はじめに
GoogleがNature Astronomy誌で発表した研究により、汎用的な大規模言語モデルGeminiが、わずか15の学習例から天体現象を93%の精度で分類し、その判断理由を自然言語で説明できることが明らかになりました。本稿では、この研究成果をもとに、Few-shot learningの実用性と説明可能なAIの可能性について解説します。
参考記事
- タイトル: Teaching Gemini to spot exploding stars with just a few examples
- 著者: Turan Bulmus, Dr. Fiorenzo Stoppa
- 発行元: Google Research Blog
- 発行日: 2025年10月20日
- URL: https://research.google/blog/teaching-gemini-to-spot-exploding-stars-with-just-a-few-examples/
- 論文タイトル:Textual interpretation of transient image classifications from large language models
- 著者:Fiorenzo Stoppa, Turan Bulmus, Steven Bloemen, Stephen J. Smartt, Paul J. Groot, Paul Vreeswijk & Ken W. Smith
- 発行日:2025年10月8日
- URL:https://www.nature.com/articles/s41550-025-02670-z
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- Geminiは各天文観測プロジェクトにつきわずか15の注釈付き例から学習し、3つのデータセット全体で平均93%の分類精度を達成した
- 従来の畳み込みニューラルネットワーク(CNN)が数百万の学習データを必要とするのに対し、Few-shot learningにより大幅に学習コストを削減できる
- モデルは分類結果だけでなく、判断理由を自然言語で説明し、フォローアップ観測の優先度スコアも提供する
- 自己の不確実性を評価する機能を持ち、低い一貫性スコアが誤分類の強力な指標となることが確認された
- 12名の天文学者による評価で、説明文の品質が高く実用的であることが検証され、人間との協働により精度を96.7%まで向上できることが示された
詳細解説
天文学における膨大なデータ処理の課題
現代の天文学では、世界中の望遠鏡が毎晩空をスキャンし、超新星のような一時的な天体現象を探索しています。Googleによれば、これらの観測で数百万の潜在的発見のアラートが生成されますが、その大半は人工衛星の軌跡や宇宙線の影響などによる「偽のシグナル」です。
従来、天文学者は畳み込みニューラルネットワーク(CNN)などの専門的な機械学習モデルを使用してこれらのデータを選別してきました。CNNは画像認識に特化した深層学習アーキテクチャで、複数の畳み込み層を通じて画像の特徴を段階的に抽出します。しかし、これらのモデルは「ブラックボックス」として機能し、単に「本物」か「偽物」かのラベルを提供するだけで、その判断理由は説明されませんでした。
この状況は、次世代望遠鏡Vera C. Rubin Observatoryの稼働により深刻な問題になることが見込まれました。Googleの発表では、この望遠鏡は1晩あたり1,000万のアラートを生成すると予想されており、従来の手動検証では対応が不可能になると考えられます。
Few-shot learningによる新しいアプローチ
研究チームは、数百万のラベル付き画像で専門モデルを訓練する代わりに、汎用モデルでFew-shot learningという手法を採用しました。Few-shot learningとは、少数の学習例から新しいタスクを学習する機械学習の手法です。
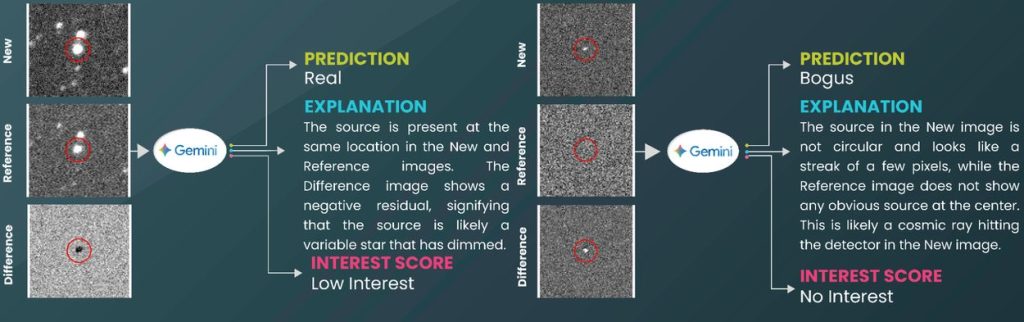
Googleによれば、Pan-STARRS、MeerLICHT、ATLASという3つの主要な天文観測プロジェクトそれぞれについて、わずか15の注釈付き例をGeminiに提供しました。各例は3つの小さな画像で構成されています。
- 一時的なアラートの新しい画像
- 以前の観測による同じ空の領域の参照画像
- 2つの間の変化を強調する差分画像
これらの画像に加えて、簡潔な指示、専門家が書いた分類を説明する短いメモ、興味スコア(例:超新星の可能性が高い場合は「高い関心」、変光星の場合は「低い関心」、偽のシグナルの場合は「関心なし」)とその説明を提供しました。
注目すべきは、これら3つの観測プロジェクトが異なる解像度、ピクセルスケール、カメラ特性を持つという点です。同じ天体でも観測プロジェクトによって見え方が大きく異なりますが、Geminiは提供されたわずかな例から一般化することができました。実際、Pan-STARRSは1ピクセルあたり0.25秒角、MeerLICHTは0.56秒角、ATLASは1.8秒角と、ピクセルスケールが大きく異なる中で高い精度を実現したことは、モデルの汎化能力の高さを示していると言えるでしょう。

