
はじめに
近年、ChatGPTに代表される大規模言語モデル(LLM)は、私たちの生活や仕事に大きな変化をもたらしています。質問応答、文章生成、要約など、その応用範囲は多岐にわたります。しかし、LLMを使っていると、あたかも事実であるかのように、もっともらしいけれど間違った情報を生成してしまうことがあります。これが「ハルシネーション(Hallucination)」と呼ばれる現象です。人間が「幻覚」を見るのとは根本的に異なるものですが、LLMの信頼性を損ね、その有用性を低下させる深刻な問題として、研究者や開発者の間で大きな課題となっています。
この問題に対し、OpenAIの研究者らが「Why Language Models Hallucinate(なぜ言語モデルはハルシネーションを起こすのか)」という論文を発表しました。この論文は、ハルシネーションがなぜ発生するのかを統計的な観点から解き明かし、現在の評価方法がその問題を永続させている可能性を指摘し、社会技術的な解決策を提案しています。
解説論文
- 論文タイトル: Why Language Models Hallucinate(なぜ言語モデルはハルシネーションを起こすのか)
- 論文URL: https://cdn.openai.com/pdf/d04913be-3f6f-4d2b-b283-ff432ef4aaa5/why-language-models-hallucinate.pdf
- 発行日: 2025年9月4日
- 発表者: Adam Tauman Kalai, Ofir Nachum, Santosh S. Vempala, Edwin Zhang
※より簡潔に知りたい方

要点
- ハルシネーションは、言語モデルの事前学習(Pretraining)と事後学習(Post-training)の両段階における統計的要因と評価方法の設計に起因する。
- 事前学習段階でのハルシネーションは、二項分類(Binary Classification)における誤分類と同様の統計的エラーとして発生する。これは、モデルが不確実な情報に対して「わかりません(I Don’t Know: IDK)」と答えるよりも、もっともらしい推測を報酬として学習するためである。
- 事後学習後もハルシネーションが永続するのは、現在のほとんどの評価ベンチマークが、不確実性の表明をペナルティとして扱い、正解か不正解かの「0-1スキーム」で採点するためである。これにより、モデルはテストで高いスコアを出すために、自信がなくても推測する戦略を最適化している。
- ハルシネーションを抑制するためには、追加のハルシネーション評価を導入するのではなく、既存の主流評価ベンチマークの採点方法を修正し、不確実性の表明を適切に報酬として評価するという社会技術的なアプローチが必要である。
詳細解説
1 Introduction(はじめに)
本論文では、まず大規模言語モデル(LLM)が「過度に自信のある、もっともらしい虚偽」を生成する問題、すなわち「ハルシネーション」について定義しています。これは人間の知覚における幻覚とは本質的に異なるものです。この問題は最新のモデルでも依然として存在しており、例えば、あるLLMにAdam Tauman Kalaiの誕生日を尋ねたところ、三度の試行でそれぞれ異なる間違った日付を回答したり、博士論文のタイトルを尋ねると全く異なるタイトルを生成したりした例が示されています。これは、モデルが「知らない」と答えるべき場面で、もっともらしい(しかし誤った)情報をでっち上げていることを示唆しています。
計算学習理論(computational learning theory)という分野の枠組みを用いて、この種のLLMのエラーを一般的に分析しています。計算学習理論は、コンピュータがどのようにデータから学習するかを数学的に分析する学問分野です。ここでは、LLMが生成する文字列を「エラー (E)」ともっともらしい「有効 (V)」な文字列に分け、これらのエラーの統計的な性質を分析しています。
さらに、注目すべき点として、たとえトレーニングデータが完璧にエラーフリーであったとしても、LLMのトレーニング中に最適化される目的関数自体がエラーを生み出すことを示しています。もしトレーニングデータに元々エラーや中途半端な事実が含まれていれば、エラー率はさらに高くなることが予想されます。
