はじめに
近年、大規模言語モデル(LLM)の分野では、パラメータ数を競うように巨大化が進み、その能力は目覚ましい進化を遂げてきました。しかしその一方で、巨大モデルの運用には膨大な計算資源とコストが必要となり、誰もが容易に利用できるわけではないという課題も顕在化しています。こうした背景から、より軽量で効率的でありながら、特定のタスクにおいては大規模モデルに匹敵する、あるいは凌駕する性能を持つ小型言語モデル(SLM: Small Language Model)への関心と需要が急速に高まっています。
特に、人間のような「推論能力」、すなわち複雑な問題を段階的に分解し、論理的に思考して結論を導き出す能力は、AIにとって長年の課題でした。この高度な認知能力を、リソースの限られた環境でも実現しようとする試みの中で、Microsoft社は「教科書品質」のデータに焦点を当てた独自の開発アプローチにより、小型でありながら高い能力を持つPhiシリーズを生み出してきました。
そして今回、そのPhiシリーズにおける推論能力の追求が一つの到達点として結実したのが、高度な推論タスクに特化した「Phi-4 Reasoning」モデルファミリーです。この新しいモデル群は、SLMの可能性を新たな次元へと引き上げるものとして、大きな注目を集めています。
本稿では、この革新的なPhi-4 Reasoningモデルファミリー(Phi-4-reasoning, Phi-4-reasoning-plus, Phi-4-mini-reasoning)について、その技術的な特徴、学習戦略、応用可能性、そして利用する上での重要なポイントを解説します。特に、なぜ小型モデルで複雑な推論が可能になるのか、その根幹にある技術や、エッジデバイスへの展開を現実のものとする最適化技術に焦点を当て、その仕組みと意義を明らかにしていきます。
引用元記事
- タイトル: Make Phi-4-mini-reasoning more powerful with industry reasoning on edge devices
- 発行元: Microsoft Tech Community
- 発行日: 2025年5月1日
- URL: https://techcommunity.microsoft.com/blog/azuredevcommunityblog/make-phi-4-mini-reasoning-more-powerful-with-industry-reasoning-on-edge-devices/4409764
HuggingFace
- タイトル: Phi-4-reasoning Model Card
- 発行元: Hugging Face (Microsoft)
- URL: https://huggingface.co/microsoft/Phi-4-reasoning
- タイトル: Phi-4-mini-reasoning Model Card
- 発行元: Hugging Face (Microsoft)
- URL: https://huggingface.co/microsoft/Phi-4-mini-reasoning
Blog
- タイトル: One year of Phi: Small language models making big leaps in AI
- 発行元: Microsoft Azure Blog
- 発行日: 2025年4月30日
- URL: https://azure.microsoft.com/en-us/blog/one-year-of-phi-small-language-models-making-big-leaps-in-ai/
Paper
- タイトル: Phi-4-reasoning Technical Report
- 発行日: 2025年4月30日
- URL: https://arxiv.org/abs/2504.21318
GoogleColab(弊社作成)
https://colab.research.google.com/drive/1-z_Sd47YXl0a31nZMbNZ1TrsmDv7lK5K?usp=sharing
要点
