
はじめに
DeepSeekが2025年10月20日に公開した「DeepSeek-OCR」は、ドキュメント画像からテキストを抽出する多言語対応モデルです。従来のテキストトークン方式ではなく、ビジョントークンを活用することで、大規模ドキュメントの処理速度とコスト効率を大幅に改善します。本稿では、このモデルの仕組み、性能、そして実装方法について解説します。
参考記事
公式発表:
- タイトル: DeepSeek-OCR (GitHub README)
- 著者: DeepSeek AI
- 発行元: GitHub
- 発行日: 2025年10月20日
- URL: https://github.com/deepseek-ai/DeepSeek-OCR
- タイトル: DeepSeek-OCR Model Card
- 発行元: Hugging Face
- 発行日: 2025年10月20日
- URL: https://huggingface.co/deepseek-ai/DeepSeek-OCR
関連情報:
- タイトル: DeepSeek’s new open-source model could decode documents more efficiently
- 著者: Aili McConnon
- 発行元: IBM Think
- 発行日: 2025年11月03日
- URL: https://www.ibm.com/think/news/deepseeks-new-model-could-decode-documents-more-efficiently
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
※技術的な解説に関しては、以下をご参照ください。

要点
- DeepSeek-OCRは、ドキュメント画像を「ビジョントークン」に変換する新型OCRモデルで、テキストトークンより効率的にテキストを抽出できる
- 10個のテキストトークンの情報を1個のビジョントークンで表現可能(97%精度)であり、単一GPU上で1日200,000ページ以上を処理できる
- 時間経過とともに古い情報を圧縮する「メモリ減衰」機能を備えており、人間の記憶に似た動作を実現している
- Tiny(512×512)からLarge(1280×1280)まで複数のサイズに対応し、Dockerのような動的スケーリングも可能である
- vLLMでの公式サポート(2025年10月23日)により、本番環境での導入がより容易になった
詳細解説
ビジョントークンが実現する効率化
DeepSeek-OCRの最大の特徴は、ドキュメント画像を直接処理し、テキストをビジョントークンに変換することです。従来のOCRモデルはテキストを文字単位のトークンに変換していましたが、この方式では画像を圧縮されたトークン形式で扱うため、処理に必要なコンテキスト長を大幅に削減できます。IBMの研究者によれば、10個のテキストトークンに相当する情報を1個のビジョントークンで表現しながら、97%の精度を維持する点が革新的だとされています。
実用的な処理能力の観点からは、従来のLLMは複数ページのドキュメント処理に20個以上のGPUを必要としていましたが、DeepSeek-OCRは単一のA100-40G GPUで1日200,000ページ以上を処理できます。これは、エンタープライズ環境において、長文書や大量ドキュメント処理の運用コストを大きく削減できることを意味します。
また、OpenAI創業者のAndrej Karpathy も、「ピクセル(画像)がテキストよりもLLMの入力として優れている可能性がある」というコンセプトに注目しており、研究コミュニティからも高い関心が寄せられています。
メモリ減衰:人間の脳に学ぶ記憶モデル
DeepSeek-OCRは「光学圧縮」という手法を用いており、その特徴の一つが、時間経過とともに古い情報を段階的に圧縮する「メモリ減衰」です。これは人間の記憶メカニズムを模倣しており、直近の情報は高精度で保持しながら、過去の情報は抽象度を高めて保存します。このアプローチにより、モデルは本当に重要な情報に処理リソースを集中させることができます。
また、この機構は有害なデータの削除や不要な学習結果の「アンラーニング」に応用される可能性も指摘されています。Google や IBM を含む複数の研究機関が機械学習における忘却メカニズムの研究を進めており、DeepSeek-OCRはこの分野における有望なアプローチとして注目されています。
