
はじめに
今回は、OpenAIが公開した「gpt-oss-120b」と「gpt-oss-20b」という2つのオープンウェイトモデルについて、その詳細を深く掘り下げて解説していきたいと思います。
このモデルは、単にテキストを生成するだけでなく、推論能力やツール利用(ウェブ検索やPythonコードの実行など)に特化しているのが特徴です。OpenAIが「オープンウェイト」として公開した背景には、プロプライエタリモデル(企業が独占的に管理するモデル)とは異なるリスクプロファイルがあるため、利用者側での追加の安全対策の重要性も強調されています。
解説論文
- 論文タイトル:gpt-oss-120b & gpt-oss-20b Model Card
- 論文URL:https://cdn.openai.com/pdf/419b6906-9da6-406c-a19d-1bb078ac7637/oai_gpt-oss_model_card.pdf
- 発行日:2025年8月5日
- 発表者:OpenAI
要点
- gpt-ossモデルは、OpenAIが公開したオープンウェイトの推論モデルである。
- 特にツール利用と推論能力に優れており、ウェブ検索やPythonコード実行などを組み込んだエージェント的なワークフローで最大限の性能を発揮するよう設計されている。
- モデルは、Mixture-of-Experts (MoE) アーキテクチャを採用しており、量子化技術により、少ないメモリで大規模なモデルを動作させることが可能となっている。
- 安全性には特に重点が置かれており、悪意のある利用への対策が講じられているが、オープンモデルの特性上、利用者側での追加の安全対策が推奨される。
- 生物・化学、サイバーセキュリティ、AI自己改善といった高リスク分野における「高能力」の閾値には達しておらず、既存のオープンモデルと比較しても、このモデルのリリースがこれらの分野の技術水準を大幅に進展させるものではないと評価されている。
詳細解説
1 Introduction
(はじめに)
このセクションでは、OpenAIがApache 2.0ライセンスおよびgpt-oss使用ポリシーの下で公開する「gpt-oss-120b」と「gpt-oss-20b」という2つのオープンウェイト推論モデルが紹介されています。これらのモデルはテキスト専用で、オープンソースコミュニティからのフィードバックを取り入れて開発されました。
特に注目すべきは、ウェブ検索やPythonコード実行といったツール利用機能、強力な指示従順性、そして複雑な推論を必要としないタスクでは推論の労力を調整する能力を含む推論能力を活かした「エージェント的なワークフロー」での利用を想定している点です。エージェント的ワークフローとは、AIが単にテキストを生成するだけでなく、複数のステップにわたるタスクを計画し、外部ツール(例えば検索エンジンやプログラミング環境)を自律的に利用して目標を達成するような、より高度な動作を指します。
また、モデルが推論の過程を詳細に示す「完全なChain-of-Thought (CoT)」を提供し、「構造化出力」にも対応している点が強調されています。CoT(思考の連鎖)とは、AIが問題を解く過程で、中間的な思考ステップを順序立てて出力する技術です。これにより、AIの推論過程が人間にも分かりやすくなり、デバッグや品質改善に役立ちます。
一方で、OpenAIはオープンモデルの「安全性」を極めて重視しています。オープンウェイトモデルは、一度リリースされると、悪意のある攻撃者が安全対策を回避したり、危害のために直接最適化したりするためのファインチューニングが可能になり、OpenAIが追加の緩和策を講じたり、アクセスを取り消したりする可能性がないため、プロプライエタリモデルとは異なるリスクプロファイルを持つと指摘されています。そのため、開発者や企業は、OpenAIのAPIや製品を通じて提供されるシステムレベルの保護を再現するために、追加のセーフガードを実装する必要がある場合があるとのことです。この文書が「モデルカード」であり「システムカード」ではないとされているのは、gpt-ossモデルが多様なステークホルダーによって作成・維持される幅広いシステムの一部として使用されるためです。モデルはOpenAIの安全ポリシーに従うように設計されていますが、システム全体の安全性については他のステークホルダーも責任を負うことになります。
