
はじめに
近年、AI分野では「基盤モデル(Foundation Models)」と呼ばれる、大規模なデータで事前学習されたモデルが様々な応用を牽引しています。これらのモデルのバックボーンとして広く使われているのが、TransformerアーキテクチャとそのAttentionメカニズムです。Attentionは、入力された系列(文章や音声、画像など)内のどこに注目すべきかを柔軟に判断できる強力なメカニズムで、複雑なデータをうまく扱えるという利点があります。
しかし、Transformerには大きな課題があります。それは、長い系列データを扱う際の計算効率です。Attentionメカニズムは、系列の長さに応じて計算量とメモリ使用量が二次関数的に増加してしまうため、非常に長いデータを扱うことがハード制約上難しくなります。この課題を解決するため、これまでにも様々な効率的なAttentionの改良版や、線形時間で計算可能なリカレントモデルなどが研究されてきました。ですが、これらの多くはTransformerの性能、特に言語のような情報密度の高いモダリティでAttentionに匹敵する性能を出すには至っていませんでした。
今回ご紹介する論文「Mamba: Linear-Time Sequence Modeling with Selective State Spaces」は、この課題に挑戦し、Transformerに匹敵あるいはそれ以上の性能を、系列長に対して線形な計算量で実現する新しいモデルアーキテクチャ「Mamba」を提案したものです。Mambaは、従来のAttentionや標準的なMLPブロックを使わず、独自に改良した「選択的ステートスペースモデル(Selective State Space Models)」をコアコンポーネントとしています。論文は2023年12月に発表され、その後2025年6月現在までMambaは様々な改良がなされ、多くのモデルに採用されています。
本稿では、では、このMambaがどのような技術で成り立っているのか、論文の内容に基づいて分かりやすく解説していきます。
引用元記事
- タイトル: Mamba: Linear-Time Sequence Modeling with Selective State Spaces
- 発行日: 2023年12月1日
- 著者: Albert Gu, Tri Dao
- URL: https://arxiv.org/abs/2312.00752
・あくまで個人の理解に基づくものであり、正確性に問題がある場合がございます。
必ず参照元論文をご確認ください。
・本記事内での画像は、上記論文より引用しております。
要点
- Mambaは、Transformerの効率性の課題、特に長い系列における二次関数的な計算量とメモリ使用量を解決することを目指している。
- 従来の効率的なモデルが言語のような情報密度の高いモダリティでTransformerに劣っていた原因として、文脈に基づいて必要な情報だけを選択的に伝播・忘却する「コンテンツベースの推論能力」が不足している点を論文は指摘している。
- Mambaの核心技術は「選択的ステートスペースモデル(Selective State Space Models; S6)」である。
- これは、入力データの内容に応じてモデルの内部パラメータ(特にΔ、B、C)を動的に変化させるメカニズムである。
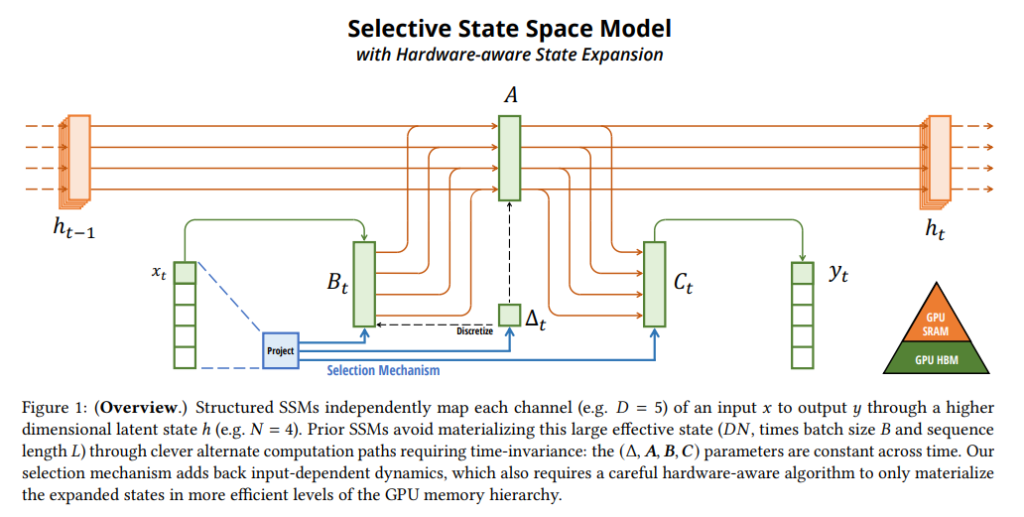
- パラメータが入力依存になると、従来の効率的な畳み込み計算が使えなくなる。これを解決するため、MambaはGPUのメモリ階層を考慮した「ハードウェア認識型並列スキャンアルゴリズム」を開発した。
- これにより、線形な計算量を維持したまま、効率的にモデルを学習・推論できる。
- Mambaアーキテクチャ自体は、この選択的ステートスペースモデルをベースにした、Attentionも標準的なMLPも含まないシンプルな構造である。