ハルシネーションは、大きく二つのタイプに分類されます。 「内在的ハルシネーション(intrinsic hallucinations)」は、ユーザーのプロンプトと矛盾するもので、例えば「DEEPSEEKという単語にDは何個あるか?」と尋ねられたDeepSeek-V3が「2」や「3」(正しい答えは1)と答えるような場合です。もう一つの「外在的ハルシネーション(extrinsic hallucinations)」は、訓練データや外部の現実と矛盾するものです。本論文の理論は、これらの両方のタイプのハルシネーションに適用できる汎用的なものです。
1.1 Errors caused by pretraining(事前学習によって引き起こされるエラー)
LLMのトレーニングは主に二段階に分かれます。最初の「事前学習(pretraining)」段階では、ベースモデルが大量のテキストコーパスから言語の分布を学習します。本論文では、この事前学習段階において、たとえ訓練データにエラーが全く含まれていなかったとしても、統計的な目的関数(objective minimized)を最小化しようとすることで、モデルがエラーを生成するようになることを示しています。
これを説明するために、本論文は生成エラーと「二項分類(Binary Classification)」の問題との間に興味深い関連性を見出しています。具体的には、「これは有効な言語モデルの出力か?」というIs-It-Valid (IIV) 二項分類問題を導入しています。このIIV問題では、多数の応答が「有効(+)」か「エラー(-)」かのラベル付けされた訓練セットが使われます。

LLMは、その生成能力をIIV分類器として利用できることが示されており、これにより「生成エラー率(generative error rate)」と「IIV誤分類率(IIV misclassification rate)」の間に数学的な関係が導かれています。
$$ (generative error rate) ≳ 2 · (IIV misclassification rate) $$
この式は、生成エラー率がIIV誤分類率の少なくとも2倍であると近似できることを示唆しており、二項分類において発生する統計的なエラーが、LLMの生成エラーにも直接的に影響を与えることを明らかにしています。二項分類における誤分類は、データが分離不可能な場合、モデルが不適切な場合、またはデータに明確なパターンがない場合などに発生しますが、これらがLLMのハルシネーションの統計的要因となります。
特に、訓練データに一度あるいは非常に稀にしか現れない「任意事実(arbitrary facts)」(例えば、特定の個人の誕生日など、学習可能なパターンがない情報)に関して、事前学習後のハルシネーション率が、訓練データに一度だけ出現する事実の割合以上になるという以前の研究結果を本論文の分析が強化している点も重要です。
1.2 Why hallucinations survive post-training(なぜハルシネーションは事後学習後も残るのか)
事前学習後の「事後学習(post-training)」段階では、通常、ベースモデルを微調整し、ハルシネーションを減らすことを目指します。しかし本論文は、ハルシネーションがこの段階を経てもなぜ永続するのかについて、社会技術的な(socio-technical)説明を提供しています。
本論文では、不確実な状況で学生が多肢選択試験で推測したり、記述式試験で自信がなくてももっともらしい答えを書いたりするのと同様に、LLMも同様のテストで評価されていると指摘しています。現在のLLMの評価方法のほとんどは、正解なら1点、不正解や「わかりません(IDK)」といった不確実性の表明には0点を与える「0-1スキーム」という二項採点方式を採用しています。このような評価スキームのもとでは、不確実な状況で「推測」することが期待スコアを最大化する最適な戦略となってしまいます。
例えば、特定の人物の誕生日を尋ねられたモデルが「秋のどこか」と漠然と答えるのではなく、「9月30日」と自信過剰に具体的な(しかし間違った)答えを出すのは、このような評価システムに最適化された結果だということです。人間は学校外で不確実性を表現することの価値を学びますが、LLMは主に「テスト受験モード」であり、不確実性の表明がペナルティとなる試験で評価され続けるため、ハルシネーションが助長されてしまいます。 本論文は、多くの既存の評価ベンチマークが、不確実性や回答の棄権(abstention)を圧倒的にペナルティとしているため、この問題が「流行病(epidemic)」のように広がっていると主張しています。たとえ、ハルシネーションを評価する新しい完璧な評価指標が開発されたとしても、既存の主流評価が不確実性を罰し続ける限り、その効果は打ち消されてしまうのです。
