
はじめに
現代の検索エンジンやAIアシスタントは、私たちが入力した曖昧な言葉からでも、意図を汲み取って最適な情報を探し出してくれます。この驚くべき性能の裏側には、「ベクトル検索」という技術が存在します。特に近年、情報の意味をより豊かに捉えることができる「マルチベクター検索」が高い精度を実現していますが、その複雑さから処理速度が課題でした。
本稿では、この「高精度だけど遅い」というジレンマを解消する画期的な技術として、Google Researchが発表した「MUVERA」について、Google Researchの公式ブログに掲載された「MUVERA: Making multi-vector retrieval as fast as single-vector search」という記事をもとに、その仕組みと意義を分かりやすく解説します。
引用元記事
- タイトル: MUVERA: Making multi-vector retrieval as fast as single-vector search
- 著者: Rajesh Jayaram and Laxman Dhulipala, Research Scientists, Google Research
- 発行元: Google Research
- 発行日: 2025年6月25日
- URL: https://research.google/blog/muvera-making-multi-vector-retrieval-as-fast-as-single-vector-search/
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- 近年の高精度な検索で使われるマルチベクター検索は、文書を複数のベクトルで表現するため、計算が複雑で処理が遅いという課題がある。
- MUVERAは、この複数のベクトル(マルチベクター)の集合を、「固定長次元エンコーディング(FDE:Fixed Dimensional Encodings)」と呼ばれる単一のベクトルに変換する新しいアルゴリズムである。
- この変換により、従来から存在する高速なシングルベクター検索(MIPS:Maximum Inner Product Search)の技術をそのまま活用することが可能になる。
- 結果として、検索精度を損なうことなく、検索の遅延を最大90%削減し、リコール率を平均10%向上させるなど、処理速度と精度の両方を大幅に改善することができる。
詳細解説
そもそも「ベクトル検索」とは?
まず、MUVERAを理解するための前提知識として「ベクトル検索」について詳しくご説明します。
ベクトル検索とは、単語、文章、画像といった様々なデータを「ベクトル」と呼ばれる数値の配列に変換して、その類似性を比較することで情報を探し出す技術です。この変換を行うAIモデル(埋め込みモデル)は、意味が近いデータを、ベクトル空間上で物理的に近い位置に配置するように学習します。
例えば、「犬」と「いぬ」、「dog」は異なる文字列ですが、意味は同じです。ベクトル化すると、これらは非常に近い位置にある点として表現されます。この類似性は主に「内積類似度(inner-product similarity)」という数学的な計算で測定され、これにより単純なキーワード一致では見つけられない、意味的に関連する情報を見つけ出すことができるのです。
「シングルベクター」と「マルチベクター」の違い
ベクトル検索には、大きく分けて2つのアプローチがあります。
シングルベクター検索
一つの文書や画像を、一つのベクトルで表現する最もシンプルな方法です。文書全体の平均的な意味を捉えるイメージで、構造が単純なため、ベクトルの比較が非常に高速です。特に、MIPS(Maximum Inner Product Search)と呼ばれる高度に最適化されたアルゴリズムを活用でき、空間分割(space partitioning)などの幾何学的手法により、全数探索を避けた準線形時間での検索が可能です。
しかし、文書内に含まれる多様なトピックや細かいニュアンスを表現しきれない場合があり、特に長い文書や複雑な内容の場合には検索精度に限界があります。
マルチベクター検索
一つの文書を、トークン(単語や文節)といった複数の部分に分け、それぞれをベクトル化します。例えば、ColBERTのような最先端モデルでは、文書内の各トークンが独自のベクトル表現を持ちます。これにより、文書の持つ豊かな情報を余すことなく保持でき、より高い精度での検索が可能になります。
例えば、「AIが開発した画期的な新薬の臨床試験結果」という文書なら、「AI」「開発」「画期的」「新薬」「臨床試験」「結果」といった要素ごとのベクトルを持つイメージです。
この方法では、Chamfer類似度という特殊な計算方法が使われます。これは、クエリの各ベクトルに対して、文書内で最も類似度の高いベクトルを見つけ、それらの類似度を合計することで、「クエリの情報が文書内にどれだけ含まれているか」を測定します。
しかし、この方法は精度と引き換えに大きな代償を払います。それは計算コストの劇的な増大です:
- 埋め込み量の増加: トークンごとにベクトルを生成するため、処理すべき埋め込みの数が劇的に増加します
- 複雑で計算集約的な類似度計算: Chamfer類似度は行列積を必要とする非線形演算で、単純なドット積よりもはるかに高コストです
- 効率的な準線形検索手法の欠如: シングルベクター検索で使える高速な幾何学的手法が、マルチベクターの複雑な類似度計算では直接適用できません
MUVERAはどのように課題を解決したのか?
