
はじめに
今回は、大規模なコンピューティングシステムにおける性能予測という、多くの産業にとって非常に重要な課題に、革新的なアプローチで挑んだGoogleの最新論文をご紹介します。その課題を「テキストからテキストへの回帰」という、意外な方法で解決しています。
解説論文
- 論文タイトル:Performance Prediction for Large Systems via Text-to-Text Regression
- 論文URL:https://arxiv.org/pdf/2506.21718
- GitHubURL:https://github.com/google-deepmind/regress-lm
- 発行日:2025年6月26日
- 発表者:Yash Akhauri*, Bryan Lewandowski, Cheng-Hsi Lin, Adrian N. Reyes, Grant C. Forbes, Arissa Wongpanich, Bangding Yang, Mohamed S. Abdelfattah, Sagi Perel, Xingyou Song
- 所属:Google, Cornell University, North Carolina State University (*はGoogle Researchの学生研究者として行った研究)
・あくまで個人の理解に基づくものであり、正確性に問題がある場合がございます。
必ず参照元論文をご確認ください。
・本記事内での画像は、上記論文より引用しております。
要点
- テキストデータの活用と高精度予測:提案された回帰言語モデル(RLM:Regression Language Model)は、システムログや設定ファイルといった、これまで扱いにくかった複雑で非表形式のテキストデータを直接入力として利用できます。これにより、Googleの巨大なコンピューティングクラスタ「Borg」の資源効率を予測し、従来の表形式手法に比べて最大100倍も低い平均二乗誤差(MSE)という驚異的な精度を達成しています。
- 優れた汎用性と適応性:RLMは、わずか数百例の新しいデータ(例えば500例)で新しい予測タスクに容易に適応できる「Few-shot adaptation」能力を持っています。これは、モデルが一度学習した知識を、まだ見たことのない状況やクラスタに素早く転移できることを意味します。
- モデル設計の重要性:アブレーションスタディ(特定の要素を取り除いて性能の変化を検証する実験)により、モデルの性能向上にはエンコーダーの利用、入力シーケンス長の増加、そしてモデルが自身の不確実性を定量化できる能力が非常に重要であることが示されています。
詳細解説
論文の内容をセクションごとに詳しく見ていきます。
1. Introduction (はじめに)
このセクションでは、まずシステム性能予測の重要性が述べられています。システムのレイテンシ(応答時間)、実行時間、スケジューリングの競合、トランザクション応答時間など、様々な産業用途で予測が不可欠であることが示されています。
従来の性能予測手法は、大きく分けて2種類あります。一つは、専門家の知識に基づいて特定のリソース利用量やパフォーマンスをモデル化する伝統的な手法です。もう一つは、機械学習ベースの回帰手法で、特徴量 x からメトリック y を予測するモデルを訓練します。
しかし、これらの伝統的な手法には課題がありました。特に、設定ファイルやシステムログのような複雑な非表形式データを扱うのが難しい点です。従来の機械学習モデル、例えばRandom Forestや多層パーセプトロン(MLP)は、入力データを固定長の数値テンソルとして表現する必要があるため、このようなデータに対しては、手動での複雑な「特徴量エンジニアリング」が不可欠でした。この特徴量エンジニアリングは非常に手間がかかる上、データを数値に圧縮する過程で重要なコンテキストが失われ、予測性能が低下する原因にもなります。
そこで登場するのが、近年大きな進歩を遂げた言語モデル(Language Models)です。言語モデルの技術を利用した「テキストからテキストへの回帰(Text-to-Text Regression)」は、これらの課題を解決する可能性を秘めています。これは、入力 x も出力 y もテキストとして表現することで、複雑なデータ構造を直接扱うことを可能にします。実際に、先行研究では、比較的小規模な言語モデル(本論文ではこれを「回帰言語モデル(RLM)」と呼んでいます)が、大量の (x, y) 回帰データで学習することで、巨大な転移学習能力を持つことが示されています。
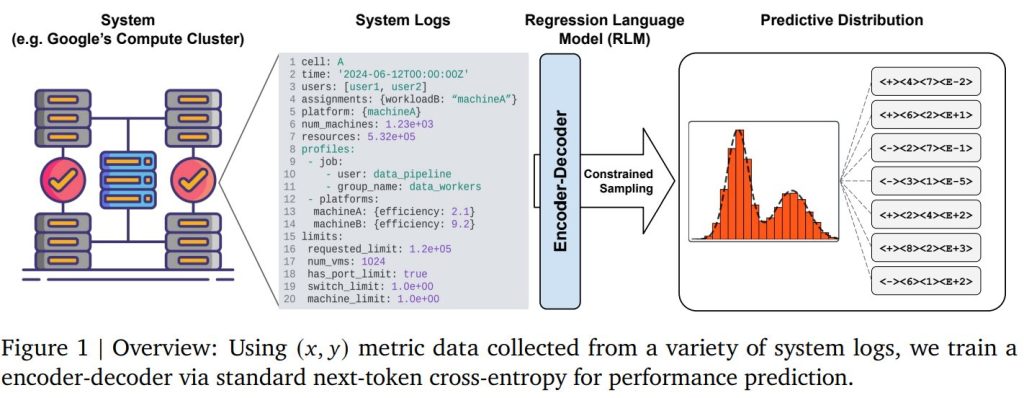
本論文では、Googleの巨大なコンピューティングクラスタである「Borg」の効率予測にRLMを適用し、その有効性を実証しています。主な貢献は以下の通りです。
- RLMが、複雑な特徴量表現や多峰性(複数のピークを持つ)の出力分布に対しても、工業システム(Googleのコンピューティングクラスタ全体など)の効率メトリックといった数値結果を非常に高い精度で予測できること。
- 事前学習済みのモデルが、ごく少量の新しい (x, y) 訓練データでファインチューニングを行うことで、新しいコンピューティングクラスタやシナリオに非常に高い精度で適応できること(Few-shot adaptation)。
- シーケンス長、モデルサイズ、特徴量の観測可能性、アーキテクチャ、学習率、早期停止などが性能向上に与える影響に関する包括的なアブレーションスタディ(詳細な分析)を提供し、モデルの持つ自然な不確実性定量化能力も明らかにしていること。
2. System Performance Prediction (システム性能予測)