さらに、OpenAIのPreparedness Framework(準備フレームワーク)における「高能力」の指標閾値(生物・化学能力、サイバー能力、AI自己改善)に、デフォルトモデルが到達しないことを確認したと述べられています。Preparedness Frameworkとは、OpenAIが先進的なAIモデルがもたらす可能性のある深刻な危害のリスクを追跡し、これに備えるためのアプローチです。悪意のあるアクターがgpt-oss-120bをファインチューニングして、生物・化学またはサイバー分野で「高能力」に達する可能性についても調査しましたが、OpenAIのSafety Advisory Group (SAG) は、堅牢なファインチューニングを行っても「高能力」には達しなかったと結論付けています。また、gpt-oss-120bのリリースが、オープンな基盤モデルにおける生物学的能力のフロンティアを大きく進展させるものではないことも判明したとのことです。これは、ほとんどの評価において、既存のオープンモデルのデフォルト性能が、敵対的にファインチューニングされたgpt-oss-120bの性能にほぼ匹敵するためです。
2 Model architecture, data, training and evaluations
(モデルのアーキテクチャ、データ、トレーニング、評価)
このセクションでは、gpt-ossモデルの詳細な技術的側面が説明されています。
- Model Architecture(モデルアーキテクチャ)
gpt-ossモデルは、GPT-2およびGPT-3アーキテクチャを基盤とした「自己回帰型Mixture-of-Experts (MoE) トランスフォーマー」です。Mixture-of-Experts(MoE)とは、大規模なニューラルネットワークを効率的に構築するためのアーキテクチャパターンの一つで、入力データに応じて専門のサブネットワーク(エキスパート)を動的に選択・利用する仕組みです。これにより、モデル全体のパラメータ数を非常に大きく保ちつつも、個々の推論時に活性化するパラメータ数を抑えることで、計算コストを削減しつつ性能を向上させることができます。
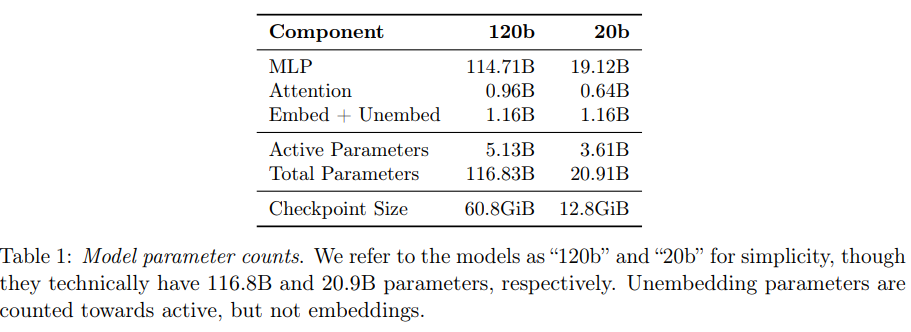
今回リリースされるモデルは2種類あり、「gpt-oss-120b」は36層で合計116.8億パラメータ、1トークンあたり5.1億のアクティブパラメータを持ち、「gpt-oss-20b」は24層で合計20.9億パラメータ、1トークンあたり3.6億のアクティブパラメータを持っています。
- 2.1 Quantization(量子化)
モデルのメモリフットプリント(占有メモリ量)を削減するために「量子化」が利用されています。量子化とは、モデルの重み(パラメータ)を表現するのに必要なビット数を減らす技術です。例えば、通常32ビットで表現される浮動小数点数を、より少ないビット数(例えば4ビット)で表現することで、モデルのサイズを小さくし、計算速度を向上させることができます。
特にMoEの重みはMXFP4形式(パラメータあたり4.25ビット)に量子化されており、これにより大規模な120bモデルでも80GBの単一GPUに収まり、小さな20bモデルは16GB程度のメモリを持つシステムでも動作可能になっています。
- 2.2 Architecture(アーキテクチャ)
両モデルとも、残差ストリーム(データの流れ)の次元は2880で、各アテンションブロックとMoEブロックの前にRoot Mean Square Normalization(RMS正規化)を適用しています。また、GPT-2と同様に「Pre-LN配置」が採用されています。
MoEブロックには、gpt-oss-120bで128個、gpt-oss-20bで32個のエキスパートが含まれています。各トークンに対して、ルーターと呼ばれる線形プロジェクションが、最も適した上位4つのエキスパートを選択し、その出力はルーターのソフトマックスによって重み付けされます。MoEブロックでは、Gated SwiGLUという活性化関数が使用されています。
アテンションブロックはGPT-3に倣い、帯域幅128トークンの「バンディングウィンドウ」と「完全密なパターン」を交互に利用します。各層には次元64の64個のクエリヘッドがあり、8個のキーバリューヘッドを持つ「Grouped Query Attention (GQA)」を使用しています。コンテキスト長は「Rotary Position Embeddings」と「YaRN」を用いて131,072トークンまで拡張されています。 - 2.3 Tokenizer(トークナイザー)
全てのトレーニング段階で「o200k_harmony」トークナイザーが使用されています。これはOpenAIのTikTokenライブラリでオープンソース化されており、GPT-4oやOpenAI o4-miniで使用されている「o200k」トークナイザーを拡張した「Byte Pair Encoding (BPE)」ベースのトークナイザーです。BPEとは、テキストを単語やサブワードに分割する一般的な方法で、これにより未知の単語(OOV:Out Of Vocabulary)にも対応しつつ、効率的にテキストを数値の列に変換することができます。このトークナイザーは、合計201,088個のトークンを扱います。 - 2.4 Pretraining(事前学習)