MUVERAは、「マルチベクターの持つ高い精度」と「シングルベクターの持つ速さ」の良いとこ取りを実現する画期的なアルゴリズムです。その核心は、マルチベクターをFDE(Fixed Dimensional Encodings; 固定長次元エンコーディング) と呼ばれる特殊なシングルベクターに変換する点にあります。
アルゴリズムの2段階プロセス
- 高速な候補検索
まず、クエリと文書のマルチベクターを、それぞれFDEという「疑似的なシングルベクター」に変換します。このFDEは、元のマルチベクター間の複雑なChamfer類似度を数学的に保証された精度で近似できるように設計されています。そして、このFDEを使って、既存の高速なMIPSアルゴリズムで、関連性の高そうな候補を高速に絞り込みます。 - 正確な再ランキング
高速検索で絞り込まれた少数(通常数百件)の候補に対してのみ、本来の正確な(ただし計算が重い)マルチベクターのChamfer類似度計算を行います。これにより、最終的な検索結果の精度を完全に保証します。
つまり、「全体を見る大雑把な検索は高速な手法で行い、有望なものだけをじっくり吟味する」 という効率的な二段階アプローチを取っているのです。
データ非依存の変換
MUVERAの重要な特徴の一つは、FDE変換がデータ非依存(data-oblivious)であることです。これは、特定のデータセットに依存せず、データ分布の変化に対して頑健で、ストリーミングアプリケーションにも適用可能であることを意味します。また、モデルが生成するシングルベクターとは異なり、FDEは指定された誤差範囲内でChamfer類似度を近似することが数学的に保証されています。
MUVERAの心臓部「FDE」の仕組み
では、どうやってマルチベクターをFDEに変換しているのでしょうか。この技術は、確率的木埋め込み(probabilistic tree embeddings)という幾何アルゴリズム理論の手法にインスパイアされ、内積とChamfer類似度に適応させたものです。
FDE構築の詳細プロセス
- 空間の分割
まず、ベクトルが存在する高次元空間を、ランダムな超平面(hyperplane)でいくつかの区画に分割します。これは空間分割の一種で、各区画が一意の識別子を持ちます。 - ベクトルのマッピング
クエリや文書を構成する各ベクトルが、この分割された区画のどこに位置するかを特定します。 - 情報の集約
FDEは、これらの区画ごとに用意された「座標ブロック」のようなものです。各区画に落ちたベクトルの情報を、対応するブロックに格納していきます。
非対称処理の重要性
ここでの最も重要なポイントは、クエリと文書で情報の集約方法を意図的に変えている点です:
- クエリの場合: 同じ区画に落ちたベクトルの座標を「合計(sum)」します
- 文書の場合: 同じ区画に落ちたベクトルの座標を「平均(average)」します
この非対称な処理が、クエリの情報が文書にどれだけ含まれているかを測るChamfer類似度の本質的な性質を、驚くほど正確に模倣する数学的な鍵となっています。Chamfer類似度は本来非対称な尺度であり、この非対称性をFDEの構築プロセスに組み込むことで、高い近似精度を実現しています。
理論的基盤と数学的保証
MUVERAは単なるヒューリスティックではなく、しっかりとした理論的基盤を持っています。研究チームは、FDEがChamfer類似度の強い近似を提供することを数学的に証明しており、これは指定された誤差範囲内での近似精度を保証する重要な結果です。