ここでは、具体的な予測タスクについて詳しく説明されています。
2.1. Background (背景)
論文では、Googleのコンピューティング管理システム「Borg」を例に挙げています。Borgは、ジョブをスケジューリングする中央マネージャーと、コンピューティングリソースを持つマシン群で構成されています。ユーザーはタスク(実行可能バイナリと必要なリソース、レプリカ数などの詳細を含む)をリクエストし、マネージャーは適切なマシンにタスクを配置します。
このシステムで最も重要なのは、リソースの効率的な割り当てです。スケジューラは、あるタスクが特定のマシン上でどれだけリソースを消費し、最終的にどれだけの有用な作業(生産性)を行うかを把握する必要があります。これにより、特別な「ビンパッキングアルゴリズム」を実行してジョブを割り当て、クラスタ全体の総生産性を最大化するのです。
この生産性メトリックは「MIPS per GCU」と定義されています。これは「Millions of Instructions Per Second per Google Computing Unit」の略で、直感的には、コンピューティングリソースの単位あたり、単位時間あたりにどれだけの作業が完了するかを表しています。このMIPS per GCUは、CPU使用率やメモリ使用量、ハードウェアの種類、様々なマシンのワークロードの組み合わせなど、多数の要因によって変動します。さらに、時間帯によってもワークロードのパターンが異なるため、このメトリックは変化します。
Borgには「デジタルツイン」という洗練されたバックテストフレームワークが存在します。これは、実際のクラスタのチェックポイントファイルを使ってクラスタの状態を複製し、スケジューリングアルゴリズムを実行して、クラスタ全体のMIPS per GCUを決定するものです。しかし、このプロセスは本質的にシーケンシャル(順次的)なため、たった1つの結果を生成するのに1〜18時間もの計算時間を要してしまいます。
幸いなことに、これらの結果は貴重なオフラインデータセットとして記録されており、安価な回帰モデルの訓練に利用できます。もし回帰モデルが推論時間(予測にかかる時間)をほとんどかけずにこのメトリックを正確に予測できれば、計算時間の削減だけでなく、MIPS per GCU全体の最適化を加速することにも繋がり、大きなコスト削減が期待できます。
2.2. Prediction Task (予測タスク)
本研究の目標は、特定のビンパッキングアルゴリズムが実行された後の、単一の浮動小数点数値であるMIPS per GCU効率メトリックを予測することです。入力として利用される情報(特徴量)は多岐にわたります。
- クラスター名(”cell”)
- セルの物理的な場所
- セルの状態を収集した時間枠、およびパフォーマンスプロファイルが収集された正確な時間
- Borgスケジューラのビンパッキングアルゴリズムの動作に影響を与えるハイパーパラメータ
- そのセル内で最も多くのコンピューティングリソースを使用している同時実行エンティティやチーム
- セルにインストールされているハードウェアプラットフォームの分布とネットワーク階層
- ジョブとマシンのパフォーマンスプロファイリング結果のリスト
これらの特徴量は、最小限のドメイン知識に基づいて重要であると推測されますが、それらがメトリックにどのように影響するかは事前には明確ではありません。例えば、効率メトリックは特定の機械とハードウェアのクラスターであるセルに大きく依存しますが、実際のセル名自体は真の特徴量ではありません。また、タイミングウィンドウやハイパーパラメータ名などの特徴量は、異なるタスク間で共有されたり相関があったりしますが、効率メトリックには異なる影響を与える可能性があります。
さらに、この予測タスクは動的であるという複雑さも抱えています。プラットフォームのアップグレードやハードウェアの変更により、新しい特徴量の値が時間とともに現れることがあります。特徴量には、カテゴリ型(ハイパーパラメータ)、様々なハードウェアタイプ、周期的なタイムスタンプなど、多様な型が含まれます。加えて、多くの特徴量(例:ジョブがどのマシンを使用しているかの情報を含むジョブオンマシンプロファイリング、そのマシンがどのようなハードウェアプロファイルを持っているかの情報など)が深くネストされた構造を持つことも、複雑さを増す要因です。
2.3. Observed Features vs. Uncertainty (観測特徴量と不確実性)
予測タスクには、根本的に二種類の不確実性が存在します。
一つは「偶発的不確実性(Aleatoric Uncertainty)」です。これは、システム固有のランダム性から生じるものです。例えば、Borgのビンパッキングアルゴリズムの確率的な性質や、ユーザー向けサービスにおける負荷/需要のランダムな変動などがこれにあたります。これは、どんなに優れた予測モデルを使っても原理的に減らすことができない、本質的なノイズです。
もう一つは「認識論的不確実性(Epistemic Uncertainty)」です。これは、モデルが観測できる情報の範囲が限られているために生じる不確実性です。もしモデルが世界全体の完全な状態 x の一部 φ(x) しか観測できない場合、φ(x) が同じでも実際の x が異なるようなケースを区別できません。この「区別できない」ことによって、モデルの予測性能はさらに制限されてしまいます。
論文では、この認識論的不確実性が、回帰モデルの達成可能な最小誤差の下限(Mean Squared Error: MSE)をどのように引き上げるかについて、数式を用いて説明しています。簡単に言うと、モデルがより多くの特徴量を観測できればできるほど、この認識論的不確実性を減らし、最高の予測性能に近づけることができる、ということです。
