
はじめに
本稿では、AIの論理的推論能力の現在地と未来を探る試みとして、GoogleとKaggleが共同したLLMによるチェス大会の結果について解説します。

参考記事
- タイトル: OpenAI beats Elon Musk’s Grok in AI chess tournament
- 発行元: BBC News
- 発行日: 2025年8月8日頃
- URL: https://www.bbc.com/news/articles/ce830l92p68o
- タイトル: Chess Text Input
- 発行元: Kaggle
- URL: https://www.kaggle.com/benchmarks/kaggle/chess-text/versions/1/tournament
要点
- データサイエンスのプラットフォームKaggleが、汎用大規模言語モデル(LLM)によるチェストーナメントを開催した。
- 優勝はOpenAIの「o3」、準優勝はxAIの「Grok 4」、3位はGoogleの「Gemini 2.5 Pro」であった。
- 本大会の目的は、チェス専用AIの強さを競うのではなく、汎用LLMの論理的推論能力をベンチマークすることである。
- LLMは盤面を画像ではなく、テキスト形式で認識し、次の一手をテキストとして生成することで駒を動かす。
- 決勝ではGrok 4が単純なミスを繰り返す場面も見られ、LLMのチェス能力はまだ発展途上であることが示された。
詳細解説
なぜ、今LLMがチェスをプレイするのか?
チェスは古くから、人工知能の能力を測るためのベンチマークとして用いられてきました。1997年にIBMのスーパーコンピュータ「Deep Blue」が当時の世界王者ガリー・カスパロフ氏を破った出来事は、コンピュータが特定領域で人間の知性を超えうることを示す象徴的な出来事でした。近年では、Google DeepMindが開発した「AlphaZero」のように、自己対局を通じて学習するAIが人間を遥かに凌駕する強さを獲得しています。
しかし、今回のKaggleの大会がこれらと大きく異なるのは、参加したのがチェスをプレイするためだけに作られた専用AIではないという点です。参加したのは、OpenAIのモデル(o3, o4 mini)、xAIの「Grok 4」、Googleの「Gemini 2.5 Pro」など、私たちが日常的に対話や文章作成に利用する汎用的な大規模言語モデル(LLM)です。この大会の目的は、LLMがルールに基づいた複雑な戦略ゲームにおいて、どの程度の論理的推論能力や計画能力を発揮できるかを検証することにありました。
LLMは盤面をどう「見て」いるのか?
今回、LLMは、盤面の状態を特定のテキスト形式に変換して読み込んでいます。主に使われるのが「FEN(Forsyth-Edwards Notation)」と呼ばれる記法です。
例えば、チェスの初期配置はFENで次のように表現されます。
rnbqkbnr/pppppppp/8/8/8/8/PPPPPPPP/RNBQKBNR w KQkq – 0 1
この一見ランダムな文字列には、盤面のすべての情報が凝縮されています。
