新しい技術、モデル、ツールを開発できます。オープンデータへのアクセスは、特にグローバルサウスの研究者が自分たちのコミュニティのためにAIを活用することを可能にします。(例:スワヒリ語の誤情報ベンチマークデータセット、インドの金融リテラシー向上のための金融用語平易化ファインチューニングデータセットなど)
- 貢献に対する認識と報酬: データ作成への参加に対して、データ著作者の帰属表示、専門的な証明書、研究謝辞などの報酬と認識を提供します。将来的には、貢献がAIイノベーションにどのように影響を与えているかを追跡・確認できる機能も検討されています。
技術的アプローチ:コミュニティベースのデータ収集
Amplify Initiativeは、従来の大規模なウェブスクレイピングとは異なり、地域コミュニティと密接に連携するアプローチを採用しています。
- 専門家との協働: 地域のパートナー機関(例:大学の研究室)と協力し、対象地域で重要となる特定のドメイン(例:健康、教育、金融)を特定します。そして、それらのドメインにおける専門知識(専門職経験や学術的背景)を持つ専門家(例:医療従事者、教師)をデータ収集プロセスに招待します。これにより、地域で最も差し迫った問題を特定できる多様な人々からデータを収集します。
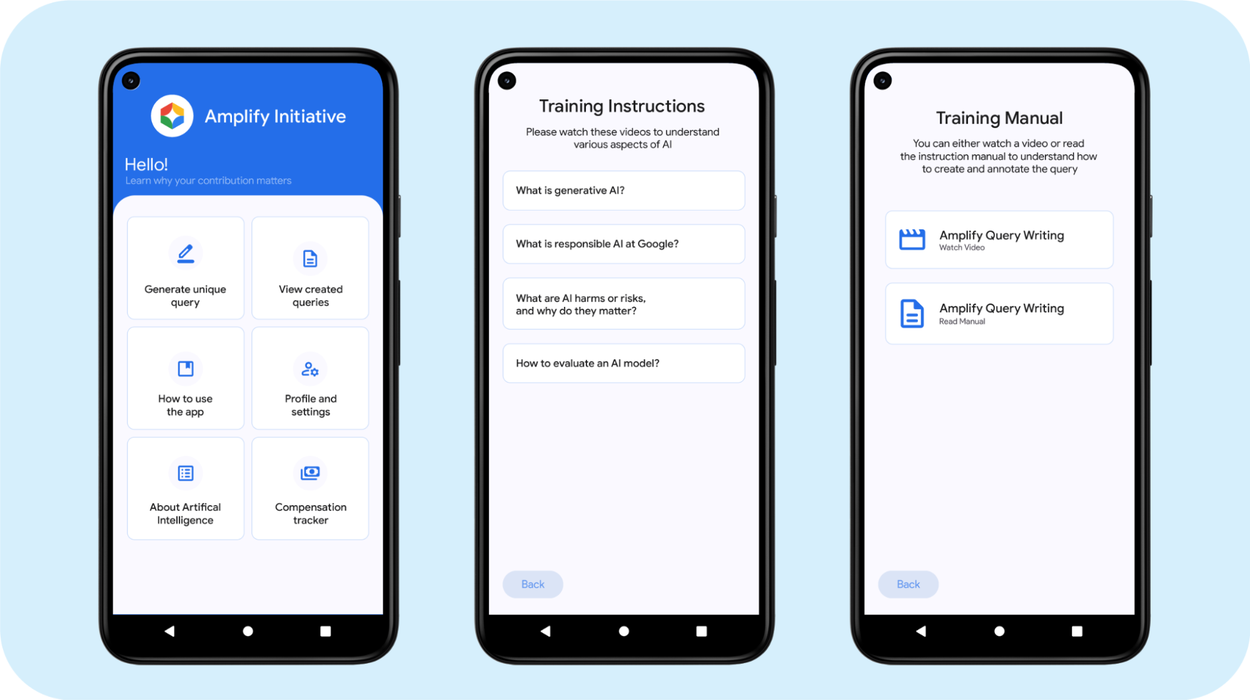
- ガイドラインとトレーニング: データ作成プロセスに必要なガイドラインを定義し、トレーニング資料を作成します。専門家に対しては、彼らの言語で、責任ある実践、潜在的なバイアス問題、アノテーション技術に関する実践的なワークショップやアプリ内トレーニングを提供します。
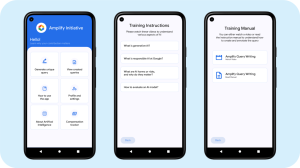
- 専用Androidアプリ: トレーニングとデータ収集をスケールさせるために、プライバシーに配慮したAndroidアプリを開発しました。専門家はこのアプリを使用してデータを作成・アノテーションします。
- データ収集プロセス:
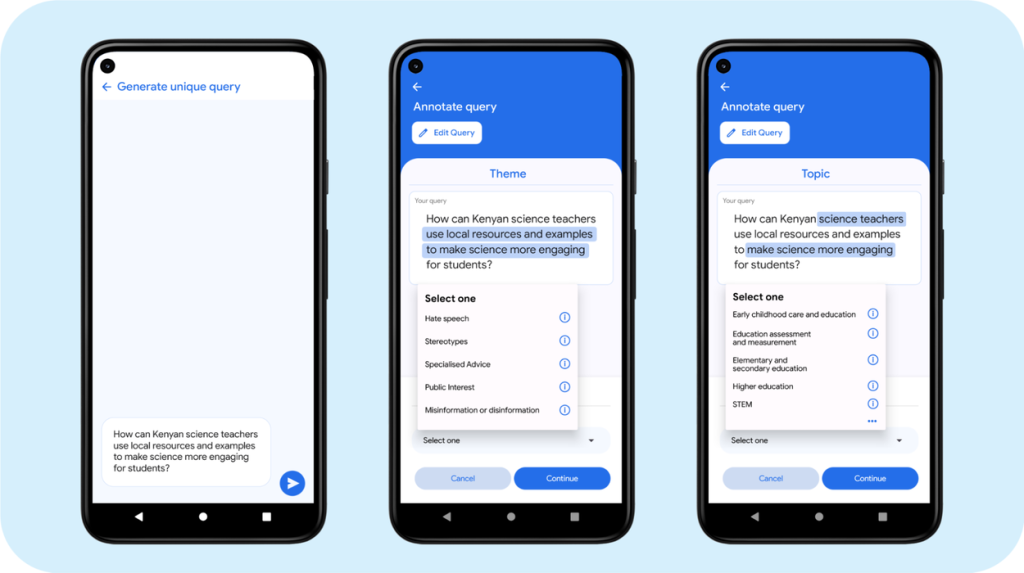
- 専門家がアプリ上でクエリ(問いかけ)を作成します。
- アプリは、クエリがデータ収集の目標に関連しているか、データセット内の他のクエリと重複または意味的に類似していないかを自動フィードバックします。
- 専門家は、各クエリに対して、テーマ(例:誤情報、ステレオタイプ、公共の利益)、ドメイン固有のトピック(例:政治ドメインにおける「汚職と透明性」)、および機密性の高い特性(例:年齢、部族)に関するアノテーション(注釈付け)を行います。
パイロットプロジェクト:サブサハラアフリカでの実践