2.4. Why Text-based Regression? (なぜテキストベース回帰なのか?)
前述の通り、Borgシステムの性能予測に必要な特徴量は非常に多様で、可変長かつ深くネストされた構造を持っています。従来の表形式の回帰モデル(MLPやRandom Forestなど)では、これら全ての特徴量を単一の固定長テンソルに変換することが極めて困難です。例えば、ジョブのリストやプラットフォームの種類は、状況によってその数が大きく変わるため、手作業でグループ化したり、ヒューリスティックな方法で処理したりする必要がありました。
さらに、表形式の特徴量化では、カテゴリ型のパラメータごとに事前に有限のクラスを定義したり、数値データの最大・最小範囲を正規化のために設定したりする必要があります。もし新しい種類のマシンやワークロードが登場した場合、このプロセス全体を最初からやり直す必要があり、これまでの訓練データも不完全になって使えなくなる、という問題がありました。
ここで、テキストベースの入力表現の利点が光ります。
- 可変長入力の許容:テキストは、入力データの長さに制限がないため、ジョブリストのように数が変動する特徴量も自然に扱えます。
- 明示的な列挙や正規化が不要:カテゴリ特徴量の明示的な列挙や連続値の正規化が不要です。これにより、新しいデータソースが登場しても、モデルを最初から再構築する必要がありません。
- 認識論的不確実性の最小化:テキスト形式であれば、表形式では表現が難しかったネストされた特徴量を含め、利用可能な全ての情報をモデルが観測できます。これにより、認識論的不確実性を最小限に抑え、可能な限り最高の性能を引き出すことができるのです。
- 高速な適応(Few-shot adaptation):モデルは、以前に学習した知識を新しいタスクに素早く転移させ、少量のデータでファインチューニングするだけで高い精度を維持できます。
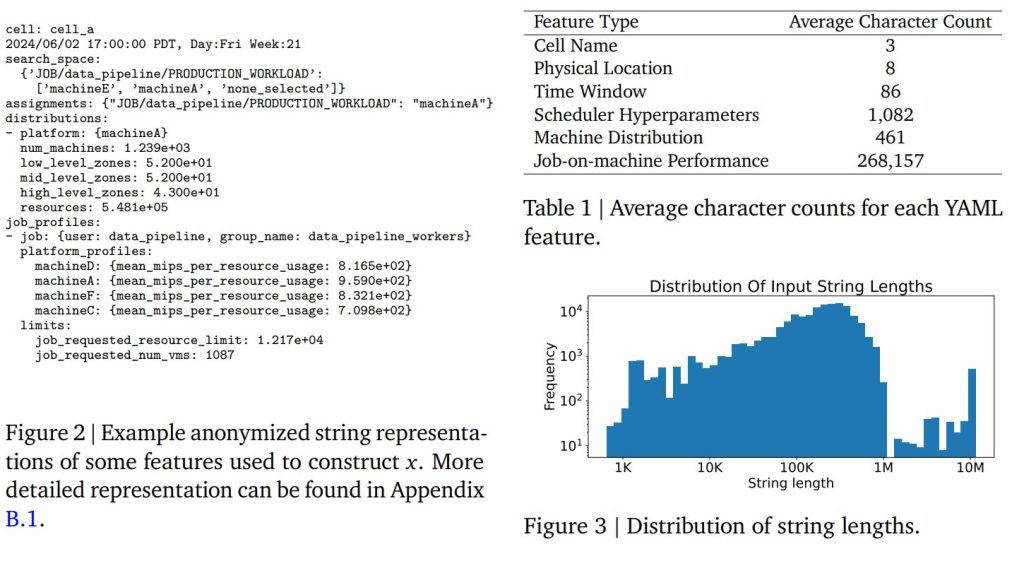
論文では、入力データがYAML(Yet Another Markup Language)のような標準形式で表現される例(Figure 2)や、各特徴量の平均文字数(Table 1)、入力文字列全体の長さの分布(Figure 3)が示されており、ジョブオンマシン性能プロファイリングが26万文字を超える非常に長い文字列になることが分かります。このような複雑なデータを直接処理できる点が、テキストベース回帰の大きな強みです。
3. Method (手法)
このセクションでは、提案する回帰言語モデル(RLM)の技術的な詳細が説明されています。
3.1. Preliminaries: Text-to-Text Regression (予備知識:テキストtoテキスト回帰)
標準的な言語モデルの訓練では、与えられた「プロンプト(指示)」と「レスポンス(応答)」のペアから、レスポンストークンに対する「次トークン交差エントロピー損失」を最小化するようにモデルを更新します。
テキストからテキストへの回帰の場合、プロンプトは入力 x の文字列表現に対応し、レスポンスは浮動小数点値 y のテキストまたは構造化されたトークン表現に対応します。これにより、どんなデータ集合に対しても訓練が可能になります。推論時、モデルは「密度推定量」として解釈でき、特定の x が与えられたときに y がどのような確率分布を持つかを予測します。この分布から複数のサンプルを生成し、それらを統合することで点予測(例えば平均値)を行うことができます。
3.2. Design Choices (設計選択)
本論文のRLMの設計には、一般的なLLM(大規模言語モデル)のトレンドとは異なる、いくつかの重要な選択があります。
- Decoding-based Output (デコーディングベースの出力):
