はじめに
近年、目覚ましい発展を遂げている大規模言語モデル(LLM)は、私たちの社会に大きな変革をもたらしつつあります。これらのモデルは、大量のデータとパラメータを用いた学習(事前学習)によって、驚くほど汎用的な知能を獲得してきました。しかし、LLMが持つ潜在的な能力を最大限に引き出し、現実世界での有効性を高めるためには、推論時(テスト時)における工夫が不可欠です。
そこで注目されているのが、「テストタイムスケーリング(TTS)」、別名「テストタイムコンピューティング」と呼ばれる研究分野です。TTSとは、LLMが与えられた問題に対して、より多くの計算資源を投入することで、その問題解決能力をさらに向上させる技術の総称です。最近の研究では、TTSが数学やプログラミングといった専門的な推論タスクだけでなく、一般的なオープンエンドの質問応答においても、目覚ましい成果を上げることが示されています。
このようにTTSに関する研究が急速に進展している一方で、その全体像を体系的に理解するための包括的な調査(サーベイ)が求められていました。そのようなニーズに応える形で発表された論文「What, How, Where, and How Well? A Survey on Test-Time Scaling in Large Language Models」 をご紹介します。
本論文は、TTS研究を「何をスケールするのか(What)」、「どのようにスケールするのか(How)」、「どこでスケールするのか(Where)」、「どの程度スケールするのか(How Well)」という4つの主要な側面から捉え、統一的かつ多次元的なフレームワークを提案しています。本記事では、このフレームワークに基づきながら、TTSの最新動向、応用例、評価方法などを分かりやすく解説していきます。
なお、数式などの詳細に関しては、論文を参照するようにお願い致します。
引用論文
- 論文タイトル:What, How, Where, and How Well? A Survey on Test-Time Scaling in Large Language Models
- 論文URL:https://arxiv.org/abs/2503.24235
- 発表日:2025年3月31日
・あくまで個人の理解に基づくものであり、正確性に問題がある場合がございます。
必ず参照元論文をご確認ください。
・本記事内での画像は、上記論文より引用しております。
要点
本論文で紹介されているテストタイムスケーリング(TTS)に関する重要なポイントは以下の通りです。
- TTSは、大規模言語モデル(LLM)の潜在能力を推論時にさらに引き出すための重要な研究分野です。
- 事前学習における計算資源の増大の効果が徐々に薄れる中、TTSが新たなブレークスルーの鍵として注目されています。
- TTSは、数学やプログラミングといった専門的なタスクから、一般的な質問応答まで、幅広いタスクにおいてLLMの性能を向上させることができます。
- 本論文では、TTS研究を「何を(What)」、「どのように(How)」、「どこで(Where)」、「どの程度(How Well)」スケールするのかという4つの軸で整理した統一的なフレームワークが提案されています。
- このフレームワークに基づき、様々なTTSの手法、応用事例、評価方法が網羅的に解説されています。
詳細解説
本論文では、テストタイムスケーリング(TTS)を理解するための4つの主要な側面が詳細に解説されています。以下では、論文の項目に沿って、説明していきます。
1. Introduction(導入)
大規模言語モデル(LLM)は、学習時のスケーリング(より多くのデータとパラメータの投入)によって汎用的な知能を獲得し、人工汎用知能(AGI)への重要な一歩として近年登場しました。しかし、これらのモデルが持つ知能を推論時に最大限に引き出し、現実世界での有効性を高める方法が依然として重要な課題です。
プリトレーニング時代の計算資源のスケーリングへの熱意が薄れるにつれて、テストタイムスケーリング(TTS、別名「テストタイムコンピューティング」)が注目を集める研究分野となっています。近年の研究では、TTSがLLMの問題解決能力をさらに引き出し、数学やコーディングなどの専門的な推論タスクだけでなく、オープンエンドの質疑応答のような一般的なタスクにおいても大きな進歩を可能にすることが示されています。しかし、この分野における最近の取り組みが急増しているにもかかわらず、体系的な理解を提供する包括的なサーベイがありませんでした。
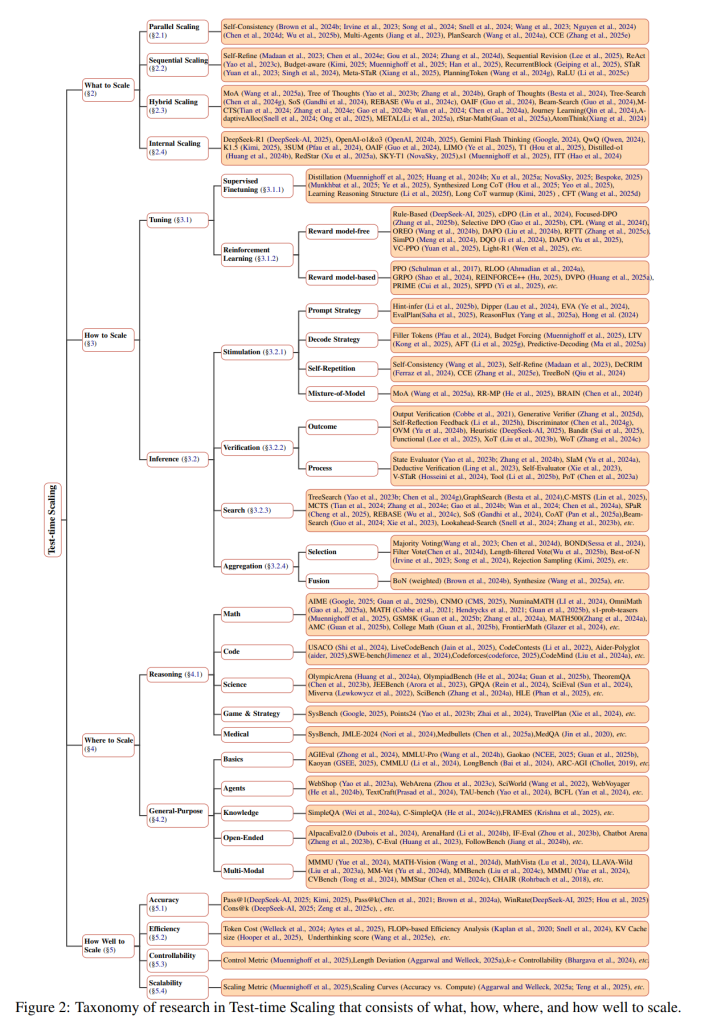
本論文では、TTS研究の4つの主要な側面(何をスケールするか、どのようにスケールするか、どこでスケールするか、どのようにうまくスケールするか)に沿って構造化された、統一的で多次元的なフレームワークを提案します。この分類に基づいて、手法、応用シナリオ、評価の側面に関する広範なレビューを実施し、より広範なTTSの状況の中で個々の技術が持つ独自の機能的役割を強調する組織的な分解を提示します。