- 実験の結果、Mambaは言語モデリングにおいて、Transformerの性能に匹敵または凌駕し、同じサイズのTransformerより推論スループットが約5倍高速であり、メモリ効率も最適化されたTransformerと同等であることが示されている。
- さらに、音声やゲノムなど他のモダリティにおいても最先端の性能を達成し、100万トークンに及ぶ超長系列のデータでも性能が向上することが確認されている。
詳細解説
論文の構成に沿って解説します。
Abstract (要旨)
最近のAI技術、特に深層学習を用いたアプリケーションの多くは、「Transformer」を基盤としています。しかしTransformerは、特に長い文章や大量のデータを扱う際に、計算に非常に時間がかかってしまうという課題を抱えています。この課題を解決するために、計算時間を短縮する新しい仕組み(線形Attention、畳み込み、リカレントモデルなど)がこれまでも提案されてきました。しかし、これらの仕組みは、特に言葉を扱うような重要な分野では、Transformerほどの性能を発揮するには至っていませんでした。
論文では、これまでの効率的なモデルの弱点は、「文章の内容に応じて、どの情報が重要かを取捨選択する能力」が低いことにあると指摘しています。そこでMambaは、この弱点を克服するために新しいアプローチを取り入れました。具体的には、「SSM(State Space Model)」という仕組みをもとに、入力されるデータ(例えば、文章中の単語)に応じて変化させる「選択的SSM」という技術を開発しました。これにより、Mambaは「今注目している単語の種類」に応じて、過去の情報を記憶に残すべきか、あるいは忘れるべきかを柔軟に判断できるようになりました。
この「選択的」な仕組みは、それ自体では従来の高速計算テクニック(畳み込み演算など)の利用を難しくしてしまいます。しかしMambaは、コンピューターのハードウェア(特にGPU)の特性を最大限に活かした、新しい並列計算アルゴリズム(ハードウェア認識型並列スキャンアルゴリズム)を開発することで、この問題を解決し、高速な処理を可能にしました。
その結果生まれた「Mamba」は、Transformerの主要部品であるAttentionや、他のモデルでよく使われるMLPブロックといった複雑な部品を使わない、非常にシンプルな構造となっています。
Mambaの性能は非常に高く、Transformerと比べて処理速度(スループット)が5倍も高速です。また、扱うデータが長くなっても計算時間の増え方が緩やか(線形スケーリング)で、実際に100万語を超えるような非常に長いデータに対しても性能が向上することが確認されています。
Mambaは、言葉(言語)だけでなく、音声や遺伝子情報(ゲノム)といった様々な種類のデータに対しても、既存の最高レベルの性能を達成しています。特に言葉を扱うタスク(言語モデリング)においては、同じ規模のTransformerの性能を上回り、Mambaの半分のサイズでTransformerと同等の性能を示すほど、効率的かつ高性能なモデルであることが実証されています。
1 Introduction (はじめに)
基盤モデル(FMs)は現代の機械学習で効果的なパラダイムとして登場しました。そのバックボーンはしばしば系列モデルであり、言語、画像、音声、時系列、ゲノムなど様々なドメインの入力系列を扱います。特定のアーキテクチャに依存する概念ではありませんが、現在のFMは主にTransformerとAttentionに基づいています。
Attentionは文脈ウィンドウ内の情報を密にルーティングできる能力が有効ですが、これにより有限ウィンドウ外をモデル化できないこと、そしてウィンドウ長に対して二次関数的にスケーリングするという根本的な欠点を持ちます。これらの欠点を克服するために効率的なAttentionの変種が多数提案されてきましたが、Attentionを有効たらしめる特性を犠牲にすることが多く、大規模なドメインで経験的に有効であることがまだ示されていません。