各行には、 左から右へ 、新規画像、参照画像、差分画像が含まれています。画像スタンプはすべて同じピクセルサイズ(100×100)ですが、サーベイ固有のピクセルスケール(Pan-STARRS:1ピクセルあたり0.25インチ、MeerLICHT:1ピクセルあたり0.56インチ、ATLAS:1ピクセルあたり1.8インチ)により、天空の角度範囲が異なります。
高精度な分類と説明可能性の両立
この最小限の入力のみで、Googleによれば、Geminiは数千の新しいアラートを分類し、3つのデータセット全体で平均93%の精度を達成しました。この精度は、膨大なキュレートされた訓練データセットを必要とする専門的なCNNと同等の水準です。
しかし、従来の分類器と異なり、Geminiはラベルを出力するだけでなく、すべての候補について以下を生成します:
- 観察した特徴と判断の論理を説明するテキスト説明
- 天文学者がフォローアップ観測の優先順位を決定するための興味スコア
この機能により、モデルはブラックボックスから透明で対話的なパートナーへと変わります。科学者は説明を読んでモデルの推論を理解し、信頼を構築し、より微妙な意思決定を可能にします。説明可能なAI(Explainable AI、XAI)は、特に医療や金融などの高度な判断が求められる分野で重要性が増しており、天文学への応用は科学的発見における透明性の新しい標準を示す可能性があります。
不確実性の自己評価:「助けを求めるタイミング」を知る
信頼性の高いシステムを構築する上で重要なステップは、出力の品質を確保することです。研究チームは12名の専門天文学者のパネルを組織し、Geminiの分類と説明200件をレビューしました。
評価では、0から5までの統一された一貫性ルーブリック(0=幻覚、5=完全に一貫)を使用し、テキストが新しい画像/参照画像/差分画像とどの程度一致しているかを評価しました。加えて、フォローアップの興味スコアが説明と一致しているかについて、シンプルなYes/Maybe/Noのチェックを行いました。結果として、モデルの説明は高度に一貫性があり有用であると評価され、専門家の推論との整合性が確認されました。
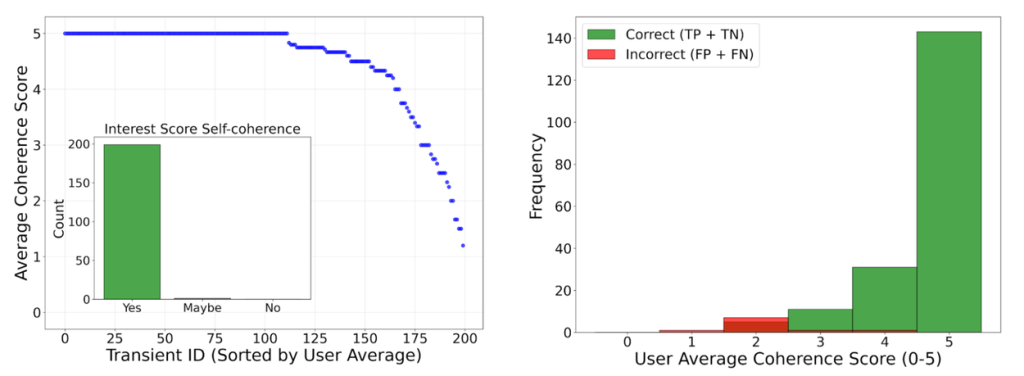
しかし、最も重要な発見は、Geminiが効果的に自身の不確実性を評価できることでした。研究チームはモデルに自身の説明に「一貫性スコア」を割り当てるよう促しました。その結果、低い一貫性スコアが誤った分類の強力な指標であることが判明しました。つまり、モデルは自分が間違っている可能性が高い時を判断できます。
Googleの発表によれば、正しく分類された例(真陽性と真陰性)は、誤った例(偽陽性と偽陰性)よりも高い一貫性スコアを受け取る傾向がありました。この能力は、信頼性の高い「人間参加型ワークフロー」を構築する上で画期的と言えるでしょう。
最も不確実なケースを自動的にフラグ付けすることで、システムは天文学者の注意を最も必要とされる場所に集中させることができます。これにより強力なフィードバックループが生まれます。フラグ付けされたケースをレビューし、これらの困難な例のいくつかをプロンプトに追加することで、モデルの性能を迅速に改善できます。Googleによれば、この反復プロセスを使用して、MeerLICHTデータセットでのモデルの精度を約93.4%から約96.7%に向上させ、システムが人間の専門家と協力して学習し改善できることを実証しました。
科学的発見の新しい時代へ
このアプローチは、複雑な科学データセットを推論し、出力を自然言語で説明できるモデルによって加速される、科学的発見の新時代への一歩を示していると考えられます。
この手法はわずかな例と平易な言語の指示のみを必要とするため、多くの異なる分野で新しい科学機器、観測、研究目標に迅速に適応できる可能性があります。研究チームは、この技術を科学における「エージェント型アシスタント」の基盤として構想しています。そのようなシステムは、複数のデータソースを統合し、自信をチェックし、フォローアップ観測を要求し、最も有望な発見のみを人間の科学者にエスカレートできると考えられます。
一方で、実用化に向けては検証すべき課題もあります。例えば、15例という少数の学習例で本当に多様なケースに対応できるのか、新しい観測装置への適応にどの程度の調整が必要なのか、といった点は継続的な評価が必要になると考えられます。また、説明の質を維持しながらリアルタイム処理に対応できるかという技術的な制約も、大規模な実運用では重要な考慮点となります。
まとめ
Geminiによる天文学応用は、Few-shot learningと説明可能性を組み合わせることで、専門的な機械学習モデルに匹敵する性能を実現しました。わずか15例から学習し93%の精度を達成し、さらに判断理由を説明できる能力は、科学的発見における人間とAIの協働の新しい形を示しています。不確実性の自己評価機能により、人間の専門知識が最も必要とされる場面に焦点を当てることができ、効率的な検証プロセスが可能になります。
今後、同様のアプローチが他の分野で応用され説明可能性が高くなることが期待されます。