
はじめに
本稿では、Google DeepMindやGoogle Researchの研究チームが2025年12月11日に発表した、大規模言語モデル(LLM)の「事実性(Factuality)」を多角的に評価する新しいベンチマークスイート「FACTS Leaderboard」に関する論文について解説します。
LLMのハルシネーション(もっともらしい嘘)は、実用化における最大の障壁の一つです。しかし、これまでの評価指標は、「知識の暗記量」や「検索ツールの使用」など、特定の能力に偏っていることが課題でした。本稿で紹介する「FACTS」は、画像認識、内部知識、Web検索、RAG(検索拡張生成)のような長文コンテキストへのグラウンディングという、実務で求められる4つの異なる能力を統合して評価する取り組みです。 GPT-5やGemini 3 Proといった最新モデルのスコア比較や、評価の仕組みについて解説していきます。
解説論文
- 論文タイトル: The FACTS Leaderboard: A Comprehensive Benchmark for Large Language Model Factuality
- 論文URL: https://storage.googleapis.com/deepmind-media/FACTS/FACTS_benchmark_suite_paper.pdf
- 発行日: 2025年12月11日
- 発表者: Aileen Cheng, Alon Jacovi, Amir Globerson, et al. (Google DeepMind, Google Research, Google Cloud, Kaggle)
要点
- 包括的な評価スイート:LLMの事実性を単一の指標ではなく、「マルチモーダル」「パラメトリック知識(内部知識)」「検索ツール利用」「グラウンディング(長文読解)」の4つの観点から総合的に評価するベンチマーク「FACTS」を構築した。
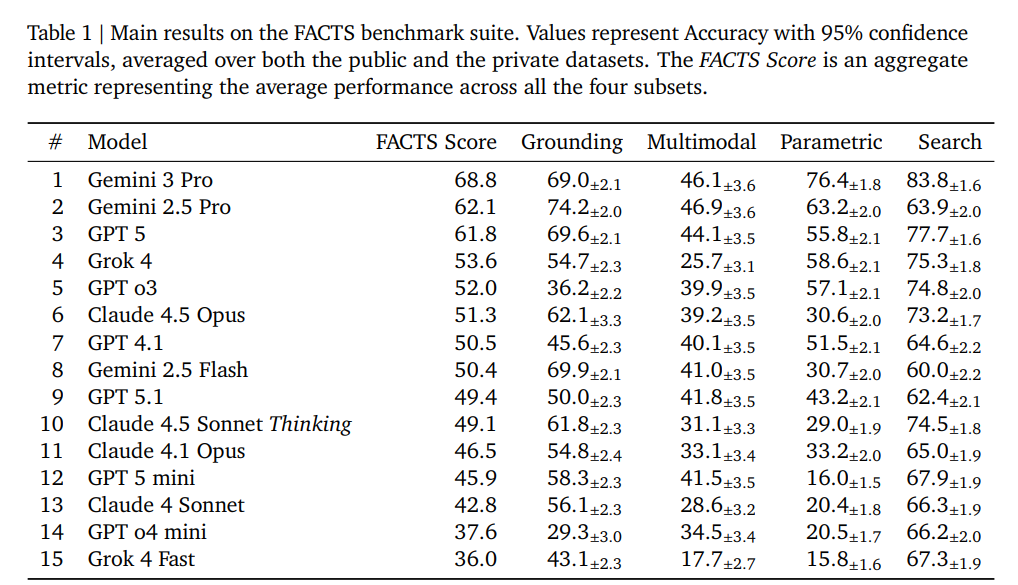
- 最新モデルの性能比較:Gemini 3 Proが総合スコア68.8%で首位となり、次いでGemini 2.5 Pro、GPT-5と続く結果が示された。しかし、最高スコアでも約69%であり、改善の余地が大きいことが明らかになった。
- 厳格な評価手法:評価の信頼性を担保するため、公開データセット(Public)と非公開データセット(Private)を分割し、モデルの過学習を防ぐ仕組みを採用している。また、採点には人間による評価と相関の高い「LLM-as-a-Judge(審査員モデル)」を活用している。