近年、Structured State Space Sequence Models (SSMs) が系列モデリングの有望なクラスとして登場しました。これらは、リカレントニューラルネットワーク(RNN)と畳み込みニューラルネットワーク(CNN)を組み合わせたものとして解釈でき、古典的なState Space Modelから着想を得ています。SSMsは、系列長に対して線形またはほぼ線形のスケーリングで、リカレンスまたは畳み込みとして非常に効率的に計算できます。また、特定のデータモダリティでは長距離依存性をモデル化する原理的なメカニズムを持ち、Long Range Arenaなどのベンチマークで優位性を示しています。しかし、テキストのような離散的で情報密度の高いデータのモデリングでは効果が低いという課題がありました。
本論文では、既存の課題を複数の側面から改善した「選択的ステートスペースモデル(Selective State Space Models)」という新しいクラスを提案し、系列長に線形にスケーリングしながらTransformerのモデリング能力を達成します。
2 State Space Models (ステートスペースモデル)
Structured State Space Sequence Models (S4) は、深層学習向けの系列モデルの最近のクラスで、RNN、CNN、古典的なState Space Modelに広く関連しています。これらは、隠れ状態 \( h(t) \) を介して入力 \( x(t) \) から出力 \(y(t)\) へ写像する連続時間システムから着想を得ています。
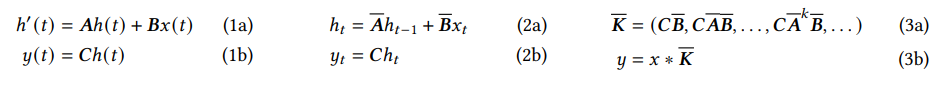
具体的には、S4モデルは4つのパラメータ (Δ, A, B, C) で定義され、連続パラメータ (Δ, A, B) を「離散化」というステップを経て「離散パラメータ」 (A, B) に変換します。この離散化されたパラメータを使って、モデルは線形リカレンス(式2a, 2b)またはグローバル畳み込み(式3a, 3b)として計算されます。
一般的には、効率的な並列化可能な学習のために畳み込みモード(式3)を使用し、効率的な自己回帰推論(入力が1ステップずつ与えられる場合)のためにリカレントモード(式2)に切り替えます。
リカレンス(式2a)や畳み込み(式3b)の重要な特性として、モデルのダイナミクスが時間にわたって一定であることがあります。これは「線形時間不変 (Linear Time Invariance; LTI)」と呼ばれ、リカレンスと畳み込みに深く関連しています。これまでのStructured SSMはすべてLTIでしたが、これは根本的な効率制約によるものでした。しかし、本研究の核心的な洞察は、LTIモデルが特定の種類のデータをモデル化する上で根本的な限界を持つことであり、技術的な貢献は効率性のボトルネックを克服しながらLTI制約を取り除くことにあります。
効率的な計算のため、Structured SSMでは行列Aに構造を課す必要があります。最も一般的な構造は対角構造であり、本論文でもこれを使用しています。この場合、A, B, C行列は少ないパラメータで表現できます。ただし、入力系列の各チャンネルに独立に適用されるため、隠れ状態の合計次元は入力ごとに D * N となり、系列全体での計算は O(BLDN) 時間とメモリを必要とします。これが Section 3.3 で取り組む効率性のボトルネックの根源です。
ここでいうNは「状態空間次元」と呼ばれ、SSMが過去の情報を圧縮して保持する隠れ状態の次元に関わる重要なパラメータです。Dはモデルのチャンネル数(特徴次元)を示します。TransformerのAttentionは、過去のすべてのキーと値をメモリに保持する必要があるため、系列長Lに対してメモリが\(O(LD)\)か \(O(L^2H) \)(Hはヘッド数)のように増加し、計算量も \( O(L^2D) \) または \( O(L^2HD_head) \) のように増加します。一方、従来のリカレントモデルは固定長の隠れ状態(例えば \( O(D) \) )で過去を要約するため、メモリは \( O(D) \) 、計算量は \( O(LD) \) と線形になります。SSMは、状態空間次元Nを大きくすることで、従来のRNNより多くの情報を保持しつつ、線形または効率的な計算を可能にする仕組みです。
