はじめに
数学における定理証明は、その厳密性が学問の根幹をなす一方で、非常に高度で緻密な作業が要求されます。近年、大規模言語モデル(LLM)の目覚ましい発展により、非形式的な数学的推論能力は大きく向上しましたが、形式的な証明支援システム(Lean 4, Isabelle, Coqなど)を用いた厳密な証明構築は、AIにとって依然として大きな課題でした。形式的証明では、全てのステップが明示的に構築され、論理的に検証される必要があり、曖昧さや暗黙の仮定は許されません。
DeepSeek-Prover-V2は、この非形式的な推論能力と形式的な証明構築の間のギャップを埋めることを目指して開発された、オープンソースの大規模言語モデルです。特に、形式的定理証明システムであるLean 4での証明に特化して設計されています。
本稿では、DeepSeek-Prover-V2の技術的な特徴、その学習方法、そして各種ベンチマークでの性能について、提供された情報をもとに詳細に解説します。AIエンジニアの皆様が、このモデルの仕組みや可能性を深く理解するための一助となれば幸いです。
引用元記事
- タイトル: DeepSeek-Prover-V2: Advancing Formal Mathematical Reasoning via Reinforcement Learning for Subgoal Decomposition
- 発行元: DeepSeek-AI
- 発行日: 2025年4月29日
- URL: https://arxiv.org/pdf/2504.21801
※Github
- タイトル: GitHub – deepseek-ai/DeepSeek-Prover-V2
- URL: https://github.com/deepseek-ai/DeepSeek-Prover-V2
※HuggingFace
- タイトル: deepseek-ai/DeepSeek-Prover-V2-671B · Hugging Face
- URL: https://huggingface.co/deepseek-ai/DeepSeek-Prover-V2-671B
GoogleColab(弊社作成)
https://colab.research.google.com/drive/1N2aAIaffJdzgf7cuoeiB80gvwyjKcDP7?usp=sharing
要点
- DeepSeek-Prover-V2は、Lean 4での形式的定理証明に特化した大規模言語モデルです。
- DeepSeek-V3を活用したサブゴール分解と再帰的証明探索により、初期学習用のデータセットを効率的に構築しています。
- 非形式的推論と形式的証明を結びつけるため、合成データによるコールドスタート学習に加えて、強化学習を導入しています。
- Chain-of-Thought (CoT) 推論モードと非CoTモードの二段階学習を行い、精度と効率の両立を図っています。
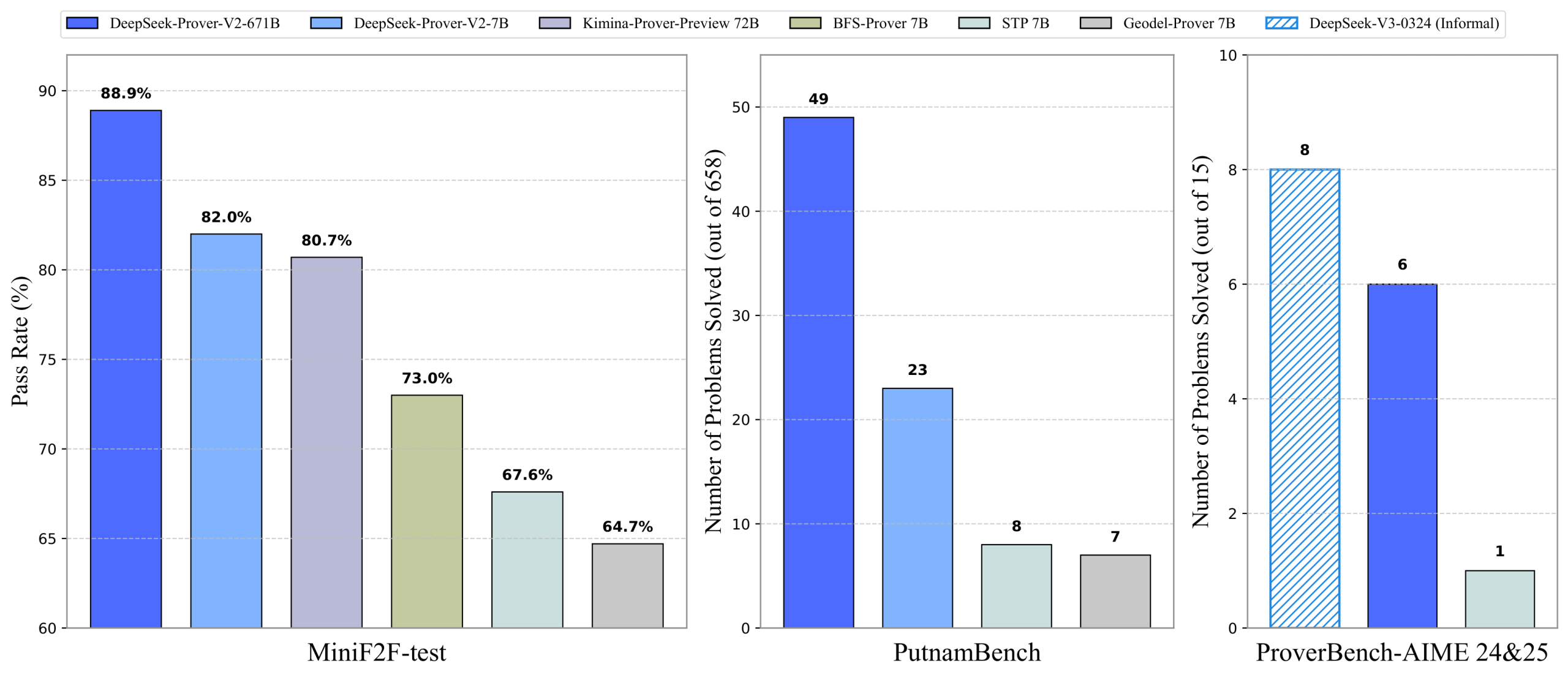
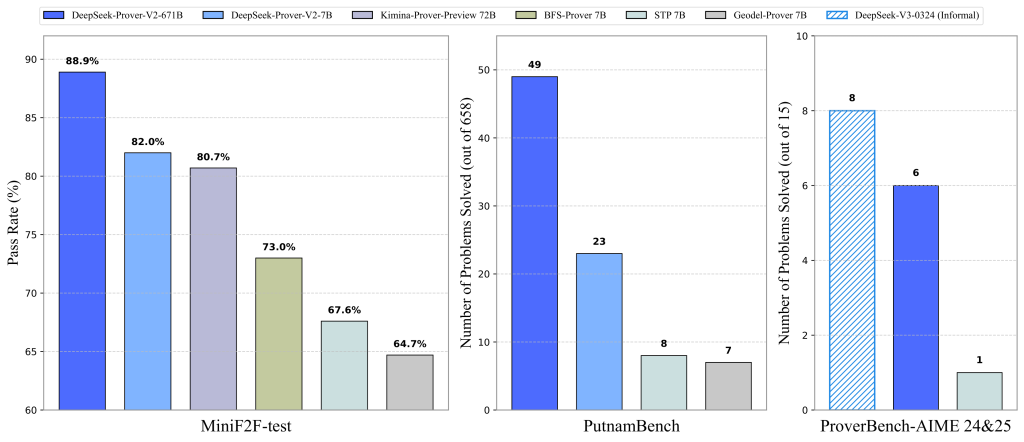
- MiniF2F-testベンチマークで88.9%のパス率を達成し、神経定理証明分野で最先端の性能を示しています。
