はじめに
本稿では、Microsoft Researchによって開発された、初のオープンソース・ネイティブ1ビット大規模言語モデル(LLM)である「BitNet b1.58 2B4T」について詳しく解説します。その技術的な特徴、性能、そして実際の利用方法まで解説します。
引用元:
- HuggingFaceリポジトリ: BitNet b1.58 2B4T – Scaling Native 1-bit LLM
- 参照元URL: https://huggingface.co/microsoft/bitnet-b1.58-2B-4T
- 確認日:2025年04月16日
Github: https://github.com/microsoft/BitNet
Paper(arxiv): https://arxiv.org/abs/2504.12285
Demo: https://bitnet-demo.azurewebsites.net/(アクセスすると、高速化を体験できるデモ画面が用意されています)
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- BitNet b1.58 2B4Tは、Microsoft Researchが開発した20億パラメータ規模のネイティブ1ビットLLMです。
- 4兆トークンという大規模なデータセットで学習されており、同規模のフル精度モデルに匹敵する性能を示します。
- 最大の利点は計算効率にあり、メモリ使用量、エネルギー消費、推論速度(レイテンシ)において既存モデルより大幅に優れています。
- 重みは1.58ビット(-1, 0, +1の3値)、活性化関数は8ビットで量子化されています。重要なのは、学習時からこの量子化を適用している点です(PTQ: Post-Training Quantization学習後量子化ではない)。
- 利用には、Hugging Face transformersライブラリ(専用フォーク版)または、効率を最大限に引き出すための公式C++実装 bitnet.cpp を使用します。
詳細解説
0. 前提知識と補足
- LLMと量子化: 通常、LLMの重みは32ビットや16ビットの浮動小数点数で表現されます。量子化とは、これらの数値をより少ないビット数(例: 8ビット整数、4ビット整数、そしてBitNetのような1ビット)で近似的に表現する技術です。これにより、メモリ使用量と計算量を削減できますが、一般的には精度がわずかに低下するトレードオフがあります。
- Native Training vs PTQ: PTQ (Post-Training Quantization) は、既に学習済みのモデルに対して後から量子化を適用します。一方、BitNetのようなNative Training(またはQAT: Quantization-Aware Training)は、学習プロセス自体に量子化を組み込むため、量子化による精度低下を学習によって補うことができ、より高い精度を維持しやすいとされています。
- 効率性の意味: BitNetの効率性は、特に推論時に顕著です。少ないメモリで動作するため、より小型のデバイス(CPU搭載のラップトップやエッジデバイスなど)での実行が現実的になります。また、計算量が少ないため、推論速度が向上し、消費電力も削減されます。
1. BitNet b1.58 2B4Tとは? – 1ビットLLMの衝撃
近年、LLMの性能向上は目覚ましいものがありますが、その一方でモデルサイズと計算コストの増大が課題となっています。BitNet b1.58 2B4Tは、この課題に対する画期的なアプローチとして登場しました。
「1ビットLLM」とは、モデルのパラメータ(重み)を極限まで削減し、通常32ビットや16ビットで表現される数値を、わずか1.58ビット(実質的に-1, 0, +1の3値)で表現するモデルです。これにより、メモリ使用量を劇的に削減できます。BitNet b1.58 2B4Tは、この1ビット量子化を学習の初期段階から適用(Native Training)することで、性能を維持しつつ効率化を実現した点が革新的です。
2. 技術的特徴:何が新しいのか?
BitNet b1.58 2B4Tの技術的な核となる要素は以下の通りです。
- アーキテクチャ:
- 基本はTransformerベースですが、線形層がBitLinearレイヤーに置き換えられています(BitNetフレームワーク)。
- 位置埋め込みにはRoPE (Rotary Position Embeddings) を採用。
- FFN層の活性化関数にはReLU² (Squared ReLU) を使用。
- 正規化層にはSubLN (Sub-Layer Normalization) を採用。
- バイアス項は線形層、正規化層ともに不使用。これは計算効率化に寄与します。
- 量子化 (Quantization):
- 重み (Weights): W1.58A8 と呼ばれる方式です。順伝播時に absmean量子化 を用いて {-1, 0, +1} の3値に量子化されます。1.58ビットという表現は、この3値を効率的に格納するためのビット数に由来します。
- 活性化関数 (Activations): トークンごとにabsmax量子化 を行い、8ビット整数へ量子化されます。
- ネイティブ量子化: 最も重要な点として、このモデルは学習後に量子化を行うPTQ(Post-Training Quantization)ではなく、学習プロセス自体に量子化を組み込んでいます。これにより、量子化による精度劣化を最小限に抑え、高い性能を達成しています。
- 学習:
- データ: 4兆トークンという膨大な公開テキスト/コード、合成数学データを使用。
- コンテキスト長: 最大4096トークン。非常に長いコンテキストを扱う場合は、事前学習とファインチューニングの間に中間的な長期シーケンス適応/学習を行うことが推奨されています。
- 学習段階:
- 事前学習 (Pre-training): 大規模データでの学習。
- 教師ありファインチューニング (SFT): 指示追従・対話データセットでファインチューニング。
- 直接的好み最適化 (DPO): 人間の好みとの整合性を高めるための調整。
- トークナイザー: LLaMA 3 Tokenizer を使用(語彙サイズ: 128,256)。
3. 性能評価:どれくらい凄いのか?
