
はじめに
本稿では、Googleが2025年9月30日に公式ブログで発表した、新しいオープンソースライブラリ「Tunix」について解説します。Tunixは、特にJAXエコシステムで大規模言語モデル(LLM)を扱う開発者や研究者に向けて、事前学習後のモデル調整(ポストトレーニング)プロセスを簡素化し、効率化するために開発されました。
参考記事
- タイトル: Introducing Tunix: A JAX-Native Library for LLM Post-Training
- 発行元: Google Developers Blog
- 発行日: 2025年9月30日
- URL: https://developers.googleblog.com/ja/introducing-tunix-a-jax-native-library-for-llm-post-training/
その他参照
- GitHubリポジトリ:https://github.com/google/tunix
- 公式ドキュメント: https://www.google.com/search?q=https://tunix.readthedocs.io/
- MaxText: https://github.com/google/maxtext
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- Tunixは、Googleが開発したJAXネイティブのオープンソースライブラリである。
- 大規模言語モデル(LLM)のポストトレーニング(事前学習後の調整)に特化している。
- 教師ありファインチューニング(SFT)、選好チューニング(DPO)、強化学習(PPO, GRPO)、知識蒸留など、主要な調整手法を網羅的に提供する。
- GoogleのTPUでの高性能な実行を目的として設計されており、特にMaxTextとの連携が有効である。
- 開発者がトレーニングループを直接カスタマイズできる「ホワイトボックス」設計を採用しており、研究開発における高い柔軟性を提供する。
詳細解説
Tunixとは何か? – 開発の背景と目的
近年、LLMは目覚ましい発展を遂げていますが、巨大なデータセットで事前学習(Pre-training)されただけのモデルは、いわば「素材」の状態です。そのままでは特定のタスクをうまくこなせなかったり、人間の意図しない不適切な応答を生成したりすることがあります。そこで、事前学習済みモデルに対して追加の学習を行い、その挙動を人間の意図や特定のタスクの要求に沿うように調整するプロセスが不可欠です。このプロセス全体をポストトレーニング(Post-training)と呼びます。
Tunixは、このポストトレーニングのプロセスを、Googleが開発した数値計算ライブラリJAXの環境で、より簡単かつ効率的に行うために開発されました。JAXは、特にGoogleのTPU(Tensor Processing Unit)のようなアクセラレータ上で高いパフォーマンスを発揮することで知られています。TunixはJAXネイティブであるため、JAXエコシステムにシームレスに統合でき、TPUの性能を最大限に活用した高速なモデル調整を実現します。
Tunixの主要な特徴
Tunixは、開発者や研究者が直面する課題を解決するため、以下の3つの重要な特徴を備えています。
1. 包括的なアルゴリズムスイート
Tunixは、LLMのポストトレーニングで利用される主要なアルゴリズムを一つのライブラリにまとめて提供します。これにより、開発者は複数のツールを使い分ける必要がなくなります。
- 教師ありファインチューニング(SFT): 特定のタスクの正解例(プロンプトと応答のペア)を用いてモデルを追加学習する最も基本的な手法です。TunixのPeftTrainerは、全パラメータの更新だけでなく、LoRAやQLoRAといった、計算コストを抑えるパラメータ効率の良いチューニング手法もサポートしています。