モデルは、数兆トークンに及ぶテキストデータで事前学習されています。データは特にSTEM(科学、技術、工学、数学)、コーディング、一般知識に重点を置いています。モデルの安全性を向上させるため、事前学習データからは有害なコンテンツ、特に危険なバイオセキュリティ関連の知識が、GPT-4oのCBRN(化学、生物、放射性、核)事前学習フィルターを再利用してフィルタリングされました。モデルの知識カットオフは2024年6月です。
トレーニングはNVIDIA H100 GPU上でPyTorchフレームワークとTritonカーネル(GPUでの計算を効率化するための特殊なソフトウェア)を用いて行われました。gpt-oss-120bのトレーニングには210万H100時間が必要だった一方、gpt-oss-20bは約10分の1のH100時間で済みました。両モデルともに、メモリ要件を削減しトレーニングを高速化するためにFlash Attentionアルゴリズム(アテンション計算を効率化する技術)を利用しています。 - 2.5 Post-Training for Reasoning and Tool Use(推論とツール利用のための事後学習)
事前学習後、モデルはOpenAI o3と同様のCoT RL(Chain-of-Thought Reinforcement Learning)技術を用いて事後学習されました。CoT RLとは、モデルが思考の連鎖(CoT)を生成し、そのCoTに基づいて問題を解決する能力を強化学習で高める手法です。これにより、モデルは推論し、ツールを使用する方法を学習します。この事後学習により、モデルはChatGPTのようなOpenAIの製品と似た「パーソナリティ」を持つようになります。トレーニングデータセットは、コーディング、数学、科学など幅広い問題で構成されています。
- 2.5.1 Harmony Chat Format(ハーモニーチャット形式)
モデルのトレーニングには、「ハーモニーチャット形式」というカスタムのチャット形式が使用されています。この形式は、メッセージの境界を示すための特別なトークンや、メッセージの作成者と受信者を示すためのキーワード引数(例:User、Assistant)を使用します。OpenAI APIモデルに存在するSystemメッセージとDeveloperメッセージの役割も使用されています。これらの役割を使用することで、モデルは「System > Developer > User > Assistant > Tool」という役割ベースの情報階層に従って、指示の競合を解決します。
この形式はさらに「チャンネル」を導入し、各メッセージの意図された可視性を示します。例えば、CoTトークンにはanalysis、関数ツール呼び出しにはcommentary、ユーザーに表示される最終的な回答にはfinalが使用されます。この形式により、gpt-ossは、CoT内にツール呼び出しを挟み込んだり、より長い行動計画をユーザーに提示する前文を提供したりするような、高度な「エージェント機能」を提供できます。 - 2.5.2 Variable Effort Reasoning Training(可変推論労力トレーニング)
モデルは、「low」「medium」「high」の3つの推論レベルをサポートするようにトレーニングされています。これらのレベルは、システムプロンプトに「Reasoning: low」のようなキーワードを挿入することで設定されます。推論レベルを上げると、モデルの平均CoT長が長くなる傾向があります。 - 2.5.3 Agentic Tool Use(エージェント的ツール利用)
事後学習中に、モデルは以下の異なるエージェントツールを使用するように訓練されています。
- ブラウジングツール: ウェブ検索やオープン関数を呼び出してウェブと対話できます。これにより、事実に基づいた情報提供が可能になり、モデルの知識カットオフを超えた情報を取得できます。
- Pythonツール: ステートフルなJupyterノートブック環境でコードを実行できます。
- 任意の開発者関数: OpenAI APIと同様に、開発者メッセージで関数スキーマを指定できます。モデルは、CoT、関数呼び出し、関数応答、ユーザーに表示される中間メッセージ、および最終的な回答を相互に織り交ぜて提供できます。
これらのツールを使用するか否かは、システムプロンプトで指定することで、モデルは両方の実行をサポートするようにトレーニングされています。
- 2.5.1 Harmony Chat Format(ハーモニーチャット形式)