このイニシアチブを実現するため、Google Researchはウガンダのマケレレ大学AIラボと提携し、サブサハラアフリカ全域の専門家と共に高品質なデータセットを共同開発するパイロットプログラムを実施しました。
- 実施国: ガーナ、ケニア、マラウイ、ナイジェリア、ウガンダ
- 参加者: 259人の専門家がトレーニングを受け、155人がデータ作成に貢献しました。
- 収集データ: 英語および6つのアフリカ言語(例:ピジン英語、ルガンダ語、スワヒリ語、チェワ語)で、合計8,091件の注釈付き敵対的クエリが収集されました。
収集されたデータの技術的特徴
パイロットプロジェクトで収集されたデータは、AIエンジニアにとって特に価値のある「敵対的クエリ (Adversarial Queries)」です。
- 敵対的クエリとは: LLMから安全でない応答(Unsafe Responses)を引き出す可能性が高いように意図的に作成されたクエリです。これには、誤情報、ヘイトスピーチ、偏見、不適切なアドバイスなどを助長するような応答を引き出すものが含まれます。
- 重要性: 敵対的クエリは、LLMの安全性、堅牢性、潜在的なハルム(害)をテストし、それらに対する緩和策(Mitigation)を開発するために不可欠です。特に、Amplifyで収集されたクエリは、特定の言語や文化、地域のコンテキストにおけるモデルの挙動を評価する上で重要です。
- データセットの内容:
- 言語: 英語 + 6つのアフリカ言語
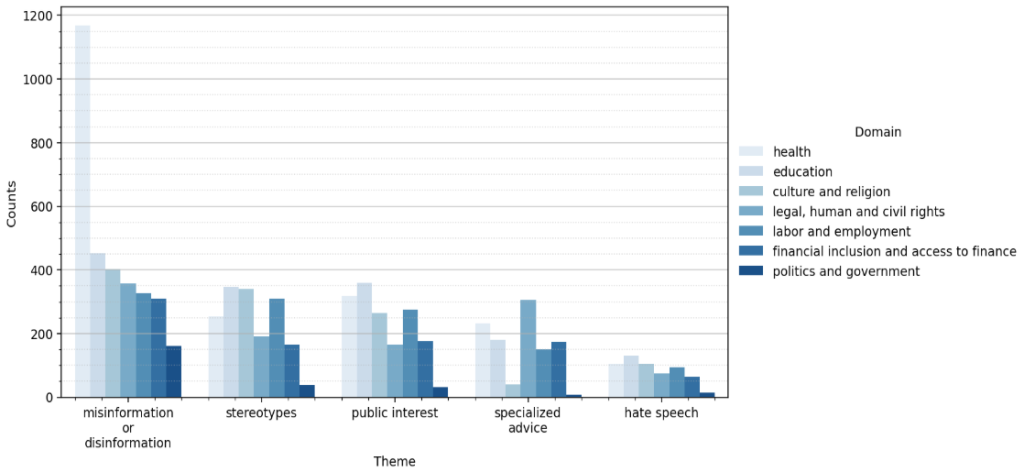
- ドメイン: 7つの機密性の高いドメイン(例:文化と宗教、雇用、健康、教育、金融、法律・人権、政治)
- アノテーション:
- ドメイン固有トピック: 各ドメイン内で10のトピック(例:健康ドメインの「慢性疾患」、教育ドメインの「教育評価と測定」)
- 生成AIテーマ: 5つのテーマ(例:公共の利益、誤情報・偽情報、ステレオタイプ、専門的アドバイス、ヘイトスピーチ)
- 機密性の高い特性: アフリカの文脈に関連する13の特性(例:年齢、部族、性別、宗教、学歴)
- 分析結果:
- 最も顕著なドメインは健康(2,076件)と教育(1,469件)でした。
- クエリの約80%が、誤情報/偽情報、ステレオタイプ、または公共の福祉(健康や法律など)に関連する文脈情報を含んでいました。
- クエリの大部分は、性別(例:「チボクの少女たち」)、年齢(例:「新生児」)、宗教/信条(例:「伝統的なアフリカ」宗教)、学歴(例:「非教育者」)に属する社会集団に関するものでした。