複数のモデルサイズと対応形式
DeepSeek-OCRは、入力画像のサイズに応じて4つのネイティブモデルを提供しています。最小のTiny(512×512、64ビジョントークン)は軽量で高速処理が必要な環境向けで、最大のLarge(1280×1280、400ビジョントークン)は高精度が求められる大規模ドキュメント向けです。さらに「Gundam」と呼ばれるモード(複数の640×640パッチ+1つの1024×1024パッチ)は、異なる解像度の領域を組み合わせるなど、動的なスケーリングに対応しています。
対応する入力形式も幅広く、単純なテキスト抽出から表の抽出、図表解析、さらにはグラウンディング機能(「このテキストの位置を特定する」といった指示)まで、様々なプロンプトによるタスク定義が可能です。
インストール方法と環境構築
DeepSeek-OCRを利用するには、Python 3.12.9、CUDA 11.8、PyTorch 2.6.0以上の環境が必要です。以下の手順で導入できます。
基本的なセットアップ:
# リポジトリのクローン
git clone https://github.com/deepseek-ai/DeepSeek-OCR.git
cd DeepSeek-OCR
# Conda環境の作成
conda create -n deepseek-ocr python=3.12.9 -y
conda activate deepseek-ocr
# 必要なライブラリのインストール
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118
pip install -r requirements.txt
pip install flash-attn==2.7.3 --no-build-isolation
# vLLMを使用する場合は、公式にサポートされているため、以下のコマンドで最新版をインストールできます。
uv venv
source .venv/bin/activate
uv pip install -U vllm --pre --extra-index-url https://wheels.vllm.ai/nightly
# 以下のやり方でもインストールできます。
# https://github.com/vllm-project/vllm/releases/tag/v0.8.5にアクセスし、ダウンロードしてください。
# 「pip install ~/<ダウンロード場所>/vllm-<ダウンロードバージョン>.whl」でインストールできます。
# 例:pip install ~/Downloads/vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl簡単なデモ:
DeepSeek-OCR-master/DeepSeek-OCR-vllm/config.py の INPUT_PATH / OUTPUT_PATH などを書き換えてから実行します。
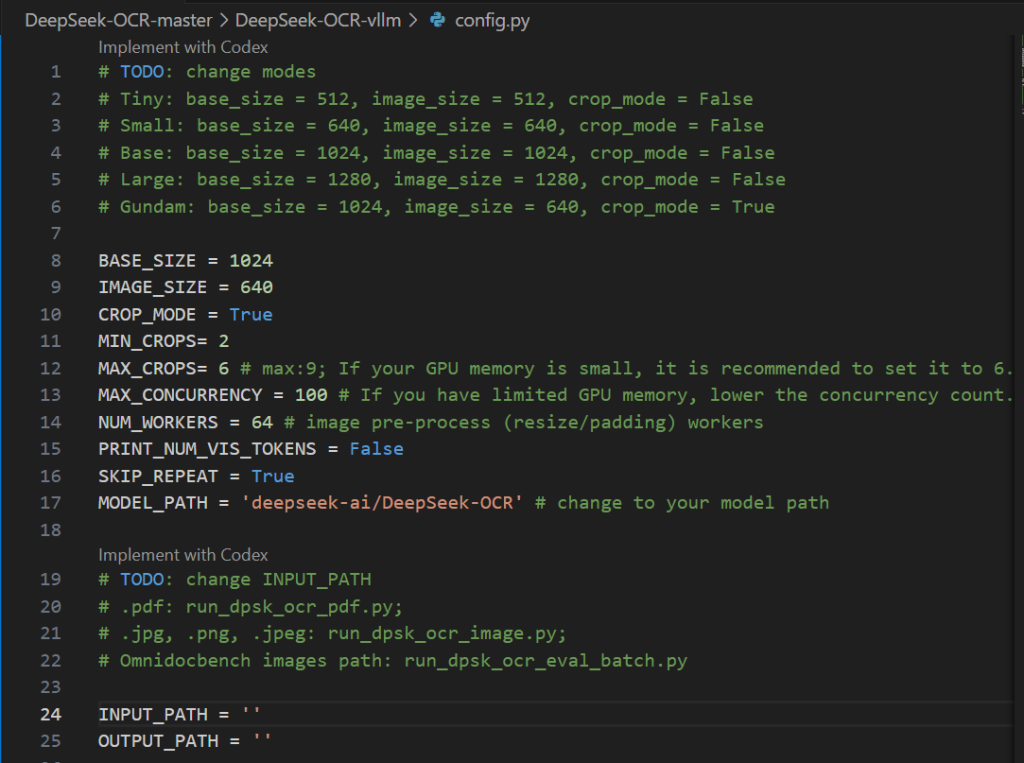
cd DeepSeek-OCR-master/DeepSeek-OCR-vllm
# 画像
python run_dpsk_ocr_image.py
# PDF
python run_dpsk_ocr_image.py実装例①:Hugging Face Transformersを使用した推論
最もシンプルな実装方法は、Transformers ライブラリを利用することです。以下のコード例では、PNG画像からテキストをMarkdown形式で抽出します。
from transformers import AutoModel, AutoTokenizer
import torch
import os
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
model_name = 'deepseek-ai/DeepSeek-OCR'
# モデルとトークナイザーの読み込み
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(
model_name,
_attn_implementation='flash_attention_2',
trust_remote_code=True,
use_safetensors=True