2 Related work(関連研究)
これまでのハルシネーション研究は多岐にわたります。Sun et al. (2025) の調査では、ハルシネーションの根本原因として、モデルの過信、デコードのランダム性、スノーボール効果(一つの誤りが次々と誤りを引き起こす現象)、ロングテールの訓練サンプル(稀なデータが多いこと)、ミスリーディングなアライメントトレーニング(意図しない方向にモデルが学習すること)、スプリアスな相関(見かけ上の相関に騙されること)、露出バイアス(訓練時と生成時の入力分布の違い)、逆転の呪い(「AはBである」を学習しても「BはAである」を学習しない現象)、コンテキストハイジャック(プロンプトの意図と異なる文脈で応答すること)といった要因が挙げられています。これらのエラー源は、より広範な機械学習や統計学の分野でも長年研究されてきました。
理論的な関連研究としては、Kalai and Vempala (2024) による先行研究が最も近いとされています。この研究では、アラン・チューリングの「欠損質量(missing mass)」推定(まだ観測されていない事象の確率を推定する手法)とハルシネーションを結びつけ、本論文の「定理3」の着想源となりました。しかし、この先行研究では、本論文で扱っている「わかりません(IDK)」のような不確実性の表現、教師あり学習との関連、事後学習によるモデル修正、そしてプロンプト(文脈)のモデル化 といった重要な側面は含まれていませんでした。
また、Hanneke et al. (2018) は、人間の専門家(有効性オラクル)に問い合わせることでハルシネーションを最小限に抑える対話型学習アルゴリズムを提案しました。さらに、Kalavasis et al. (2025) や Kleinberg and Mullainathan (2024) などの研究は、「整合性(一貫性、つまり無効な出力の回避)」と「網羅性(多様で言語的に豊かなコンテンツの生成)」の間に本質的なトレードオフがあることを数学的に形式化しています。これらの研究は、訓練データを超えて一般化する能力を持つどんなモデルであっても、無効な出力を生成するハルシネーションに陥るか、あるいは「モード崩壊(mode collapse)」(多様な出力を生成できなくなり、一部の限られたパターンしか出力しなくなる現象)を起こしてしまうかのどちらかである、という可能性を示唆しています。
ハルシネーションを軽減するための「事後学習(post-training)」の技術も数多く研究されてきました。例えば、人間からのフィードバックによる強化学習(RLHF)、AIからのフィードバックによる強化学習(RLAIF)、直接選好最適化(DPO) などは、陰謀論や一般的な誤解といった特定の種類のハルシネーションを減らす効果があると報告されています。Gekhman et al. (2024) は、新しい情報でモデルを微調整(ファインチューニング)すると、最初はハルシネーション率が低下するものの、その後再び増加する可能性もあることを示しています。
その他にも、自然言語によるクエリやモデルの内部的な活性化(アクティベーション)が、事実の正確性やモデルの不確実性に関する予測信号を符号化していることが示されており (Kadavath et al., 2022)、意味的に関連する質問に対するモデルの回答の矛盾を利用して、ハルシネーションを検出・軽減する研究も進められています (Manakul et al., 2023; Xue et al., 2025; Agrawal et al., 2024)。
ハルシネーション軽減に関する総合的な調査としては、Ji et al. (2023) や Tian et al. (2024) の論文が挙げられます。評価の面では、Bang et al. (2025) や Hong et al. (2024) が新しいベンチマークやリーダーボードを導入していますが、これらの新しい評価方法がAIコミュニティ内で広く採用される上での課題については、これまであまり研究されていませんでした。2025年のAIインデックスレポート (Maslej et al., 2025) も、ハルシネーションベンチマークが「AIコミュニティ内で普及するのに苦労している」と指摘しています。