多くの回帰モデルは、数値予測のために、モデルの最後の層に「バリューヘッド」と呼ばれる追加の層を設け、平均二乗誤差(MSE)のような誤差ベースの損失で学習します。しかし、このRLMでは、出力 y をテキストとしてデコードし、トークンに対する交差エントロピー損失で学習します。この方法の利点は、訓練がより安定することです。誤差ベースの損失は、エラーが自然に大きいタスクに過度に注目しがちですが、交差エントロピー損失は予測ギャップの大きさに影響されにくいため、様々な y 値に対して安定した訓練が可能です。また、先行研究でも、埋め込みベースやロジットベースの手法よりも、数値予測をエンドツーエンドでデコードする方が良い性能を示すことが広く観察されています。 - Use of Encoder (エンコーダーの使用):
最近のLLMの多くは、デコーダーのみのアーキテクチャ(例:Gemma、Llama)を採用しています。これにより、プロンプトとレスポンスを結合して設計を単純化できます。しかし、本研究のアブレーション(詳細後述)では、複雑な入力 x を処理するためには別途エンコーダー層が必要であり、デコーダーのみのアーキテクチャでは最適な結果が得られないことが示されています。これは、デコーダーのみのモデルが比較的単純なプロンプトからの出力生成には優れていても、複雑な「プロンプト」である x の情報処理には不十分であるためと仮説されています。 - No Language Pretraining (言語事前学習なし):
現在のLLMのトレンドは、人間が生成した膨大なテキストデータ(例:英語の文章)でモデルを事前学習することです。しかし、本論文では、回帰モデルの訓練において、そのような言語事前学習済みチェックポイントを使用することは必ずしも必要ではなく、また有益であると保証されていないと述べています。実際に、先行研究では、ランダムに初期化された言語モデルでも表形式回帰が可能であることが示されています。これは、回帰というタスクが、単語の持つ「意味論的」な意味から恩恵を受けるのではなく、異なる構造化されたトークン間の「相関」を学習することに本質があるためと考えられています。 - y-Tokenization (yのトークン化):
交差エントロピー損失は、数値的な距離の概念を直接持っていません。そのため、実数をトークン化して離散化する際に、効率的な表現が重要になります。本研究では、「P10トークン化」という手法を採用しています。これは y を特別な符号、仮数、指数トークンで表現するもので、例えば 72.5 を <+><7><2><5><E-1> のように表します。このトークン化は「正規化フリー」であるため、各タスクの y の最小値や最大値を事前に計算する必要がなく、複数のタスクを簡単に訓練できるという利点があります。 - Context-Free (コンテキストフリー):
本モデルは、複数の (x1, y1), (x2, y2), … のペアを「コンテキスト内学習」として入力に与えるのではなく、単一の x を観測して単一の y を返す「コンテキストフリー」な回帰モデルです。これにより、モデルの入力シーケンス長を、何千トークンにもなる可能性のある単一の x の文字列表現に最大限に活用できます。また、このアプローチでは、訓練時に学習された知識がモデルの重みの中に吸収されるため、推論時のコンテキストバッファの有限な制約に縛られることなく、無限のデータをモデルに学習させることができます。
3.3. Fine-tuning (ファインチューニング)
RLMは、一般的なLLMと同様に、事前学習後に追加データでファインチューニングを行うことが可能です。これには2つの目的があります。
- 新しい未知の回帰タスクへの適応: 事前学習で得た知識を利用し、まだ見たことのないタスクにモデルを素早く適応させます。
- 以前に見たタスクへの再集中: 事前学習データが非常に大きかった場合などに、特定のタスクにモデルの焦点を絞り直します。
ファインチューニングは、事前学習済みチェックポイントの重みとオプティマイザの状態を復元し、新しいデータで低い学習率を用いて標準的な訓練を再開するだけで行われます。新しい例の数は非常に少なくても(例えば1~512個)効果があり、単一のGPUで数分という短時間で完了します。これは「メタ学習」の一形態と見なすことができ、事前学習によって得られたチェックポイントが、新しいタスクに勾配更新ベースで迅速に適応できることを意味します。