- 驚異的な推論能力を持つ小型モデル: Phi-4 Reasoningファミリーは、14B(140億)パラメータのPhi-4-reasoningおよびPhi-4-reasoning-plusと、さらに小型な3.8B(38億)パラメータのPhi-4-mini-reasoningから構成されます。これらのモデルは、そのパラメータサイズからは想像できないほど高い推論能力を、特に数学オリンピックレベルの難問や複雑な論理的推論タスクにおいて発揮します。これは、AIの応用範囲を大きく広げる可能性を秘めています。
- 推論能力に特化した学習戦略: 単純な知識の記憶ではなく、「考えるプロセス」そのものを学習させるため、高品質な合成データ、思考プロセスを明示した思考連鎖(Chain-of-Thought: CoT)データセット、そして強化学習(RL)といった技術を駆使しています。これにより、多段階の分解や内省、試行錯誤を伴う複雑なタスクを効果的に解く能力を獲得しています。
- エッジデバイスへの展開可能性: モデル量子化技術(Microsoft OliveやApple MLXフレームワークを利用)を適用することで、モデルのサイズと計算コストを劇的に削減できます。これにより、従来はクラウド環境が必須だった高度なAI推論を、IoTデバイス、スマートフォン、ラップトップなどのエッジデバイス上で直接実行することが現実的になります。これは、低遅延、オフライン動作、プライバシー向上といった多くの利点をもたらします。
- 特定ドメインへの高度な適応能力: LoRA(Low-Rank Adaptation)のような効率的なファインチューニング手法を用いることで、比較的少ない計算コストでモデルを特定の業界やタスク(例:医療診断支援、金融リスク分析、法律文書の解釈など)に特化させることが可能です。これにより、汎用モデルをベースに、特定のニーズに合致した高精度なカスタム推論AIを構築できます。
- 開発者に優しい多様な利用環境: モデルはAzure AI FoundryやHugging Faceを通じて容易にアクセス可能です。また、Transformersライブラリ、ONNX Runtime、Apple MLXなど、主要なフレームワークやライブラリでサポートされており、既存の開発ワークフローにスムーズに統合できます。OllamaやLM Studioといったツールも利用可能で、開発者は自身の環境や好みに合わせて最適な方法を選択できます。
詳細解説
0. 前提知識の補足
Phi-4 Reasoningモデルファミリーを理解する上で重要な技術について、補足します。(理解が十分である方は、飛ばしても問題ありません。)
- SLM (Small Language Model): パラメータ数が数十億から百数十億程度の、比較的小規模な言語モデルを指します。数百億〜数兆パラメータを持つLLM(大規模言語モデル)と比較して、学習や推論に必要な計算資源が格段に少なく、特定のタスクにおいてはデータ品質や学習戦略の工夫によりLLMに匹敵、あるいはそれを超える性能を発揮することが示されています。PhiシリーズはこのSLMの代表例であり、AIの民主化と応用範囲の拡大に貢献します。
- Transformer: 2017年にGoogleから発表されたニューラルネットワークアーキテクチャであり、現在のLLMやSLMのほぼ全ての基盤となっています。最大の特徴はAttention(注意)機構であり、入力シーケンス(文章など)内の各要素(単語など)が、他のどの要素と関連が深いかを動的に計算し、重み付けすることができます。これにより、文脈に応じた柔軟な情報処理が可能となり、特に長距離の依存関係を持つ言語の理解や、論理的な思考プロセスのモデル化に適しています。
- Chain-of-Thought (CoT): 複雑な推論問題を解く際に、最終的な答えだけでなく、そこに至るまでの中間的な思考ステップを言語モデル自身に生成させるプロンプティング手法、またはそのような思考ステップを含むデータセットを指します。これにより、モデルは問題をより小さなステップに分解して考えることを学習し、推論の正確性が大幅に向上することが知られています。Phi-4 Reasoningの学習において中心的な役割を果たしています。
- Quantization (量子化): AIモデルの推論効率を高めるための重要な最適化技術です。モデルの重みや活性化値を、より少ないビット数(例: 4ビット整数)で表現することにより、モデルサイズを劇的に削減し、推論速度を向上させ、消費電力を削減します。エッジデバイスのようにリソースが限られた環境へのAIモデル展開を可能にする鍵となります。Microsoft OliveやApple MLXは、この量子化プロセスを自動化・最適化するツールです。