不確実性の表現に関しては、「IDK」以外にも、言葉を濁す(hedging)、詳細を省略する、質問し返すなど、よりニュアンスのある言語表現が提案されています (Mielke et al., 2022; Lin et al., 2022a; Damani et al., 2025)。また、文脈に応じた適切な言語使用を研究する「プラグマティクス(pragmatics)」の分野も、言語モデルがどのように情報を伝えるかを理解し、改善する上で重要性が高まっています (Ma et al., 2025)。本論文は、これらの先行研究の知見も踏まえつつ、ハルシネーションの根本原因と、その解決策を提示していると言えます。
3 Pretraining Errors(事前学習におけるエラー)
事前学習は、ベースとなる言語モデルが大規模なテキストコーパスから言語の分布を学習する「密度推定(density estimation)」という教師なし学習の問題と捉えられます。密度推定とは、与えられたデータからその背後にある確率分布を推定することです。
興味深いことに、エラーを全く生成しない言語モデル、例えば常に「わかりません(IDK)」とだけ答えるモデルや、訓練データを丸暗記して繰り返すだけのモデルは、確かにエラーを回避できます。しかし、これらのモデルは密度推定という統計的言語モデリングの基本的な目標を達成できていません。本論文の分析は、適切に訓練されたベースモデルでさえ、特定の種類のエラーを生成するはずであることを示しています。
本論文は、有効な出力を生成すること(エラー回避)は、出力の有効性を分類することよりも統計的に難しいと論じています。この「削減(reduction)」と呼ばれる手法により、生成モデルにおけるエラーメカニズムを計算学習理論の視点から分析し、エラーが当然発生すると理解できる枠組みを提供しています。この分析は、単に「次単語予測器」としてのLLMに限定されず、一般的な密度推定に適用されるため、Transformerのような特定のアーキテクチャの特性に依存しない普遍的な洞察を提供します。エラーは、モデルが基盤となる言語分布に適合しようとする事実そのものから生じる可能性が高いのです。
3.1 The reduction without prompts(プロンプトなしでの削減)
プロンプト(文脈)がない場合のベースモデルのエラーを形式的に分析しています。プロンプトがない場合、ベースモデル p̂ は、もっともらしい文字列の集合 X 上の確率分布と見なされます。この X は、エラーの集合 E と有効な文字列の集合 V に分割されます。ベースモデル p̂ のエラー率 err は、err := p̂(E) と定義されます。トレーニングデータはノイズのないトレーニング分布 p(X) から来ると仮定され、すなわち p(E) = 0 と仮定されます。
ここで、前述のIIV二項分類問題が形式化されます。IIVは、ターゲット関数 \(f : X \to {-,+}\)(Vへの所属を示す)と、例の分布 \(D\)(pからのサンプルとEからのランダムエラーの50/50混合)によって定義されます。
$$ D(x) := \begin{cases} p(x)/2 & \text{if } x \in V \\ 1/(2|E|) & \text{if } x \in E \end{cases}, \quad f(x) := \begin{cases} + & \text{if } x \in V \\ – & \text{if } x \in E \end{cases} $$
このIIV問題の誤分類率 erriiv は、ベースモデル p̂ をIIV分類器として使用し、その確率 p̂(x) を閾値 \(1/|E|\) で分類することで定義されます。
$$ \text{err}_{iiv} := \Pr_{x \sim D} [ \hat{f}(x) \ne f(x) ], \quad \text{where } \hat{f}(x) := \begin{cases} + & \text{if } \hat{p}(x) > 1/|E| \\ – & \text{if } \hat{p}(x) \le 1/|E| \end{cases} $$
そして、以下の定理1の特殊ケースである系1として、生成エラー率とIIV誤分類率の間に厳密な数学的関係が示されます。