さらに、モデルが「タスク識別子特徴量」(例:セル名)を観測できるため、特別な技術を必要とせず、全てのタスクデータで事前学習するだけで、複数のタスクにわたる同時回帰を実行できます。その後、ファインチューニングを通じて新しいタスクにも回帰能力を獲得できるのです。
3.4. Regression Scaling Paradigm (回帰スケーリングパラダイム)
RLMは複数の軸でスケーリングを最大化しますが、回帰において最も重要な2つのスケーリング要因は「多様な訓練データ」と「特徴量観測可能性」であると述べられています。回帰は基本的に関数の連続性を学習するタスクであるため、x1 と x2 が「近い」ならば y1 と y2 も「近い」はず、という関係を学習します。そのため、より良い特徴量観測可能性は、入力 x のより良い連続表現をモデルが学習するのに役立ち、より多くの訓練データは入力空間のカバー率を高めることに貢献します。
対照的に、モデルサイズは必ずしも非常に重要ではないとされています。回帰タスクは本質的に識別タスクであり、テキスト生成のような大規模なモデルを必要としないためです。また、ドメイン知識を持つユーザーが、カンマや空白を削除したり、最も重要な特徴量を文字列の先頭に配置したりすることで、文字列表現を効率的に圧縮できれば、シーケンス長の要件も大幅に削減できます。実際に、本論文のデフォルトモデルは、わずか2層のエンコーダー・デコーダー(60Mパラメータ)で、2Kの最大シーケンス長でも十分な結果を出しています。これは、比較的少ない計算資源で高性能な回帰モデルを構築できる可能性を示唆しています。
4. Experiments (実験)
このセクションでは、GoogleのBorgコンピューティングクラスタでの性能予測を通じて、テキストtoテキスト回帰の有効性が実証されています。その結果は、本手法が他の大規模システムにも適用可能であることを示唆するものです。
主な結論として、以下の点が挙げられています。
- 特徴量の観測可能性を最大化することで、これまでのベースラインを大幅に上回る回帰性能が得られる。
- 大規模なデータセットでの事前学習が、効果的な転移学習と新しいタスクへのロバストな適応のために非常に重要である。
- RLMが、点予測と密度推定の両方を可能にする「普遍的」な能力を持ち、データ、モデルサイズ、シーケンス長に応じて効率的にスケーリングできる。
4.1. Data and Evaluation Protocol (データと評価プロトコル)
今回のアプリケーションでは、「タスク T」とは、特定のセル(コンピューティングクラスタの物理的な場所)と特定の月(6月または11月)からの28,000~56,000個の (x, y) 状態-結果ペアの集合と定義されています。これらのペアは、標準的な8:1:1の比率で、訓練データ、検証データ、テストデータにランダムに分割されます。
モデルは、複数のタスク T = {T1, T2, …} の訓練データを組み合わせて事前学習されることがあります。評価は、「in-distribution」(事前学習済みタスクに含まれるタスク T’)と「out-of-distribution」(事前学習済みタスクに含まれないタスク T’)の両方で行われます。out-of-distribution評価は、未知の時期や未知のセルに対して行われることを意味します。評価の質を最大化するため、本論文では y 値の分散が最も大きい40個のセルを含むデータプールが使用されています。
回帰性能の評価には、様々な一般的な指標が用いられています。
- MSE(平均二乗誤差): 予測の精度を評価します。TotalVariance φ という理論的な下限値と比較されます。
- Spearman順位相関係数(ρ): タスク間の y 値のスケールによるバイアスを避けるために使用されます。順位付けのみが重要な最適化ベースのアプリケーションで特に有用です。