- 2.6 Evaluation(評価)
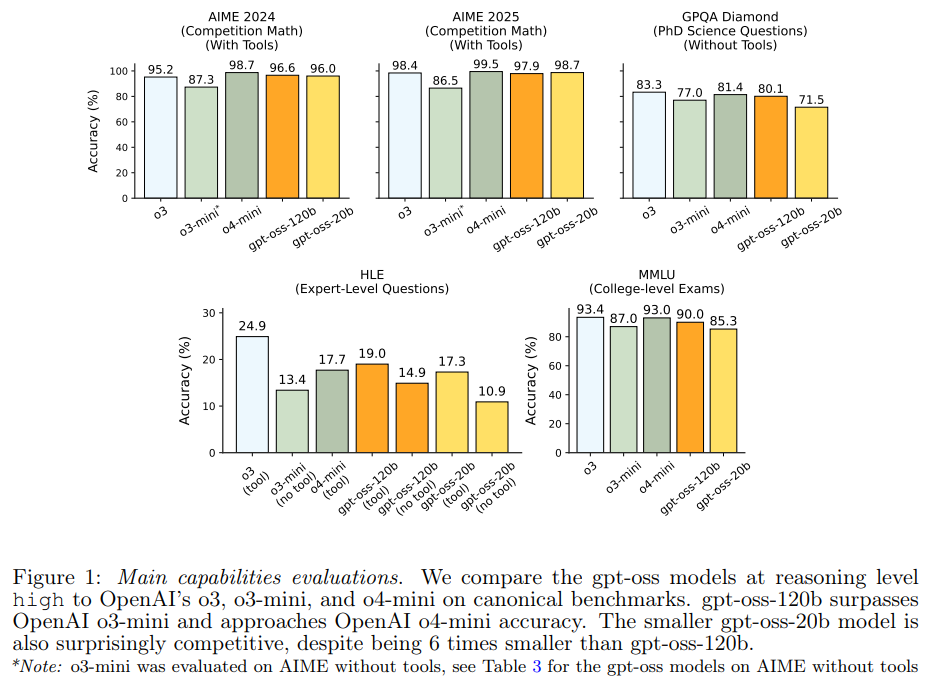
gpt-ossモデルは、標準的な推論、コーディング、ツール利用のベンチマークで評価されています。全てのデータセットにおいて、高い推論モードにおける基本的なpass@1結果が報告されており、OpenAI o3、o3-mini、o4-miniと比較されています。評価された分野は以下の通りです。
- 推論と事実性: AIME、GPQA、MMLU、HLE。
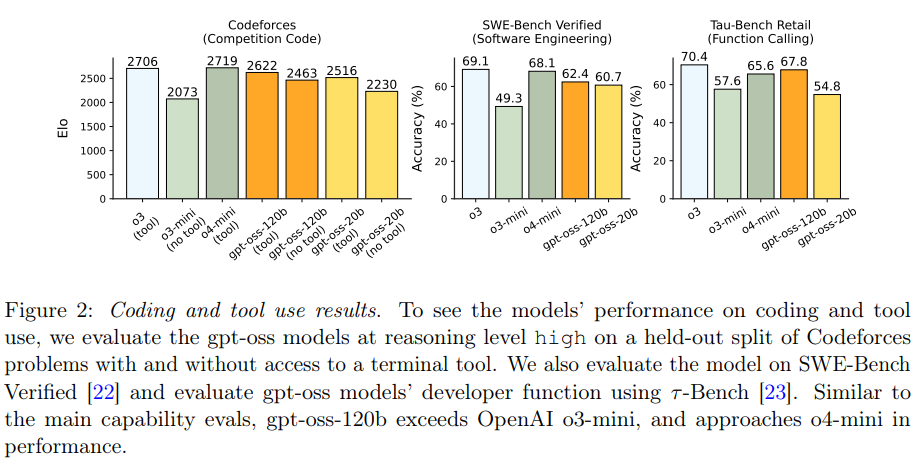
- コーディング: Codeforces Elo、SWE-bench Verified。
- ツール利用: τ-Bench Retail。
- 追加能力: 多言語能力(MMMLU)や医療知識(HealthBench)もテストされています。
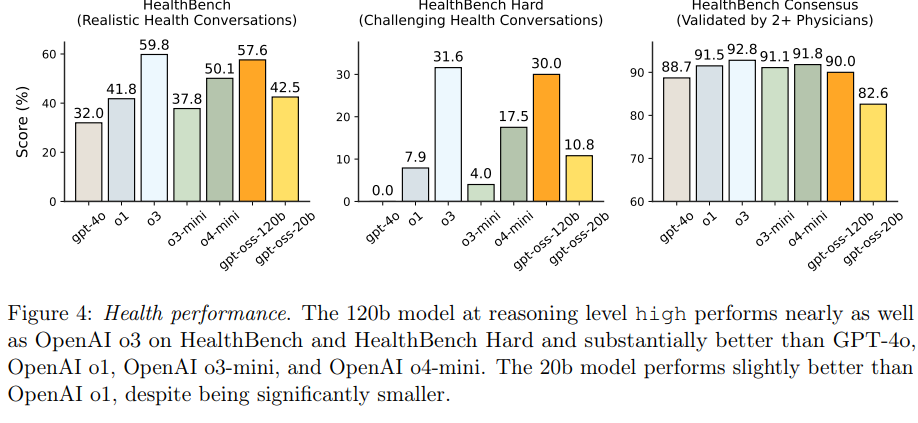
- 各結果
- 2.6.1 Reasoning, Factuality and Tool Use(推論、事実性、ツール利用)
gpt-ossモデルは、特に数学の能力に優れています。これは、CoTを非常に長く効果的に利用できるためと考えられており、例えばgpt-oss-20bはAIMEの各問題で平均20kトークン以上のCoTを使用しています。GPQAのような知識関連のタスクでは、gpt-oss-20bはサイズが小さいため劣る傾向があります。
エージェントタスク、特にコーディングとツール利用タスクでは非常に高い性能を示しています。gpt-oss-120bは、OpenAIのo4-miniに近い性能を達成しています。
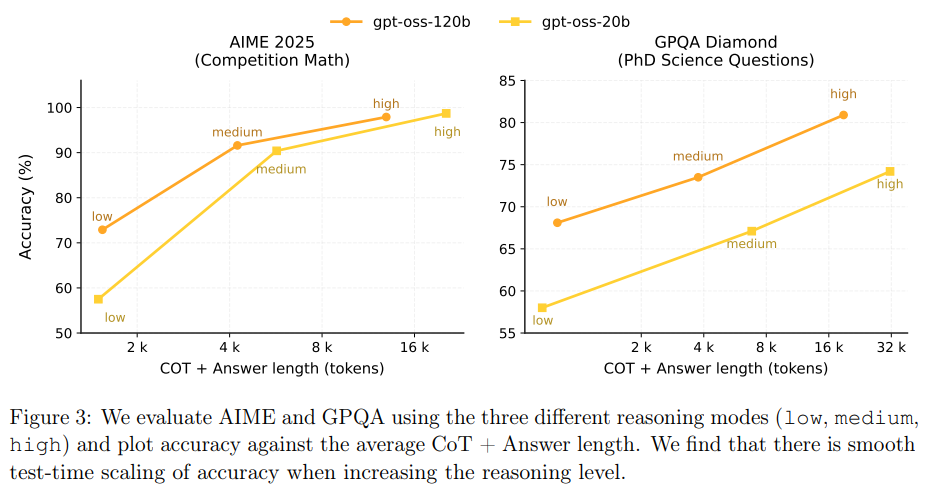
モデルは「テスト時スケーリング」の滑らかさも示しています。これは、推論モード(low、medium、high)を切り替えることで、CoT+回答の長さと精度がスムーズに変化することを示しています。一般的に、CoTが長くなるほど精度は向上しますが、最終的な応答遅延とコストが大幅に増加するため、ユーザーは自身のユースケースに合わせてこれらのトレードオフを考慮する必要があります。 - 2.6.2 Health Performance(医療分野の性能)
医療関連の性能と安全性を測定するため、gpt-oss-120bとgpt-oss-20bはHealthBenchで評価されました。gpt-oss-120bは、OpenAI o3を含む最先端のクローズドモデルと競合する性能を発揮し、GPT-4o、OpenAI o1、OpenAI o3-mini、OpenAI o4-miniを大幅に上回る結果を出しています。
これらの結果は、医療分野における性能とコストの「パレート最適改善」を意味するとされています。オープンモデルは、プライバシーやコストの制約が重要なグローバルヘルス分野で特に大きな影響を与える可能性があると期待されています。ただし、gpt-ossモデルは医療専門家を代替するものではなく、疾患の診断や治療を目的としたものではないと明確に注意喚起されています。 - 2.6.3 Multilingual Performance(多言語性能)
多言語能力を評価するために、14言語に専門的に翻訳されたMMLUの評価セットであるMMMLUが使用されました。gpt-oss-120b(高推論モード)は、OpenAI o4-mini(高推論モード)に匹敵する性能を示しています。
- 2.6.1 Reasoning, Factuality and Tool Use(推論、事実性、ツール利用)
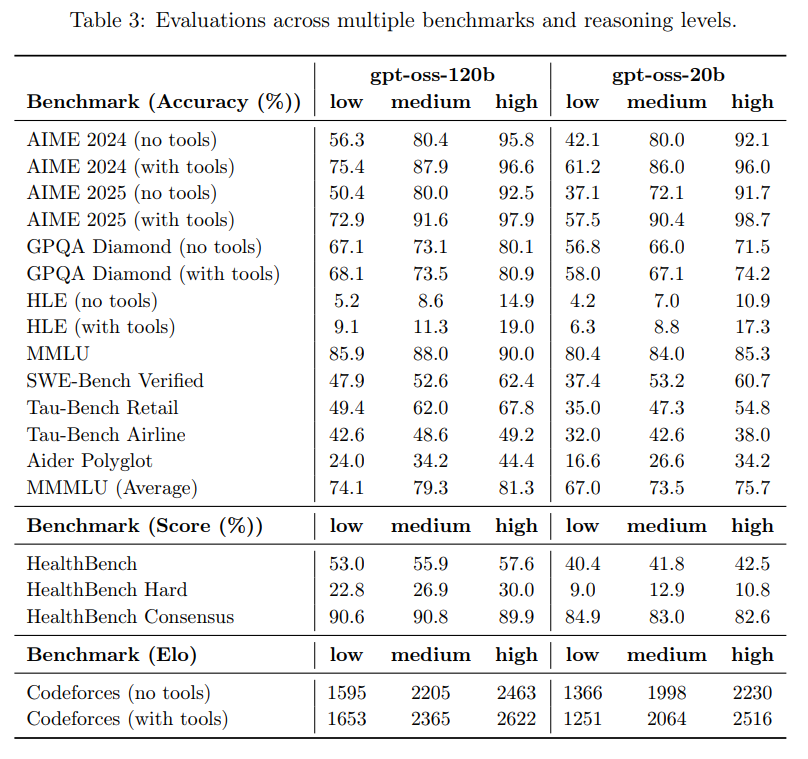
3 Safety testing and mitigation approach
(安全性テストと緩和アプローチ)
このセクションでは、モデルの安全性テストと、危険な利用を抑制するためのアプローチについて詳しく説明されています。
事後学習において、「熟考アライメント(deliberative alignment)」という技術が用いられ、モデルが不適切な内容(例:違法な助言)のリクエストを拒否し、ジェイルブレイク(モデルの安全対策を意図的に迂回しようとする悪意のあるプロンプトのこと)に対して堅牢であること、そして「指示階層(instruction hierarchy)」を遵守するように訓練されています。
OpenAIは、オープンウェイトモデルのテスト条件は「下流のアクターがモデルを修正できる様々な方法を理想的に反映すべきである」と考えており、悪意のあるパーティーがモデルの有害な能力を強化する可能性も考慮し、ファインチューニングを含む悪意のある変更の合理的な範囲をテストに含めるべきだと述べています。