)
model = model.eval().cuda().to(torch.bfloat16)
# ドキュメント画像をMarkdownに変換
prompt = "<image>\n<|grounding|>Convert the document to markdown."
image_file = 'document.jpg'
output_path = './output'
res = model.infer(
tokenizer,
prompt=prompt,
image_file=image_file,
output_path=output_path,
base_size=1024, # Baseサイズで処理
image_size=640,
crop_mode=True, # 動的スケーリング有効
save_results=True
)プロンプトは用途に応じてカスタマイズできます。「Free OCR.」は単純なテキスト抽出、「Parse the figure.」は図表の解析、「Describe this image in detail.」は画像全体の詳細描写といった形式に対応しています。
実装例②:vLLMを使用したバッチ処理と高速推論
本番環境で複数の画像を効率的に処理する場合は、vLLMの利用が推奨されます。以下の例では、2つの画像をバッチ処理しています。
from vllm import LLM, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from PIL import Image
# LLM インスタンスの作成
llm = LLM(
model="deepseek-ai/DeepSeek-OCR",
enable_prefix_caching=False,
mm_processor_cache_gb=0,
logits_processors=[NGramPerReqLogitsProcessor]
)
# 画像の読み込みとバッチ入力の準備
image_1 = Image.open("image_1.png").convert("RGB")
image_2 = Image.open("image_2.png").convert("RGB")
prompt = "<image>\nFree OCR."
model_input = [
{
"prompt": prompt,
"multi_modal_data": {"image": image_1}
},
{
"prompt": prompt,
"multi_modal_data": {"image": image_2}
}
]
# サンプリングパラメータの設定
sampling_param = SamplingParams(
temperature=0.0,
max_tokens=8192,
extra_args=dict(
ngram_size=30,
window_size=90,
whitelist_token_ids={128821, 128822} # <td>, </td> タグのホワイトリスト
),
skip_special_tokens=False
)
# 推論の実行
model_outputs = llm.generate(model_input, sampling_param)
# 結果の出力
for output in model_outputs:
print(output.outputs[0].text)vLLMを使用することで、A100 GPU上での処理速度は約2500トークン/秒に達します。これは、大量のドキュメント処理を行う企業データセンター環境で特に有用です。
まとめ
DeepSeek-OCRは、ビジョンベースの光学圧縮とメモリ減衰という2つの革新的なアプローチにより、企業スケールのドキュメント処理を大幅に効率化するモデルです。単一GPUで1日200,000ページ以上の処理が可能という実績は、既存のテキスト抽出方式の限界を示唆しています。vLLMでの公式サポート開始により、本番環境への導入障壁も低下しました。エンタープライズのドキュメント管理、請求書処理、契約書分析など、実務的なユースケースは多く存在します。一方で、この技術が「忘却」というメカニズムを通じて、機械学習の未来にどのような影響を与えるのか、という学術的な問いも同時に生じています。今後のモデル開発に影響を与えることが考えられます。