- Validation Cross-Entropy Loss(検証交差エントロピー損失): アブレーションスタディでは、評価性能の単純かつ正確な代理指標として用いられています。
4.2. Results (結果)
まず、RLMが十分な訓練データがあれば文字列から回帰できる能力について、y 値の分散が最も大きいタスク T を用いたケーススタディが行われました。Figure 4(左図)では、8つのタスク(約100万データポイント、または約20億トークン)でRLMを事前学習し、タスク T でin-distribution評価を行った結果、0.86という高い順位相関を達成しています。
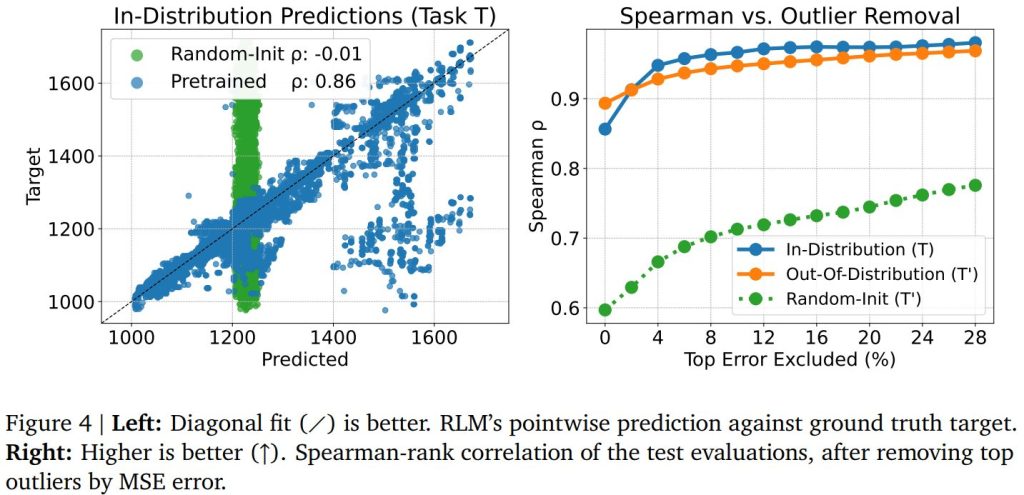
さらに、事前学習済みチェックポイントを、完全に新しいタスク T’ からわずか512個の少数のサンプルでファインチューニングしたところ、RLMは同様に高い性能を達成できることが示されました。対照的に、ランダムに初期化されたモデルが512個のサンプルしか与えられない場合では、in-distributionとout-of-distributionのいずれのケースでも同等の性能を達成することはできませんでした。これは、大規模な事前学習と転移学習の重要性を示しています。
予測における外れ値誤差の大きな要因は、偶発的不確実性(y が決定論的な一点の結果ではなく、確率分布 p(y|x) からサンプリングされるため)にあると考えられています。Figure 5では、RLMが入力 x の中の単一の特徴量(計算が行われた時間)を変えた場合の、回帰モデルの密度推定能力が視覚化されています。RLMの表現 φ(x) が非常にリッチで各状態 x に固有であるため、訓練データ自体には y 値に関する多峰性はありませんが、訓練後にはモデルの誘導バイアスと学習された連続表現により、出力 pθ(y|x) が複数のモード(ピーク)を示すことが確認できます。
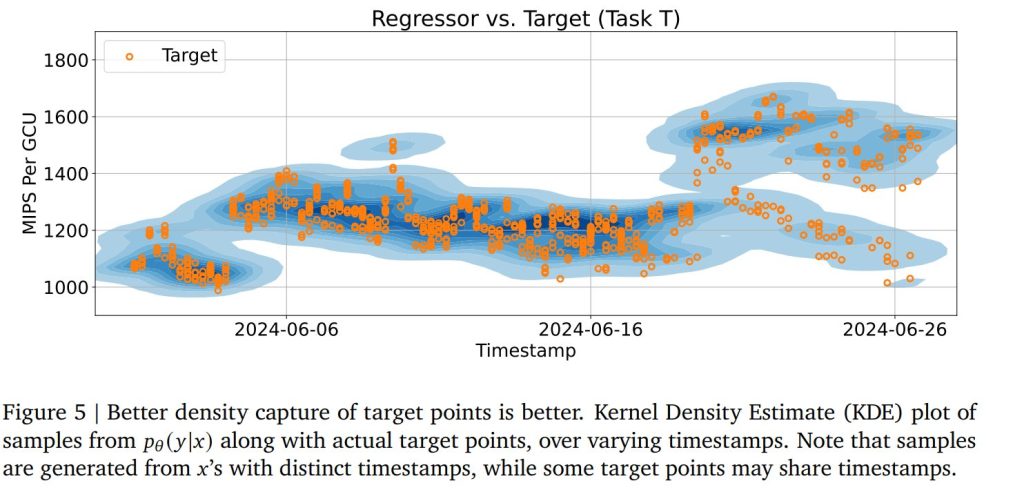
Figure 6では、RLMの性能が、限られた表現 φ(x) を使用するベースライン(表形式のハイパーパラメータ特徴量のみを観測する場合、または全く観測しない「null」の場合)と比較されています。結果として、RLMは全体としてはるかに低い残差を示し、表形式の特徴量ベースの手法と比較してMSEが100分の1に減少しています。これは、特徴量観測可能性を最大化することの重要性を明確に示しています。
Figure 7では、大規模な事前学習、特に新しいタスクへの転移学習における価値が示されています。様々な数のタスクで事前学習したモデルについて、in-distributionの場合ではタスク数を変えても性能の大きな向上は見られませんでしたが、out-of-distributionの場合では、事前学習タスク数 N が多いほど、未知のセルに対する結果が大幅に改善されることが示されています。これは、多様なタスクで事前学習することで、モデルがより汎用的な知識を獲得し、新しい状況にも対応できるようになることを意味します。
回帰手法は、固有のランダム性(偶発的不確実性)や限られたデータカバレッジ(認識論的不確実性)が原因で、特定の場合には根本的に不正確になる可能性があります。このような場合でも、モデルがより高い不確実性(例えば、密度分布の分散)を示すことができれば、ベイジアン最適化のような下流のアプリケーションにとって非常に重要です。Figure 8では、pθ(y|x) の分散と、サンプル (x, y) からの残差誤差との間に高い相関があることが確認されています。さらに、Figure 9では、RLMの密度が、必要な場合に適切に多峰性を示すことが確認され、Figure 5の結果を裏付けています。
Figure 10では、RLMが様々な特性とスケールを持つタスクで、非常に正確な点回帰(pointwise regression)を達成できることが示されています。特にノイズが少ないと思われるタスクでは、Spearman順位相関係数も非常に高く、多くの場合で0.93を超えています。
