
はじめに
本稿では、Googleが発表した新しいAIモデル「Gemma 3n」について、Google for Developers Blogの「Introducing Gemma 3n: The developer guide」という記事をもとに、その技術的な特徴と可能性を詳しく解説します。Gemma 3nは、スマートフォンなどのデバイス上で直接動作すること(オンデバイスAI)を主眼に置いたモデルです。
引用元記事
- タイトル: Introducing Gemma 3n: The developer guide
- 著者: Omar Sanseviero, Ian Ballantyne
- 発行元: Google for Developers Blog
- 発行日: 2025年6月26日
- URL: https://developers.googleblog.com/ja/introducing-gemma-3n-developer-guide/
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。

要点
- Gemma 3nは、デバイス上で直接動作する「オンデバイスAI」向けに設計されたGoogleの最新モデルである。
- テキストだけでなく、画像、音声、動画も入力として扱えるマルチモーダルAIである。
- MatFormerアーキテクチャという新技術により、デバイスの性能に応じてモデルの計算量を動的に調整することが可能である。
- Per-Layer Embeddings (PLE) というメモリ効率化技術により、少ないメモリ(RAM)のデバイスでも、より大きなモデルを動作させることができる。
- 新しい音声エンコーダと視覚エンコーダ(MobileNet-V5)を搭載し、音声認識・翻訳や画像・動画理解の性能が飛躍的に向上している。
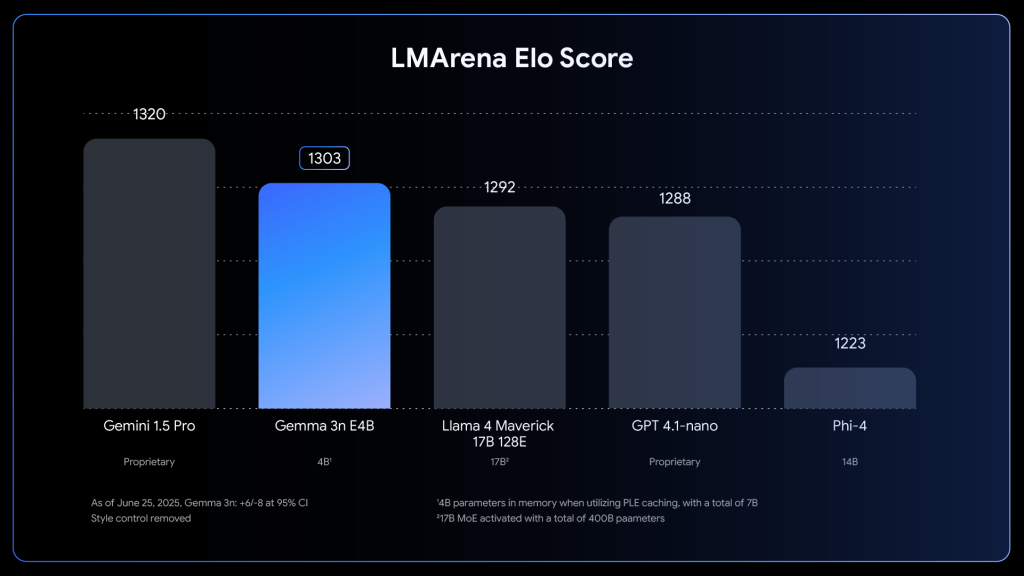
- 結果として、クラウド上の大規模モデルに匹敵する性能を、スマートフォンなどのエッジデバイスで実現することを目指したモデルである。
詳細解説
なぜ「オンデバイスAI」が重要なのか?