また、この分析から、これまでのTTSの主要な開発軌跡を抽出し、実践的な展開のための実践的なガイドラインを提供します。さらに、いくつかの未解決の課題を特定し、さらなるスケーリング、技術の機能的本質の明確化、より多くのタスクへの汎化、およびより多くの属性を含む、有望な将来の方向性に関する洞察を提供します
2. What to Scale(何をスケールするのか)
この項目では、テスト時に計算資源を投入し、性能向上を目指す対象、つまり「何をスケールするのか」について議論されています。論文では、以下の4つのカテゴリが挙げられています。
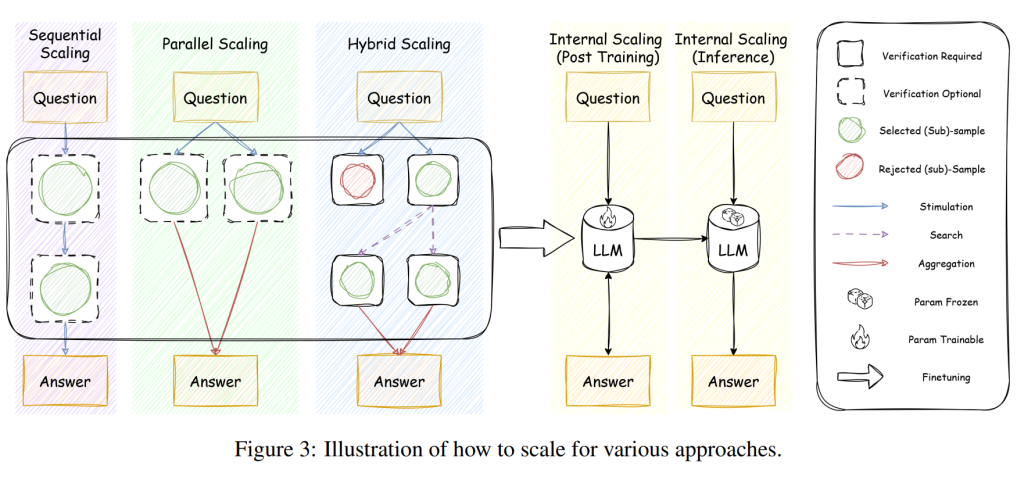
2.1 Parallel Scaling(並列スケーリング):
これは、LLMに同じ質問やタスクを複数回行わせ、複数の異なる回答や思考プロセスを生成し、それらを統合して最終的な回答を得る手法です。例えば、自己整合性(Self-Consistency)は、複数の回答を生成し、最も頻繁に出現する回答を最終的な答えとするものです。また、複数のAIエージェントを協調させるMulti-Agentsや、複数の解決策候補を探索するPlanSearch、異なる視点からの推論を組み合わせるCCE (Zhang et al., 2025e)などがこのカテゴリに含まれます。
並列スケーリングの効果は、少なくとも1つの正解を含む回答が生成される可能性(カバレッジ)と、そこから正解を適切に選択・統合する能力(アグリゲーション品質)の両方に依存します。認知科学の研究でも、複雑な問題には複数の有効な解決策が存在し、より多くの回答を生成することで正解にたどり着く可能性が高まることが示唆されています。
2.2 Sequential Scaling(逐次スケーリング):
このアプローチでは、LLMが生成した回答や思考プロセスを段階的に改善していきます。自己改善(Self-Refine)は、LLM自身が前の回答を評価し、フィードバックに基づいて回答を洗練させる手法です。ReAct (Reasoning and Acting)は、推論と行動を交互に行うことで、より複雑なタスクに対応します。
計算予算を意識しながら推論を行うBudget-awareな手法や、RecurrentBlock (Geiping et al., 2025)、段階的な推論を促すSTaR (Self-Taught Reasoner)、Meta-STaR (Xiang et al., 2025)、PlanningToken (Wang et al., 2024g)、RaLU (Reasoning-as-Logic-Units)などがこのカテゴリに分類されます。
2.3 Hybrid Scaling(ハイブリッドスケーリング):
これは、並列スケーリングと逐次スケーリングの手法を組み合わせることで、それぞれの利点を活かし、より高度な問題解決を目指すものです。思考の木(Tree of Thoughts; ToT)は、複数の思考パスを探索し、各パスの評価に基づいて探索を深める手法です。思考のグラフ(Graph of Thoughts; GoT)は、より複雑な思考の流れを表現します。
Tree-Search (Chen et al., 2024g)、SoS (Stream of Search)、REBASE (Wu et al., 2024c)、OAIF (Guo et al., 2024)、Beam-Search、M-CTS (Monte Carlo Tree Search)、Journey Learning (Qin et al., 2024)、A-daptiveAlloc (Snell et al., 2024)、METAL (Li et al., 2025a)、rStar-Math (Guan et al., 2025a)、AtomThink (Xiang et al., 2024)などが含まれます。
2.4 Internal Scaling(内部スケーリング):
これは、外部からの指示や追加の計算資源に頼るのではなく、LLM自身の内部パラメータの中で、推論に必要な計算量を自律的に決定し、実行する能力を高めることを目指すものです。具体的には、多段階の推論タスク(例えば、外部スケーリングによって生成された長いCoTの例)を含むデータでモデルを再学習(Φ : (M0,D) → M1)します。驚くべきことに、結果指向の報酬モデリング(例えば、DeepSeek-R1、OpenAI-o1&o3)を用いた強化学習により、モデルが自律的に推論プロセスを拡張できることが示されています。
Gemini Flash Thinking (Google, 2024)、QwQ (Qwen, 2024)、K1.5 (Kimi, 2025)、3SUM (Pfau et al., 2024)、OAIF (Guo et al., 2024)、LIMO (Ye et al., 2025)、T1 (Hou et al., 2025)、Distilled-o1 (Huang et al., 2024b)、RedStar (Xu et al., 2025a)、SKY-T1 (NovaSky, 2025)、s1 (Muennighoff et al., 2025)、ITT (Hao et al., 2024)などがこのカテゴリに属します。内部スケーリングは、他のスケーリング手法と比較して効率性が高い傾向がありますが、学習には相応のリソースが必要となるため、実務者にとっては利用しにくい場合があります。