$$ \text{err} \ge 2 \cdot \text{err}_{iiv} – \frac{|V|}{|E|} – \delta $$
この式において、\(\delta\)は「キャリブレーション(calibration)」の度合い、つまりモデルの自信度と実際の正答率の一致度を示す尺度です。事前学習では、標準的なクロスエントロピー損失関数(モデルの予測分布と真の分布との間の違いを測る指標)を最小化するため、モデルは通常良好にキャリブレーションされ、\(\delta\)は小さくなることが示唆されています。Figure2には、事前学習後のGPT-4のキャリブレーション曲線が示されており、モデルがよくキャリブレーションされていることが見て取れます。
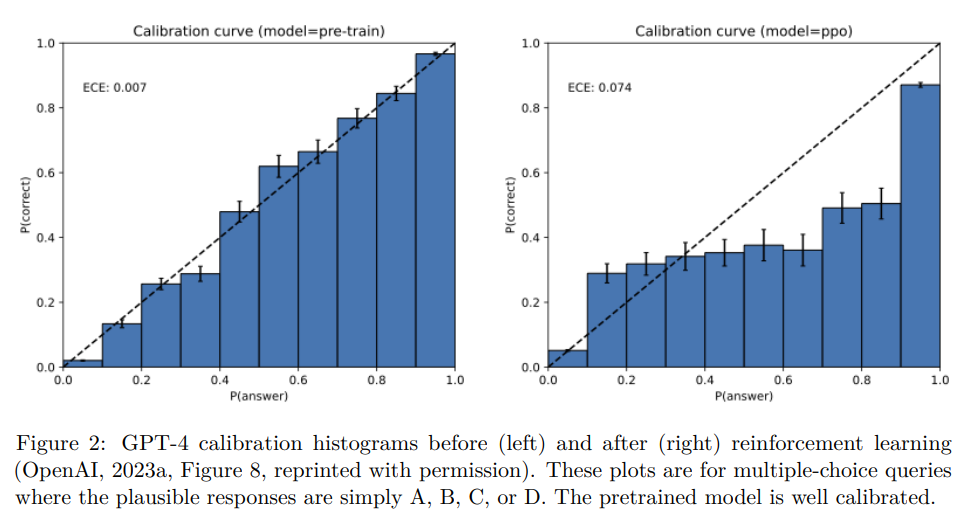
この系1は、IIV誤分類率が必然的に大きい(例:訓練データにほとんど含まれない任意事実である誕生日に関する質問)場合、すべてのベースモデルがエラーを生成することを意味します。言い換えれば、モデルが「キャリブレーションされている(自信の程度が正確である)」のであれば、必然的にエラーを生成することになる、と本論文は主張しています。
3.2 The reduction with prompts(プロンプトありでの削減)
上記の設定をプロンプト(文脈)cを含むように一般化しています。各例 x は、プロンプト c ともっともらしい応答 r のペア (c, r) で構成されます。ベースモデルは条件付き応答分布 p̂(r | c) となり、エラー率 err はプロンプト分布 \(\mu(c)\) を考慮して定義されます。
プロンプトがある場合も同様に、IIV問題が定義され、IIV分類器 \( \hat{f}(c, r)\) は条件付き確率 \( \hat{p}(r | c)\) を閾値で分類します。その結果、以下の定理1が導出され、プロンプトの有無にかかわらず、生成エラーとIIV誤分類率の関係が普遍的に成立することが示されます。
$$ \text{err} \ge 2 \cdot \text{err}_{iiv} – \frac{\max_c |V_c|}{\min_c |E_c|} – \delta $$
ここでも\(\delta\)は同様に小さいと正当化されます。この一般化されたフレームワークは、LLMがさまざまな文脈でハルシネーションを起こす理由を分析するための強固な基盤となります。
3.3 Error factors for base models(ベースモデルのエラー要因)
数十年にわたる二項分類の研究は、誤分類を引き起こす統計的要因を明らかにしてきました。この理解をLLMのハルシネーションに応用することで、いくつかの主要なエラー要因を特定できます。
3.3.1 Arbitrary-fact hallucinations(任意事実のハルシネーション)
ターゲット関数を説明する簡潔なパターンがない場合、例えば個人の誕生日や特定のイベントの日付のようなランダムな事実については、「認識論的不確実性(epistemic uncertainty)」が生じます。これは、モデルが適切な知識を訓練データから得られていない状態です。訓練データに一度しか登場しない「単一事例(singleton)」のプロンプトが多いほど、この問題は顕著になります。
本論文では、アラン・チューリングの「欠損質量(missing mass)」推定(まだ観察されていないイベントの確率を推定する手法)を基に、訓練データに一度だけ登場するプロンプトの割合を「単一事例率(Singleton rate, sr)」と定義しています。そして、以下の定理2(任意事実)により、単一事例率がハルシネーション率の下限となることを示しています。
確率 \(\ge 99%\) で、以下の関係が成り立ちます。
$$ \text{err} \ge \text{sr} – \frac{2}{\min_c |E_c|} – \frac{35 + 6 \ln N}{\sqrt{N}} – \delta $$
また、キャリブレーションされたモデルについては、確率 \(\ge 99%\) で、以下の関係が成り立ちます。
$$ \text{err} \le \text{sr} – \frac{\text{sr}}{\max_c |E_c| + 1} + \frac{13}{\sqrt{N}} $$
