
はじめに
本稿では、近年のAIモデルの大規模化に伴う学習コストの増大という課題に取り組むための新しい技術として、Microsoft Researchが発表した最適化アルゴリズム「Dion」について解説します。AIの学習において、どの様にパラメータを更新するかを決定する「オプティマイザ(最適化アルゴリズム)」は、学習の速度と性能を左右する重要な要素です。長年「AdamW」という手法が広く使われてきましたが、その性能を上回る新しい選択肢が登場しました。
本稿は、Microsoft Research Blogの「Dion: the distributed orthonormal update revolution is here」という記事を基に、Dionの技術的な仕組みからその性能、そして実際の利用方法まで、解説していきます。
参考記事
- タイトル: Dion: the distributed orthonormal update revolution is here
- 発行元: Microsoft Research Blog
- 発行日: 2025年8月12日
- URL: https://www.microsoft.com/en-us/research/blog/dion-the-distributed-orthonormal-update-revolution-is-here/
要点
- Dionは、AIモデルの学習を効率化するために開発された新しい最適化アルゴリズムである。
- 既存の有力な手法「Muon」が抱えていた、大規模な分散学習環境における通信オーバーヘッドの問題を解決することを目的としている。
- 「ランク」概念を導入し、更新処理の一部(影響の大きい上位ランク)のみを計算対象とすることで、計算量と通信コストを大幅に削減する。
- モデルの規模が大きくなるほど、より低いランクでも性能を維持、あるいは向上させることができ、学習時間の大幅な短縮が期待される。
- PyTorchをベースとした実装がオープンソースで公開されており、誰でも利用可能である。
詳細解説
AI学習におけるオプティマイザの役割
AIモデル、特に深層学習モデルの学習とは、膨大なデータからパターンを学び、モデル内の無数のパラメータ(重み)を調整していく作業です。このとき、モデルの予測と正解の誤差(損失)を計算し、その誤差が小さくなるようにパラメータを少しずつ更新していきます。この「どのようにパラメータを更新するか」という戦略を決めるのがオプティマイザの役割です。
ここ数年間は「Adam」やその改良版である「AdamW」がデファクトスタンダードとして広く利用されてきました。しかし、モデルが数百億、数千億パラメータへと巨大化するにつれ、学習に必要な計算リソースと時間は増大し、より効率的なオプティマイザが求められるようになりました。
学習を安定させる「正規直交更新」