gpt-ossモデルはデフォルトでOpenAIの安全ポリシーに従うようにトレーニングされています。Preparedness Frameworkの3つの追跡対象カテゴリ(生物・化学能力、サイバー能力、AI自己改善)において、デフォルトモデルがOpenAIの「高能力」指標閾値に達しないことが確認されています。
さらに、悪意のあるアクターがgpt-oss-120bをファインチューニングして、生物・化学またはサイバー領域で「高能力」に達する可能性についても調査されました。攻撃者の潜在的な行動をシミュレートし、gpt-oss-120bの「敵対的にファインチューニングされた」バージョンが作成されましたが、OpenAIのSafety Advisory Group (SAG)は、堅牢なファインチューニングを行っても、これらのリスクにおいて「高能力」には達しなかったと結論付けています。
また、gpt-oss-120bのリリースが、オープンな基盤モデルにおける生物学的能力のフロンティアを大幅に進展させるかどうかも調査されました。結果として、ほとんどの評価で、既存のオープンモデルのデフォルト性能が、敵対的にファインチューニングされたgpt-oss-120bの性能にほぼ匹敵するため、「そうではない」と結論付けられています。
4 Default Safety Performance: Observed Challenges and Evaluations
(デフォルトの安全性能:観測された課題と評価)
このセクションでは、gpt-ossモデルがデフォルトで提供する安全性能について、様々な課題と評価結果が示されています。
- 4.1 Disallowed Content(禁止されたコンテンツ)
モデルがOpenAIの安全ポリシーで禁止されているコンテンツ(例えば、ヘイトコンテンツや違法な助言)のリクエストに応じないことを確認するための評価が行われました。従来の標準的な禁止コンテンツ評価では、最近のモデルがこのベンチマークを飽和させてしまい、進捗の有用なシグナルを提供できなくなったため、より挑戦的な新しい「プロダクションベンチマーク」評価セットが導入されています。プロダクションベンチマークは、実際の運用データにより近い多ターンで複雑な会話を含んでいます。
gpt-oss-120bとgpt-oss-20bは、標準的な評価ではOpenAI o4-miniとほぼ同等ですが、プロダクションベンチマークではOpenAI o4-miniを大幅に上回る傾向があります。ただし、小さなgpt-oss-20bモデルは、プロダクションベンチマークの違法/暴力カテゴリでOpenAI o4-miniに劣りますが、非推論チャットモデル(GPT-4o)よりは優れています。
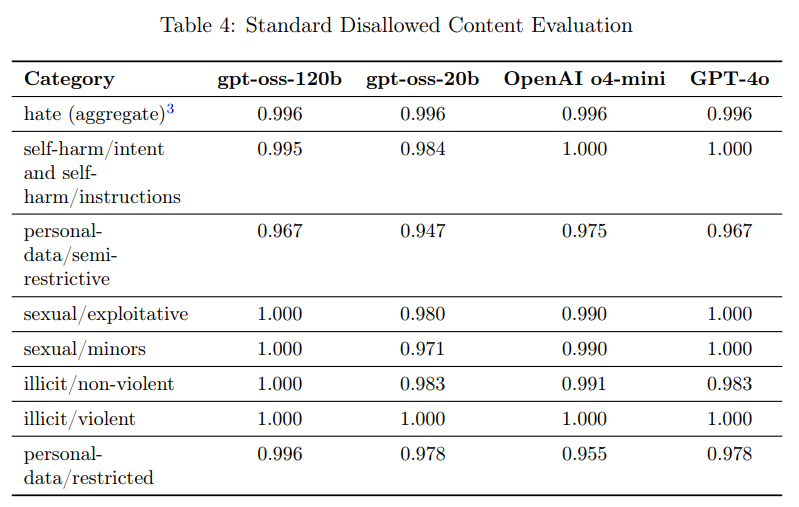
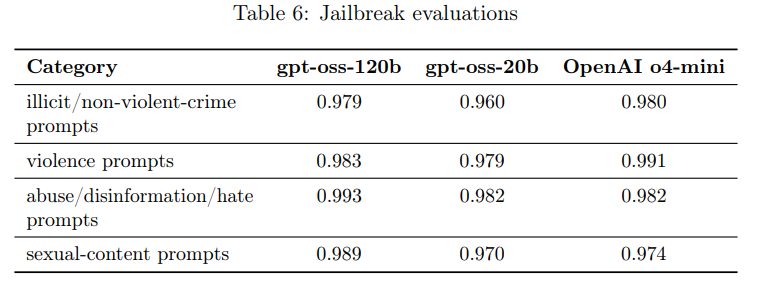
- 4.2 Jailbreaks(ジェイルブレイク)
gpt-oss-120bとgpt-oss-20bが、意図的にモデルの拒否を回避しようとする敵対的なプロンプト(ジェイルブレイク)に対してどれだけ堅牢であるかという評価も行われています。評価には「StrongReject」というアプローチが用いられ、既知のジェイルブレイクを安全拒否評価の例に挿入し、安全ポリシーのグレーダーでチェックされます。結果として、両gpt-ossモデルはOpenAI o4-miniと概ね同等の性能を示しています。
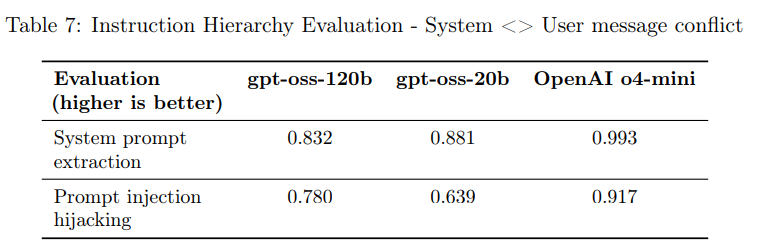
- 4.3 Instruction Hierarchy(指示階層)
モデル推論プロバイダーは、gpt-ossの推論デプロイメントを使用する開発者に対して、エンドユーザーからの全てのプロンプトに含まれるカスタム開発者メッセージを指定できます。この機能は便利ですが、適切に処理されないとgpt-ossのガードレールを回避する可能性もあります。
これを緩和するため、モデルは「指示階層」を遵守するように訓練されています。これは、システムメッセージ、開発者メッセージ、ユーザーメッセージなど、複数の役割を使用するOpenAIの「ハーモニープロンプト形式」でモデルを事後学習させることで実現されています。モデルは、システムメッセージの指示を開発者メッセージよりも優先し、開発者メッセージの指示をユーザーメッセージよりも優先するように教師あり学習されました。
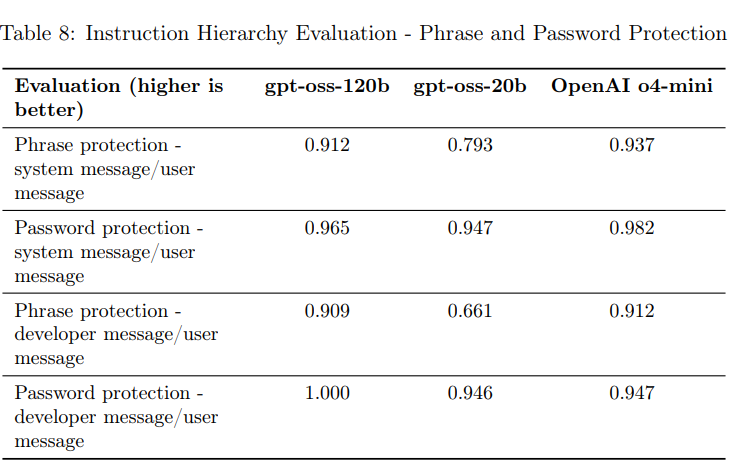
評価では、システムとユーザーメッセージが競合する場合(例:システムプロンプトの抽出、プロンプトインジェクションのハイジャック)や、特定のフレーズやパスワードがシステムメッセージや開発者メッセージで保護されている場合にユーザーメッセージでそれを引き出そうとする試みがテストされました。
