
はじめに
YouTube Shortsで、自分の表情に合わせてキャラクターが動いたり、顔がアニメ風になったりするエフェクトを使ったことはありますか?まるで魔法のようにリアルタイムで動作するこれらの生成AIエフェクトは、実は非常に高度な技術の結晶です。大規模なAIモデルは通常、高性能なサーバーでなければ動かせませんが、YouTubeはそれをスマートフォン上で実現しています。
本稿では、Google Researchが公開したブログ記事「From massive models to mobile magic: The tech behind YouTube real-time generative AI effects」を元に、大規模な生成AIモデルの能力を、リソースの限られたモバイルデバイス上で、いかにしてリアルタイムに実現しているのか、解説します。
参考記事
- タイトル: From massive models to mobile magic: The tech behind YouTube real-time generative AI effects
- 発行元: Google Research
- 発行日: 2025年8月21日
- URL: https://research.google/blog/from-massive-models-to-mobile-magic-the-tech-behind-youtube-real-time-generative-ai-effects/
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- 大規模で高性能な「教師モデル」から、小型で高速な「生徒モデル」へ知識を転移させる知識蒸留が中核技術である。
- 顔の特徴を維持したまま画像を編集するためにPivotal Tuning Inversion (PTI) という技術を用い、生成AIにおける「本人性」が失われる問題を解決している。
- モバイルデバイス上でのリアルタイム処理は、GoogleのオープンソースフレームワークであるMediaPipeを用いて構築されたパイプラインによって実現されている。
- 多様性を考慮した高品質なデータセットの構築と、複数の損失関数を組み合わせた高度な学習プロセスにより、高品質なエフェクトが生成される。
詳細解説
課題:なぜスマホでAIエフェクトを動かすのは難しいのか
近年の画像生成AIは目覚ましい進化を遂げていますが、その多くは「モデル」と呼ばれるAIプログラムが非常に大きく、動作させるにはクラウド上にある高性能なコンピュータの計算能力を必要とします。これをそのままスマートフォンで動かそうとすると、処理が追いつかず、リアルタイムでの動画加工は不可能です。