- 高難度の PutnamBench や学部レベルの ProofNet、そして独自ベンチマーク ProverBench でも高い性能を発揮し、大学レベルの数学への強力な汎化能力を示しています。
詳細解説
形式的定理証明とLean 4について
DeepSeek-Prover-V2を理解する上で、「形式的定理証明」と「証明支援系」という概念は重要です。
形式的定理証明とは、あらかじめ定められた厳密な論理規則に従って、命題(定理)が真であることを示すプロセスです。これは、人間が通常行う数学の証明とは異なり、直感や飛躍を一切許容しません。全ての推論ステップは、形式的な言語で記述され、その正しさが論理的に検証可能である必要があります。
この形式的な証明をコンピュータ上で構築・検証するためのツールが証明支援系です。Lean 4は、そのような証明支援系の一つで、プログラミング言語としての機能も持ち合わせています。Lean 4を使用することで、数学的な定義や定理を形式的に記述し、その証明をステップバイステップで構築し、システムによる検証を受けることができます。DeepSeek-Prover-V2は、このLean 4のコード(形式的証明)を自動生成することを目指しています。
DeepSeek-Prover-V2の技術的な仕組み
DeepSeek-Prover-V2の開発は、主に以下の要素から成り立っています。
1. 再帰的証明探索 via サブゴール分解
人間が難しい問題を解く際に、いきなり最終的な答えを出すのではなく、問題を小さな部分に分解して一つずつ解決していくように、定理証明においてもサブゴール分解は効果的な戦略です。サブゴールとは、元の定理を証明するための中間目標となるより簡単な命題や補題のことです。
DeepSeek-Prover-V2では、基盤モデルであるDeepSeek-V3をこのサブゴール分解と形式化のための統一ツールとして活用しています。まず、DeepSeek-V3に元の定理を自然言語でのProof Sketch(証明の概要)として分解するよう促します。同時に、これらの証明ステップをLean 4の形式的なステートメントに翻訳します。この際、DeepSeek-V3は完全な証明コードを生成するのではなく、詳細を省略したProof Sketchを形式化したLeanコードを生成します。具体的には、証明すべきステップをhaveというキーワードと対応する命題で表現し、証明の本体をsorryというプレースホルダーで示します。人間が証明の骨子だけを書き出すようなスタイルに似ています。図2がこのプロセスの概要を示しています。
次に、分解されたサブゴールは、より小さい7Bパラメータのモデルを用いて再帰的に解決されます。このように小さいモデルを使うことで、計算コストを削減しています。各サブゴールは、必要に応じて先行するサブゴールを前提として利用できるように構築されます。全てのサブゴールが解決されると、それらを組み合わせることで元の問題の完全な形式的証明が自動的に構築されます。
このようにして、解決されたサブゴールの完全な形式的証明と、DeepSeek-V3によるステップバイステップのChain-of-Thought (CoT) 推論(思考過程)が組み合わされ、高品質なコールドスタート(初期学習用)データが合成されます。このデータセットが、DeepSeek-Prover-V2のトレーニングの基礎となります。
2. 強化学習による非形式的推論と形式化の連携強化