まず前提として、Gemma 3nが目指す「オンデバイスAI」の重要性についてご説明します。従来の多くのAIは、Googleなどの巨大なデータセンターにある高性能なサーバー(クラウド)で計算され、その結果がインターネットを通じて私たちのスマートフォンやPCに返されていました。
これに対してオンデバイスAIは、AIの計算をクラウドではなく、スマートフォンやPC、自動車などのデバイス内部で完結させます。これには、以下のような大きなメリットがあります。
- プライバシーの向上: 個人情報やカメラの映像などを外部のサーバーに送信する必要がないため、プライバシーが保護されます。
- 低遅延(サクサク動く): インターネット通信が不要なため、AIの応答が非常に速くなります。リアルタイム性が求められるAR(拡張現実)や通訳アプリなどで威力を発揮します。
- オフラインでの利用: インターネットに接続できない場所でもAI機能を利用できます。
Gemma 3nは、このオンデバイスAIを、これまでにない高いレベルで実現するために開発されたモデルなのです。
Gemma 3nを支える画期的な技術
Gemma 3nは、限られた計算能力とメモリしかないデバイス上で高い性能を発揮するために、いくつかの革新的な技術を搭載しています。
1. MatFormer:必要に応じてサイズを変える変幻自在のモデル
Gemma 3nの最も重要な核心技術が「MatFormer」です。これはロシアの入れ子人形「マトリョーシカ」から着想を得たアーキテクチャです。
大きなモデル(高性能だが計算も重い)の中に、それより小さいモデル(性能は少し落ちるが計算は軽い)が完全な形で含まれているような構造になっています。
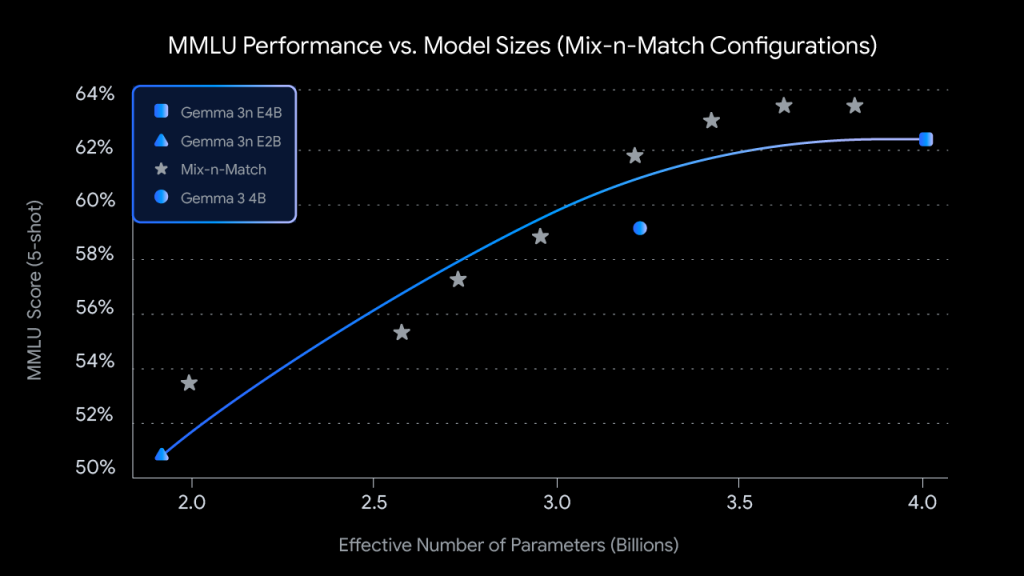
技術的な仕組みとしては、4億パラメータの有効E4Bモデルを訓練する際に、2億パラメータの有効E2Bサブモデルが同時に最適化されます。これは従来の「後から圧縮する」手法とは根本的に異なり、最初から2つのサイズのモデルが同じ重みを共有しながら学習される画期的な手法です。

これにより、開発者はデバイスの性能に合わせて、最適なサイズのモデルを選択できます。例えば、高性能な最新スマートフォンではフルサイズの「E4B」モデルを使い、少し前のモデルではより軽量な「E2B」モデル(推論速度が最大2倍高速)を使う、といった柔軟な対応が可能です。
さらに、Mix-n-Matchという技術により、E2BとE4Bの間の任意のサイズのモデルを作成することも可能です。具体的には、Feed Forward Network(FFN)の隠れ層次元を8192から16384の間で調整したり、特定のレイヤーを選択的にスキップしたりすることで、ハードウェア制約に合わせて細かくモデルサイズを調整できます。Googleは「MatFormer Lab」というツールも提供し、MMLU等のベンチマークで評価済みの最適な構成を開発者が簡単に取得できるようにしています。
将来的には、デバイスの負荷状況に応じて、一つのモデルがリアルタイムで自身の計算量を切り替える「弾性推論(Elastic Execution)」も可能になるとされています。これは、普段は省電力モードで動作し、必要な時だけフルパワーを発揮するような、賢いAIの実現に繋がります。
2. Per-Layer Embeddings (PLE):メモリを賢く節約する技術
オンデバイスAIの大きな課題の一つが、メモリ(特に高速なVRAM)の容量制限です。Gemma 3nは「Per-Layer Embeddings (PLE)」という技術でこの問題に取り組みます。
技術的には、モデルを構成するパラメータ(AIの知識のようなもの)のうち、常に高速なメモリに置いておく必要がある「コア部分」と、比較的低速なメモリ(CPUが管理するメインメモリ)からその都度読み込んでも問題ない「補助的な部分」に分割する技術です。
具体的な数値で説明すると、E2Bモデルは総パラメータ数5B(50億)、E4Bモデルは8B(80億)を持ちますが、PLEにより実際に高速メモリ(VRAM)に配置する必要があるのは、コアTransformer重みのみとなります。これはE2Bで約2B、E4Bで約4Bに相当し、各レイヤーに関連する埋め込みパラメータ群は効率的にCPU側で処理されます。