3 Selective State Space Models (選択的ステートスペースモデル)
選択性メカニズムは、合成タスクからの直感を基に動機づけられ(Section 3.1)、それをステートスペースモデルに組み込む方法(Section 3.2)が説明されています。結果として得られる時間可変SSMは畳み込みを使用できなくなるため、効率的に計算するための技術的課題が生じます。これを、現代のハードウェア(GPU)のメモリ階層を利用したハードウェア認識型アルゴリズムで克服しています(Section 3.3)。
3.1 Motivation: Selection as a Means of Compression (動機:圧縮手段としての選択性)
系列モデリングの根本的な問題は、文脈をより小さな状態に圧縮することだと論文は主張します。TransformerのAttentionは文脈を全く圧縮しないため効果的ですが、効率が悪いです。自己回帰推論では文脈全体(KVキャッシュ)を明示的に保存する必要があり、これがTransformerの遅い線形時間推論と二次関数的学習を引き起こします。一方、リカレントモデルは有限の状態を持つため効率的ですが、その有効性は状態が文脈をどれだけうまく圧縮したかに依存します。
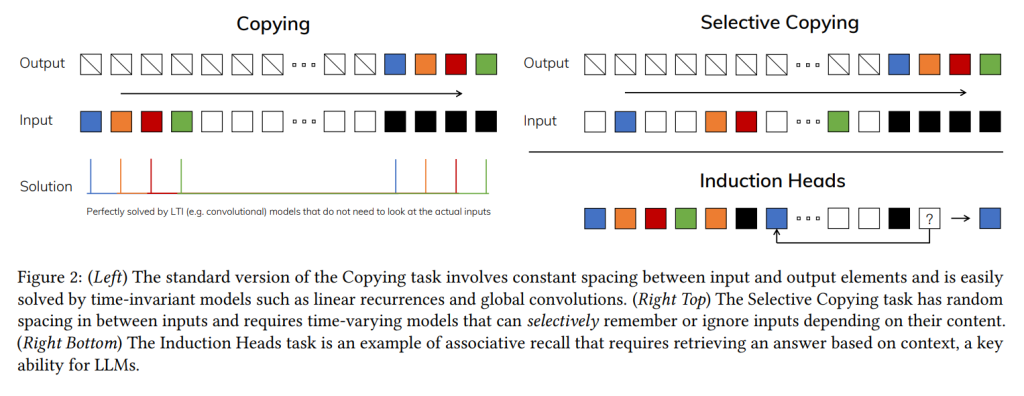
この原理を理解するため、論文はSelective CopyingタスクとInduction Headsタスクという2つの合成タスクを例に挙げます。Selective Copyingは、記憶すべきトークンの位置が変化するため、内容認識的な推論が必要です。Induction Headsは、LLMのインコンテキスト学習能力を説明すると仮説されているメカニズムであり、文脈認識的な推論が必要です。
これらのタスクは、LTIモデルの失敗モードを明らかにします。リカレントな観点では、その一定のダイナミクスは文脈から正しい情報(入力)を選択したり、隠れ状態を文脈依存的に変化させたりできません。畳み込みの観点では、静的な畳み込みカーネルでは Selective Copying のように入力間の間隔が変化するタスクをモデル化することが難しいとされています。
まとめると、系列モデルの効率性と有効性のトレードオフは、状態をどれだけうまく圧縮するかに特徴づけられます。効率的なモデルは小さな状態を持つ必要がありますが、有効なモデルは文脈からの必要な情報をすべて含む状態を持つ必要があります。したがって、系列モデル構築の基本的な原則は「選択性」であると提案しています。つまり、系列的な状態への入力に注目したりフィルターしたりする、文脈認識的な能力です。
3.2 Improving SSMs with Selection (選択性によるSSMの改善)
モデルに選択性メカニズムを組み込む一つの方法は、系列に沿った相互作用に影響するパラメータ(例えばRNNのリカレントダイナミクスやCNNの畳み込みカーネル)を入力依存にすることです。

論文中の Algorithm 2 は、この主要な選択性メカニズムを示しています。主な違いは、いくつかのパラメータ(Δ、B、C)を入力の関数にしたことです。これにより、これらのパラメータが系列長次元Lを持つことになり、モデルは時間不変から時間可変に変化します。この変更により、畳み込み(式3)との等価性が失われ、効率性に影響が出ます。
具体的には、B、C、Δは入力 \( x \) に線形変換 \( s(x) \) を適用し、Δには非線形関数 \( \tau_Δ (softplus)\) を適用することで入力依存にしています。特にΔの選択は、Section 3.5で議論されるRNNのゲーティングメカニズムとの関連によるものです。
3.3 Efficient Implementation of Selective SSMs (選択的SSMの効率的な実装)