3. How to Scale(どのようにスケールするのか)
この項目では、前述の「何をスケールするのか」を実現するための具体的な方法論、つまり「どのようにスケールするのか」について解説されています。論文では、チューニングに基づくアプローチと、推論に基づくアプローチの2つが紹介されています。
3.1 Tuning-based Approaches(チューニングに基づくアプローチ):
事前学習済みのLLMを特定のTTSの目的に合わせてさらに学習(ファインチューニング)するアプローチです。
3.1.1 Supervised Finetuning (SFT)(教師ありファインチューニング):
特定のタスクや推論形式(例えば、長い連鎖的思考;Long Chain-of-Thought; CoT)のデータを用いてモデルを学習します。知識蒸留(Distillation)は、大規模なモデルの知識をより小さなモデルにtransferする技術で、TTSにおいても効率的な推論を可能にするために用いられます。
Synthesized Long CoT (Hou et al., 2025; Yeo et al., 2025)、Learning Reasoning Structure (Li et al., 2025f)、Long CoT warmup (Kimi, 2025)、CFT (Wang et al., 2025d)などがSFTの具体的な手法として挙げられています。
3.1.2 Reinforcement Learning (RL)(強化学習):
報酬関数に基づいてモデルの行動を最適化する手法です。近年、強化学習とpreference optimization(人間の好みなどを反映した最適化)の進展により、LLMの推論能力が大幅に向上しています。
報酬モデルフリーの手法としては、ルールベースの報酬(DeepSeek-AI, 2025)、cDPO (Lin et al., 2024)、Focused-DPO (Zhang et al., 2025b)、Selective DPO (Gao et al., 2025b)、CPL (Wang et al., 2024f)、OREO (Wang et al., 2024b)、DAPO (Liu et al., 2024b; Yu et al., 2025)、RFTT (Zhang et al., 2025c)、SimPO (Meng et al., 2024)、DQO (Ji et al., 2024)、VC-PPO (Yuan et al., 2025)、Light-R1 (Wen et al., 2025)などがあります。
報酬モデルベースの手法としては、PPO (Proximal Policy Optimization)、RLOO (Ahmadian et al., 2024a)、GRPO (Shao et al., 2024)、REINFORCE++ (Hu, 2025)、DVPO (Huang et al., 2025a)、PRIME (Cui et al., 2025)、SPPD (Yi et al., 2025)などが挙げられます。特に、DeepSeek R1は、検証可能な報酬を用いたRLを導入し、効率的かつ信頼性の高いモデル最適化を実現しています。
また、SimpleRL (Zeng et al., 2025b)やDeepScaler (Luo et al., 2025)、SimpleRL-Zoo (Zeng et al., 2025a)、X-R1 (X-R1Team, 2025)、TinyZero (Pan et al., 2025b)、Open-Reasoner-Zero (Hu et al., 2025; Zeng et al., 2025a,b)、OpenR (Wang et al., 2024c)、OpenRLHF (Hu et al., 2024)、OpenR1 (HuggingFace, 2025)、Logic-RL (Xie et al., 2025)、AReaL (AntResearch-RL-Lab, 2025)といったオープンソースの強化学習フレームワークの登場も、研究開発を加速させています。
3.2 Inference-based Approaches(推論に基づくアプローチ):
モデルのパラメータを直接変更するのではなく、推論時に様々な工夫を凝らすことで性能向上を目指すアプローチです。
3.2.1 Stimulation(刺激):
LLMへの入力(プロンプト)や出力の生成方法を工夫することで、より良い推論を引き出すことを目指します。
プロンプト戦略としては、考える時間を促すHint-infer (Li et al., 2025b)や、Dipper (Lau et al., 2024)、EVA (Ye et al., 2024)、EvalPlan (Saha et al., 2025)、ReasonFlux (Yang et al., 2025a)、Hong et al. (2024)などがあります。