一方、点予測が不適切な、より高い偶発的ノイズを持つ可能性のあるタスクでは、RLMは代わりに密度推定を実行し(Figure 11)、様々なモードや密度の形状を捉えることができます。
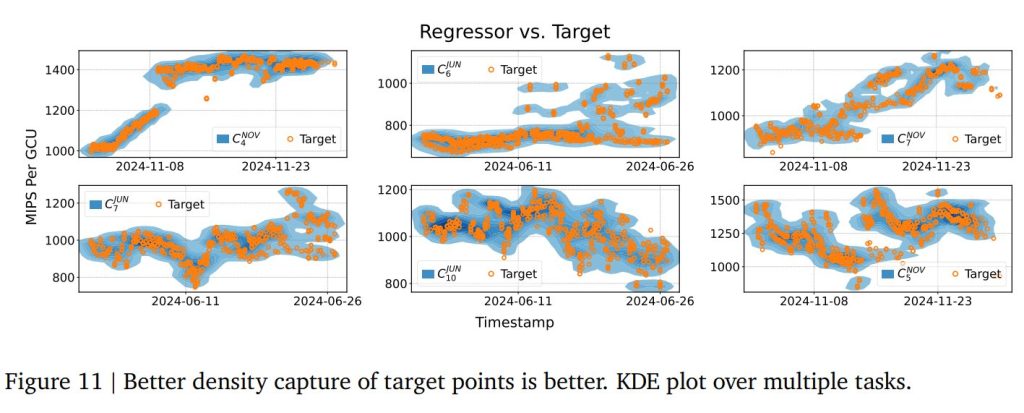
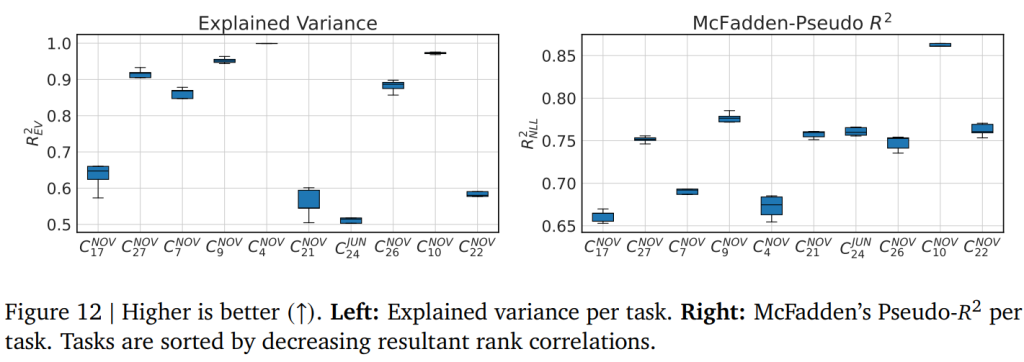
Figure 12では、RLMの実際のゲインを定量化し、本手法の一貫性を示すために、点回帰に対する「説明分散 R^2EV」と、密度推定に対する「McFaddenの擬似 R^2NLL」が複数の実行で集計されています。これらの指標は、x を観測しない「nullケース」と比較して、x を観測することで p(y|x) のモデリングがどれだけ改善されたかを捉えます。興味深いことに、RLMはタスク C_NOV4 で R^2EV ≈ 1 というほぼ完璧な予測を達成しており、ノイズの多いタスクで R^2EV が低い場合でも、R^2NLL は高くなることが示されています。
5. Experiments: Ablations (実験:アブレーション)
このセクションでは、モデルの設計選択や訓練設定が性能にどのように影響するかを探るためのアブレーションスタディ(要素分解研究)が詳しく報告されています。
5.1. Cross-Entropy Loss (交差エントロピー損失)
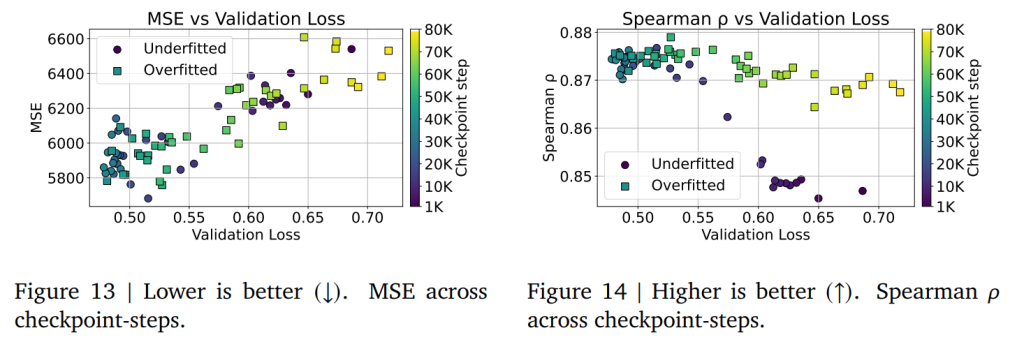
交差エントロピー損失が、MSEやSpearman順位相関といった従来の回帰指標の代理としてどのように機能するかを調査しています。訓練中に保存された全てのチェックポイントを評価した結果、Figure 13では交差エントロピー損失とMSEの間に直接的な相関があることが示されました。しかし興味深いことに、Figure 14では、過学習したモデルでも順位相関は高く維持されることが判明しました。これは、モデルが絶対的な誤差を減らすことよりも、相対的な順位関係を学習する能力を維持できることを示唆しています。
5.2. Architecture (アーキテクチャ)
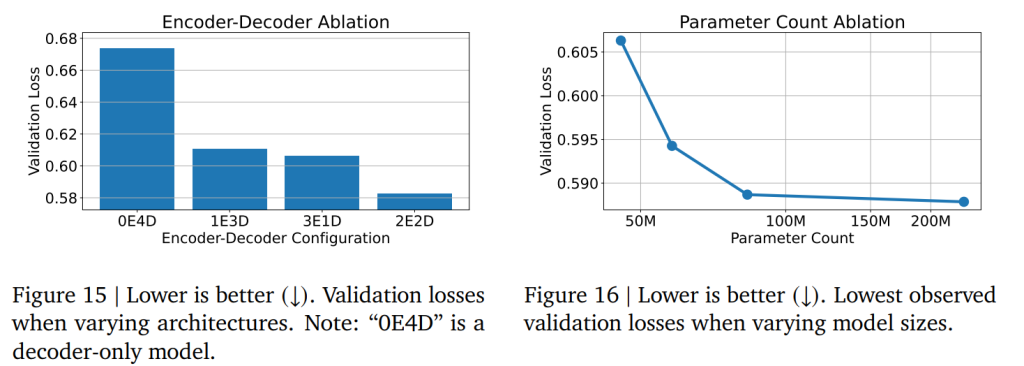
Figure 15では、入力 x を処理する上でエンコーダーの重要性が示されています。同等のモデルサイズ(層数)を考慮した場合、エンコーダー・デコーダーアーキテクチャは、デコーダーのみのアーキテクチャよりも大幅に優れた性能を発揮することが示されています。これは、GemmaやLlamaといったデコーダーのみのLLM設計とは対照的です。論文では、デコーダーのみのモデルが比較的単純なプロンプトに対する出力生成や思考連鎖には優れていても、複雑な「プロンプト」である x を処理するための情報経路が不十分であるためと仮説を立てています。
Figure 16では、モデルのパラメータ数が増加すると回帰性能が向上することが示されていますが、驚くべきことに、この改善はO(100M)パラメータの範囲内で急速にプラトーに達することが分かります。これは、最新の汎用LLMがO(1B)の範囲であることと比較すると、桁違いに低い規模です。この結果は、テキストからテキストへの回帰手法が比較的低い計算量(最大で単一のGPUなど)で実現できることを裏付けており、本手法の幅広い有用性を支持しています。
5.3. Feature Importance (特徴量の重要性)
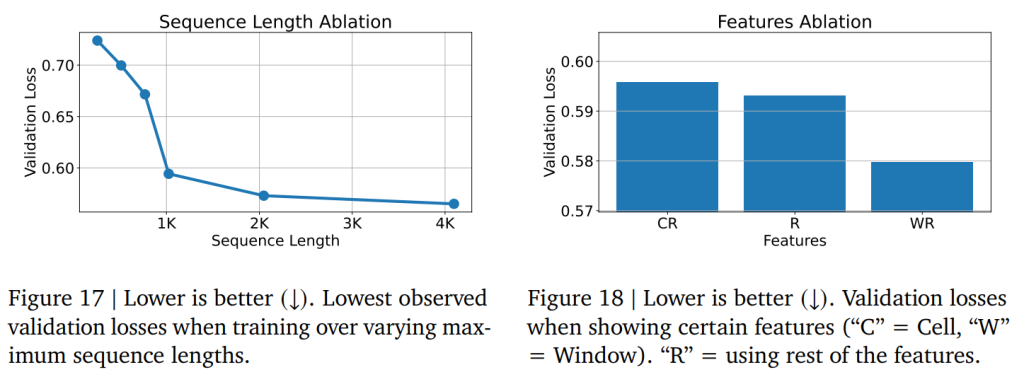
Figure 17では、入力長(シーケンス長)を長くすることで、モデルが y の予測のためにより多くの特徴量 x を観測できるようになり、検証損失が低下することが示されています。しかし、入力長が約3000トークンを超えると、追加されるトークンは主にTable 1で言及されている「ジョブオンマシン性能」のような、最も長く、かつ重要度が低いと思われる特徴量からのものになるため、シーケンス長をさらに増やしてもリターンが減少していくことが分かります。