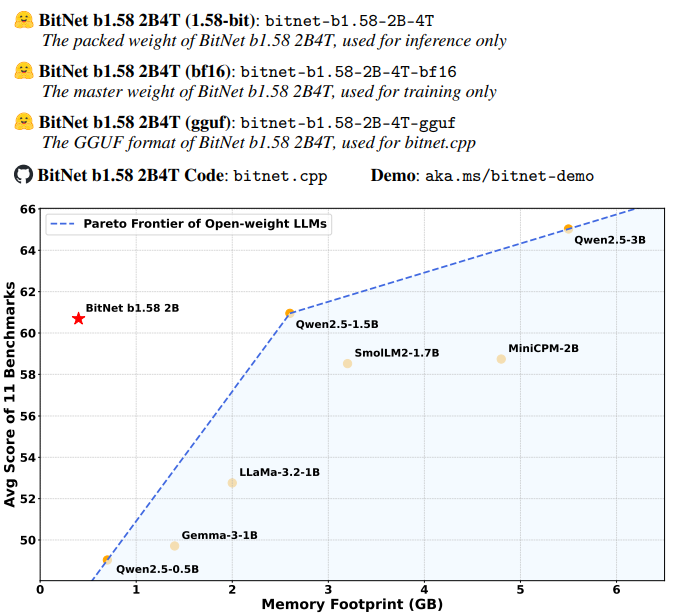
BitNet b1.58 2B4Tは、同規模(1B〜2Bパラメータ)の主要なオープンソース・フル精度LLMと比較して、非常に優れた結果を示しています。
| ベンチマーク | LLaMA 3.2 1B | Gemma-3 1B | Qwen2.5 1.5B | SmolLM2 1.7B | MiniCPM 2B | BitNet b1.58 2B |
| メモリ (非埋込) | 2GB | 1.4GB | 2.6GB | 3.2GB | 4.8GB | 0.4GB |
| レイテンシ (CPU) | 48ms | 41ms | 65ms | 67ms | 124ms | 29ms |
| エネルギー (推定) | 0.258J | 0.186J | 0.347J | 0.425J | 0.649J | 0.028J |
| MMLU | 45.58 | 39.91 | 60.25 | 49.24 | 51.82 | 53.17 |
| GSM8K | 38.21 | 31.16 | 56.79 | 45.11 | 4.40 | 58.38 |
| MATH-500 | 23.00 | 42.00 | 53.00 | 17.60 | 14.80 | 43.40 |
| HumanEval+ | 31.10 | 37.20 | 50.60 | 28.00 | 43.90 | 38.40 |
| 平均スコア | 44.90 | 43.74 | 55.23 | 48.70 | 42.05 | 54.19 |
(*LLaMA 3.2 1Bはプルーニングと蒸留を使用, **Gemma-3 1Bは蒸留を使用)
特筆すべきは、メモリ使用量が0.4GBと極めて少なく、CPUでの推論レイテンシも29msと高速である点です。エネルギー効率も群を抜いています。各種ベンチマークスコアにおいても、Qwen2.5 1.5Bに匹敵、あるいは上回る項目が多く、平均スコアでは比較対象の中で2番目に高い性能を示しています。これは、1ビット量子化を行いながらも高い精度を維持できていることを証明しています。
4. 利用方法:どうやって使うのか?