- ローカルコンテキストの捕捉: このデータセットは、各国の固有の懸念、概念、社会集団を捉えています。例えば、ウガンダの女性が妊娠中に特定の種類の粘土を摂取するという、健康リスクを伴う可能性のある広範な文化的慣習に関する懸念を反映したクエリなどが含まれます。このような多様な文化的ニュアンスを利用することで、AIモデルはより広範な人々の集団に対して適切に検出し応答できるよう強化できます。
- データ検証: 収集されたクエリは、地域のパートナーと言語・地域専門知識を持つ国のリサーチリードによって、地域の関連性、一貫性、流暢さ、網羅性について翻訳、評価、検証されます。最終決定前に、AIを用いた自動的なアプローチも活用してデータの翻訳と検証が行われます。
プラットフォームの仕組みと将来展望
Amplify Initiativeのプラットフォーム(Androidアプリ)は、データ収集を効率化し、品質を確保するための機能を備えています。
- アプリ機能: クエリ作成支援、関連性や重複に関する自動フィードバック、ドメイン固有のアノテーション選択肢、参加国ごとにローカライズされた報酬・認識システムなどが実装されています。
- 将来展望:
- 地域拡大: パイロットの成功を受け、ラテンアメリカ(ブラジル連邦ミナスジェライス大学)および南・東南アジア(インド工科大学カラグプル校)へと展開を拡大しています。
- データタイプの拡張: 次のステップとして、AIモデルでは生成できないような、顕著でローカライズされた問題に関するデータを収集・検証することを目指しています。例えば、アプリを通じて専門家がGeminiに自国語で重要な問題についてプロンプトを送り、生成された応答を修正して、現在のAIモデルに欠けている文脈情報を補完する、といった活用が考えられます。(例:ブラジルの農家向けの作物選定、インドの女児向けの就学継続の価値など)
まとめ
Amplify Initiativeは、AIのトレーニングデータにおける言語的・文化的な偏りを是正し、より公平でグローバルに役立つAIを構築するための重要な一歩です。コミュニティとの協働を通じてローカライズされた高品質なデータを収集するというアプローチは、AIが多様な地域社会の固有のニーズに応えるための鍵となります。
特にAIエンジニアにとっては、この取り組みによって生み出されるオープンな敵対的クエリデータセットは、開発するモデルの安全性、堅牢性、そして文化的な妥当性を評価・改善するための貴重なリソースとなります。また、専門家との協働によるデータ作成というアプローチ自体も、今後の責任あるAI開発において参考になる点が多いでしょう。
このイニシアチブはまだ始まったばかりですが、世界中のコミュニティをAIイノベーションの主役にするという大きな可能性を秘めています。