Figure 18では、特定の入力特徴量を観測することによるモデルの性能が、ドメイン知識からの期待と一致していることが示されています。例えば、クラスタの性能は時間的なサイクルに大きく依存します。夜間はYouTubeのジョブが少なくなったり、特定のジョブが週末には実行されなかったりする、といった具合です。実験的にも、モデルは「時間ウィンドウ」特徴量(例:2024-06-12T06:00:00Z から 2024-06-12T06:05:00Z の期間)が x の表現に含まれる場合に、性能が大幅に向上することが確認されており、この直感を裏付けています。
5.4. Few-Shot Adaptation (少量のデータでの適応)
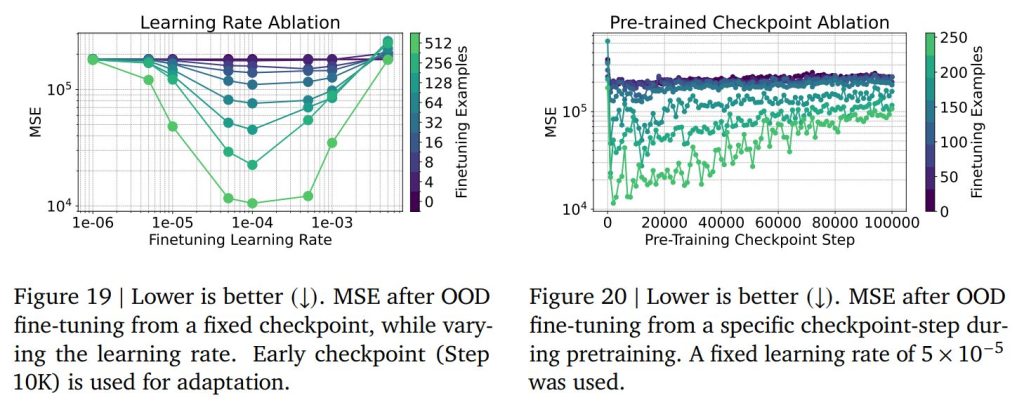
将来的に本手法を実用化するエンジニアにとって有用な、ファインチューニングの最適な設定に関するアブレーションも提供されています。Figure 19では、ファインチューニング時に最適な学習率を見つけることが、予測誤差を減らす上で非常に重要であることが示されています。
Figure 20では、事前学習の比較的初期の段階のチェックポイントの方が、out-of-distributionタスクに対するファインチューニングでより良い結果をもたらす場合があることが示されています。これは、過度に事前学習されたモデルが、事前学習タスク自体に「メタ過学習」してしまう可能性があり、事前学習タスクとは異なる新しいタスクへの適応が難しくなるためと考えられています。この結果は、ファインチューニングの際には、必ずしも最も学習が進んだチェックポイントを選ぶのが最適ではないという、実用上の重要な示唆を与えています。
6. Conclusion (結論)
この論文は、テキストからテキストへの回帰アプローチが、Googleの広範なコンピューティングクラスタシステムといった、複雑な産業環境における性能予測において非常に有効であることを実証しました。
本研究で提案されたエンコーダー・デコーダー型の回帰言語モデル(RLM)は、比較的低コストでシンプルでありながら、一般的な言語の事前学習に依存することなく、システムログや設定ファイルのようなリッチで非表形式の入力を直接学習できます。そして、非常に高精度な浮動小数点予測を返し、最小限の追加データで新しいタスクにも迅速に適応することが可能です。
最終的に、この研究は、RLMが生のテキストから数値結果を予測するための、強力で汎用的かつスケーラブルなツールであることを示しています。これにより、手動での特徴量エンジニアリングの負担が軽減され、複雑なシステムの「普遍的なシミュレータ」を構築するための新しい道が開かれます。さらに、RLMが多様な入力からの数値フィードバックを正確にモデル化する能力は、洗練された報酬モデルの開発の基礎となり、言語モデルのための強化学習における将来の研究を促進する可能性を秘めています。
まとめ
今回の論文では、大規模システムの性能予測という、これまで手動の特徴量エンジニアリングに大きく依存していた複雑な課題に対して、「テキストからテキストへの回帰」という斬新なアプローチが非常に有効であることを示しました。
特に、Googleの「Borg」システムでの具体的な成果は、この回帰言語モデル(RLM)が、非表形式の複雑なテキストデータを直接扱い、高い精度で数値予測を行い、さらには新しいタスクへも少ないデータで迅速に適応できるという、強力な汎用性を持つことを証明しています。AIエンジニアの皆さんにとっては、このようなモデルが、これまでボトルネックとなっていたデータ前処理の負担を軽減し、より効率的なシステム最適化やシミュレーションの実現に貢献する可能性を秘めている、という点が大きなポイントになるかと思います。
この研究は、複雑な現実世界のシステムの振る舞いを予測する「普遍的シミュレータ」の実現に向けた重要な一歩であり、今後のAIの応用分野に大きな影響を与えることでしょう。