畳み込みやAttentionのようなハードウェアフレンドリーなプリミティブは広く使われています。Mambaは選択的SSMを現代のハードウェア(GPU)で効率的に動作させることを目指しています。選択性メカニズム自体は自然なものですが、入力依存のパラメータは計算効率の課題を生じさせます。S4およびその派生モデルは、この理由から効率性のためにLTI(非選択的)モデル、最も一般的にはグローバル畳み込みの形式を使用してきました。
時間可変SSMはもはや畳み込みと等価ではないため、並列連想スキャン(parallel associative scan)を活用します。SSMスキャンは理論的には効率的( \( O(BLDN) FLOPs \) 、Lに対して線形)ですが、選択的SSMを使った基盤モデルの学習には、現代のハードウェアでも効率的である必要があります。Mambaはカーネルフュージョンと再計算(recomputation)を使用して、SSMスキャンを高速かつメモリ効率的にしています。
なお、GPUには階層的なメモリがあります。高速で容量が小さいSRAM(Static Random-Access Memory)と、低速だが大容量のHBM(High-Bandwidth Memory)です。HBMは一般的に「GPUメモリ」として認識される主メモリです。計算速度はメモリ間のデータ転送速度(メモリ帯域幅)に制約されることが多いです。従来の方式では、リカレンス計算に必要な中間状態(サイズ BLDN)を一度HBMに書き出し、次のステップでまた読み出す必要があり、これがボトルネックでした。
効率的な実装の主眼は、中間状態 h を高速なメモリ階層(SRAM)内でのみ具現化し、低速なHBMへのIOアクセスを避けることです。具体的には、SSMパラメータ(Δ, A, B, C)を低速なHBMから高速なSRAMに直接読み込み、SRAM内で離散化とリカレンスを実行し、最終出力のみをHBMに書き戻します。これにより、IO回数を状態次元Nの係数だけ削減し、実際には20〜40倍の高速化を実現しています。
シーケンス長LがSRAMに収まらないほど長い場合は、シーケンスをチャンクに分割し、各チャンクでフューズドスキャンを実行します。中間スキャン状態があれば、次のチャンクでスキャンを継続できます。
さらに、バックプロパゲーションに必要な中間状態を保存しないことで、メモリ使用量を削減します(再計算)。中間状態は保存されず、バックワードパスで入力がHBMからSRAMにロードされるときに再計算されます。結果として、フューズド選択的スキャン層は、FlashAttentionを使用した最適化されたTransformer実装と同等のメモリ要件を持ちます。
3.4 A Simplified SSM Architecture (簡略化されたSSMアーキテクチャ)
Structured SSMと同様に、選択的SSMもニューラルネットワークに柔軟に組み込める単独の系列変換器です。H3アーキテクチャは多くのSSMアーキテクチャの基盤であり、一般的に線形Attentionから着想を得たブロックとMLPブロックをインターリーブ(交互に配置)した構成です。Mambaは、これらの2つのコンポーネントを1つに組み合わせることでアーキテクチャを簡略化し、それを均一に積み重ねる設計にしています。これはAttentionで同様の試みを行ったGAU (Gated Attention Unit) にインスパイアされています。
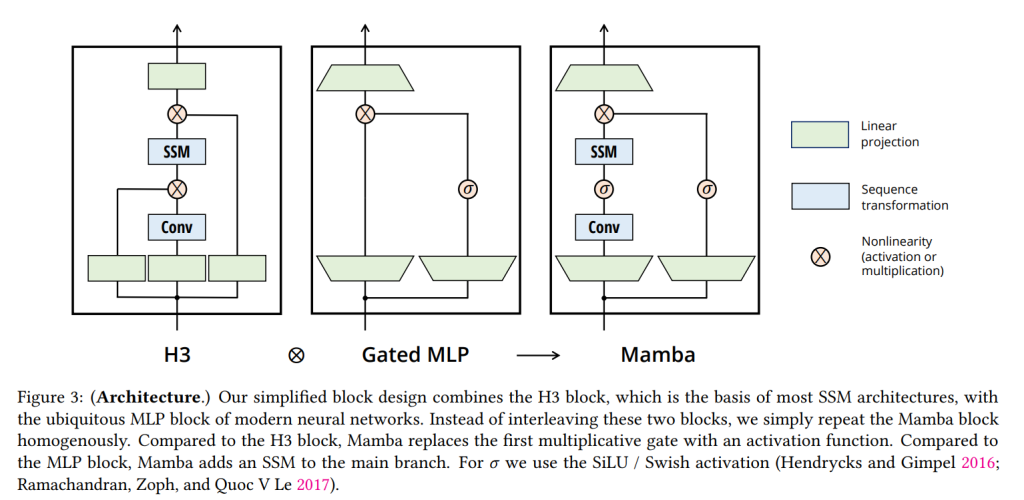
このアーキテクチャでは、モデルの次元Dを拡張係数E(実験ではE=2に固定)で拡張します。各ブロックにおいて、ほとんどのパラメータ( \( 3ED^2 \) )は線形射影にあり、内側のSSMのパラメータはそれに比べてはるかに小さいです。このブロックを正規化層(LayerNorm)や残差接続と組み合わせて繰り返すことで、Mambaアーキテクチャを形成します。活性化関数にはSiLU/Swishを使用しています。
3.5 Properties of Selection Mechanisms (選択性メカニズムの特性)