BitNet b1.58 2B4Tを利用するには、主に2つの方法があります。
4.1. Hugging Face transformers ライブラリ (現状はフォーク版)
手軽に試すには transformers ライブラリが便利ですが、重要な注意点があります。
【重要】効率性の注意点:
標準の transformers ライブラリ(および現在のフォーク版)では、BitNetアーキテクチャの計算効率の利点(速度、レイテンシ、エネルギー消費)を享受できません。これは、1ビット演算に最適化された計算カーネルが含まれていないためです。transformers経由で実行した場合、推論速度やエネルギー効率は、標準的なフル精度モデルと同等か、場合によっては劣る可能性があります。メモリ使用量の削減は確認できるかもしれませんが、真の効率性を得るには後述の bitnet.cpp が必須です。
必要なライブラリ:
現在、公式 transformers への統合が進められていますが、現時点では専用のフォーク版をインストールする必要があります。
pip install git+https://github.com/shumingma/transformers.gitPythonコード例:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# モデルIDを指定
model_id = "microsoft/bitnet-b1.58-2B-4T"
# トークナイザーとモデルをロード
# BF16を使用することが推奨されています
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16 # BF16でロード
)
# デバイス(CPUまたはGPU)にモデルを移動
# device = "cuda" if torch.cuda.is_available() else "cpu" # GPUが利用可能ならGPUを使用
# model.to(device)
# CPUで実行する場合は上記2行は不要
# チャットテンプレートを適用
messages = [
{"role": "system", "content": "あなたは役に立つAIアシスタントです。"},
{"role": "user", "content": "今日の天気はどうですか?"}, # 例として質問を変更
]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
# プロンプトをトークン化
# chat_input = tokenizer(prompt, return_tensors="pt").to(device) # GPUの場合
chat_input = tokenizer(prompt, return_tensors="pt") # CPUの場合
# 応答を生成
# max_new_tokens で生成する最大トークン数を指定
chat_outputs = model.generate(**chat_input, max_new_tokens=100)
# 応答部分のみをデコード
# response = tokenizer.decode(chat_outputs[0][chat_input['input_ids'].shape[-1]:], skip_special_tokens=True) # GPUの場合
response = tokenizer.decode(chat_outputs[0][chat_input['input_ids'].shape[-1]:], skip_special_tokens=True) # CPUの場合
print("\nAssistant Response:", response)4.1. 公式C++実装 bitnet.cpp
公式C++実装 bitnet.cpp (推奨:高効率)
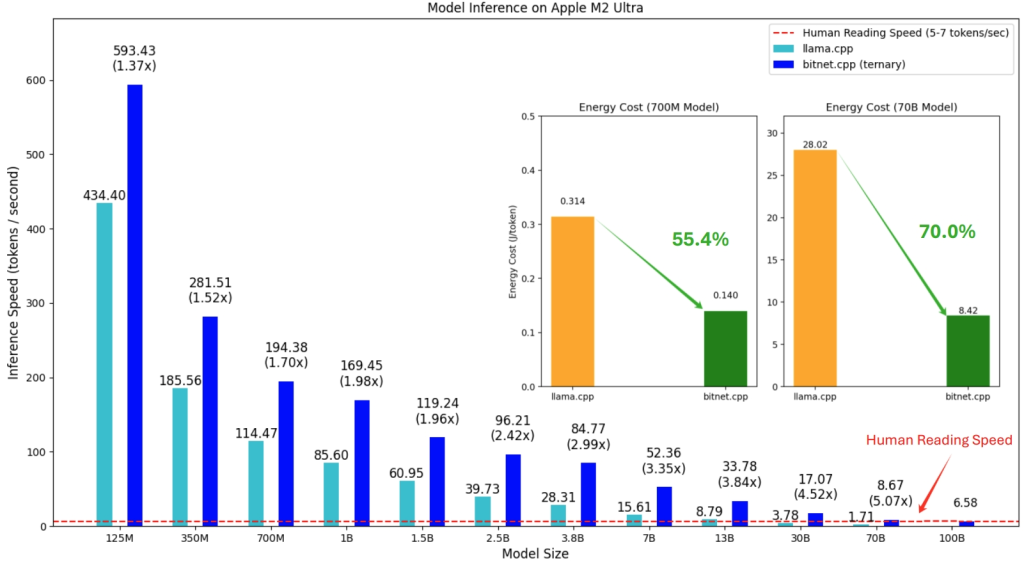
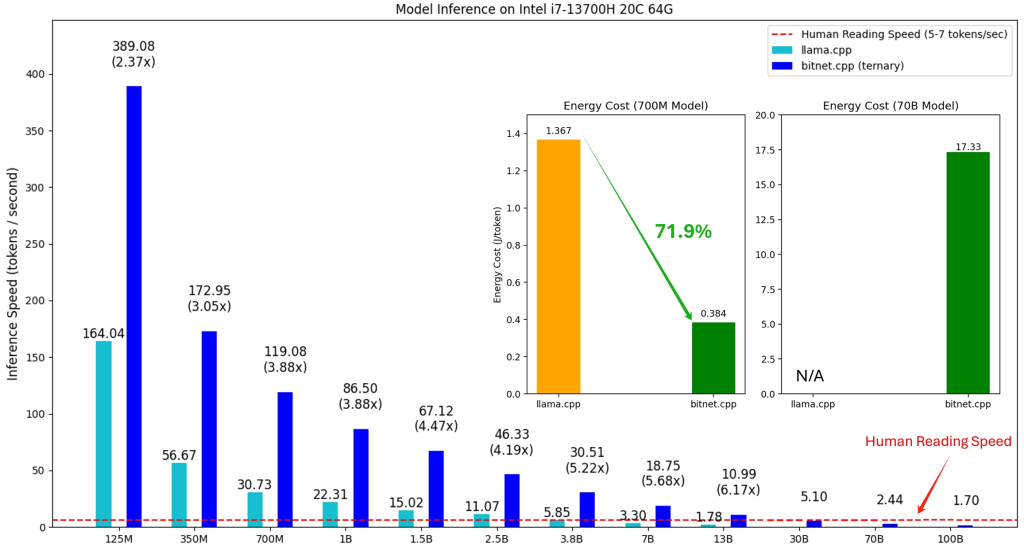
BitNet b1.58 2B4Tの真の効率性(高速な推論、低レイテンシ、低エネルギー消費)を引き出すには、専用に開発されたC++ライブラリ bitnet.cpp を使用する必要があります。これは llama.cpp にインスパイアされた実装で、特にCPUでの推論に最適化されており、NPUやGPUのサポートも予定されています。