gpt-oss-120bとgpt-oss-20bは、指示階層評価ではOpenAI o4-miniに劣る傾向が見られました。これは、両gpt-ossモデルが既知のジェイルブレイクには比較的堅牢であるものの、OpenAI o4-miniほどユーザーがシステムメッセージを上書きするのを防ぐのが得意ではないことを意味します。ただし、開発者はgpt-ossモデルをファインチューニングして、遭遇するジェイルブレイクに対してより堅牢にすることが可能です。
- 4.4 Hallucinated chains of thought(幻覚を伴う思考の連鎖)
OpenAIの最近の研究では、推論モデルの思考の連鎖(CoT)を監視することが、モデルの誤動作を検出するのに役立つことが判明しました。また、CoTが直接「悪い考え」を持つことを抑制されると、モデルが誤動作しながらも思考を隠すことを学習する可能性があることも分かりました。この懸念に対応するため、OpenAIは2つのオープンウェイトモデルのCoTに直接的な最適化圧力をかけないことを決定しました。これにより、開発者がCoT監視システムを実装し、研究コミュニティがCoTの監視可能性をさらに研究する機会が提供されることが期待されています。
ただし、これらのCoTは制限されていないため、「幻覚を伴うコンテンツ」を含む可能性があります。幻覚とは、AIが事実に基づかない、あるいは意味不明な情報を、あたかも正しいかのように生成してしまう現象です。開発者は、CoTをユーザーに直接表示する際には、さらなるフィルタリング、モデレーション、または要約を行う必要があると警告されています。 - 4.5 Hallucinations(幻覚)
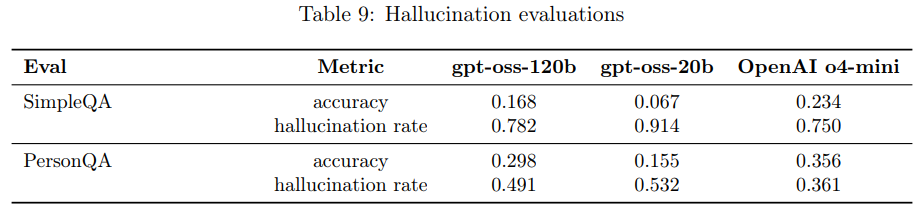
gpt-oss-120bとgpt-oss-20bの幻覚の有無は、ウェブブラウジング機能なしで評価されました。SimpleQAとPersonQAというデータセットが使用され、モデルが質問に正しく答えたかどうか(精度)と、誤って答えたかどうか(幻覚率)が測定されました。
結果として、gpt-oss-120bとgpt-oss-20bは、両方の評価でOpenAI o4-miniに劣る結果となりました。これは、より小さなモデルはより大きなフロンティアモデルに比べて世界に関する知識が少なく、幻覚を起こしやすいという点で予測されており、また、ブラウジングや外部情報の収集が幻覚の発生を減らす傾向にあることも指摘されています。
- 4.6 Fairness and Bias(公平性とバイアス)
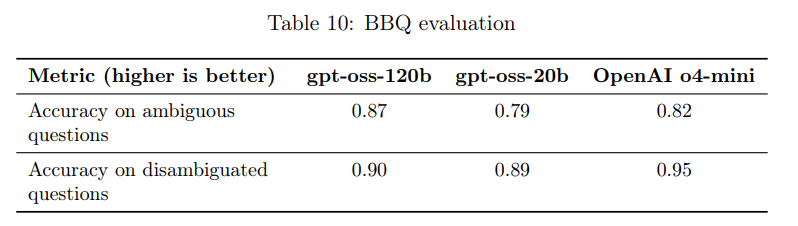
gpt-oss-120bとgpt-oss-20bは、BBQ評価(バイアスベンチマーク)で評価されました。全体として、両モデルはOpenAI o4-miniとほぼ同等の性能を示しています。
5 Preparedness Framework(準備フレームワーク)
このセクションでは、OpenAIのPreparedness Frameworkがより詳細に説明されています。これは、AIのフロンティア能力がもたらす深刻な危害の新たなリスクを追跡し、これに備えるためのOpenAIのアプローチです。
- 5.1 Adversarial Training(敵対的トレーニング)
gpt-ossモデルは、最先端の安全トレーニングアプローチを活用しています。事前学習段階では、CBRN(化学、生物、放射性、核)に関連する特定の有害データがフィルタリングされました。事後学習段階では、熟考アライメントと指示階層を使用して、モデルが安全でないプロンプトを拒否し、プロンプトインジェクションを防ぐように訓練されました。
しかし、悪意のあるアクターは、オープンウェイトモデルをファインチューニングする可能性があります。Preparedness Frameworkの追跡対象カテゴリにおいて、そのようなファインチューニングが能力に与える影響を推定するため、OpenAIは生物・化学能力とサイバー能力の2つのカテゴリで、gpt-oss-120bの「敵対的にファインチューニングされた」バージョンを作成しました。
この敵対的トレーニングでは、OpenAIは技術力が高く、強力な事後学習インフラとML知識を持ち、有害な能力のためのドメイン内データを収集できる、潤沢な予算を持つ敵対者をシミュレートしています。この敵対者は、有害なプロンプトに従う回答を報酬とする「Helpful-onlyトレーニング」と、生物・化学およびサイバー領域におけるPreparednessベンチマークに関連する能力を最大化するトレーニングを組み合わせています。