詳細解説
以下、論文の構成に従い、各セクションの詳細を解説します。
1. Introduction(はじめに)
LLMは劇的な進化を遂げているものの、依然として事実と異なる情報を生成する問題(ハルシネーション)を抱えています。事実性の研究は大きく分けて、「与えられたコンテキストに基づく事実性(例:RAG)」と、「一般的な世界知識に基づく事実性(例:Web検索や内部知識)」の2つに分類されます。
実用的なユースケース(例:財務レポートの分析など)では、これら両方の能力が求められます。しかし、既存のベンチマークは特定の能力に焦点を当てたものが多く、モデルの総合的な「信頼性」を測るには不十分でした。そこで本稿の著者らは、4つの異なるサブリーダーボードを集約した包括的な評価スイート「FACTS Leaderboard」を提案しています。
FACTSは以下の4つの柱で構成されており、これらの平均スコアを「FACTS Score」として算出します。
- FACTS Multimodal:画像と世界知識を組み合わせた回答能力。
- FACTS Parametric:外部ツールを使わず、モデルの内部知識だけで回答する能力。
- FACTS Search:検索ツール(Search API)を使って正確な情報を回答する能力。
- FACTS Grounding v2:与えられた長文ドキュメントに基づいて回答する能力。
2. The FACTS Leaderboard(FACTSリーダーボード)
評価の公平性を保つため、プロンプトの一部は非公開(Private)とされ、Kaggle上で評価が実施されます。また、Gemini 3 Proなどの最新モデルでの評価結果(Table 1)が示されており、各モデルが得意とする領域と苦手とする領域が可視化されています。
3. FACTS Multimodal(FACTSマルチモーダル)
このベンチマークは、画像に対する質問への回答精度を測定します。単に画像に写っているものを答えるだけでなく、視覚情報と世界知識を統合する必要があります(例:電車の画像を見て、その型番と製造年を答える)。
3.1. Data(データ)
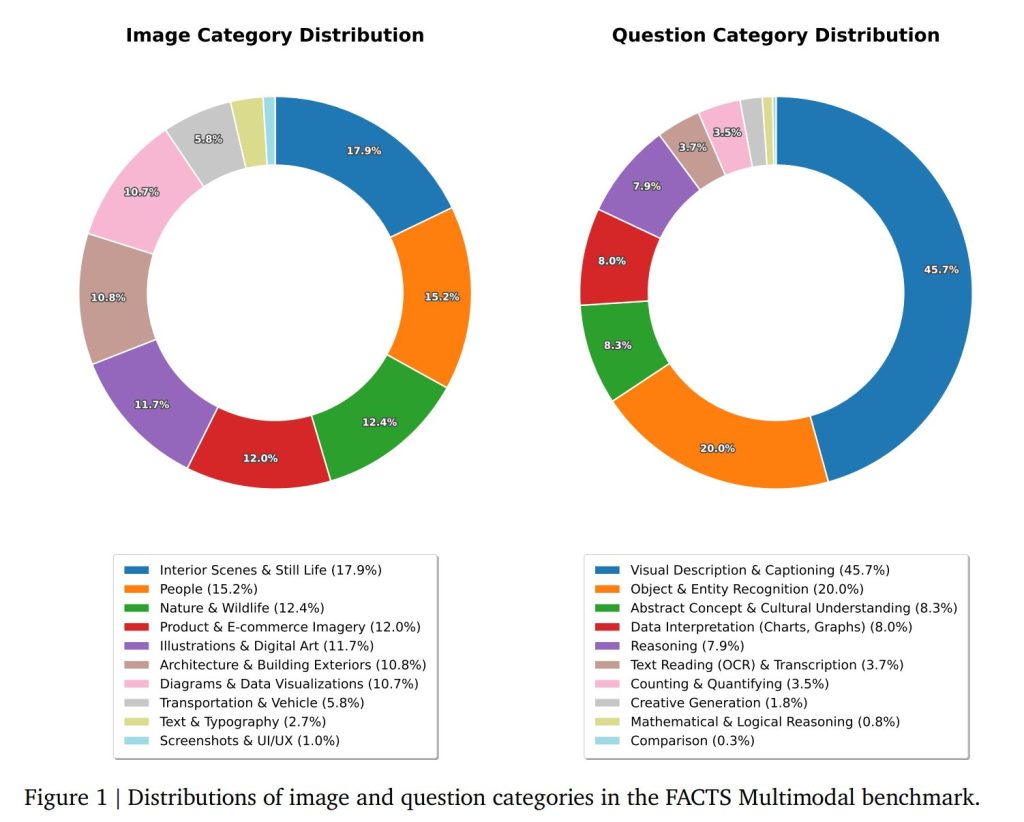
評価用データセットには約1,500問が含まれており、711項目の公開セットと811項目の非公開セットに分割・フィルタリングされています。質問は、多様な実世界のユーザークエリを反映するよう様々なソースから収集され、客観的な情報検索タスクに焦点を当てるようフィルタリングされました。