- 選好チューニング(Preference Tuning): 人間による「AとBの応答のうち、どちらが良いか」という選好データを用いて、モデルをより人間に好まれるように調整します。Tunixは、報酬モデルの学習を不要にすることでプロセスを簡略化したDPO(Direct Preference Optimization)をDPOLearnerを通じて提供します。
- 強化学習(RL): モデルの応答に対して報酬を与え、その報酬が最大化されるように学習させる手法です。より複雑なタスクや、人間の指示への追従性を高めるために利用されます。
- PPO(Proximal Policy Optimization): RLHF(人間のフィードバックによる強化学習)における標準的な手法です。
- GRPO(Group Relative Policy Optimization): 報酬を評価するための別モデル(クリティックモデル)を不要とし、より効率的に学習を進めることができる手法です。
- GSPO-token: GRPOの派生形で、複数ターンにわたる対話形式のRLトレーニングでの安定性を向上させます。
- 知識蒸留(Knowledge Distillation): 高性能だが大規模で扱いにくい「教師モデル」の知識を、より小型で高速な「生徒モデル」に転移させる技術です。これにより、性能を維持しつつ、コストや応答速度が重要な本番環境向けのモデルを作成できます。
2. 「ホワイトボックス」設計
多くの機械学習ライブラリは、内部の複雑な処理を隠蔽する「ブラックボックス」的な設計になっています。これは使いやすさにつながる一方で、研究者などが内部のロジックを細かく変更したい場合には不便でした。
対照的に、Tunixは「ホワイトボックス」設計を採用しています。これにより、開発者はトレーニングループやその他のコードを抽象化レイヤーに邪魔されることなく、直接的かつ容易にカスタマイズできます。この柔軟性は、新しいアルゴリズムの試行や、データ処理の反復実験を迅速に行う上で大きな利点となります。
3. シームレスなJAX統合
TunixはJAXネイティブのライブラリとして設計されており、JAX、Flax(JAXベースのニューラルネットワークライブラリ)、MaxText(JAXベースの高性能LLMライブラリ)など、既存のJAXエコシステムと深く連携します。これにより、JAXでモデル開発を行っているユーザーは、Tunixを自身のワークフローに簡単に追加し、TPU上でのスケーラブルなトレーニングを効率的に実行できます。
具体的な利用方法と性能
Tunixは、Pythonのパッケージ管理システムであるPyPIで公開されており、以下のコマンドで簡単にインストールできます。
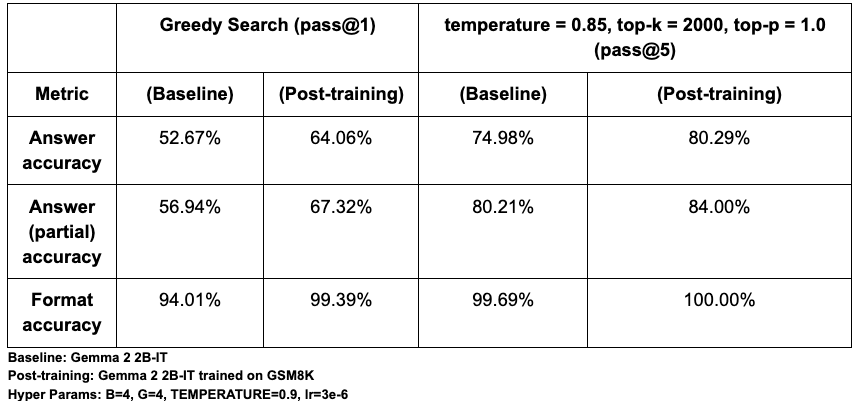
pip install tunixGoogleは、Tunixの有効性を示すために、Gemma 2 2B-ITモデルを数学的推論能力を測るベンチマーク「GSM8K」でポストトレーニングした結果を公開しています。TunixのGRPOアルゴリズムを用いてチューニングした結果、正解率(pass@1)が52.67%から64.06%へと、相対的に約12%向上したことが示されています。これは、Tunixがモデルの性能を短期間で効果的に向上させる能力を持つことを示す一例です。
まとめ
本稿では、Googleが新たに発表したJAXネイティブのLLMポストトレーニングライブラリ「Tunix」について解説しました。Tunixは、SFT、DPO、強化学習、知識蒸留といった主要なモデル調整手法を網羅的に提供し、TPU上での高いパフォーマンスと、研究開発を加速する「ホワイトボックス」設計による高いカスタマイズ性を両立させています。
JAXエコシステムでLLMを扱う開発者や研究者にとって、Tunixは事前学習済みモデルのポテンシャルを最大限に引き出し、本番環境向けの高品質なモデルを効率的に構築するための強力なツールとなるでしょう。