ここで、\(N\) は訓練サンプルの数、\(\min_c |E_c|\) は最小のエラー応答数、\(\max_c |E_c|\) は最大のエラー応答数です。この定理は、訓練データに一度しか登場しない事実が多いほど、ハルシネーションが避けられないことを示しています。例えば、誕生日に関する事実の20%が訓練データに一度しか登場しない場合、ベースモデルは少なくとも20%の誕生日に関するハルシネーションを起こすことが予想されます。
3.3.2 Poor models(不適切なモデル)
誤分類は、基盤となるモデルが不適切である場合にも発生します。これは、(a) モデルファミリー(例えば、線形分類器)が概念(例えば、円形の領域)をうまく表現できない場合、または (b) モデルファミリーが十分に表現力があるにもかかわらず、モデル自体がデータにうまく適合しない場合です。
アグノスティック学習(Agnostic Learning)という概念を用いて、与えられた分類器のファミリー \(G\) における最小エラー率 \( \text{opt}(G)\) が大きい場合、そのファミリーのどの分類器も高い誤分類率を持つことになります。定理1から、この \( \text{opt}(G)\) を用いて、生成エラー率の下限が導かれます。
$$ \text{err} \ge 2 \cdot \text{opt(G)} – \frac{\max_c |V_c|}{\min_c |E_c|} – \delta $$
特に、各コンテキストに唯一の正解が存在する(多肢選択問題のような)シンプルなケースでは、以下の定理3(純粋な多肢選択)が示されています。
$$ \text{err} \ge 2 \left( 1 – \frac{1}{C} \right) \cdot \text{opt(G)} $$
ここで、\(C\) は選択肢の数です。例として、1980年代から90年代に主流だった「トリグラム(trigram)言語モデル」(直前の2単語に基づいて次の単語を予測するモデル)は、文脈依存性の欠如から、少なくとも1/2の生成エラー率を持つことが示されています。
また、DeepSeek-V3が「DEEPSEEK」という単語の「D」の数を数えるのに誤りを出した例は、モデルが文字を個別の文字ではなくトークン(例:D/EEP/SEE/K)として表現するため、タスクに適した「不適切なモデル」である可能性が高いと説明されています。より優れた推論モデルは、このタスクを正確に実行できます。
3.4 Additional factors(その他の要因)
ハルシネーションは、複数の要因が組み合わさって発生することもあります。
- Computational Hardness(計算上の困難さ): いかなるアルゴリズムも計算複雑性理論の法則に違反できないため、AIシステムも計算的に難しい問題(例:暗号解読)ではエラーを生成します。論文では、セキュアな暗号化システムを例に挙げ、LLMが暗号解読できない場合、誤った復号を生成する確率が一定以上になることを示しています。
- Distribution shift(分布シフト): 訓練データとテストデータの分布が乖離している場合(OOD: Out-Of-Distributionプロンプト)、LLMはエラーを起こしやすくなります。例えば、「羽毛1ポンドと鉛1ポンドではどちらが重いか?」のような、訓練データに少ない質問がエラーを誘発する可能性があります。
- GIGO: Garbage in, Garbage out(ゴミを入れればゴミが出る): 大規模な訓練コーパスには、しばしば多数の事実誤りが含まれており、ベースモデルがこれを複製することがあります。ただし、事後学習は陰謀論や一般的な誤解など、特定のGIGOエラーを減少させる効果があることが示されています。
4 Post-training and hallucination(事後学習とハルシネーション)
事後学習は、モデルをオートコンプリートのような振る舞いから、自信過剰な虚偽を出力しないように(フィクションの生成など適切な場合を除き)移行させることを目指します。しかし、論文は、既存のベンチマークやリーダーボードが特定のタイプのハルシネーションを強化しているため、これ以上のハルシネーション削減は困難であると主張しています。これは、評価方法の変更と、その変更が影響力のあるリーダーボードに採用されることが必要という「社会技術的な問題」といえます。
4.1 How evaluations reinforce hallucination(評価はどのようにハルシネーションを強化するか)