この理論的保証により、MUVERAは単なる経験的な高速化手法ではなく、原理的にマルチベクター検索を単一ベクトルのプロキシで実行できる確実な方法となっています。
MUVERAの驚くべき成果
Google ResearchがBEIR(Benchmarking Information Retrieval)ベンチマークで行った包括的な実験では、MUVERAは既存の最先端手法(PLAID)と比較して、以下の優れた結果を示しました。
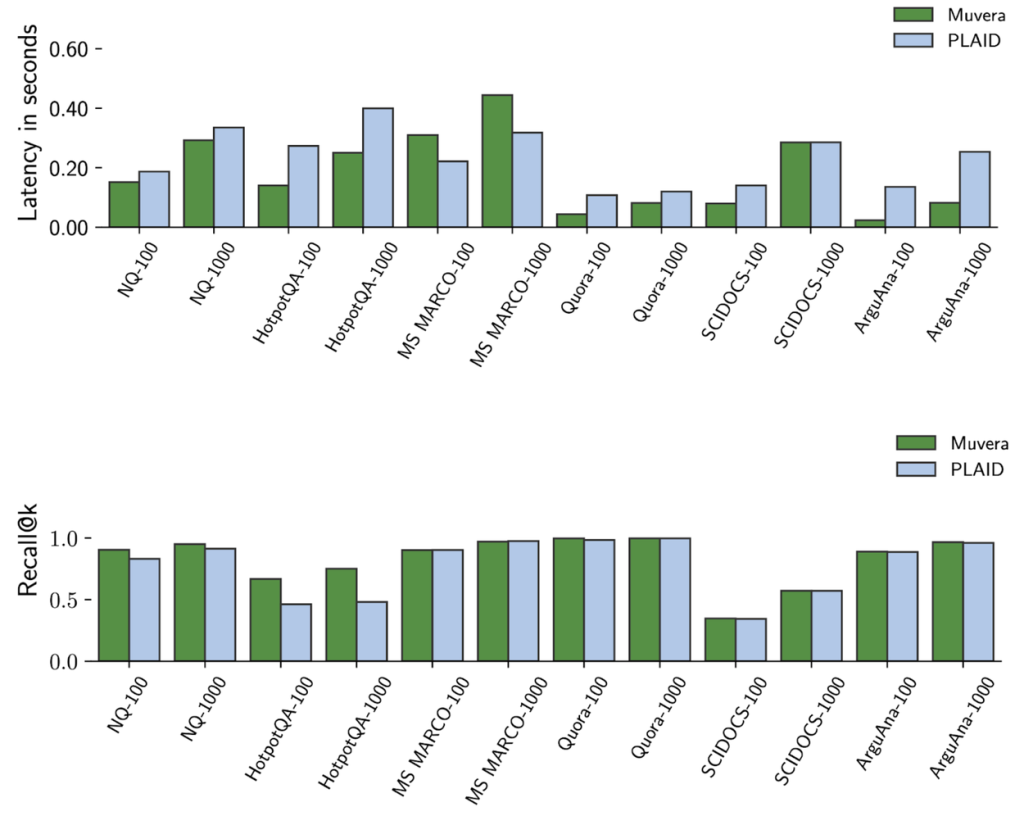
1. 速度の大幅な向上
- 検索にかかる時間(レイテンシ)を平均で90%削減
- BEIRデータセット全体で一貫した高速化を実現
2. 精度の維持・向上
- 検索の網羅性を示す指標(リコール率)は平均で10%向上
- シングルベクターヒューリスティック(PLAIDでも使用)を大幅に上回る性能
- 固定されたリコール率を達成するために必要な候補文書数を5~20分の1に削減
3. メモリ効率の大幅改善
- FDEは積量子化(product quantization)による圧縮に対して高い耐性を示す
- データサイズを32分の1にしても、検索品質への影響は最小限
- 10,240次元のFDEは元のマルチベクター表現とほぼ同じ表現サイズでありながら、検索時の比較回数を大幅に削減
4. 実用性の向上
- データ非依存の変換により、様々なドメインやデータセットに容易に適用可能
- ストリーミングアプリケーションでの使用にも対応
- 既存のMIPSアルゴリズムとの完全な互換性
これらの結果は、MUVERAがマルチベクター検索を、これまでの常識を覆すほど実用的で効率的なものにしたことを示しています。
オープンソース実装と今後の展開
Googleは研究の透明性と技術普及を促進するため、MUVERAのFDE構築アルゴリズムの実装をGitHubでオープンソースとして公開しています(https://github.com/google/graph-mining/tree/main/sketching/point_cloud)。これにより、研究者や開発者は実際にMUVERAを試用し、さらなる改良や応用を検討することができます。
まとめ
本稿では、Google Researchが開発した革新的な検索アルゴリズム「MUVERA」について詳しく解説しました。
MUVERAは、高精度だが低速なマルチベクター検索を、FDEという数学的に保証された疑似シングルベクターに変換することで、既存の高速な検索技術の恩恵を受けられるようにするという画期的なアイデアです。確率的木埋め込みの理論を基盤とし、Chamfer類似度の非対称性を巧妙に活用することで、精度を犠牲にすることなく、検索速度を劇的に向上させることに成功しました。
この技術は、膨大な情報の中から瞬時に最適な答えを見つけ出す必要がある検索エンジン、個人の好みに合わせた商品を提案する推薦システム、そして対話型AI、自然言語処理など、私たちの生活に関わる多くの分野に革命的な影響を与える可能性を秘めています。
特に、データ非依存の変換、理論的保証、メモリ効率の大幅な改善といった特徴により、MUVERAは学術的な研究だけでなく、実世界の大規模システムでの実用化にも大きな期待が寄せられています。Googleによるオープンソース実装の公開により、今後の技術の発展と普及がさらに加速されることが期待されます。
研究チームは、MUVERAのさらなる最適化により、より大きな性能向上とマルチベクター検索技術の広範な普及が実現されると予測しており、情報検索の未来を大きく変える技術として注目されています。