合成されたコールドスタートデータでの初期学習(ファインチューニング)の後、DeepSeek-Prover-V2 は強化学習(Reinforcement Learning, RL)の段階に進みます。これは、モデルの非形式的推論と形式的証明構築を結びつける能力をさらに強化するためです。
標準的な強化学習の手法に倣い、生成された証明が正しいか否かというバイナリな(0か1の)フィードバックが主要な報酬として使用されます。さらに、CoTガイダンスで示されたサブゴールの分解構造と、生成された証明の構造が整合するように、訓練の初期段階では整合性報酬が導入されています。これにより、複雑な定理において、多段階の推論が必要な場合の証明精度が向上するとのことです。RLアルゴリズムとしては、Group Relative Policy Optimization (GRPO)が採用されています。
3. 二段階学習パイプライン
DeepSeek-Prover-V2は、証明生成において以下の二つのモードをサポートするために、二段階の学習パイプラインを経ています。
- 高効率 non-Chain-of-Thought (non-CoT) モード: 中間推論ステップを明示せず、簡潔なLean形式的証明コードを迅速に生成することに最適化されています。
- 高精度 Chain-of-Thought (CoT) モード: 中間推論ステップを体系的に記述し、証明の透明性や論理的な進行を重視してから最終的な形式的証明を構築します。
一段階目では、主にnon-CoTモードのモデルが、Expert Iterationというフレームワークを用いて訓練されます。Expert Iterationでは、現在のモデルで解けなかった難しい問題を対象に証明生成を試み、成功した証明を学習データに追加してモデルを改善していくという反復的なループを行います。この段階で、サブゴールベースの再帰的証明手法を用いて難しい問題の証明を合成し、データセットを拡充しています。non-CoTモードは推論・検証サイクルが速いため、データ収集に適しています。
二段階目では、DeepSeek-V3の高度な数学的推論パターンと合成された形式的証明を統合したコールドスタートCoTデータを活用し、CoTモードが強化されます。この強化に強化学習が利用されます。
4. モデルサイズと基盤モデル
DeepSeek-Prover-V2は、7Bパラメータと671Bパラメータの2つのモデルサイズで公開されています。 DeepSeek-Prover-V2-671Bは、DeepSeek-V3-Baseの上に構築されています。一方、DeepSeek-Prover-V2-7BはDeepSeek-Prover-V1.5-Baseを基盤とし、コンテキスト長は最大で32Kトークンに拡張されています。より小さい7Bモデルの学習には、671Bモデルの強化学習で収集されたデータの蒸留も利用されています。
ベンチマーク性能
DeepSeek-Prover-V2は、様々な数学分野や難易度の形式的定理証明ベンチマークで評価されています。
- MiniF2F-test: 数学オリンピックレベルの定理証明ベンチマークです。DeepSeek-Prover-V2-671B(CoTモード)は、Pass@8192で88.9%という、このベンチマークにおける最先端のパス率を達成しています。より小さい7Bモデルでも競争力のある性能を示しており、既存のオープンソースプロバーを上回っています。CoTモードはnon-CoTモードと比較して大幅な性能向上を示しており、形式的定理証明においてもCoTが有効であることが確認されました。