近年のTransformerベースのモデルでは、内部で常に行列演算が行われています。学習中にパラメータの行列を更新すると、入力されるデータ(活性化ベクトル)の方向によって、出力の変化の大きさが変わってしまうという性質があります。これにより、学習が不安定になることがありました。
この問題を解決するアイデアが「正規直交更新(Orthonormal Update)」です。これは、パラメータの更新量を、どの方向の入力に対しても(ほぼ)均一にするための手法です。これにより、学習プロセスが安定し、より高速な学習が可能になります。この正規直交更新の考え方を採用し、高い性能を示したのが「Muon」というオプティマイザでした。

Muonの成功と新たな課題:通信の壁
Muonは、多くのAI研究所で従来の2倍のスケール改善を報告するなど、大きな成功を収めました。これは、同じ性能のモデルを半分のGPUで学習できることを意味します。
しかし、Muonには課題もありました。正規直交化の計算に大規模な行列演算が必要となり、特に巨大なモデルを複数のGPUで並列学習させる「分散学習」(FSDPやテンソル並列化など)の環境では、GPU間の通信がボトルネックになってしまったのです。モデルを分割して複数のGPUで処理する分散学習では、GPU同士が頻繁にデータをやり取りする必要があり、この通信時間が計算時間全体を律速する要因となります。
Dionの登場:ランクを利用したスケーラブルな解決策
この通信の壁を打ち破るために開発されたのが、本稿の主役である「Dion」です。Dionは、Muonの正規直交更新という優れたアイデアを継承しつつ、よりスケーラブルな(規模を拡大しやすい)方法で実現します。
Dionの最も重要な特徴は、「ランク(rank)」という新しいスケーラビリティの軸を導入した点です。行列の更新全体を正規直交化するのではなく、その中で最も影響の大きい部分(上位ランクの特異ベクトル空間)のみを対象とします。これにより、計算の大部分を削減しつつ、性能への影響を最小限に抑えることができます。
Dionは、以下の技術を組み合わせることで、この効率的な部分正規直交化を実現しています。
- 償却べき乗法 (Amortized Power Iteration): 行列の最も主要な成分を効率的に見つけ出すための反復計算を、学習の各ステップに分散させて少しずつ行うことで、1ステップあたりの計算コストを削減します。
- QR分解: べき乗法で見つけ出した主要な成分から、正規直交化された基底(計算の基準となるベクトルのセット)を効率的に抽出します。
- 誤差フィードバック (Error Feedback): 上位ランクのみを計算対象としたことで生じる誤差(無視された部分)を、次回の更新計算にフィードバックします。これにより、重要な情報が失われるのを防ぎ、更新の精度を保ちます。
これらの仕組みにより、Dionは「行列全体を見ることなく、その一部を正規直交化する」ことを可能にしました。これは、データを各GPUに分散させている分散学習環境において、通信量を劇的に削減できることを意味します。