デコード戦略としては、無関係なトークンを挿入するFiller Tokens (Pfau et al., 2024)、思考の終了トークンの生成を抑制するBudget Forcing (Muennighoff et al., 2025)、潜在的な思考ベクトルに基づいてデコードするLTV (Kong et al., 2025)、提案を繰り返し集約するAFT (Li et al., 2025g)、先見性を評価してデコード分布を再調整するPredictive-Decoding (Ma et al., 2025a)などがあります。自己反復(Self-Repetition)による自己整合性(Self-Consistency)、自己改善(Self-Refine)、DeCRIM (Ferraz et al., 2024)、CCE (Zhang et al., 2025e)、TreeBoN (Qiu et al., 2024)などもこのカテゴリに含まれます。
また、複数のモデルを並列に実行し、結果を組み合わせるMixture-of-Model(MoA、RR-MP、BRAIN)といったアプローチも存在します。
3.2.2 Verification(検証):
生成された回答や思考プロセスの品質を評価し、誤りがないかなどを確認する手法です。結果検証(Outcome Verification)では、最終的な出力の正しさや品質を評価します。
具体的には、正解データで学習された検証モデル(Generative Verifier、Discriminator、OVM)、ヒューリスティックなルール(Heuristic)、機能的な評価(Functional)、バンディットアルゴリズム(Bandit)、自己反省フィードバック(Self-Reflection Feedback)、外部ツールを用いた検証(XoT)、多視点からの検証(WoT、Multi-Agent Verifiers)、ユニットテスト(Unit Test)など様々な手法が用いられます。
プロセス状態評価(Process State Evaluator)では、推論の各ステップにおける思考の質を評価します。例えば、思考の木(ToT)における自己評価(Self-Evaluator)や、V-STaR (Verifier for Self-Taught Reasoner)、Tool (Li et al., 2025b)、PoT (Program of Thoughts)などが該当します。
複数の視点から検証を行うアプローチも提案されており、検証エージェントの数を任意に増やし、意味的な基準と検証エージェントを分離する試み(Lifshitz et al., 2025)や、様々な要素を考慮して各サンプルをスコアリングする検証エージェント(Parmar et al., 2025; Saad-Falcon et al., 2024)、ユニットテストに基づいた検証(Saad-Falcon et al., 2024)などがあります。
3.2.3 Search(探索):
考えられる推論の経路を探索し、より良い解決策を見つけ出すことを目指します。
探索木(Tree Search、Graph Search)、モンテカルロ木探索(Monte Carlo Tree Search; MCTS、C-MSTS)、SPaR (Self-Play with Tree-Search Refinement)、REBASE (Wu et al., 2024c)、SoS (Stream of Search)、CoAT (Chain-of-Associated-Thoughts)、ビームサーチ(Beam-Search、Lookahead-Search)などが代表的な手法です。
モンテカルロ木探索は、制約のあるテキスト生成において、識別器によって誘導されるデコード段階で採用されたり、コード生成における計画能力を向上させるために拡張されたり、LLMの自己改善フレームワークの重要な要素として組み込まれたり、長期的な計画や深い探索木を必要とする問題に対処するために調整されたりしています。
識別器が探索強化された計画における主要なボトルネックであるという指摘や、探索プロセスを統一的な言語で体系化し、探索プロセスからのデータとフィードバックを用いてLLMを訓練する試み、様々な探索アルゴリズムを経験的に分析し、パレート最適なテストタイムスケーリングを目指した報酬バランス探索アルゴリズムの設計、多様性の考慮を組み込んだビームサーチの拡張なども研究されています。
3.2.4 Aggregation(集約):
複数の解を統合して最終的な意思決定を行うことで、モデルの予測の信頼性とロバスト性を高める手法です。これは、特に並列スケーリングによって複数の候補解が生成された場合や、探索ベースの手法によって多様な推論パスが得られた場合に、それらを一つにまとめる役割を果たします。
Selection(選択)
選択カテゴリでは、生成された複数の候補サンプルの中から、最も適切と思われるものを一つ選び出し、それを最終的な出力とします 。この選択の基準は、様々なアプローチによって異なります。
Fusion融合(融合)
融合カテゴリでは、複数の候補サンプルを直接的に一つに統合して、最終的な出力を生成します。これは、候補サンプルの品質が低い場合に、単に選択するよりも良い結果が得られる可能性があると考えられています。