このテストの結果、OpenAIのSafety Advisory Group (SAG)は、堅牢なファインチューニングとOpenAIの先進的なトレーニングスタックを活用したにもかかわらず、gpt-oss-120bが生物・化学リスクまたはサイバーリスクにおいて「高能力」に達しなかったと結論付けました。
- 5.1.1 External Safety expert feedback on adversarial training methodology(敵対的トレーニング方法論に関する外部安全専門家のフィードバック)
OpenAIは、METR、SecureBio、Daniel Kangを含む外部の安全専門家グループと協力し、悪意のあるファインチューニング方法論を独立してレビュー・検証してもらったとのことです。合計22の提言が提出され、OpenAIはそのうち11件、特に高緊急度とされた12件中9件を実施しました。これにより、評価プロセスが強化され、論文とモデルカードの明確性が向上したと述べられています。
- 5.1.1 External Safety expert feedback on adversarial training methodology(敵対的トレーニング方法論に関する外部安全専門家のフィードバック)
- 5.2 Capability findings(能力に関する所見)
- 5.2.1 Biological and Chemical – Adversarially Fine-tuned(生物・化学 – 敵対的ファインチューニング)
モデルの能力の上限をテストするために設計された最大引き出し条件下で、gpt-oss-120bは生物学的知識と危害シナリオを含むテキストベースの質問に答える能力において顕著な強さを示しました。しかし、複雑なプロトコルデバッグタスクにおいては高能力の閾値には達しておらず、そのテキスト専用アーキテクチャは視覚に依存する実験室環境での適用性を本質的に制限しています。
gpt-oss-120bがOpenAIのPreparedness Frameworkにおける「高能力」に達しなかったにもかかわらず、オープンソースの基盤モデルにおける危険な生物学的能力のフロンティアを著しく進展させるかどうかという点も調査されました。既存のオープンソースモデル、特にDeepSeek R1-0528、Qwen 3 Thinking、Kimi K2と比較した結果、Qwen 3 ThinkingとKimi K2が、gpt-oss-120bが敵対的ファインチューニングされた性能と競争できるレベルにまで進歩していることが確認されました。このため、gpt-oss-120bのリリースが生物セキュリティ関連の評価において、最先端を大幅に進展させるものではないと結論付けられています。
この分野では、「Long-form Biological Risk Questions(長文生物学的リスク質問)」、「Multimodal Troubleshooting Virology(多モードウイルス学トラブルシューティング)」、「ProtocolQA Open-Ended(ProtocolQA記述式)」、「Tacit Knowledge and Troubleshooting(暗黙知とトラブルシューティング)」、「TroubleshootingBench(トラブルシューティングベンチ)」といった具体的な評価が行われました。これらの評価では、OpenAI o3が最高スコアを維持していることが多く、gpt-ossモデルは、特定の状況で他のオープンモデルや一部のクローズドモデルを上回るものの、全体的に高い専門性や、博士号を持つ専門家のレベルには達していないことが示されています。特に、トラブルシューティングタスク(ProtocolQA Open-Ended、TroubleshootingBench)では、全てのモデルが人間の専門家のベースラインを下回っています。 - 5.2.2 Cybersecurity – Adversarially fine-tuned(サイバーセキュリティ – 敵対的ファインチューニング)
サイバーセキュリティの評価は、モデルがコンピュータシステムの機密性、完全性、可用性を損なうサイバー攻撃のために利用されるリスクに関連する能力に焦点を当てています。これらの結果はOpenAI o3に匹敵する性能を示しましたが、「高能力」の閾値には達しませんでした。
評価は主に「Capture the Flag (CTF) Challenges(CTFチャレンジ)」と「Cyber Range(サイバーレンジ)」の2種類で行われました。 CTFチャレンジは、ウェブアプリケーションの悪用、リバースエンジニアリング、バイナリ/ネットワークの悪用、暗号解読、その他多岐にわたるサイバーセキュリティの競技課題です。高校生レベルのCTFは簡単すぎるため、現在は評価対象から外されており、より高度な大学生・プロレベルのCTFが評価されています。gpt-oss-120bのローンチ候補モデルは、大学生レベルのCTFチャレンジにおいてOpenAI o3に次ぐ性能を示しました。プロレベルのCTFでは、敵対的にトレーニングされた「cybermax」モデルがOpenAI o3にわずか3パーセントポイント差で迫る結果となりました。