- Fine-tuning (ファインチューニング): 大規模なデータセットで事前学習された汎用的なモデル(Foundation Model)を、特定のタスクやドメインに特化したデータセットで追加学習させるプロセスです。これにより、モデルの性能を特定の目的に合わせて最適化・向上させることができます。
- SFT (Supervised Fine-tuning): 正解ラベル付きのデータを用いて教師あり学習を行う手法。
- RLHF (Reinforcement Learning from Human Feedback): 人間のフィードバックを報酬シグナルとして利用し、強化学習によってモデルの挙動を望ましい方向(例:より役立つ、無害な応答)に誘導する手法。
- DPO (Direct Preference Optimization): 良い応答と悪い応答のペアデータから直接的にモデルの嗜好を学習する手法。
- LoRA (Low-Rank Adaptation): 元のモデルの大部分を凍結し、少数の追加パラメータのみを学習することで、計算コストを大幅に削減する効率的なファインチューニング手法。Phi-4 Reasoningのカスタマイズにおいて重要な技術です。
- ONNX (Open Neural Network Exchange): Facebook (現Meta) とMicrosoftによって開発された、AIモデルのためのオープンな標準フォーマットです。PyTorch, TensorFlow, Kerasなど、異なるディープラーニングフレームワークで訓練されたモデルを共通の形式で表現し、相互に利用したり、ONNX Runtimeのような共通の推論エンジンで実行したりすることを可能にします。モデルの共有、再利用、クロスプラットフォーム展開を促進する上で不可欠な技術であり、特にOliveによる最適化モデルの出力形式として利用されます。
- Edge Computing: クラウド上の集中型サーバーではなく、データが生成される現場(センサー、カメラ、スマートフォン、自動車など)やその近くに配置されたデバイス(エッジデバイス)でデータ処理を行うコンピューティングパラダイムです。リアルタイム性(低遅延)、ネットワーク帯域幅の節約、オフライン動作の実現、データプライバシーの向上といった利点があり、IoT、スマートファクトリー、自動運転など、多くの分野で重要性が増しています。Phi-4-mini-reasoningのような高性能SLMの登場と量子化技術の進展により、エッジデバイス上で実行できるAIアプリケーションの可能性が大きく広がっています。
1. Phi-4 Reasoningモデルファミリーとは? – 推論特化SLMの新境地
Phi-4 Reasoningモデルファミリーは、MicrosoftがSLM研究開発において長年培ってきた知見と、「データ品質こそがモデル能力を決定づける」という哲学に基づき開発された、Phiシリーズの最新世代です。その最大の特徴は、単なる言語理解や生成能力にとどまらず、人間が行うような複雑な「推論(Reasoning)」能力に徹底的にフォーカスしている点にあります。従来のLLMが巨大化によって汎用的な能力を獲得してきたのに対し、Phi-4 Reasoningは「小型・軽量」でありながら「深い思考」を可能にすることを目指しています。
- Phi-4-reasoning (14B): このモデルは、Phiシリーズの14Bパラメータモデル「Phi-4」を基盤としています。その上で、OpenAIのo3-miniモデルなどから得られた、思考プロセスが詳細に記述された高品質な推論データ(CoTトレース)を用いて、教師ありファインチューニング(SFT)が施されています。この学習により、数学の問題解決、論理パズル、科学的推論、コード生成におけるアルゴリズム的思考など、複雑な推論が求められるタスクにおいて、自身の5倍以上のパラメータを持つモデル(例: DeepSeek-R1 Distill Llama 70B)をも上回る性能を示すことが報告されています。これは、モデルサイズと性能の関係性において、データ品質と学習戦略がいかに重要であるかを示す好例と言えます。