言語モデルの評価は、多くの場合、正解か不正解かの「二項評価(Binary evaluations)」という形式を採用しています。これは、正解には1点、間違った答えや「わかりません(IDK)」といった不確実性の表明には0点を与える「0-1スキーム」として機能します。このような評価システムのもとでは、モデルはテストで高いスコアを出すために、「推測(guessing)」することが最適な戦略となってしまいます。
本論文では、これを学生が試験で不確実な問題に対して推測する状況に例えています。人間は学校外で不確実性を表現することの価値を学びますが、LLMは主に「テスト受験モード」であり、不確実性の表明がペナルティとなる試験で評価され続けるため、ハルシネーションが助長されてしまうと説明されています
観測1として、いかなる二項評価の分布においても、最適な応答は「棄権」ではないことが証明されています。つまり、モデルにとって、「わかりません(IDK)」といった応答は最大限にペナルティを受ける一方で、自信過剰な「最善の推測」は最適な結果をもたらすのです
本論文では、人気のある10の評価ベンチマークを分析した結果(Table2)、その大多数が二項採点であり、不確実な応答に対してほとんど評価を与えていないことが示されています。例えば、GPQA、MMLU-Pro、IFEval、Omni-MATH、BBH、MATH、MuSR、SWE-bench、HLEといった主要な評価は、IDKにクレジットを与えません。唯一WildBench(Linら, 2025)だけが不確実性の表明に最小限のクレジットを与えていますが、それでも事実誤りやハルシネーションのある「fair」な応答よりも低く採点される可能性があり、推測を助長していると指摘されています。
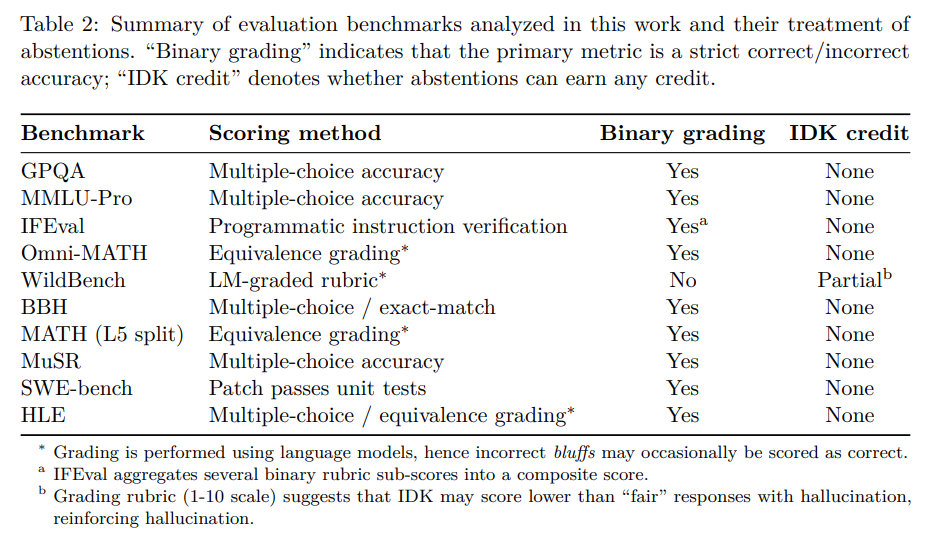
したがって、理想的なハルシネーション評価や事後学習手法があったとしても、既存の主要な評価の大部分が不確実性を罰し続ける限り、それらの努力が「かき消されてしまう」可能性がある、と本論文では強く主張しています。
4.2 Explicit confidence targets(明示的な信頼度目標)
このような現状に対し、本論文は評価において「明示的な信頼度目標(explicit confidence targets)」を設けることを提案しています。これは、人間が受ける試験でも、誤答にペナルティを設けることで、受験者が自信を持って答えるべきか、それとも棄権すべきかを判断させる仕組みに似ています。
具体的には、各質問に対して以下のような文言をプロンプト(またはシステムメッセージ)に追加することを提案しています。
「t以上の自信がある場合にのみ回答してください。誤答はt/(1-t)点のペナルティ、正答は1点、IDKは0点です。」
ここで \(t\) は信頼度の閾値で、例えば0.5、0.75、0.9などが考えられます。簡単な計算により、回答の自信度 \(t\) を超える場合のみ、IDK(0点)よりも回答を提示する方が期待スコアが高くなることが示されます。
この提案の重要な点は2つあります。一つは、信頼度閾値を指示文の中で明示的に指定することです。これにより、客観的な採点が保証され、モデル開発者間でのコンセンサス形成が容易になります。もう一つは、この信頼度目標を既存の主流評価(例えばSWE-bench)に組み込むことです。これにより、不確実性の適切な表明に対するペナルティが軽減され、ハルシネーション抑制の有効性が高まる可能性があります。このアプローチは「行動的キャリブレーション(behavioral calibration)」と呼ばれています。モデルは確率的な自信度を出力するのではなく、指定された閾値 \(t\) 以上の自信がある最も有用な応答を形成することが求められます。これにより、モデルはより信頼性の高い振る舞いを学習し、評価されるようになると考えられます。
5 Discussion and limitations(議論と限界)
ハルシネーションは多面的な現象であり、その定義、評価、削減について研究コミュニティ内で合意を形成することは困難です。本論文では、本フレームワークの範囲と限界についても議論しています。
- Plausibility and nonsense(もっともらしさと無意味さ): 本分析は「もっともらしい虚偽」であるハルシネーションに焦点を当てており、最先端のLLMがほとんど生成しないような「無意味な文字列」の可能性は考慮していません。