これにより、デバイスのGPUなどが搭載する高速メモリの消費を大幅に削減できます。54.4億あるパラメータのうち、高速メモリに載せる必要があるのは19.1億だけで済むようになります(約65%の削減)。これにより、メモリが少ないデバイスでも、実質的に大きなモデルを動かすことが可能になるのです。

さらに重要なのは、この手法がメモリ帯域幅の効率化も実現することです。高頻度でアクセスされるパラメータのみを高速メモリに配置し、CPU-GPU間の効率的なデータ転送により、全体的なレイテンシを最小化しています。
3. KV Cache Sharing:長いシーケンス処理の革新
Gemma 3nには、長い入力シーケンス(音声や動画ストリームなど)を効率的に処理するための「KV Cache Sharing」という技術も搭載されています。
技術的な仕組みとしては、モデルが初期入力を処理する段階(「プリフィル」フェーズと呼ばれる)で、ローカルアテンションとグローバルアテンションの中間層から得られるキー・値(KV)を、上位のすべての層と直接共有します。この最適化により、Gemma 3 4Bと比較してプリフィル性能が2倍向上しています。
これは特に、ストリーミング応答アプリケーションにおけるTime-to-First-Token(TTFT)の大幅な短縮を意味します。つまり、モデルが長いプロンプトシーケンスを理解し、最初のレスポンスを生成するまでの時間が劇的に短くなるのです。
この技術により、リアルタイム性が要求されるマルチモーダルアプリケーション(例:ライブ音声翻訳、動画解析など)での実用性が大幅に向上しています。
4. マルチモーダル性能の飛躍的向上
Gemma 3nはテキストだけでなく、目や耳を持ったAIのように、画像や音声も理解できます。
音声理解の技術革新:
Gemma 3nはUniversal Speech Model (USM)をベースとした高度な音声エンコーダを搭載しています。この技術的特徴として、160ms(約6トークン/秒)の音声を1トークンに変換し、言語モデルへ直接統合することで、音声コンテキストの粒度の細かい表現を実現しています。
この統合アーキテクチャにより、デバイス上でリアルタイムの文字起こし(ASR)や音声翻訳(AST)が可能になります。特に英語、スペイン語、フランス語、イタリア語、ポルトガル語間での翻訳性能が高く、Chain-of-Thought プロンプティング(「まずスペイン語で転写してから英語に翻訳する」といった段階的処理)を使用することで、さらなる性能向上が図れます。
現在の実装では30秒までの音声クリップを処理できますが、これは技術的制限ではなく実装上の制限です。基礎となる音声エンコーダはストリーミング対応で任意長の音声処理が可能であり、今後の実装で長時間音声訓練により制限が解除される予定です。これにより、海外旅行中にカメラをかざすだけでリアルタイムに通訳してくれるようなアプリが、より身近になるかもしれません。
視覚理解の技術革新:
新開発の「MobileNet-V5-300M」という非常に効率的な視覚エンコーダを搭載しています。この技術革新により、従来のSoViTベースライン(SigLipで訓練、蒸留なし)と比較して驚異的な性能向上を実現しています。
具体的な性能指標は以下の通りです:
- 処理速度: 量子化時13倍、非量子化時6.5倍の高速化
- パラメータ効率: 46%のパラメータ削減
- メモリ効率: 4倍小さいメモリフットプリント
- 精度: ビジョン言語タスクで大幅な精度向上
これらの性能向上は、高度な蒸留技術(教師モデルからの知識転移最適化)、効率的な畳み込み構造(モバイルデバイス向け最適化)、量子化対応設計(INT8量子化での高性能動作)といった複数のアーキテクチャ革新により実現されています。
実際のGoogle Pixel Edge TPUでは、最大60fpsでの画像・動画認識が可能です。例えば、スマートフォンのカメラに映るものをリアルタイムで分析し、情報を提供したり、目の前の風景について対話したりするような応用が、実用的なレベルで実現できるのです。
開発者エコシステムとの統合
Gemma 3nは発表と同時に、幅広い開発者ツールとの互換性を確保しています。対応フレームワークには、Hugging Face Transformers、llama.cpp、Google AI Edge、Ollama、MLX、Docker、NVIDIA Jetson、SGLang、Unsloth、vLLMなどが含まれており、開発者は慣れ親しんだツールを使ってすぐに開発を始めることができます。