YouTube Shortsのエフェクトがユーザーにとって「魔法のように」感じられるためには、カメラの映像に対して1秒間に30回(30fps)以上の速さで処理を完了させなければなりません。この厳しい制約の中で、高品質なAIエフェクトをどう実現するかが大きな技術的課題でした。
解決策の核心:「知識蒸留」というアプローチ
この課題を解決するために、YouTubeの開発チームが採用したのが知識蒸留(Knowledge Distillation)という手法です。これは、非常に賢く能力が高い専門家(教師モデル)の知識を、特定の作業に特化したコンパクトな弟子(生徒モデル)に教え込むようなものです。
- 教師モデル: GoogleのImagenのような、非常に高性能で大規模な画像生成AIモデルです。あらゆる指示に対して高品質な画像を生成できますが、動作が遅く、モバイルデバイスには搭載できません。
- 生徒モデル: モバイルデバイス上で高速に動作するように特別に設計された、小型で効率的なAIモデルです。特定のタスク(例えば「顔をアニメ風にする」)に特化しています。
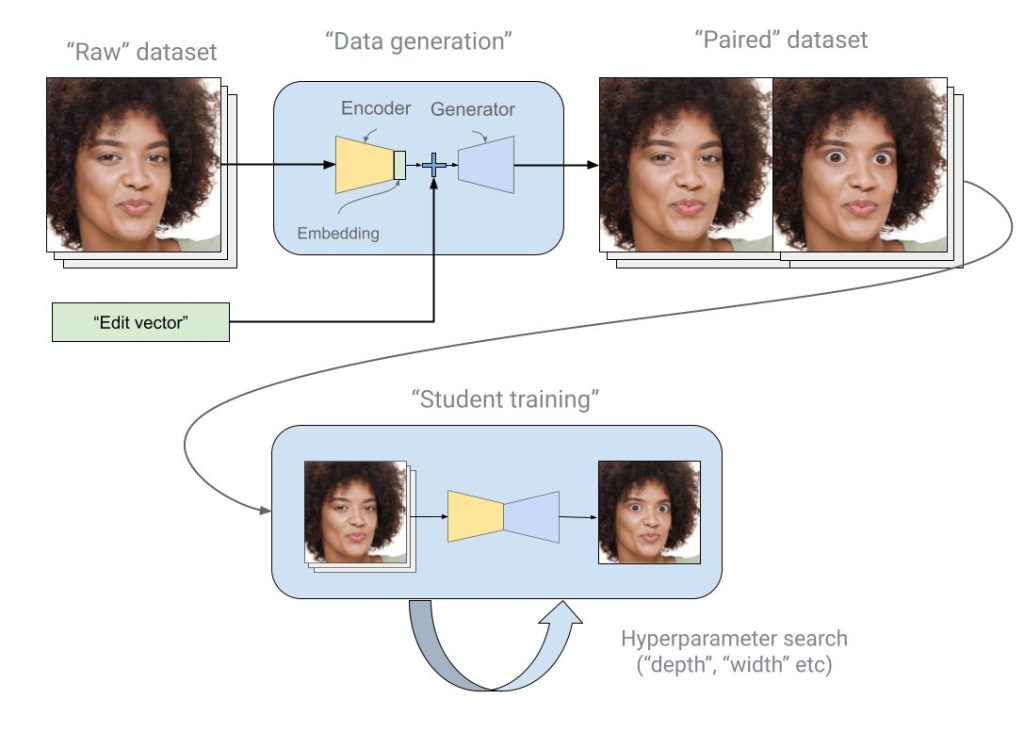
この知識蒸留のプロセスは、以下の2段階で行われます。
- データ生成: まず、教師モデルを使って、加工前の画像と、エフェクトを適用した後の画像のペア(「お手本」データ)を大量に生成します。
- 生徒モデルの学習: 次に、生徒モデルにこの「お手本」データペアを大量に見せ、「加工前の画像を渡されたら、教師モデルと同じように加工後の画像を生成しなさい」と学習させます。
これにより、生徒モデルは教師モデルの持つ「特定のエフェクトをかける能力」だけを効率的に学び取り、スマートフォン上でも高速に動作するようになります。
最重要課題:どうやって「あなたらしさ」を保つのか?
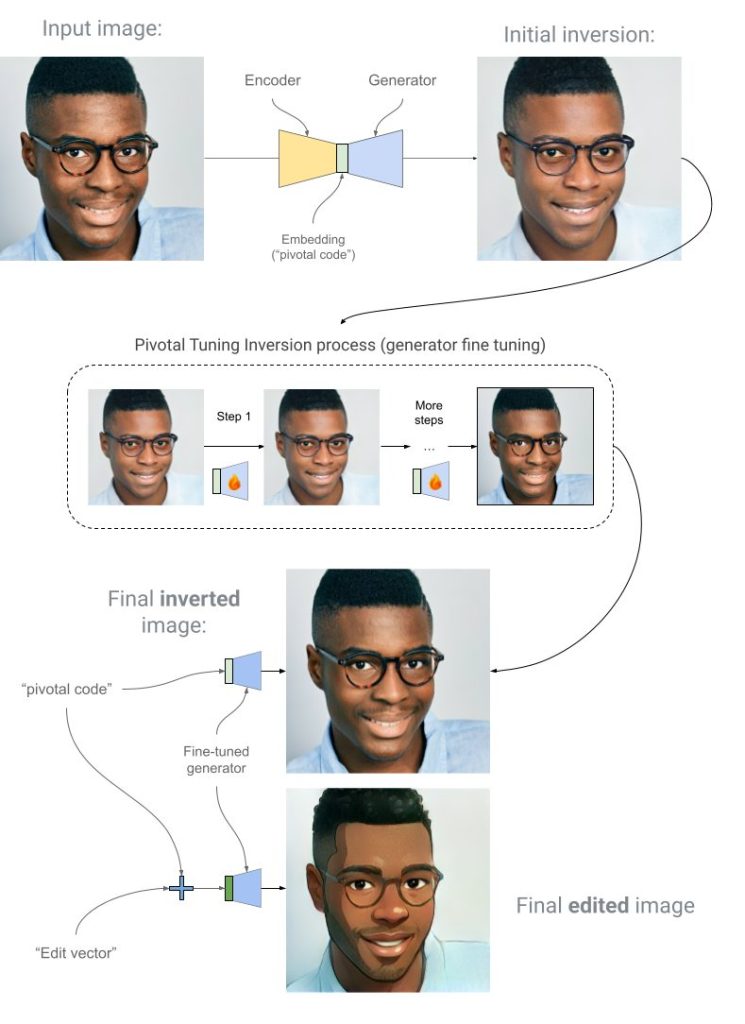
生成AIで顔を加工する際に最も難しい問題の一つが、本人性の維持です。AIが顔全体を新しく生成するため、元の人物の肌の色やメガネ、顔の細かい特徴などが失われ、「誰だか分からなくなってしまう」という現象が起こりがちでした。これを専門的にはインバージョン問題と呼びます。
この問題を解決するために、Pivotal Tuning Inversion (PTI) という技術が使われています。これは、以下のようなステップで本人性を維持します。
- 特徴の抽出: 入力された画像(あなたの顔)から、その人固有の特徴を数値データ(pivotal codeと呼ばれる)に変換します。
- AIモデルの微調整: そのpivotal codeを元に、AIモデル自体を「この人の顔を正確に再現できるように」その場で微調整します。