選択性メカニズムは、より伝統的なRNNやCNN、あるいは他のパラメータ(例えば Algorithm 2 のA)、または異なる変換関数 \( s(x) \) を使用するなど、様々な方法で適用できるより広い概念です。
3.5.1 Connection to Gating Mechanisms (ゲーティングメカニズムとの関連)
最も重要な関連として、RNNの古典的なゲーティングメカニズムが、SSMに対する選択性メカニズムの一例であることが挙げられます。これは連続時間システムの離散化と関連があり、特に定理1に示すように、状態空間次元N=1などの特定の条件下で、選択的SSMのリカレンスがゲーティング付きRNN(式5)の形を取ることが示されています。これにより、SSMのΔはRNNのゲーティングメカニズムを一般化した役割を果たすと見なせます。
3.5.2 Interpretation of Selection Mechanisms (選択性メカニズムの解釈)
選択性による3つのメカニズム的効果が説明されています。
- Variable Spacing (可変的な間隔): 選択性により、関心のある入力間に現れる無関係なノイズトークンをフィルタリングできます。これは Selective Copying タスクで実証されますが、離散的なデータで遍在します。例えば、ゲーティング付きRNNの場合、入力 \( x_t \) を完全に無視する必要がある場合(ゲーティング値 \( g_t \to 0 \) の時など)に発生します。
- Filtering Context (文脈のフィルタリング): 多くの系列モデルは文脈が長くなっても性能が向上しないことが経験的に観察されています。これは、多くのモデルが必要なときに無関係な文脈を効果的に無視できないためです。選択的モデルは状態をリセットして余計な履歴を削除でき、したがって原理的には文脈長とともに性能が単調に向上します。
- Boundary Resetting (境界のリセット): 複数の独立した系列が結合されている設定で、Transformerは特定のAttentionマスクでそれらを分離できますが、LTIモデルは系列間で情報が漏れます。選択的SSMは、境界で状態をリセットすることも可能です(例えば \( \Delta_t \to \infty \)の時)。これはデータセットを効率的に扱うための人工的な結合(ドキュメントのパッキング)や自然な境界(強化学習のエピソード境界)で発生します。
各選択的パラメータの解釈も述べられています。
- Δの解釈: Δは、現在の入力\( x_t \) にどれだけ注目するか、無視するかのバランスを制御します。これはRNNゲートを一般化したものです。メカニズム的には、大きなΔは状態 \( h \) をリセットして現在の入力に注目し(選択して現在の状態を忘れる)、小さなΔは状態を保持して現在の入力を無視します。SSMのΔは連続時間システムのタイムステップとしても解釈でき、大きなΔは現在の入力に長く注目し、小さなΔは無視される一時的な入力と見なせます。
- Aの解釈: Aパラメータも選択的になり得ますが、最終的には \( \mathcal{A} = \exp(\Delta A) \)(離散化式4)を介してΔとの相互作用を通じてのみモデルに影響します。したがって、Δの選択性で (A, B) の選択性を確保するのに十分であり、これが改善の主な源です。
- BとCの解釈: SSMにおいて、BとCを選択的にすることは、入力 \( x_t \) を状態 \( h_t \) に、あるいは状態を出力 \( y_t \) に流すかどうかのより細かい制御を可能にします。これらは、モデルがコンテンツ(入力)と文脈(隠れ状態)に基づいてリカレントダイナミクスを調整できるようにすると解釈できます。
3.6 Additional Model Details (その他のモデル詳細)
Real vs. Complex (実数 vs 複素数)