4. Where to Scale(どこでスケールするのか)
この項目では、TTSが実際にどのようなタスクや領域で活用され、その効果を発揮しているのか、つまり「どこでスケールするのか」について紹介されています。
4.1 Reasoning(推論):
- Mathematical Reasoning(数学的推論):算数から高度な数学の問題まで、様々な数学的推論タスクにおいてTTSが性能向上に貢献しています。具体的には、AIME、CNMO、NuminaMATH、OmniMath、MATH、s1-prob-teasers、GSM8K、MATH500、AMC、College Math、FrontierMathといったベンチマークで評価されています。
- Programming & Code Generation(プログラミング、コード生成):プログラミングの問題解決やコード生成においてもTTSは有効です。USACO、LiveCodeBench、CodeContests、Aider-Polyglot、SWE-bench、Codeforces、CodeMindなどが関連するベンチマークやツールです。
- Game Playing and Strategic Reasoning(ゲームプレイと戦略的推論):ゲームのプレイや戦略立案においてもTTSが活用されています。SysBench (Google, 2025)、Points24、TravelPlanなどが具体的な例です。
- Scientific Reasoning(科学的推論):科学的な知識や推論を必要とするタスクにもTTSが応用されています。OlympicArena、OlympiadBench、TheoremQA、JEEBench、GPQA、SciEval、Miverva、SciBench、HLEなどが評価に用いられるデータセットです。
- Medical Reasoning(医学的推論):医療に関する質問応答や診断支援など、医療分野へのTTSの応用も研究されています。SysBench、JMLE-2024、Medbullets、MedQAなどが関連するデータセットです。
4.2 General-Purpose(汎用):
- Basics(基礎):一般的な知識や理解力を評価するタスクにもTTSが用いられています。AGIEval、MMLU-Pro、Gaokao、Kaoyan、CMMLU、LongBench、ARC-AGIなどが評価に用いられるベンチマークです。
- Open-Ended(オープンエンド):制約の少ない自由な形式の質問応答や対話においてもTTSが性能向上に貢献しています。AlpacaEval2.0、ArenaHard、IF-Eval、Chatbot Arena、C-Eval、FollowBenchなどが評価に用いられるプラットフォームやベンチマークです。
- Agents(エージェント):自律的に環境と対話し、タスクを遂行するエージェントの開発においてもTTSが重要な役割を果たしています。WebShop、WebArena、SciWorld、WebVoyager、TextCraft、TAU-bench、BCFLなどが関連研究やベンチマークです。
- Knowledge-intensive(知識):事実に関する質問応答など、知識集約型のタスクにもTTSが適用されています。SimpleQA、C-SimpleQA、FRAMESなどが評価に用いられるデータセットです。
- Multi-Modal(マルチモーダル):テキストだけでなく、画像や音声など複数のモダリティを扱うタスクにおいてもTTSの研究が進んでいます。MMMU、MATH-Vision、MathVista、LLAVA-Wild、MM-Vet、MMBench、MMMU、CVBench、MMStar、CHAIRなどが関連するベンチマークです。
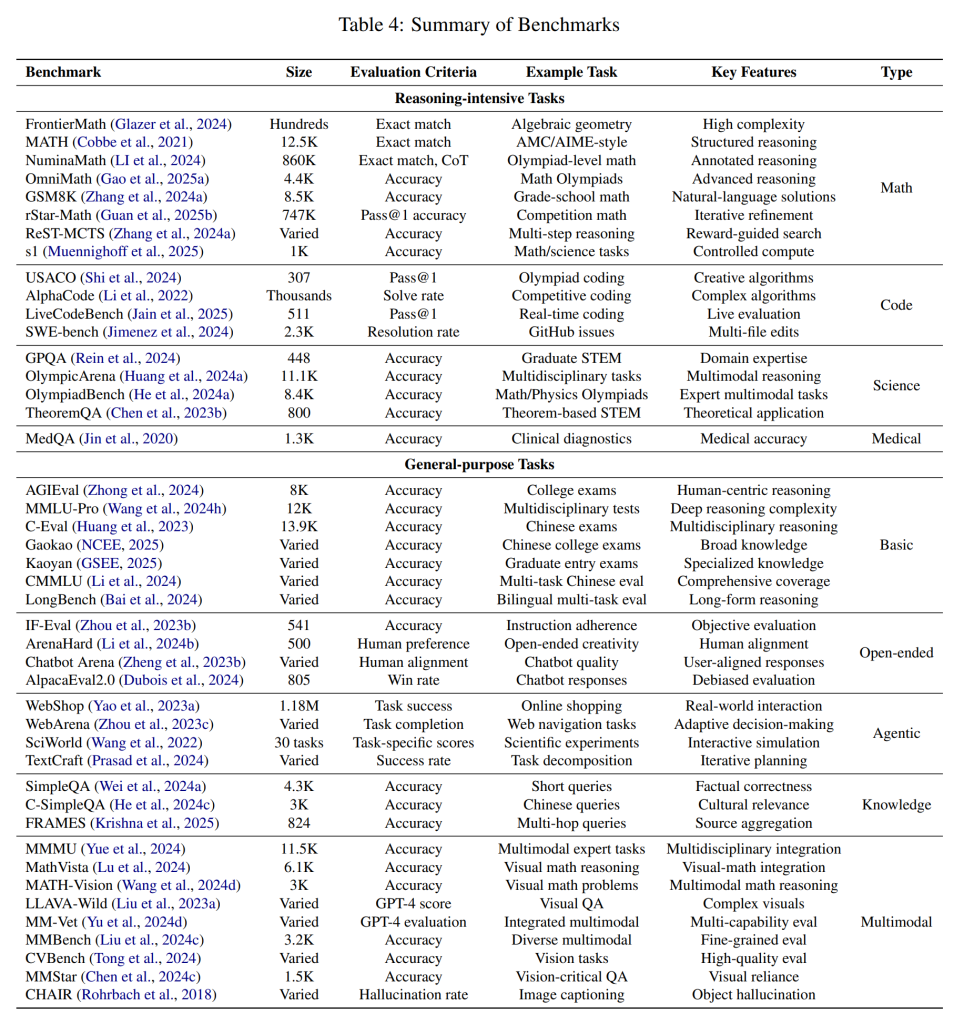
5. How Well to Scale(どの程度スケールするのか)
この項目では、TTSの手法の有効性をどのように評価するのか、つまり「どの程度スケールするのか」を測るための評価指標について議論されています。論文では、性能、効率性、制御可能性、拡張性の4つの主要な側面が挙げられています。
5.1 Performance(性能):
生成されたソリューションの正しさを評価する指標です。
- Pass@1:モデルが最初に生成した回答が正解である割合を測る最も広く用いられる指標の一つです。
- Pass@k:モデルが生成した上位k個の回答の中に正解が含まれる割合を評価します。
- WinRate:異なるモデルや設定との比較において、あるモデルがより良い回答を生成する割合を示します。
- Cons@k (Consistency@k):複数回生成された上位k個の回答の一貫性を評価する指標です。
これらの指標は、数学的推論やプログラミングのベンチマークなどで頻繁に用いられます。
5.2 Efficiency(効率性):
TTSによって性能が向上する一方で、どれだけの計算コストがかかるのかを評価する指標です。
- Token Cost:生成されたトークンの総数を測ります。