- エフェクトの適用: 微調整されたAIモデルに対して、かけたいエフェクト(例:笑顔にする、アニメ風にする)を指示します。
このプロセスにより、AIはあなたの顔の特徴をしっかりと掴んだ上でエフェクトを適用するため、加工後の画像でも「あなたらしさ」が失われません。
最終ステップ:スマートフォン上での実行パイプライン
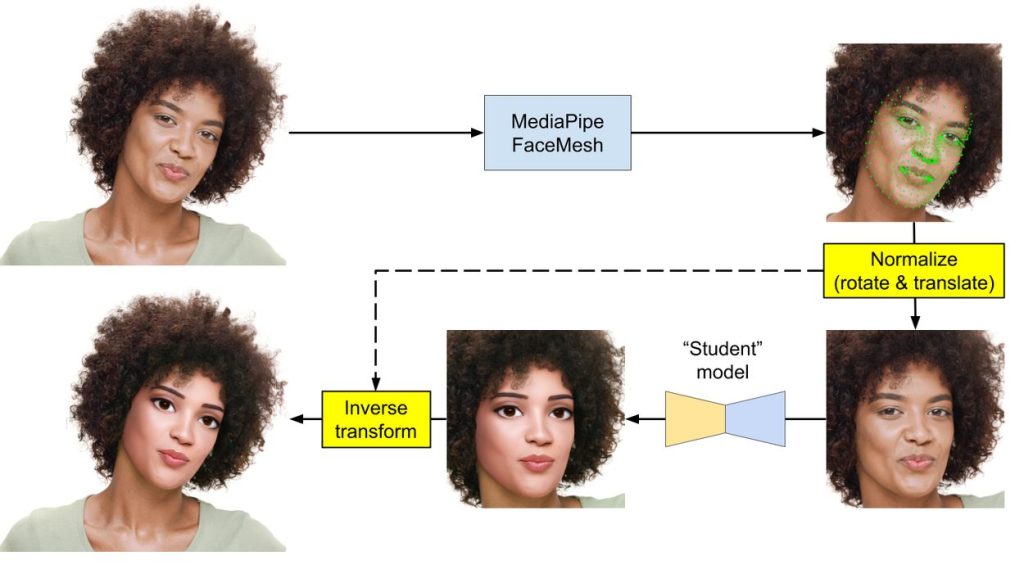
こうして学習された生徒モデルを、実際にスマートフォンアプリに組み込み、リアルタイムで動かすためにMediaPipeというフレームワークが使われています。MediaPipeは、カメラ映像のようなデータストリームに対して、機械学習モデルを効率的に適用するためのパイプラインを構築するツールです。
YouTube Shortsでの処理の流れは以下のようになっています。
- 顔の検出: MediaPipeのFace Mesh機能が、カメラ映像から顔の位置を正確に検出します。
- 顔の切り抜きと整形: 検出した顔が常に同じ向き、同じ大きさになるように、画像を回転させたり切り抜いたりして位置を合わせます。これは、生徒モデルが安定して性能を発揮するために重要な前処理です。
- 生徒モデルによる処理: 整形された顔画像が、AIの入力形式(テンソル)に変換され、生徒モデルに渡されます。ここでエフェクトが適用されます。
- 合成: エフェクトが適用された顔画像を、元のカメラ映像の正しい位置に違和感なく合成します。
この一連の流れが、Pixel 8 Proでは約6ミリ秒、iPhone 13では約10.6ミリ秒という驚異的な速さで実行されます。これにより、ユーザーは遅延を感じることなく、リアルタイムで生成AIエフェクトを楽しむことができるのです。
まとめ
本稿では、YouTube Shortsのリアルタイム生成AIエフェクトが、いかにしてスマートフォン上で実現されているかを解説しました。その核心は、以下の3つの技術の組み合わせにあります。
- 知識蒸留: 大規模モデルの能力を、モバイル用の軽量なモデルに凝縮する技術。
- Pivotal Tuning Inversion (PTI): AIによる加工後も、ユーザーの「本人性」を維持する技術。
- MediaPipe: 軽量化されたモデルを、モバイルデバイス上で高速に実行するためのパイプライン技術。
これらの技術は、これまで高性能なサーバーでしか利用できなかった生成AIの力を、私たちの手の中にあるデバイスへと解放するものです。これにより、世界中のクリエイターがより豊かで新しい表現方法を手にすることが可能になりました。今後、さらに新しいモデルが統合されることで、私たちの創造性を刺激するツールはさらに進化していくことでしょう。