Dionの驚くべき性能
実験結果は、Dionの有効性を明確に示しています。特に、モデルの規模が大きくなるほど、その利点が顕著になります。
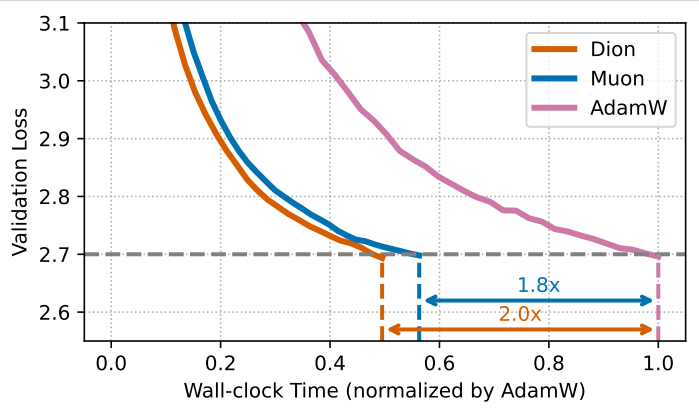
- 大規模モデルでの速度向上: 30億パラメータモデルの学習において、DionはMuonやAdamWよりも短い時間で目標の損失値に到達しました。これは、計算と通信の効率化が、学習全体の高速化に直接つながっていることを示しています。
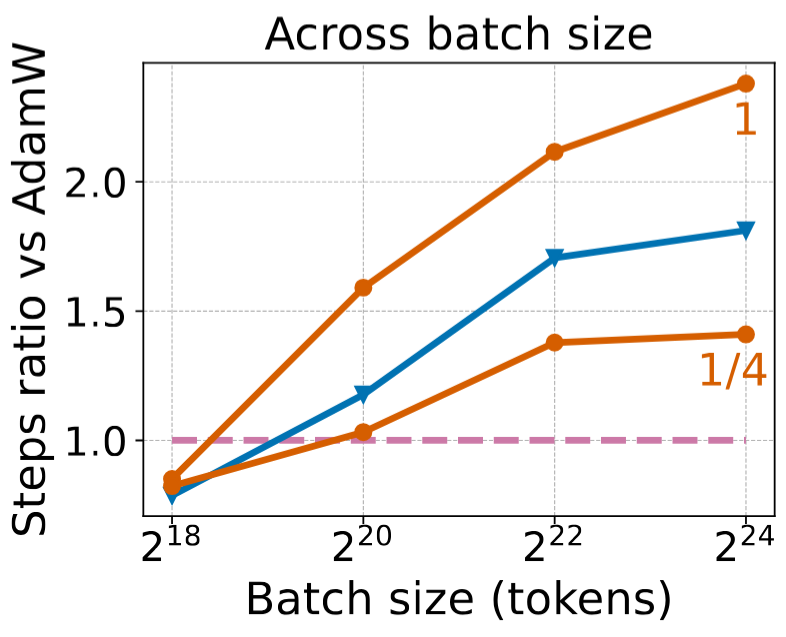
- バッチサイズへの耐性: 一度に処理するデータ量(バッチサイズ)を大きくすると、一般的に学習の質は低下しがちですが、Dionはその劣化が他の手法に比べて緩やかです。これにより、より大きなバッチサイズでの効率的な学習が可能になります。
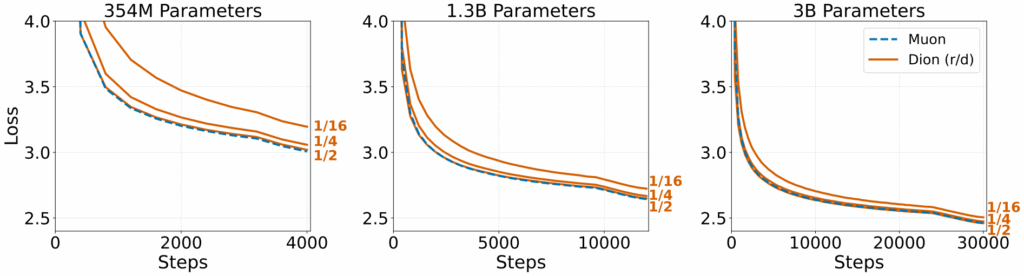
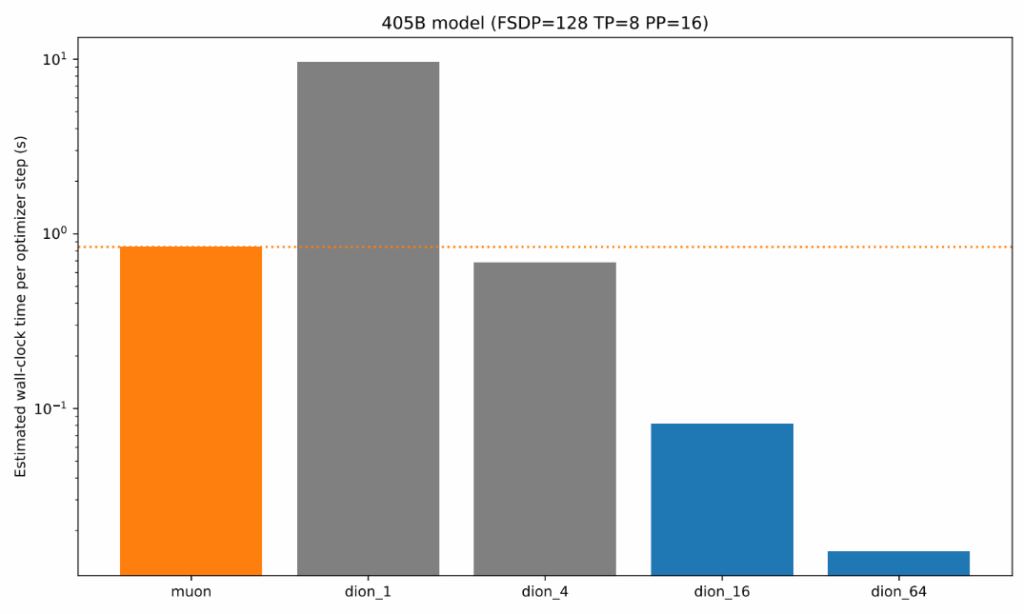
- ランクの調整による柔軟性: モデルが大きくなるほど、全体に対するランクの比率(rank fraction)を小さくしても性能が維持されることが経験的に確認されています。例えば、4050億パラメータのLLaMA-3のような巨大モデルでは、ランクを1/16や1/64に下げても十分に機能すると予測されています。これにより、Muonと比較して1桁以上(10倍以上)の速度向上が見込まれます。
Dionを使ってみる
Dionは、研究者や開発者がすぐに利用できるよう、オープンソースで公開されています。PyTorchでFSDP2(最新の分散学習技術)とテンソル並列化をサポートした実装が、簡単なコマンドでインストール及び利用できます。
pip install git+https://github.com/microsoft/dion.gitfrom dion import Dion, Muon リポジトリにはMuonの実装も含まれており、最新の最適化技術を試すための貴重なリソースとなっています。
まとめ
本稿では、新しいAIの最適化アルゴリズム「Dion」について解説しました。Dionは、正規直交更新の利点を保ちつつ、ランクという概念を用いて計算量と通信コストを削減することで、大規模分散学習におけるスケーラビリティの問題を解決します。
AIモデルの巨大化が続く現代において、学習の効率化は最も重要な課題の一つです。Dionは、その課題に対する強力な解決策であり、今後の大規模モデル開発において新たな標準となる可能性を秘めています。オープンソースとして誰もが利用できる形で提供されていることは、AI開発コミュニティ全体の発展を加速させる上で非常に大きな意義を持つでしょう。