- Phi-4-reasoning-plus (14B): Phi-4-reasoningの能力をさらに引き出すために、強化学習(RL)による追加学習が行われたモデルです。推論を行う際により多くの計算資源(具体的には、Phi-4-reasoningの約1.5倍のトークン)を費やして思考を深めるように訓練されており、その結果として、より高い精度と信頼性を実現しています。これは、時間的制約が比較的緩い状況で、最大限の推論精度を追求したい場合に適した選択肢となります。
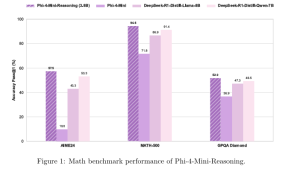
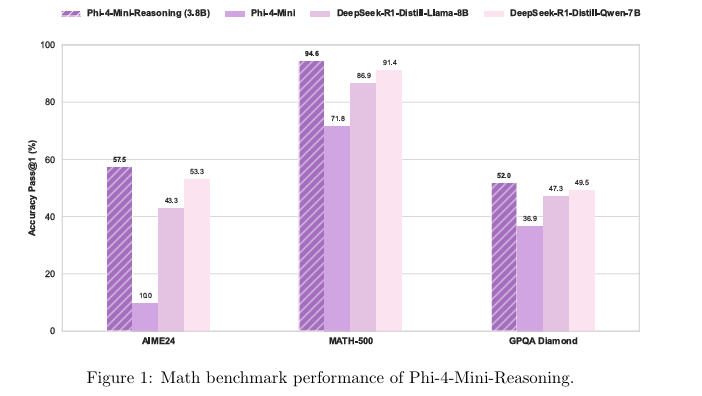
- Phi-4-mini-reasoning (3.8B): このモデルは、「推論能力」と「極限までの小型化」という二つの要求に応えるために設計されました。パラメータ数はわずか3.8Bと非常に小さいながらも、数学的推論に特化して最適化されています。学習には、より高性能なモデルであるDeepseek-R1によって生成された膨大な量の合成数学データ(100万問以上、約300億トークン)が用いられました。特筆すべきは、128kトークンという非常に長いコンテキスト長をサポートしている点です。これにより、複数ステップにわたる複雑な証明問題や、長文の応用問題など、問題全体を俯瞰し、長期的な依存関係を捉えながら推論を進めることが可能になります。計算資源や応答速度(レイテンシ)が厳しく制限されるエッジデバイスやモバイルアプリケーションでの利用において、理想的な選択肢となるでしょう。教育用アプリ、組み込み型チューターシステム、オフライン環境でのインテリジェント機能などに大きな可能性を秘めています。
これらのモデル群は、単に問題を解くだけでなく、なぜその結論に至ったのかという思考プロセス(Reasoning Chain)を生成する能力に長けており、AIの判断根拠の透明性を高める上でも重要な意味を持ちます。
2. 高度な推論能力を支える技術 – データ、学習、アーキテクチャの融合
Phi-4 Reasoningモデルが、その比較的小さなサイズにも関わらず、なぜこれほど高度な推論能力を発揮できるのでしょうか? その秘密は、革新的な学習データ戦略、推論に最適化された学習手法、そして効率的なモデルアーキテクチャの三位一体にあります。
- 高品質な学習データ:「教科書品質」とその先へ: MicrosoftのPhiシリーズ開発における一貫した哲学は、「データの質は量に勝る」というものです。初期のPhiモデルでは、Webからフィルタリングされた「教科書レベル」の高品質なテキストと合成データが用いられ、これが小型モデルでも高い言語能力と基本的な推論能力を獲得する基盤となりました。Phi-4 Reasoningでは、このアプローチをさらに推し進め、推論能力の獲得に特化したデータが大量に投入されています。
- 思考連鎖(Chain-of-Thought: CoT)データ: これは、単に問題と答えのペアだけでなく、「どのように考えてその答えに至ったか」という思考プロセスを段階的に記述したデータです。例えば、「リンゴが5個あり、3個もらうと合計何個?」という問題に対し、「最初に5個あった。次に3個もらった。足し算をすればよい。5 + 3 = 8。答えは8個。」といった思考ステップを含むデータです。モデルにCoTデータを学習させることで、複雑な問題を解く際に、人間のように段階的に思考を進める能力を模倣させ、推論精度を向上させることができます。
- 合成データ: 特にPhi-4-mini-reasoningの学習では、Deepseek-R1のような非常に高性能な大規模モデルを用いて、大量の数学問題とそのCoT形式の解答を自動生成(合成)しています。この合成データを用いることで、多様かつ難易度の高い推論タスクを網羅的に学習させることが可能になります。ただし、合成データの品質管理は非常に重要であり、誤った推論パターンを学習させないよう、生成された解答の正しさを検証するプロセス(例:複数の解答をサンプリングし、正解のみを採用)が不可欠です。
- 推論に特化したファインチューニング手法: 高品質なデータを最大限に活かすため、複数の先進的な学習手法が組み合わされています。