このベンチマークは以下のような幅広い能力をカバーしています:
- 詳細な視覚的記述
- チャートやグラフからのデータ解釈
- 物体認識
- 視覚シーンに関する論理的推論
Figure 1には、公開セット内の画像と質問のカテゴリー分布が示されています。
3.2. Metrics(評価指標)
評価には「ルーブリック(採点基準)」ベースのアプローチを採用しています。各質問に対し、人間が「必須の事実(Essential Facts)」と「非必須の事実」を定義し、自動評価モデル(Autorater)が以下の2点を判定します。
- Coverage score(網羅性):必須の事実が含まれているか。
- No-Contradiction score(非矛盾性):画像や事実と矛盾する内容が含まれていないか。
Table 2は、この二重評価プロセスを示しており、自動評価システムが判定を正当化するために提供する詳細な推論と、検出可能なエラーのニュアンスを示しています。

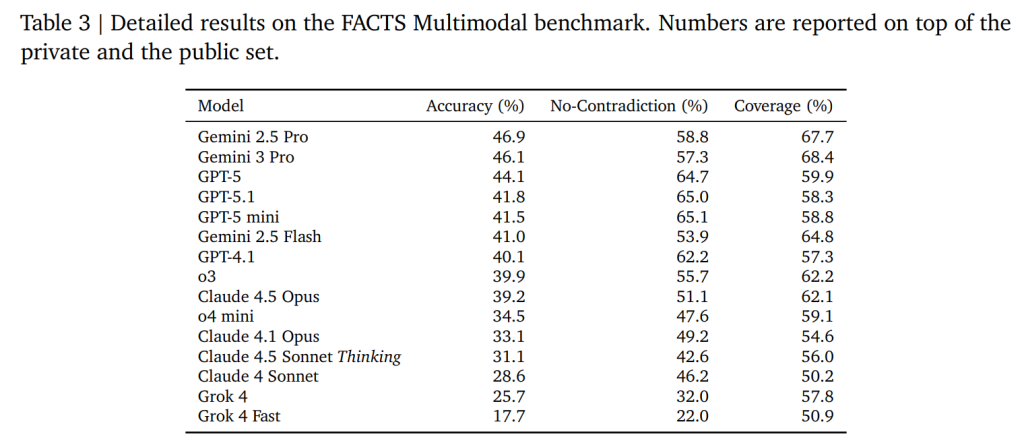
Table 3は、FACTS Multimodal ベンチマークの主要結果を示しています。これらを組み合わせた正解率(Accuracy)が最終スコアとなります。結果として、Geminiモデル群は網羅性が高く(Recall重視)、GPTモデル群は矛盾が少ない(Precision重視)傾向が見られました。
3.3. Autorater Validation(自動評価システムの検証)
自動評価システムの信頼性は、人間による正解アノテーションとの照合によって確立されました。
Coverage(網羅性)の検証
人間によるアノテーションタスクは、自動評価システムの機能を正確に反映するよう設計されました。モデルの回答が与えられると、人間評価者はルーブリック(評価基準)から各必須事実を「サポートされている」または「サポートされていない」としてマークしました。自動評価システムも同じ目的でタスクを実行しました。
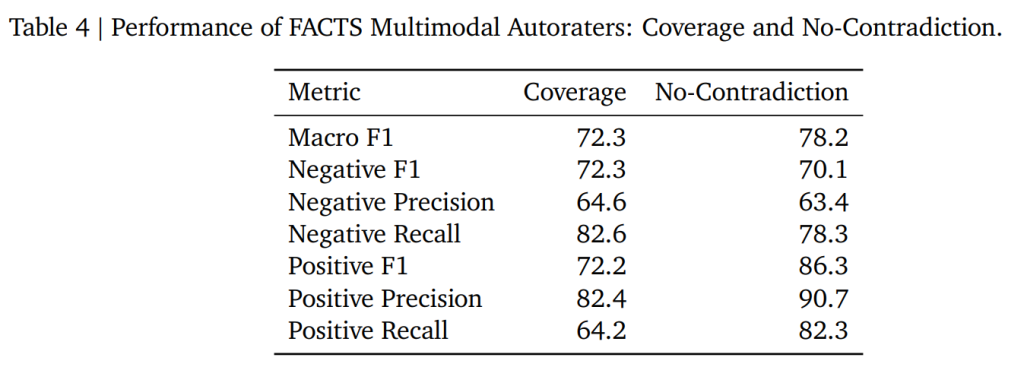
これにより「サポートされた必須事実の割合」という最終指標を直接比較することが可能となり、自動評価システムは人間の判断との間でSpearman順位相関係数0.64という高い信頼性を達成しました。さらに、しきい値0.5を適用してブール値の結果に変換することで、ほとんどの事実がカバーされていることを確認し、マクロF1スコア72.3を獲得しました。