- FLOPs-based Efficiency Analysis:演算回数に基づいて効率性を分析します。
- KV Cache size:Transformerモデルの推論時にキャッシュされるキーと値のペアのサイズを測り、メモリ使用量と推論速度に影響します。
- Underthinking score:モデルが問題に対して十分に深く思考せずに回答してしまう度合いを評価する指標で、有用な洞察が早い段階で現れるものの、それが追求されない場合に高い値を示します。
5.3 Controllability(制御可能性):
TTSの手法によって、生成される回答の特性(例えば、長さ、スタイルなど)をどれだけ制御できるかを評価する指標です。
- Control Metric:指定された計算予算の範囲内に、実際に観測された計算量(例えば、思考トークンの数など)がどの程度収まっているかを定量化する指標です。
- Length Deviation Metrics:モデルが出力長をどの程度制御できるかを定量化する指標です。
- k–ϵ Controllability:言語モデルのプロンプトベースの操縦性を特徴づけるための形式的な指標です。
5.4 Scalability(拡張性)
計算資源(トークン予算、サンプル数、推論ステップ数など)の増加に応じて、TTS手法がどれだけ効果的に性能(精度など)を向上させられるかを測る指標です。
- Scaling Metric:計算量の増加に伴う性能向上を平均的な勾配として捉え、数値化するものです
- Scaling Curves:計算資源(トークン予算、反復深度、サンプル数など)の変化に応じて、精度、パスレート、Exact Match (EM) スコアなどの性能指標がどのように推移するかをグラフで視覚的に表現したものです
6. Organization and Trends in Test-time scaling(テストタイムスケーリングの構成とトレンド)
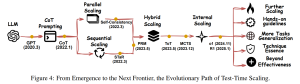
この章では、論文で提案された4つの軸(何をスケールするか、どのようにスケールするか、どこでスケールするか、どのようにうまくスケールするか)に基づいて既存の研究文献を分解し、テストタイムスケーリング(TTS)の分野におけるトレンドを分析しています。下図に示すように、異なる技術革新を持つ研究は、おおむね一貫した道筋を辿っています。
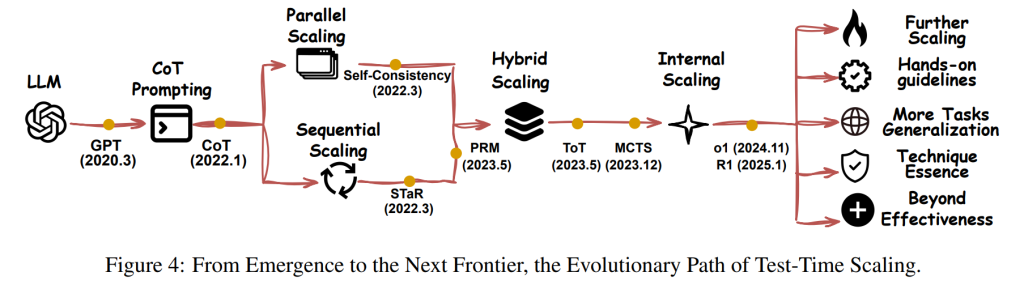
2022年から2023年にかけて、研究者たちはより複雑な解決策を生成するためにLLMを導く構造化された推論を重視しました。2024年には、PRM(Process Reward Model)やMCTS(Monte Carlo Tree Search)のような手法が登場し、複雑な推論軌跡の自動的な教師あり学習を可能にし、TTSの性能向上に貢献しました。その後のアプローチ、例えばo1(OpenAI)やR1(DeepSeek-AI)は、純粋な強化学習(RL)も包括的で論理的に健全な推論を引き出すことができることを示しました。
表5では、既存の文献における推論スケーリングを実行する際の一般的な組み合わせが示されています。重要な点として、これらの技術は相互に排他的ではなく、むしろ補完的です。例えば、R1は予備的なウォームアップステップとして拒否サンプリングによるSFT(Supervised Finetuning)を必要とします。したがって、より強力なスケーリングを実現するには、これらの手法を体系的に統合する必要があります。RLフレームワーク内であっても、より複雑なシナリオに効果的に対処するためには、合成されたCoT(Chain-of-Thought)アプローチを活用し、構造化された推論戦略を組み込むべきです。
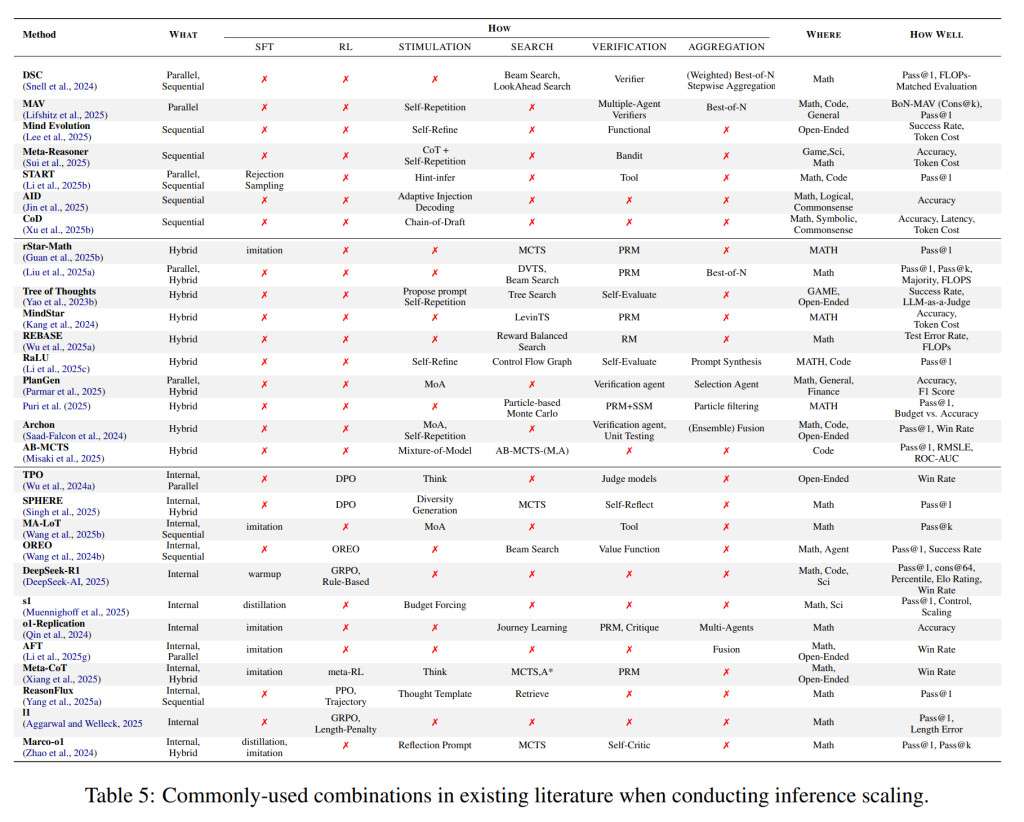
研究者たちは、すべての問題に有効な単一のシンプルなスケーリングソリューションは存在しないことを発見しました。ますます多くの研究者が、最適スケーリングソリューションに焦点を当てる傾向にあります。
推論ベースのアプローチとチューニングベースのアプローチの境界は曖昧になりつつあります。その結果、スケーリングの対象(何をスケールするか)は、異なる段階間で変化します。一部の論文では、推論ベースのアプローチから高品質なデータを合成し、それをチューニングデータとして使用することで、推論ベースの能力をLLMにチューニングしています。他の論文では、トレーニング段階と推論段階の両方でLLMの能力をより良く活用するための様々な技術が提案されています。
7. A Hand-on Guideline for Test-time Scaling(テストタイムスケーリングの実践的ガイドライン)
この章では、理論的な分類から、実践的で実用的なTTSのガイドラインを提供することに焦点を当てています。効果的なTTSの導入を促進するための明確で実行可能な指示と技術的な道筋を提供することを目的としています。
以下は、一般的な問題に対する実践的ガイドラインです。(以下は、基本的に論文の直訳となります。)
Q: TTSはどのようなタスクに役立ちますか?