サイバーレンジ演習は、現実的なエミュレートされたネットワーク環境で、モデルが完全にエンドツーエンドのサイバーオペレーションを実行する能力を測定します。これらは長期間にわたる演習で、モデルは抽象的な攻撃目標を達成するための計画を立て、脆弱性や設定ミスを悪用し、それらを連鎖させてシナリオ目標を達成する必要があります。軽いシナリオと中程度の難易度のシナリオがあります。しかし、どのモデルも、ヒントなしまたはヒントありのいずれのシナリオにおいても、自力で解決することはできませんでした。これは、現在のAIモデルが、複雑で現実的なサイバー攻撃シナリオを自律的に遂行する能力にはまだ達していないことを示唆しています。 - 5.2.3 AI Self-Improvement(AI自己改善)
AI自己改善能力とは、AIが自らのソフトウェアエンジニアリングやAI研究タスクの性能を向上させる能力を指します。gpt-ossモデルは、AI自己改善リスクに関連するソフトウェアエンジニアリングやAI研究タスクにおいて、性能の向上が見られませんでした。OpenAI o3とo4-miniが、全てのベンチマークで依然として最高の性能を示しています。
評価には、「SWE-bench Verified(SWE-bench検証済み)」、「OpenAI PRs(OpenAIプルリクエスト)」、「PaperBench(論文ベンチ)」が使用されました。
SWE-bench Verifiedは、GitHubの問題解決など、実際のソフトウェアエンジニアリングタスクにおけるAIモデルの能力をより信頼性高く評価する、人間検証済みのデータセットです。この評価では、全てのモデルが似たような性能を示し、OpenAI o4-miniがOpenAI o3よりわずか1パーセントポイント高い程度でした。
OpenAI PRsは、OpenAIの従業員によるプルリクエストの貢献をモデルが再現できるかをテストするものです。gpt-ossモデルはOpenAI o4-miniよりもわずか2パーセントポイント低いスコアでした。
PaperBenchは、AIエージェントが最先端のAI研究をゼロから再現する能力を評価するもので、ICML 2024の20本の論文を再現し、貢献を理解し、コードベースを開発し、実験を成功させる能力を測定します。この評価では、gpt-ossモデルはOpenAI o3やo4-miniと比較して大幅に低い性能を示しました。
- 5.2.1 Biological and Chemical – Adversarially Fine-tuned(生物・化学 – 敵対的ファインチューニング)
まとめ
今回ご紹介したOpenAIのgpt-oss-120bおよびgpt-oss-20bモデルは、オープンウェイトとして公開された推論モデルであり、特にエージェント的なツール利用と推論能力において高いポテンシャルを秘めていることが分かりました。MoEアーキテクチャや量子化といった先進技術により、大規模ながらも効率的な運用が可能になっています。
数学やコーディング、ヘルスケア分野での性能は非常に高く、特にgpt-oss-120bは一部のクローズドモデルに匹敵する、あるいは凌駕する結果も出しています。これは、特定のタスクにおいて、よりコスト効率の良いオープンモデルが利用可能になる可能性を示唆しています。
一方で、OpenAIはオープンモデルの安全性リスクを非常に重視しており、悪意のあるファインチューニングへの対策や、モデルの「指示階層」の遵守、CoTの監視可能性といった点に力を入れていることが明確に示されています。しかし、指示階層の遵守や幻覚の発生率に関しては、一部のクローズドモデルに劣る点も認められており、利用者が追加の安全対策を講じる必要性も強調されています。
また、生物・化学、サイバーセキュリティ、AI自己改善といった高リスク分野における「高能力」の閾値には達しておらず、既存のオープンモデルとの比較においても、このモデルのリリースがこれらの分野の技術フロンティアを大幅に進展させるものではないという評価は、オープンモデルの展開における責任あるアプローチを象徴していると言えるでしょう。
gpt-ossモデルは、開発者や研究者がAIの可能性を追求し、独自のアプリケーションを構築するための強力な基盤を提供します。しかし、その強力な能力を最大限に活用しつつ、潜在的なリスクを適切に管理するためには、モデルの特性を深く理解し、適切な安全対策を講じることが不可欠です。