No-Contradiction(矛盾なし)の検証
矛盾なしの検証では、自動評価システムを詳細な人間アノテーションと照合しました。このプロセスでは、モデル回答全体の包括的なレビューが必要でした。Figure 2に示されているように、アノテーターはテキストを一文ずつ評価し、インターフェースを使用して各文に矛盾が含まれているかどうかをマークしました。この検証ではマクロF1スコア78.2を達成しました。

Table 4はこれらの結果を詳述しており、陽性クラスは矛盾の不在を示しています。
4. FACTS Parametric(FACTSパラメトリック)
外部ツール(検索など)を一切使用せず、モデルが学習済みのパラメータ(記憶)のみを使って事実に基づいた回答ができるかを評価します。
4.1. Data(データ)
Wikipediaに答えが存在する、ユーザーの関心が高いトピック(政治、スポーツ、技術など)から2,104の質問と回答のペアを作成しています。
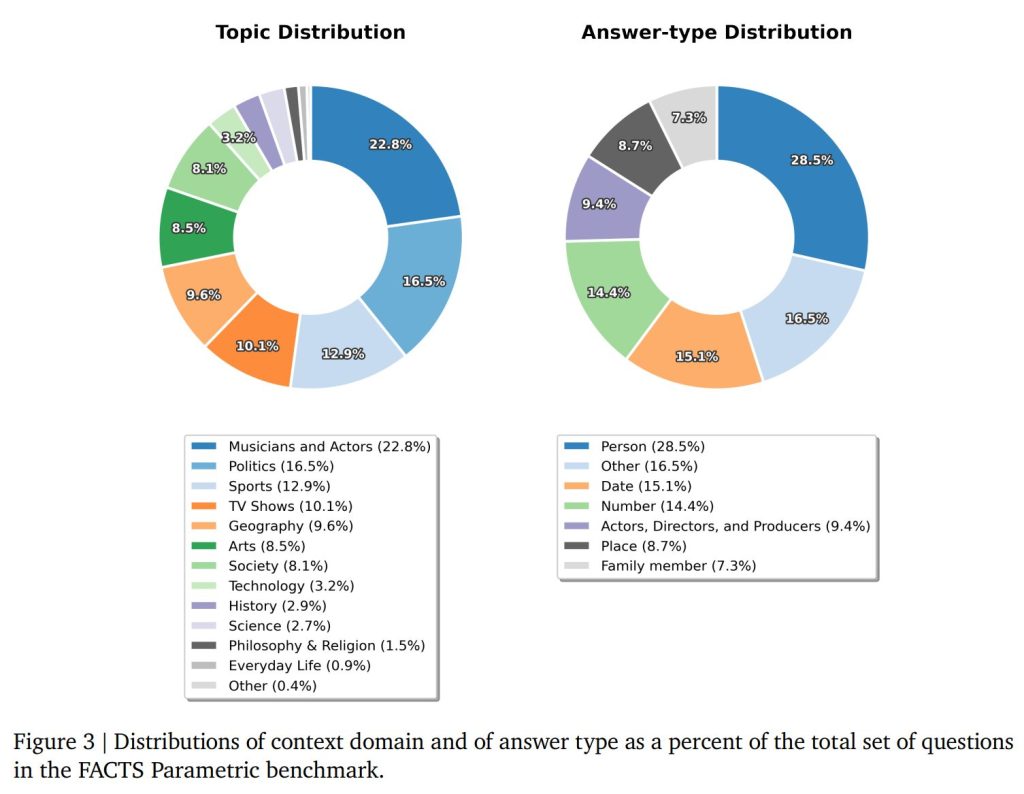
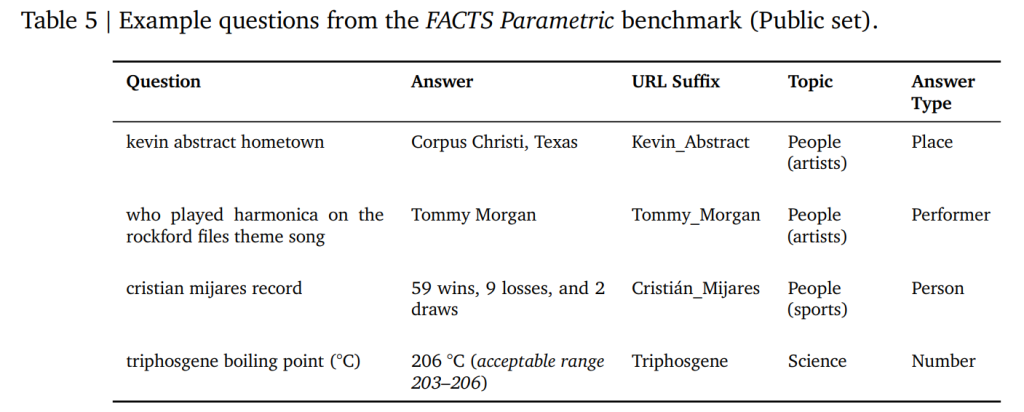
特筆すべきは「敵対的サンプリング(Adversarial Sampling)」を行っている点です。Gemini-2.5-Proなどの強力なモデルで生成した「銀の正解データ(Silver labels)」に対し、オープンな重みを持つ複数のモデルが回答できなかった「難問」のみを抽出しています。これにより、ベンチマークがすぐに飽和(全モデルが高得点を取る状態)することを防いでいます。
4.2. Metrics(評価指標)
Wei et al. (2024)が提案した評価スキームをベースに、いくつかの修正を加えて採用しました。
主な修正点
- 例の調整: 評価者向けの指示プロンプトに含まれる例を、実際のデータでよく見られるシナリオをより適切に表現するよう若干変更しました
- 新ラベルの導入: “unknown”という追加の評価ラベルを導入しました。これは、正解とモデル回答が一致しているか評価者が確信を持てない場合を表します。このラベルにより、評価者の精度がさらに向上することが確認されました
評価ラベル
自動評価システムは、各モデル回答を以下の4つに分類します:
- correct(正解)
- incorrect(不正解)
- not-attempted(回答を試みず)