bitnet.cpp の利点:
- 速度向上: ARM CPUで1.37倍~5.07倍、x86 CPUで2.37倍~6.17倍の高速化を実現します(モデルサイズが大きいほど効果大)。
- 省エネルギー: ARM CPUで55.4%~70.0%、x86 CPUで71.9%~82.2%のエネルギー消費を削減します。
- 大規模モデルの実行: 例えば100BパラメータのBitNetモデルを単一CPU上で人間が読む速度(5~7トークン/秒)で実行可能にします。
前提条件:
- Python >= 3.9
- CMake >= 3.22
- Clang >= 18
- (推奨) Conda 環境
- (Windowsの場合) Visual Studio 2022 (特定のコンポーネント含む)、Developer Command Prompt/PowerShellの使用
利用手順:
1. リポジトリのクローン (再帰的): git clone --recursive https://github.com/microsoft/BitNet.git cd BitNet 2. 環境設定と依存関係のインストール (Conda推奨): conda create -n bitnet-cpp python=3.9 conda activate bitnet-cpp
3. 依存関係をインストール: pip install -r requirements.txt
4. モデルのダウンロードと環境セットアップ: Hugging Faceからダウンロードし、setup_env.py を実行して環境を準備します。 huggingface-cli download microsoft/bitnet-b1.58-2B-4T-gguf --local-dir models/BitNet-b1.58-2B-4T
# 環境セットアップスクリプトを実行 (量子化タイプなどを指定)
# * `-md`: モデルが格納されているディレクトリ
# * `-q`: 量子化タイプ (`i2_s` または `tl1`)。公式の `BitNet-b1.58-2B-4T` は `i2_s` を使用します。
# * 他のオプションについては `python setup_env.py -h` を参照してください。
python setup_env.py -md models/BitNet-b1.58-2B-4T -q i2_s5. 推論の実行: run_inference.py スクリプトを使用します。 python run_inference.py -m models/BitNet-b1.58-2B-4T/ggml-model-i2_s.gguf -p "あなたは役に立つAIアシスタントです。" -cnv * -m: 量子化されたモデルファイル (.gguf) へのパス。setup_env.py で生成されます。
* -p: プロンプト (チャットモードでない場合) またはシステムプロンプト (チャットモードの場合)。
* -cnv: チャットモードを有効にします (指示チューニングされたモデル用)。
* -n: 生成するトークン数 (デフォルト: 128)。
* -t: 使用するスレッド数 (デフォルト: 環境による)。
* 他のオプションについては python run_inference.py -h を参照してください。
ベンチマーク: utils/e2e_benchmark.py スクリプトを使用して推論のベンチマークを実行できます。詳細はリポジトリのREADMEを参照してください。
bitnet.cpp を利用することで、論文で報告されているような劇的な効率改善を体験できます。
まとめ
BitNet b1.58 2B4Tは、1ビット量子化をネイティブに学習に取り入れることで、フル精度モデルに匹敵する性能を維持しつつ、メモリ使用量、推論速度、エネルギー効率を劇的に改善した画期的なLLMです。
transformers ライブラリ(フォーク版)で手軽に試すことも可能ですが、その真価である計算効率を最大限に引き出すには、公式のC++実装 bitnet.cpp の利用が不可欠です。
このモデルの登場は、LLMの活用シーンをエッジデバイスやリソースに制約のある環境へと大きく広げる可能性を秘めており、今後のLLM研究開発における重要なマイルストーンと言えるでしょう。