以前のSSMは多くの場合、知覚モダリティで性能を発揮するために複素数を使用していました。しかし、テキストやDNAのような離散モダリティでは完全に実数のSSMでも十分に機能し、場合によってはより優れていることが経験的に観察されています。Mambaではデフォルトで実数値を使用しています。
Initialization (初期化):
以前のSSMは特別な初期化(特に複素数ケース)を推奨していましたが、MambaではS4D-Realのようなシンプルな実数値対角初期化やランダム初期化でもうまく機能することが示されています。
Parameterization of Δ (Δのパラメータ化):
Δを選択的に調整するために、入力の線形射影を使用しています。実験では、入力の次元を1次元に射影するだけでも大きな性能向上が見られましたが、さらに次元を増やすことで modest な改善が得られました。
4 Empirical Evaluation (評価)
論文の実験セクションでは、Mambaの様々なタスクでの性能が評価されています。
- Synthetic Tasks (合成タスク): Selective Copyingタスクでは、Mamba(選択的SSMを使用)が他のゲーティング付きアーキテクチャや非選択的SSMよりも大幅に優れた性能を示し、ほぼ完璧に解決しています。Induction Headsタスクでは、Mambaはトレーニング時の系列長(256)の4000倍以上(100万トークン以上)に完璧に外挿できることを示しており、これは他のモデルでは達成できていません。
- Language Modeling (言語モデリング): The Pileデータセットでのスケーリング法則の実験では、MambaはTransformer++と呼ばれる強力なTransformerのレシピに匹敵する性能を、他の注意機構を持たないモデルよりも良くスケーリングすることを示しています。特に長い系列長(8192)で優位性が見られます。ゼロショット評価タスク(LAMBADA, HellaSwag, PIQA, ARC, WinoGrandeなど)では、Mambaは同じサイズの他のオープンソースモデル(Pythia, RWKV)を凌駕し、多くの場合2倍大きいモデルの性能に匹敵または超えています。
- DNA Modeling (DNAモデリング): HG38データセットでの事前学習において、MambaはモデルサイズのスケーリングでHyenaDNAやTransformer++より効率的であり、さらに系列長のスケーリングでは100万トークンまで性能が向上することを示しています。一方、HyenaDNAは系列長が長くなると性能が悪化しました。これは選択性メカニズムがノイズを無視する能力によるものです。困難な合成分類タスク(5つの類人猿種のDNA分類)では、Mambaは長い系列でHyenaDNAよりも顕著に高い精度を達成しています。
- Audio Modeling and Generation (音声モデリングと生成): YouTubeMixデータセットでの音声波形事前学習では、Mamba(複素数パラメータ化)はSaShiMi(S4+MLP)よりも性能が向上し、特に長い系列長で差が広がりました。SC09データセットでの自己回帰音声生成では、Mambaは最先端のGANや拡散ベースのモデルをも凌駕する生成品質を達成しています。
- Speed and Memory Benchmarks (速度とメモリベンチマーク): MambaのコアであるSSMスキャン操作は、2Kトークンを超える系列長でFlashAttention-2よりも高速であり、標準的なPyTorchスキャン実装より20〜40倍高速です。推論スループットは、TransformerがKVキャッシュを持つ必要があるのに対し、Mambaはリカレントモデルとしてより大きなバッチサイズを利用できるため、同じサイズのTransformerより4〜5倍高くなっています。Mambaのメモリ使用量は、FlashAttention-2を使用した最適化されたTransformer実装と同等であることが示されています。