Hugging Face Transformersでの利用
最も手軽に始められる方法として、Hugging Face Transformersが提供されています。以下の手順で簡単に利用開始できます:
# 必要なライブラリのインストール
pip install -U transformers timm torch accelerate基本的な使用例(テキスト生成):
from transformers import pipeline
import torch
# パイプラインの作成
pipe = pipeline(
"text-generation",
model="google/gemma-3n-E2B-it", # または "google/gemma-3n-E4B-it"
torch_dtype=torch.bfloat16,
device="cuda" # CPUの場合は "cpu"
)
# チャット形式での入力
messages = [{
"role": "user",
"content": [{"type": "text", "text": "AIについて説明してください"}]
}]
output = pipe(messages, max_new_tokens=200)
print(output[0]["generated_text"][-1]["content"])
マルチモーダル処理の例(画像理解):
from transformers import AutoProcessor, Gemma3ForConditionalGeneration
import torch
# モデルとプロセッサの読み込み
model = Gemma3ForConditionalGeneration.from_pretrained(
"google/gemma-3n-E4B-it",
device_map="auto",
torch_dtype=torch.bfloat16
).eval()
processor = AutoProcessor.from_pretrained("google/gemma-3n-E4B-it")
# 画像と質問の組み合わせ
messages = [{
"role": "user",
"content": [
{"type": "image", "image": "path/to/your/image.jpg"},
{"type": "text", "text": "この画像について説明してください"}
]
}]
inputs = processor.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt"
).to(model.device)
# 推論実行
with torch.inference_mode():
generation = model.generate(**inputs, max_new_tokens=100)
response = processor.decode(generation[0], skip_special_tokens=True)
print(response)
Google AI EdgeとGoogle AI Studioでの利用
Googleの公式プラットフォームでも利用可能です:
- Google AI Studio: ブラウザベースの対話型環境で、コードを書かずにGemma 3nを試用可能
- Google AI Edge: モバイルアプリケーション開発向けの最適化されたランタイム環境
モバイル・エッジデバイス向けのデプロイメント
ONNX形式でのモデル提供により、様々なランタイム環境での利用が可能です:
# ONNX Runtime使用例(iOS/Androidアプリ開発)
pip install onnxruntimeJavaScript/Web開発者向け
Transformers.js(バージョン3.6.0以降)を使用してWebブラウザで直接実行可能:
import { pipeline } from '@huggingface/transformers';
const generator = await pipeline(
'text-generation',
'google/gemma-3n-E2B-it'
);
const output = await generator("AIの未来について", {