- unknown(判定不能)
副次的指標:
- Hedging rate: 回答を試みなかった割合(not-attemptedの割合)
- Attempted-accuracy: 回答を試みたもののうちの正解率
- F1-score: 精度と「試みた場合の精度」の調和平均
評価の信頼性向上
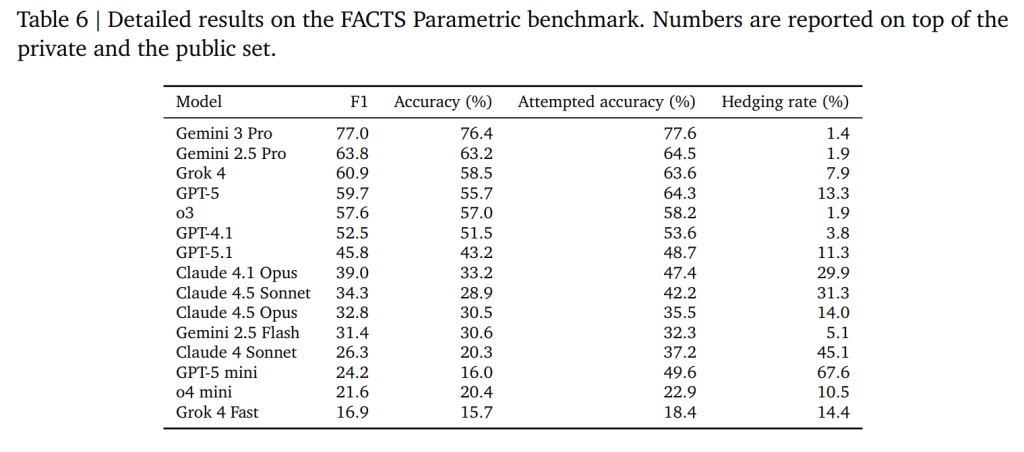
評価の信頼性を高めるため、各クエリ・正解・回答の3つ組に対してGemini-2.5-Proから3回サンプリングを行い、それらを平均して最終スコアを決定しました。強力なモデルを評価に使用することで、評価精度が向上することが観察されました。
最終的に、ベンチマークをシンプルで保守しやすく保つため、Gemini-2.5-Proを唯一の評価者として標準化することを決定しました。この選択を検証するため、混合モデルパネル(Gemini-2.5-Pro、GPT-o3、Grok-4からそれぞれ1回ずつサンプリング)と比較しました。その結果、Gemini-2.5-Pro単体でも、より複雑なアンサンブルと同じ相対的なパフォーマンス傾向とランキングが保持されることが確認されました。
Table 6で示されているように、興味深い結果として、GPT-o3は単純な正解率が高い一方、GPT-5はHedging rate(回答回避率)が高く、結果として「回答した時の信頼性(Attempted accuracy)」が高い傾向にありました。これはモデルの安全設計やチューニング方針の違いを示唆しています。
5. FACTS Search(FACTS検索)
モデルがWeb検索ツールを使用して、正確な情報を回答できるかを評価します。学習データに含まれていないような「ロングテール(稀な情報)」や、複数の情報を組み合わせる必要がある「マルチホップ」な質問が含まれます。
5.1. Data(データ)
データセットは以下の4つのサブセットで構成されています。
- Hard Tail:Web検索の1ページ目には答えが出ないような難問。
- Wiki Two-Hop:Wikipediaの情報を2段階組み合わせる必要がある質問。
- Wiki Multi-Doc:複数のドキュメントを合成して回答する必要がある質問。
- KG Hops:ナレッジグラフ上の複数の関係を辿る質問。
品質チェックプロセス
上記の収集プロセスにより、対応する正解を持つ質問セットが作成されました。正解は、人間評価者によって書かれたものか、データ生成プロセスの一部として自動的に抽出されたものです。