- SFT (Supervised Fine-tuning): CoTデータなどを用いて、モデルが望ましい思考プロセスと解答を出力するように直接的に教師あり学習を行います。Phi-4-reasoningでは、応答を思考プロセスを記述する<think>セクションと最終解答を示す<solution>セクションに構造化するように学習させており、これにより推論過程の可読性と検証可能性を高めています。
- RLHF (Reinforcement Learning from Human Feedback) / RL: 人間が評価した応答の良し悪しや、特定のルール(例:数学的な正しさ)に基づいてモデルに報酬を与え、より良い応答を生成するように強化学習を行います。Phi-4-reasoning-plusでは、RLを用いて推論時により多くの計算を行うことで精度を高めるように学習されています。
- DPO (Direct Preference Optimization): RLHFの代替または補完として注目される手法で、良い応答と悪い応答のペアデータから、モデルが良い応答をより好むように直接的に学習させます。Phiシリーズの安全性向上などにも活用されています。
- 効率化されたアーキテクチャ: モデルの基盤となるTransformerアーキテクチャ自体も、効率と性能を高めるために改良されています。Phi-4 Mini(Reasoningモデルのベース)では、Phi-3.5 Miniと比較して以下の点が改善されました。
- 語彙サイズ拡張 (200K): より多くの単語や記号を直接扱えるように語彙サイズが拡張され、特に数学記号や専門用語の表現能力が向上している可能性があります。
- Grouped-Query Attention (GQA): 標準的なMulti-Head Attention (MHA) と Multi-Query Attention (MQA) の中間的な手法で、推論時のメモリ帯域幅を削減し、推論速度を向上させる効果があります。
- 入出力埋め込みの共有: 入力単語と出力単語の埋め込み層を共有することで、モデルのパラメータ数を削減し、学習効率を高めます。
これらの要素が複合的に作用することで、Phi-4 Reasoningモデルは、限られたパラメータ数の中で推論能力を最大限に引き出すことに成功しているのです。
3. エッジデバイスへの展開:量子化技術による最適化
Phi-4-mini-reasoningの登場により、高度なAI推論をスマートフォンやIoTデバイスなどのエッジ環境で実行するというビジョンが、より現実味を帯びてきました。エッジAIは、低遅延(クラウドとの通信が不要)、オフライン動作(ネットワーク接続なしで利用可能)、プライバシー向上(データをデバイス外部に送信しない)、通信コスト削減といった多くの利点をもたらします。しかし、エッジデバイスは計算能力やメモリ容量が限られているため、AIモデルをそのままデプロイすることは困難です。ここで鍵となるのがモデル量子化技術です。
- 量子化の原理と効果: 量子化とは、通常32ビットや16ビットの浮動小数点数で表現されるモデルの重み(パラメータ)や活性化関数の値を、より少ないビット数(例えば8ビット整数や4ビット整数)で近似的に表現する技術です。これにより、以下のような効果が得られます。
- モデルサイズの劇的な削減: ビット数を減らすことで、モデルファイルのサイズが数分の一になります。これにより、デバイスのストレージ容量を節約し、モデルのダウンロードやロード時間を短縮できます。
- 推論速度の向上: 整数演算は浮動小数点演算よりも一般的に高速であり、またメモリ帯域幅の消費も削減されるため、推論(モデルによる予測)の実行速度が向上します。
- 消費電力の削減: 計算量が減り、メモリアクセスも効率化されるため、特にバッテリー駆動のデバイスにおいて消費電力を抑えることができます。
- 精度のトレードオフ: 量子化は近似処理であるため、一般的には元のモデルと比較してわずかに精度が低下する可能性があります。しかし、適切な量子化手法を選択し、場合によっては量子化を考慮した再学習(Quantization-Aware Training)を行うことで、精度低下を最小限に抑えることが可能です。
- 量子化を支援するツール: Phi-4 Reasoningモデルを効率的に量子化し、デプロイするために、MicrosoftやAppleは強力なツールを提供しています。