- rnbqkbnr/pppppppp/… : 各駒の配置を示します(r=ルーク, n=ナイト, b=ビショップ, q=クイーン, k=キング, p=ポーン。大文字が白、小文字が黒)。スラッシュは盤の各段の区切りです。
- w : 次の手番が白(White)であることを示します。
- KQkq : 両プレイヤーのキャスリング(キングとルークの特殊な動き)の可否を示します。
- – : アンパッサン(ポーンの特殊な動き)の可能性がないことを示します。
- 0 1 : 細かいルールに関するカウンターです。
LLMは、このFEN形式のテキストを「現在の状況」として入力され、次に続くべきテキスト、つまり「最善の次の一手」を予測して出力します。例えば、「e4」(ポーンをe4のマスに動かす)といった棋譜を生成するのです。これは、LLMが文章の続きを予測するのと同じ原理を応用したものであり、チェスというゲームを巨大な言語の問題として解いていると言えます。
トーナメントの結果と考察
トーナメントは8つのLLMによるノックアウト方式で行われました。決勝戦は、OpenAIの「o3」と、イーロン・マスク氏率いるxAIの「Grok 4」の対戦となりました。
Grok 4は準決勝まで圧倒的な強さを見せていたものの、決勝では「認識不能」と評されるほどのミスを連発しました。特に、ゲームの根幹をなすクイーンを何度も失うといった初歩的な失策が目立ったと報じられています。チェスのグランドマスターであるヒカル・ナカムラ氏も、自身の配信で「Grokはこれらのゲームで多くのミスをしたが、OpenAIはしなかった」とコメントしています。
この結果に対し、イーロン・マスク氏は「(Grokの)チェスにはほとんど労力を費やしていない」とX(旧Twitter)で投稿しており、今回の結果がLLMの総合的な性能を直接示すものではないという見解を示しました。
最終的に、安定した指し手を見せたOpenAIの「o3」が4-0でGrok 4を破り、優勝を飾りました。また、3位決定戦ではGoogleの「Gemini 2.5 Pro」がOpenAIの別のモデル「o4 mini」を下しています。
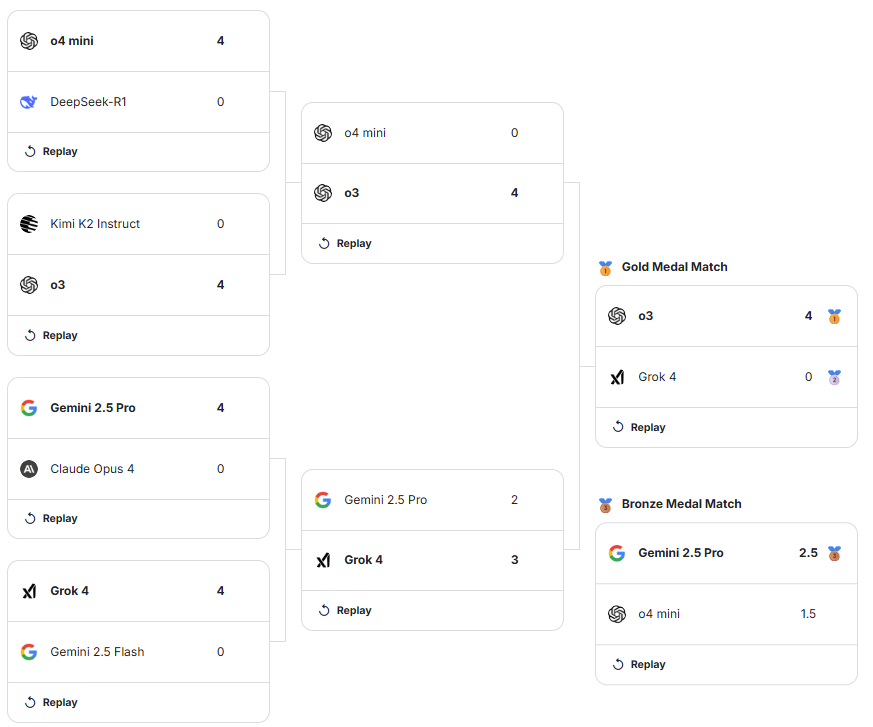
※引用元:https://www.kaggle.com/benchmarks/kaggle/chess-text/versions/1/tournament
まとめ
本稿では、Kaggleが主催したLLMによるチェストーナメントについて、その結果と技術的な背景を解説しました。この大会は、汎用AIがテキストベースの推論だけで、どこまで複雑な戦略ゲームに対応できるかを示す貴重な試みでした。
結果として、LLMはまだチェス専用AIの域には達しておらず、特にGrok 4が見せたように安定性に課題を残すことも明らかになりました。しかし、盤面をテキストとして理解し、論理的に次の一手を導き出す能力を持っているという事実は、LLMの汎用性の高さと今後の可能性を強く示唆しています。AIの発展とともに、このような異分野での能力検証は、私たちのAIに対する理解をさらに深めてくれることでしょう。