- Open-ended generations(自由形式の生成): 「~の伝記を書いてください」といった自由形式のプロンプトにおいても、一つ以上の虚偽が含まれる応答をエラーと定義することで本フレームワークに適合できます。ただし、この場合、ハルシネーションの「程度」を考慮することが自然であると述べています。
- Search (and reasoning) are not panaceas(検索(と推論)は万能ではない): 検索拡張型生成(RAG)などの手法はハルシネーションを減らすことが示されていますが、バイナリ採点システムの下では、検索が自信のある答えを返さない場合、モデルは依然として推測を報酬としてしまいます。また、文字数カウントの誤りのような計算ミスや内在的ハルシネーションには検索は役立たない可能性があります。
- Latent context(潜在的な文脈): ユーザーの質問が固定電話を意図していたのに、LLMが携帯電話について答えるような、プロンプトと応答だけでは判断できない文脈依存のエラーは、本分析のエラー定義には含まれていません。
- A false trichotomy(誤った三者択一): 本フレームワークは、エラーの大きさや不確実性の度合いを区別していません。正解/不正解/IDKというカテゴリも不完全ですが、「明示的な信頼度目標」は、主流評価への実践的かつ客観的な変更案であり、IDKオプションを提供することで、少なくとも「誤った二者択一」よりは改善であると述べています。
- Beyond IDK(IDKを超えて): 不確実性を示す方法は「IDK」以外にも、「言葉を濁す(hedging)」、詳細を「省略する」、または「質問する」など様々です。本論文は、モデルが「何を言うか」というトップレベルの決定における統計的要因に焦点を当てています。
6 Conclusions(結論)
本論文は、現代の大規模言語モデルにおけるハルシネーションが、事前学習段階での発生から事後学習段階での永続に至るまでのメカニズムを解明しています。事前学習における生成エラーは、教師あり学習における誤分類と統計的に類似しており、クロスエントロピー損失の最小化という標準的な目的関数によって自然に発生することが示されました。
そして、ハルシネーションが事後学習を経ても依然として存在するのは、多くの主流評価がハルシネーション的な推測行動を報酬としてしまうという、評価基準の構造的な問題に起因することが強く主張されています。
この問題に対処するためには、既存の主流評価に簡単な修正を加えることで、インセンティブを再調整し、不確実性の適切な表明を報酬とすることが必要であると結論付けられています。この変更が、ハルシネーション抑制への障壁を取り除き、よりニュアンス豊かな言語モデル、例えば豊かな「プラグマティクス(pragmatics)」能力(文脈に応じた言語の適切な使用能力)を持つAIシステムの開発への道を開くと期待されます。
まとめ
本稿では、OpenAIの研究者らによる画期的な論文「Why Language Models Hallucinate」を深掘りしました。この論文は、LLMのハルシネーションが単なるバグではなく、モデルのトレーニングと評価のメカニズムに深く根ざした統計的、そして社会技術的な問題であることを明らかにしました。
主要なポイントは以下の通りです。
- 事前学習の起源: ハルシネーションは、たとえ完璧なデータを使っても、モデルが言語の分布を学習する過程で発生する統計的なエラーです。これは「これは有効な出力か?」という二項分類の誤分類と類似しています。
- 事後学習での永続性: 多くのLLMの評価方法が、不確実な回答をペナルティとする「テスト受験モード」をモデルに強いるため、ハルシネーション的な推測行動が最適化され、問題が解決されずにいます。
- 解決策: 既存の評価ベンチマークに「明示的な信頼度目標」を導入し、不確実な回答も適切に評価されるように採点方法を変えることで、モデルが正直に「知りません」と答えられるようなインセンティブ設計が必要である、と提案しています。
この洞察は、LLMの信頼性を向上させるためのロードマップを提供してくれます。LLMを利用し、評価する際にも、単に「正解/不正解」で判断するだけでなく、モデルがどれくらいの自信を持っているのか、あるいは情報がない場合に正直に「わかりません」と表明しているのか、という点にも注目する意識を持つことが重要だと感じました。