すべての質問の回答品質をさらに確認するため、3人の独立した人間評価者が以下の基準に従って各質問と回答を評価するよう求められました:
評価基準
- Correctness(正確性):Google検索を使用して、提供された回答が質問に対する正しい回答であることを確認する
- Uniqueness(一意性):提供された回答とは異なる、別個の実体(エンティティ)で、同じ質問に対して正解となり得るものが存在するかどうかを確認する
- Immutability(不変性):その質問に対する回答が、今後5年間で変化する可能性があるかどうかを特定する

5.2. 検索エンジン
FACTS Searchベンチマークの目的は、LLM(大規模言語モデル)が検索ツールをどの程度うまく使用できるかを評価することです。
評価における重要な考慮点
パフォーマンスは使用する特定のツールに大きく依存するため、意味のある比較を行うには、すべてのモデルが同じ検索エンジンにアクセスする必要があります。
実装方法
FACTS リーダーボード評価では:
- Brave Search APIを検索ツールとして使用
- すべての評価対象モデルは、同じツールの説明を受け取る
- LLMがツール呼び出しをトリガーすると、APIがクエリされる
- 出力はLLMのコンテキストに追加される
5.3. Metrics(評価指標)
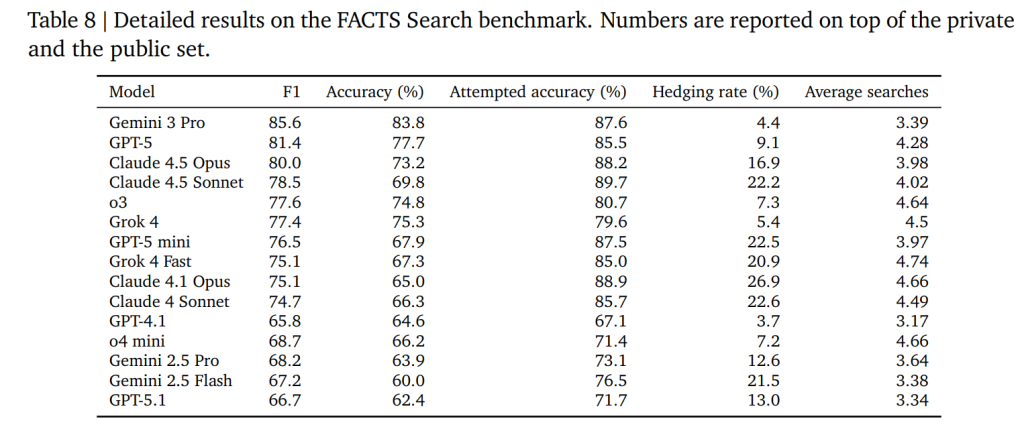
Brave Search APIを共通のツールとして使用し、Gemini 2.0 Flashを審査員として正誤判定を行います。
結果(Table 8)では、Gemini 3 Proが最も高いスコアを記録しました。また、Grokファミリーは検索回数が多い傾向にあり、Claudeファミリーは検索においても不確実な場合は回答を控える(Hedgingする)傾向が見られました。
6. FACTS Grounding v2(FACTSグラウンディング v2)
以前発表された「FACTS Grounding」のアップデート版です。RAG(Retrieval-Augmented Generation)システムのように、与えられた長文ドキュメント(最大32kトークン)のみに基づいて、外部知識を使わずに回答する能力を評価します。
6.1. データ
FACTS Grounding v2のプロンプトセットは、v1と同じものを使用しています。
データ収集プロセス