- Microsoft Olive (ONNX LIVE): これは、ONNX Runtimeエコシステム向けの包括的なAIモデル最適化ツールキットです。ユーザーがモデルとターゲットハードウェア(CPU, GPU, NPUなど)を指定すると、Oliveは自動的に最適な量子化手法(INT8, INT4など)やグラフ最適化などを組み合わせて適用し、ターゲット環境で最も効率的に動作するONNX形式のモデルを生成します。Azure Machine Learningとの連携もスムーズで、クラウド上で量子化プロセスを実行できます。
- Apple MLX Framework: Apple Silicon (Mシリーズチップ) を搭載したMacデバイス上で、機械学習モデルのトレーニングと推論を効率的に行うためにAppleが開発したフレームワークです。MLXは、Apple Siliconの統合メモリとNeural Engineを最大限に活用するように設計されており、Phi-4-mini-reasoningのようなモデルをローカル環境で高速に量子化し、実行することが可能です。Pythonインターフェースを提供しており、既存の機械学習ワークフローにも比較的容易に組み込めます。
これらのツールを活用することで、AIエンジニアは、ターゲットとするエッジデバイスの特性に合わせてPhi-4-mini-reasoningを最適化し、これまで不可能だったようなインテリジェントな機能を組み込んだアプリケーションを開発することが可能になります。
4. 特定ドメインへの適応:ファインチューニングによる専門家AIの構築
Phi-4 Reasoningモデルファミリーは、そのままでも高い汎用的な推論能力を持っていますが、特定の業界や専門分野(ドメイン)における、より高度で専門的な推論タスクに対応させたいというニーズも存在します。例えば、医療分野での診断支援、金融分野でのリスク評価、法律分野での判例検索や文書要約などです。このような場合、ファインチューニングによってモデルを特定のドメインに適応させることが極めて有効な戦略となります。
- LoRA (Low-Rank Adaptation) による効率的なファインチューニング: 従来のファインチューニングでは、モデル全体のパラメータを更新するため、大規模な計算資源と時間が必要でした。しかし、LoRAは、元の事前学習済みモデルの重みを凍結(固定)したまま、ごく一部の追加パラメータ(アダプタと呼ばれる低ランク行列)のみを学習する手法です。具体的には、Transformer層内の重み行列の「変化分」を低ランク行列の積で近似します。これにより、以下のような利点が得られます。
- 計算コストの大幅削減: 学習対象のパラメータ数が非常に少ないため、トレーニングに必要な計算資源(GPUメモリ、時間)が大幅に削減されます。
- 元のモデルの知識維持: ベースモデルの重みを変更しないため、事前学習で獲得した汎用的な知識が失われる「破滅的忘却」のリスクを低減できます。
- アダプタの切り替え: 学習されたアダプタは比較的小さなファイルサイズであるため、複数のタスクやドメイン用に学習したアダプタを保存しておき、必要に応じて切り替えて利用することも容易です。
- ドメイン固有のCoTデータセットの重要性: 特定ドメインへのファインチューニングを成功させるためには、そのドメインに特化した高品質な思考連鎖(CoT)データセットが鍵となります。単に専門知識を問うQ&Aデータだけでなく、その分野の専門家がどのように問題を分析し、どのような思考プロセスを経て結論に至るのかを示すデータが、モデルにドメイン固有の推論パターンを学習させる上で非常に効果的です。記事で例示されている医療分野のデータセットのように、質問、思考プロセス、最終回答がセットになったデータが理想的です。
- OliveやMLXを用いたファインチューニングワークフロー: 量子化と同様に、ファインチューニングのプロセスもツールによって支援されています。
- Microsoft Olive: LoRAを用いたファインチューニング機能も提供しており、Azure ML上でデータセットの準備、LoRAアダプタの学習、そして学習済みアダプタを適用したONNXモデルの生成まで、一連のワークフローをサポートしています。