- Model Ablations (モデルアブレーション): 様々なMambaの構成要素に関する詳細な実験が行われています。選択的パラメータ(特にΔ)が最も重要であり、BとCの選択性を組み合わせることで相乗効果が得られることが示されています。SSMの状態次元Nを増やすことは、BとCも選択的である場合に限り、無視できるパラメータ/FLOPsのコストで性能を大幅に向上させることが確認されており、これは論文の主要な動機を裏付けています。
5 Discussion (議論)
論文では、関連研究、限界、および今後の方向性について議論しています。
No Free Lunch: Continuous-Discrete Spectrum (フリーランチなし:連続-離散スペクトル): Structured SSMは元々連続システムを離散化したもので、音声や動画のような連続的なデータモダリティに強い誘導バイアスを持っていました。Mambaの選択性メカニズムは、テキストやDNAのような離散モダリティにおける弱点を克服しますが、逆にLTI-SSMが得意とするデータでの性能を妨げる可能性もあります。
Downstream Affordances (下流タスクへの適応性): TransformerベースのFM、特にLLMには、ファインチューニング、プロンプティング、インコンテキスト学習、RLHF、量子化など、事前学習済みモデルとの豊かな相互作用のエコシステムがあります。MambaのようなTransformerの代替が、同様のプロパティと適応性を持つかどうかを調査することに興味が持たれています。
Scaling (スケーリング): 本論文の評価は、ほとんどの強力なオープンソースLLM(例: Llama)や他のリカレントモデル(RWKV, RetNet)が評価されている7Bパラメータスケールより小さなモデルサイズに限定されています。Mambaがこれらのより大きなサイズでも依然として有利であるかどうかを評価する必要があります。また、SSMのスケーリングには、本論文で議論されていない更なるエンジニアリング上の課題やモデルの調整が含まれる可能性があることにも注意が必要です。
6 Conclusion (まとめ)
本論文は、structured state space modelに選択性メカニズムを導入し、コンテキスト依存の推論を可能にしながら、系列長に線形にスケーリングするMambaモデルを提案しています。Attentionフリーのシンプルなアーキテクチャに組み込まれたMambaは、多様なドメインで最先端の結果を達成し、強力なTransformerモデルの性能に匹敵またはそれを超えています。
選択的ステートスペースモデルは、ゲノム、音声、動画など、長い文脈を必要とする新しいモダリティを含む、異なるドメイン向けの基盤モデルを構築するための広範な応用が期待されます。Mambaは、一般的な系列モデルのバックボーンとなる強力な候補であることが示唆されています。
まとめ
Mambaは、State Space Modelに「選択性」という概念を取り入れ、入力データの内容に応じてモデルの振る舞いを動的に変化させることで、Transformerの持つコンテキスト依存の強力なモデリング能力を獲得しました。同時に、ハードウェア効率を追求した新しいアルゴリズムによって、Transformerの弱点であった長い系列に対する計算効率を大幅に改善し、系列長に対して線形のスケーリングを実現しています。
言語、音声、ゲノムといった多様なモダリティでの実験は、Mambaが既存の最先端モデル、特にTransformerに匹敵またはそれを上回る性能を示し、特に長い系列データを扱う能力に優れていることを強力に示唆しています。推論速度やメモリ効率の面でも大きな利点があり、今後の基盤モデル研究における重要な方向性を示すものと言えるでしょう。
特に長い系列やリアルタイム処理が求められるアプリケーションにおいて、MambaはTransformerに代わる強力な選択肢となる可能性を秘めています。現在、MambaがTransformerに代わるほどとはいえませんが、改良が重ねられており、今後の発展を注視していく必要があります。