第三者の人間評価者は、長文入力の処理と長文出力の作成を必要とするプロンプトを設計するよう指示されました。これらのタスクには以下が含まれます:
- Q&A(質疑応答)
- 要約
- 文書の書き換え
評価セットの構成
評価セット内の各例は、以下の要素で構成されています:
コンテキスト:
- ウェブから取得した文書またはレビューのセット
ユーザーリクエスト:
- 提供されたコンテキストを使用して対処できる、自明ではないリクエスト
- 長文の回答を必要とする
システム指示:
- モデルに対し、与えられたコンテキストのみから回答を生成するよう指示
- 外部知識を組み込まないことを要求
多様性の確保
評価セットの多様性を確保するため、プロンプトは以下の範囲で生成されました:
文書の長さ:
- 最大32,000トークンまで様々な長さ
企業ドメイン:
- 金融(Finance)
- 技術(Technology)
- 小売(Retail)
- 医療(Medical)
- 法律(Legal)
アノテーション指示の設計
アノテーション指示は、以下を必要とするプロンプトを避けるよう慎重に設計されました:
- 創造的な回答
- 専門家レベルのドメイン知識
- 数学的または論理的推論
- テキストのメタ分析(トーン分析や著者の意図の解釈など)
データ例と分布
Table 9には、収集されたデータインスタンスの具体例が示されています。

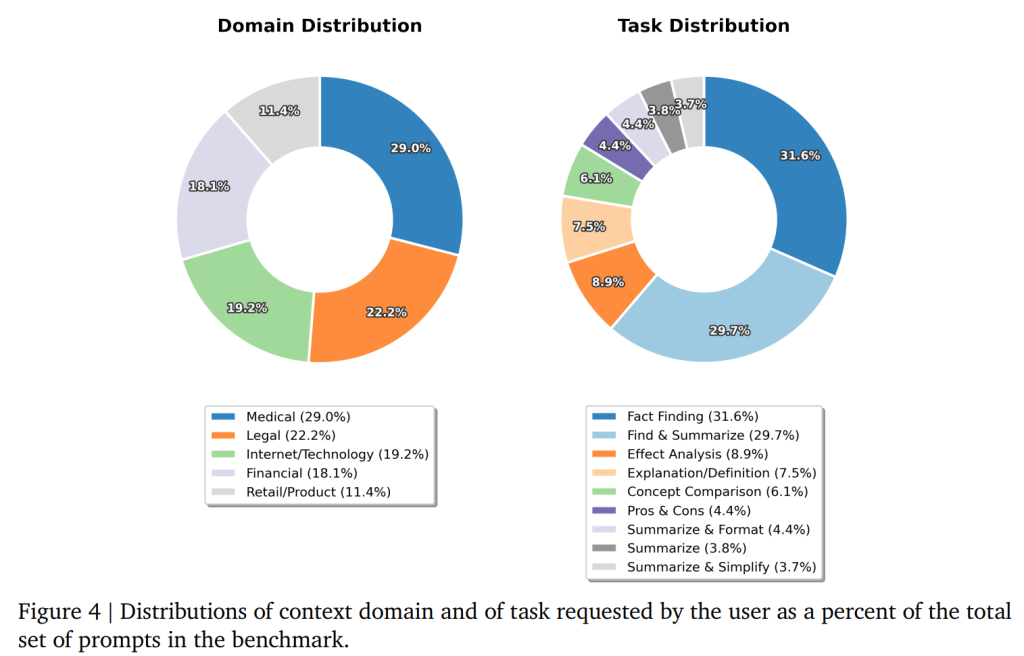
企業ドメインの具体的な分布とユーザーが要求するタスクの分布は、Figure 4に示されています。
6.2. Metrics(評価指標)
v2での主な変更点は、審査員モデル(Judge models)の刷新です。Gemini 2.5 FlashとGPT-5の2つのモデルを審査員として使用し、バイアスを低減しています。
評価は以下の2段階で行われます。
- Grounding Check:回答内のすべての主張が、提供されたドキュメントに基づいているか。
- Eligibility Check:回答がユーザーの質問に対して適切か(はぐらかしていないか)。
例えば、「文書に基づいて売上減少の理由を要約せよ」という問いに対し、「文書には課題が書かれています」とだけ答えるような、ハルシネーションはしていないが役に立たない回答(Ineligible)は不正解として扱われます。これにより、ハッキング的なスコア稼ぎを防いでいます。
評価モデルの品質検証
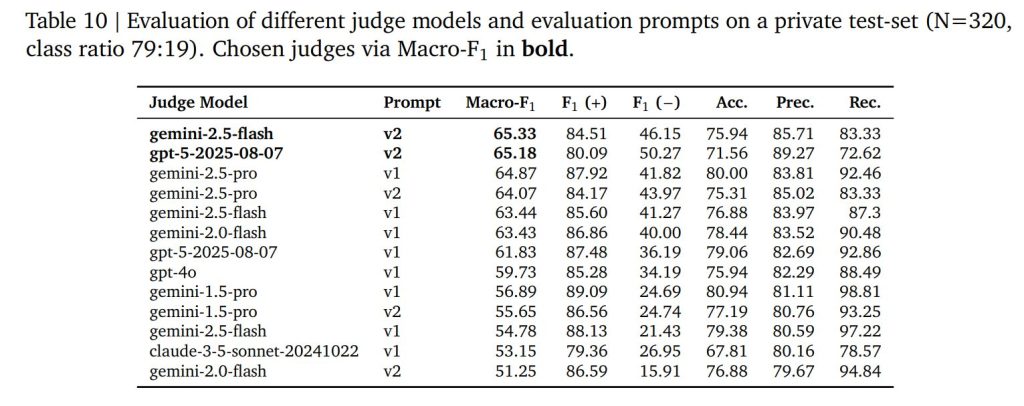