- Apple MLX: ローカルのMac環境でLoRAファインチューニングを実行するための機能も提供されており、手元のデータで迅速にモデルのカスタマイズを試すことが可能です。
- ファインチューニングの際の考慮事項: 効率的なLoRAとはいえ、ファインチューニングには注意点もあります。使用するデータセットの質と量が性能に直結するため、慎重なデータキュレーションが必要です。また、学習率やLoRAのランク(次元数)などのハイパーパラメータ調整も重要となります。
LoRAを用いたファインチューニングにより、開発者はPhi-4 Reasoningという強力な汎用推論エンジンを基盤として、それぞれの応用分野に特化した、より専門的で高精度なカスタムAIモデルを、比較的容易に構築することが可能になります。
5. 利用方法とエコシステム – 開発者のためのアクセスとツール
Phi-4 Reasoningモデルファミリーの価値を最大限に引き出すためには、開発者が容易にアクセスし、利用できる環境が整備されていることが重要です。Microsoftはこの点を重視しており、多様なプラットフォームとツールを通じてモデルを提供しています。
- 主要なアクセスポイント:
- Azure AI Foundry: Microsoftの公式なAIモデルカタログであり、Phi-4 Reasoningモデルを含む最新のモデルが提供されています。Azureのクラウド環境上で、モデルの探索、評価、実験、そしてデプロイまでをシームレスに行うことができます。エンタープライズレベルのセキュリティと管理機能が必要な場合に適しています。
- Hugging Face Hub: 世界最大のオープンソースAIコミュニティであり、Phi-4 Reasoningモデルファミリーもここで公開されています。transformersライブラリを使えば、数行のコードでモデルをダウンロードし、ローカル環境や任意のクラウド環境で利用を開始できます。研究開発や迅速なプロトタイピングに適しています。
- 主要な利用フレームワークとライブラリ:
- Transformers (Hugging Face): Pythonにおけるデファクトスタンダードとも言えるLLMライブラリです。Phi-4モデルの読み込み、トークナイズ、推論実行、そしてLoRAを用いたファインチューニングまで、豊富な機能を提供します。後述のColabコード例もこのライブラリを使用しています。
- ONNX Runtime: Microsoftが主導する、クロスプラットフォームな推論エンジンです。特に、Oliveによって量子化・最適化されたONNX形式のモデルを実行する際に利用されます。onnxruntime-genaiという拡張ライブラリを用いることで、テキスト生成タスクに特化した機能や、LoRAアダプタの動的な適用などが容易になります。エッジデバイスへのデプロイにおいて中心的な役割を果たします。
- Apple MLX: 前述の通り、Apple Silicon搭載Mac上でモデルを効率的に実行・ファインチューニングするためのフレームワークです。mlx_lmというパッケージを通じて、Phi-4モデルの変換、量子化、推論、LoRAファインチューニングなどがサポートされています。macOSネイティブアプリへの組み込みなどに強みを発揮します。
- その他のツール: Ollamaやllama.cppといった、ローカル環境でLLMを簡単に実行するための人気ツール群でも、Phi-4モデルがサポートされています。これにより、コマンドラインから手軽にモデルを試したり、カスタムアプリケーションに組み込んだりすることが可能です。
- 推論実行時の重要な考慮点:
- ChatML形式の遵守: Phi-4モデル群は、特定のチャット形式であるChatML (Chat Markup Language) を用いて学習されています。これは、<|im_start|>system、<|im_start|>user、<|im_start|>assistantといった特別なトークンで対話の役割(システム、ユーザー、アシスタント)を明示する形式です。最良の性能を引き出すためには、推論時の入力(プロンプト)もこの形式に準拠させることが強く推奨されます。特にPhi-4-reasoningモデルでは、思考プロセスを促すための特定のシステムプロンプト(例:「あなたはアシスタントとして、最終的な正確な解答を提供する前に、体系的な思考プロセスを通じて質問を徹底的に探求する役割を担います…」)の使用が効果的です。