max_new_tokens: 100,
});
その他のフレームワーク利用例
Ollama(ローカル環境での簡単実行):
# Ollamaでの利用
ollama pull gemma3n:E2B
ollama run gemma3n:E2B "AIについて教えて"llama.cpp(高効率なCPU推論):
# llama.cppでの利用(テキスト入力のみ現在対応)
./main -m gemma-3n-E2B-q4_0.gguf -p "質問: AIとは何ですか?"MLX(Apple Silicon最適化):
import mlx.core as mx
from mlx_lm import load, generate
model, tokenizer = load("google/gemma-3n-E2B-it")
response = generate(model, tokenizer, prompt="AIについて", verbose=True)ファインチューニングとカスタマイズ
Gemma 3nは、特定のドメインやタスクに合わせてファインチューニングが可能です。Googleは以下のリソースを提供しています:
- Google Colabでの無料ファインチューニング: 専用ノートブックにより、無料のColab環境でモデルをカスタマイズ可能
- 音声タスク特化ノートブック: 音声データセットでの専門的なファインチューニング手順
- Hugging Face Gemma Recipesリポジトリ: 様々な用途向けのスクリプトとノートブック集
ハードウェア要件とパフォーマンス 実際の動作環境での性能目安:
| モデル | VRAM要件 | CPU推論 | GPU推論(FP16) | 推奨デバイス |
|---|---|---|---|---|
| E2B | ~2GB | 可能 | RTX 3060以上 | 中級スマートフォン以上 |
| E4B | ~4GB | 推奨しない | RTX 4060以上 | 高性能スマートフォン、PC |
ライセンスとアクセス制限
Gemma 3nの利用には、Googleの使用ライセンスへの同意が必要です:
- Hugging Faceでのアクセス時に自動的にライセンス確認
- 商用利用可能(ライセンス条項に準拠)
- オープンソースプロジェクトでの利用歓迎
コミュニティとサポート
- GitHub: 公式クックブックリポジトリでサンプルコード提供
- Hugging Face Hub: モデルカード、使用例、コミュニティディスカッション
- Google AI for Developers: 公式ドキュメント、チュートリアル
また、技術的な詳細については、Googleが今後リリース予定の「MobileNet-V5技術レポート」で、モデルアーキテクチャ、データスケーリング戦略、高度な蒸留技術について、さらに詳しい解説が提供される予定です。
まとめ
Gemma 3nは、単なるAIモデルのアップデートではなく、AIをクラウドから解放し、私たちの手元にあるデバイスで当たり前に使えるようにするための、重要な一歩と言えます。
- MatFormerによる柔軟なパフォーマンス調整と同時最適化技術
- PLEによる卓越したメモリ効率と階層化メモリ活用
- KV Cache Sharingによる長いシーケンス処理の最適化
- USMベース音声エンコーダによる高精度なリアルタイム音声処理
- MobileNet-V5による超高効率な視覚理解
- 音声と視覚を高度に理解する統合マルチモーダル能力
これらの技術革新により、開発者はこれまで以上にプライバシーに配慮し、応答性が高く、そしてオフラインでも動作する、新世代のAIアプリケーションを創造できるようになります。特に、メモリ使用量を65%削減しながら2倍の推論速度を実現し、60fpsでの視覚処理と6トークン/秒での音声処理を同時に行えるという技術的成果は、エッジデバイスでのAI活用の可能性を根本から変えるものです。
Googleは、この技術を使って社会に貢献するアプリケーションを募集するチャレンジ(Gemma 3n Impact Challenge、賞金総額15万ドル)も開催しており、コミュニティと共に未来を創っていく姿勢を明確にしています。Gemma 3nが、私たちの生活をどのように変えていくのか、今後の展開が非常に楽しみです。