A: ほぼすべてのタスクです!オリンピックレベルの数学、複雑なコーディング、ゲームベースの課題といった伝統的な推論タスクは、TTSによって大幅な改善が見られています。コミュニティの観察によると、TTSはコメント生成や評価のようなオープンエンドなタスクの性能も向上させる可能性があります。しかし、出力が長文になる傾向があり、客観的なベンチマークが不足しているため、これらのタスクを定量的に評価することは本質的に難しく、決定的な主張をすることは困難です。それ以外にも、医療推論や法律のような、より現実的で複雑な、長期的なシナリオでも、TTS戦略を通じて有望な成果が示されています。
Q: TTSパイプラインを迅速に実装したい場合、考慮すべき主要な経路は何ですか?初心者が最小限のコストでTTSを使用するにはどうすればよいですか?
A: 大まかに言って、テストタイムスケーリングには3つの主要な技術的経路があります。(i) 推論時の意図的な推論手順、(ii) 複雑な推論軌跡の模倣、(iii) RLベースのインセンティブ付与。もし、最小限のコストで強力なTTSがタスクにもたらす可能性のある上限を迅速に把握したいのであれば、(iii)でトレーニングされたモデルを直接利用できます。最小限のコストでTTSのベースラインを開発したいのであれば、(i)から始めることができます。(i)が期待を満たす結果を生み出したら、(ii)を適用して結果をさらに検証し、一般化することができます。
Q: これらのパイプラインは相互に排他的ですか?最先端のTTS戦略を設計するにはどうすればよいですか?
A: これらのパイプラインは決して相互に排他的ではなく、シームレスに統合できます。例えば、R1は本質的に予備的なウォームアップステップとして拒否サンプリングによるSFTを必要とします。RLを使用する場合、実践者は合成されたCoT手法を引き続き活用し、ますます複雑になるシナリオに効果的に対処するために追加の構造化された推論戦略を導入する必要があります。
Q: ベースラインとして役立つ代表的または広く使用されているTTSの手法は何ですか?
A: 並列 – 自己整合性、Best-of-N。逐次 – STaR、Self-Refine、PRM。ハイブリッド – MCTS、ToT。内部 – Distilled-R1、R1。
Q: これまでのところ、最適な定番ソリューションはありますか?
A: フリーランチはありません。最適な計算は、問題の難易度とオープンネスに依存することが多いです。
Q: TTS手法の性能をどのように評価すべきですか?標準的な精度に加えて、他にどのような側面に注意を払うべきですか?
A: 評価はタスクに大きく依存しますが、精度は依然として最も重要な指標です。さらに、効率性(性能とコストのトレードオフ)は、実際の環境におけるもう一つの重要な懸念事項です。TTSがより汎用的な戦略になるにつれて、研究者たちは、TTSのより広範な影響をより良く理解するために、ロバスト性、安全性、バイアス、解釈可能性など、さまざまな二次的な属性の評価も開始しています。
Q: 他のスケーリング形式を内部スケーリングにチューニングする場合、元のスケーリング形式を直接使用する場合と比較して違いはありますか?