- <think>と<solution>構造の活用 (Phi-4-reasoning): Phi-4-reasoningは、応答を思考プロセス(<think>タグ内)と最終解答(タグ外、または<solution>タグ内)に分けて生成するように学習されています。この構造を利用することで、モデルがどのように結論に至ったかを追跡・検証しやすくなり、AIの判断に対する信頼性を高めることができます。
- 推論パラメータの調整: テキスト生成の挙動は、temperature、top_p、do_sampleといったパラメータによって大きく変化します。
- temperature: 値が高いほど、よりランダムで創造的な出力になりますが、不確実性も増します。低いほど、より決定的で予測可能な出力になります。推論タスクでは、やや低め(例: 0.5〜0.8)に設定することが多いですが、問題によっては多様な思考経路を探索するために少し高めに設定することも有効です。
- top_p: 確率の高い単語から累積確率がpを超えるまでを選択肢とするサンプリング手法です。temperatureと組み合わせて使用され、出力の多様性と品質のバランスを取ります。
- do_sample=True: 上記のtemperatureやtop_pを用いたサンプリングを有効にします。Falseにすると、常に最も確率の高い単語を選択する貪欲なデコーディングとなり、出力は決定的になりますが、多様性が失われます。
- max_new_tokens: 生成するトークンの最大長を指定します。CoTを含む推論タスクでは、思考プロセスを十分に記述できるよう、比較的大きな値(例: 1024, 4096, あるいはモデルの最大コンテキスト長に近い値)を設定することが重要です。
これらのツールと利用上の注意点を理解することで、開発者はPhi-4 Reasoningモデルファミリーを効果的に活用し、自身のプロジェクトに組み込むことができます。
まとめ
本稿では、MicrosoftがAI分野における新たなマイルストーンとして発表した、推論特化型小型言語モデル「Phi-4 Reasoning」ファミリーについて、その背景、技術的詳細、応用可能性、そして利用方法に至るまで、解説しました。
Phi-4 Reasoningモデルファミリーは、「小型でありながら驚異的な推論能力を持つ」という、これまでの常識を覆す可能性を示しています。特に、数学や科学、論理パズルといった複雑な問題解決能力において、自身の何倍ものサイズを持つ大規模モデルに匹敵、あるいは凌駕する性能を達成している点は特筆に値します。これは、「教科書品質」のデータと合成データに基づく革新的な学習データ戦略、Chain-of-Thoughtを活用した推論プロセス重視の学習、そして強化学習や効率的なアーキテクチャといった要素技術が見事に融合した成果と言えるでしょう。
さらに重要なのは、量子化技術(Microsoft Olive, Apple MLX)との組み合わせによって、これらの高度な推論能力をリソースが限られたエッジデバイス上で実現する道筋が示されたことです。これにより、低遅延、オフライン動作、プライバシー保護といった要求が厳しい分野においても、インテリジェントな機能の実装が可能となり、AIの応用範囲は飛躍的に拡大することが期待されます。また、LoRAを用いた効率的なファインチューニングにより、特定の業界やタスクに特化したカスタムAIを、比較的容易に構築できる点も、開発者にとっては大きな魅力です。
Phi-4 Reasoningは、単なる新しいモデルの登場に留まらず、AI開発のパラダイムシフトを促す可能性を秘めています。すなわち、巨大化一辺倒だったLLM開発の流れに、「小型・高効率・高性能」という新たな潮流を生み出し、AI技術の民主化をさらに加速させるかもしれません。Azure AI FoundryやHugging Faceを通じて容易にアクセスできるこれらのモデルを実際に試し、その能力を直接体験し、自身のプロジェクトや研究開発にどのように活用できるかを探求してみることをお勧めします。Phi-4 Reasoningが切り拓く、小型AIによる推論の新時代は、まだ始まったばかりです。