- PutnamBench: アメリカとカナダの学部生向けの数学競技会 Putnam Competition の問題 formalized dataset です。DeepSeek-Prover-V2-671B(CoTモード)は、最新版の658問中49問を解決しました。これはnon-CoTモードを大きく上回る結果です。興味深いことに、7B non-CoTモデルは、671B CoTモデルが解けなかった13問を解決し、合計で62問の解決に貢献しました。これは、小さいモデルがCardinality(集合の要素数)の操作に関する特定の技術(Cardinal.toNatやCardinal.natCast_injなど)を発見したことによると考えられています。
- ProofNet-test: 学部レベルの純粋数学の教科書から形式化された問題集です。DeepSeek-Prover-V2-671B(CoTモード)は、Pass@1024で37.1%のパス率を達成しました。主に高校レベルの数学データで学習しているにも関わらず、学部レベルの問題で強力な汎化能力を示しています。
- ProverBench: DeepSeek-Prover-V2の開発チームによって導入された新しいベンチマークです。AIME 24&25の競技問題から形式化された15問と、教科書・チュートリアルからの310問で構成されています。AIME 15問において、DeepSeek-Prover-V2-671B(CoTモード)は6問を解決しました。DeepSeek-V3(非形式的推論)が同じ問題セットで8問を解いていることと比較すると、形式的推論と非形式的推論の間の性能差が縮まっていることが示唆されます。ProverBench全体でも、671B CoTモデルは他のベースラインを上回る性能を示しています。
まとめ
本稿では、形式的定理証明分野における最先端の取り組みであるDeepSeek-Prover-V2について詳しく見てきました。このモデルは、DeepSeek-V3による賢明なサブゴール分解と形式化、それを効率的に解決する再帰的証明探索、そして非形式的推論と形式的証明の連携を強化する強化学習を組み合わせることで、複雑な数学的定理の形式的証明を高い精度で自動生成することを可能にしました。
MiniF2FでのSOTA達成や、学部レベルの PutnamBench、ProofNet、そして独自ベンチマーク ProverBench での優れた性能は、DeepSeek-Prover-V2が形式的定理証明において大きな一歩を踏み出したことを明確に示しています。特にChain-of-Thought推論モードが性能向上に貢献している点は、今後の定理証明AIの開発において重要な示唆を与えると考えられます。
非形式的な自然言語による数学的推論が得意なLLMと、厳密な形式的検証が可能な証明支援システムの間にはまだギャップがありますが、DeepSeek-Prover-V2はまさにこの橋渡しを強力に進めるモデルと言えます。今後、さらなるスケーリングや手法の改善により、最終的には国際数学オリンピック(IMO)レベルといった、人間にとっても極めて難しい問題の形式的証明にAIが挑戦することが期待されています。