A: はい、直感的な違いの一つは効率性の側面です。内部スケーリングはLMに一度だけプロンプトを入力するため、他のスケーリング手法が通常複数の試行を必要とするのに対し、より高い効率性をもたらす傾向があります。しかし、内部スケーリングには無視できないチューニングリソースが必要であり、実践者にとっては利用しにくい場合があります。
8. Challenges and Opportunities(課題と機会)
この章では、TTS研究における主要な課題と将来の有望な方向性について議論しています。
8.1 More Scaling is the Frontier(さらなるスケーリングがフロンティアを広げる)
特に複雑なタスクにおいて、AIをより汎用的な知能へと押し進める上で、テストタイムスケーリングはプレトレーニング後の時代において最も有望な方法論の一つとして登場しました。OpenAIのo1やDeepSeek-R1のようなモデルに見られるように、推論を多用するタスクに対するその影響を考えると、テストタイムスケーリングの可能性を最大限に引き出すことが、AGIの進歩における中心的な柱であり続けることは明らかになっています。いくつかの有望な研究の方向性があります。
並列スケーリング:
並列スケーリングは、複数の応答を生成し、最良の答えを選択することで、ソリューションの信頼性を向上させます。その有効性にもかかわらず、並列スケーリングはカバレッジが飽和に達すると収益逓減に見舞われます。重要な課題は、総当たり的なカバレッジ拡張から、より誘導的で効率的なプロセスへと移行し、カバレッジをどのように強化するかです。将来の可能性のある進歩には、スマートなカバレッジ拡張や、リアルタイム検証メカニズムの統合による検証器拡張並列スケーリングなどがあります。
逐次スケーリング:
逐次スケーリングは、特に一貫性を維持し、エラーの蓄積を防ぐ上で、独自の課題に直面しています。重要な課題は、収益逓減を避け、誤ったステップを強化しないように、段階的な推論を最適化することです。単純な反復的改善の代わりに、将来の進歩は、各推論ステップが最終結果を有意義に改善することを保証する、より適応的で構造化されたアプローチに焦点を当てるべきです。可能性のある方向性には、自己訂正的な推論パラダイムの進化などがあります。
ハイブリッドスケーリング:
ハイブリッドスケーリングは、並列法と逐次法を組み合わせることで、現実世界のアプリケーションに対してより適応的で実用的になります。現在のテストタイムスケーリング手法は高度に特化していることが多く、その一般化可能性が制限されています。これらの制限に対処するために、ハイブリッドスケーリングはいくつかの点で改善できます。例えば、異なるクエリタイプに最適な戦略を動的に選択する単一のフレームワークへの統合や、複数モデルインスタンスが構造化された議論や交渉を行うことを可能にするマルチエージェントおよびインタラクティブスケーリングへの拡張などがあります。
内部スケーリング:
内部スケーリングは、外部からの介入なしに、テスト中の推論に必要な計算量をモデル自身が決定することを可能にします。このパラダイムは有望な結果を示していますが、独自の課題ももたらします。例えば、必要な場合にのみ追加の推論ステップを割り当てる効果的な計算量割り当てや、自己一貫性を外部のガイダンスなしに維持することによる安定性と一貫性の確保、そして失敗の診断や推論コストの調整を困難にする解釈可能性と制御可能性の向上などです。
8.2 Clarifying the Essence of Techniques in Scaling is the Foundation(スケーリングにおける技術の本質を明確にすることが基礎)
何をスケールするかが進化し続け、PPOからGRPOへの移行のように技術が内部的にさらに発展する一方で、スケーリング技術のコアカテゴリは比較的安定していることが観察されます。例えば、SFTとRLは依然として最も一般的なアプローチの2つですが、それらの役割と相互作用は時間の経過とともに変化しています。これは、これらの基本的な技術がテストタイムスケーリングにどのように貢献しているのかについての理解を深める緊急の必要性を提起します。さらなる調査の潜在的な方向性として、スケーリング技術における理論的ギャップ、報酬モデリングの再評価、テストタイムスケーリングの数学的特性、Chain-of-Thought推論の優先順位、そして適応的なテストタイムスケーリングなどが挙げられています。
8.3 Optimizing Scaling is the Key(スケーリングの最適化が鍵)
新しいTTS手法が増加するにつれて、体系的な評価と最適化が重要になります。タスク精度に関するさまざまな戦略のパフォーマンスを包括的に測定し、効率性、ロバスト性、バイアス、安全性、解釈可能性なども考慮する必要があります。TTSのこれらの側面を最適化することは徐々に表面化しており、将来の発展の重要な部分になるでしょう。
8.4 Generalization across Domains is the Mainstream(ドメインを超えた一般化が主流)
複雑な意思決定と構造化された推論が不可欠な医学や金融などのより幅広いドメインにテストタイムスケーリングを拡張する研究の波が来ると予想されます。この拡大は避けられないと同時に有望でもあります。テストタイムスケーリングは、コストのかかる再トレーニングを必要とせずに、推論の深さを高め、計算を動的に適応させ、精度を向上させるための強力なメカニズムを提供するからです。これらの分野を超えて、法律、AI評価、オープン ドメインQA、その他の高リスクまたは知識集約型の分野での広範な応用が期待できます。その可能性にもかかわらず、ドメインを超えたテストタイム推論のスケーリングにはいくつかの主要な課題があります。例えば、コストと精度のバランス、ドメイン固有の解釈可能性の確保、外部知識と現実世界の制約の統合、そして多様な推論タスクにわたってロバストな一般化可能なテストタイムスケーリング戦略の特定などです。これらの課題に対処することで、テストタイムスケーリングは、AIシステムが自身の推論を動的に拡張し、現実世界の制約に適応し、専門分野を超えて一般化することを可能にする、基礎的なAI能力となる可能性があります。
9. Conclusion(結論)
この論文は、TTSを階層的な分類で分解した最初のサーベイであり、概念理解と個々の貢献の特定の両方を助ける構造化された視点を提供します。実用性を重視し、各分類軸に合わせた実践的なガイドラインを紹介しており、今後これを拡張していく予定です。このフレームワークに基づいて、TTS研究の将来を形作る主要なトレンド、課題、機会を概説しています。
まとめ
本記事では、論文「What, How, Where, and How Well? A Survey on Test-Time Scaling in Large Language Models」 をもとに、大規模言語モデル(LLM)のテストタイムスケーリング(TTS)について解説しました。TTSは、事前学習後のLLMの潜在能力を最大限に引き出すための重要な研究分野であり、様々な手法と応用が存在することが分かりました。
本論文で提案された4つの側面、「何を(What)」、「どのように(How)」、「どこで(Where)」、「どの程度(How Well)」スケールするのか、というフレームワークは、TTS研究を体系的に理解する上で非常に有用です。TTSは、今後の人工知能研究、特に汎用人工知能(AGI)の実現に向けて、ますます重要な役割を果たすと考えられます。