新しい評価モデル(judge models)の品質を評価するため、ホールドアウト評価セット(N=320)で人間評価との比較を行いました。また、評価プロンプトテンプレートの変更についても調査しました。
プロンプトバリアント
具体的には、以下の2つのプロンプトバリアントを検討しました:
- v1: FACTS Grounding v1で使用されたもの
- v2: わずかに修正されたバージョン
検証結果
Table 10に示された結果は、新モデルとv2プロンプトの組み合わせが、他のモデル・プロンプトの組み合わせを上回る性能を示したことを実証しています。
スコアリング方法
2つの評価者が与えられた場合:
- 個別のfactualityスコア: 各評価者における正確な回答の割合
- 未調整のfactualityスコア: すべての評価者スコアの平均
不適格な回答の失格処理
問題点
コンテキスト文書に基づいて生成されたテキストの事実性を評価することに焦点を当てた指標は、ユーザーの意図を無視することで「ハック」される可能性があります。
具体的には:
- より短い回答を提供することで、十分に包括的な情報を伝えることを回避できる
- たとえその内容がユーザーリクエストの重要な側面であったとしても
- 役に立つ回答を提供していないにもかかわらず、高いfactualityスコアを達成することが可能
表11には、この問題を示す具体例が記載されています。

不適格回答への対策
このような回答(情報を省略してスコアをハックする回答)を防ぐため、プロンプト付きjudge LLMsを使用して、生成された回答がユーザーのリクエストに十分対応しているかを判定します。
7. Conclusion(まとめ)
FACTS Leaderboardは、マルチモーダル、内部知識、検索、グラウンディングという異なる側面から事実性を評価することで、LLMの現状をより正確に浮き彫りにしました。
トップモデルであっても平均スコアは約69%に留まっており、事実性の向上にはまだ大きな余地が残されています。今後は、動画理解やリアルタイム情報の反映など、さらなる領域への拡張が期待されます。
まとめ
本稿では、Googleが公開した新しい事実性ベンチマーク「FACTS」について解説しました。単に「RAGの精度」や「学習データの量」だけでなく、画像認識時の幻覚や、検索ツールを使いこなす能力、そして「わからない時に正直にわからないと言う能力(Hedging)」など、多角的な視点でモデルを選定・評価する必要性が示唆されています。








