
はじめに
近年、AIの世界では「デコーダのみ」アーキテクチャを持つ大規模言語モデル(LLM)が主流となっています。しかし、Googleは2024年7月、その流れに一石を投じる新しいモデルファミリー「T5Gemma」を発表しました。これは、従来の「エンコーダ・デコーダ」モデルの強みと、最新のデコーダのみモデルの能力を融合させるアプローチから生まれたものです。
本稿では、このT5Gemmaがどのようなモデルで、何が新しく、私たちにどのような可能性をもたらすのかを解説していきます。
参考記事
- 発行元: Google
- 発行日: 2025年7月9日
- タイトル: T5Gemma: A New Collection of Encoder-Decoder Gemma Models
- URL: https://developers.googleblog.com/jp/t5gemma/
- 発行元: HuggingFace(Google記載)
- タイトル: T5Gemma model card
- URL: https://huggingface.co/google/t5gemma-b-b-prefixlm-it
要点
- T5Gemmaは、デコーダのみモデル(Gemma 2)をエンコーダ・デコーダモデルへと変換する「モデル適応(Model Adaptation)」という新しい手法で開発された、軽量かつ強力なAIモデルである。
- この手法により、Gemma 2が持つ強力な基礎能力を継承しつつ、要約や質疑応答などで高い効率と性能を発揮するエンコーダ・デコーダアーキテクチャの利点を両立させている。
- 大きな特徴として、エンコーダとデコーダのサイズを非対称に組み合わせる(例:9Bエンコーダと2Bデコーダ)ことが可能であり、タスクに応じて品質と効率のトレードオフを柔軟に調整できる。
- 各種ベンチマークにおいて、同規模のデコーダのみモデルと比較して、特に数学的思考や読解などのタスクで優れた性能を示し、品質と推論速度のバランスにおいて高い優位性を持つ。
- 研究開発の促進のため、事前学習済みモデルと命令チューニング済みモデルがオープンなライセンスでコミュニティに提供されている。
詳細解説
前提知識:LLMの2つの主要なアーキテクチャ
T5Gemmaを理解するために、まず大規模言語モデル(LLM)の主要な2つの設計思想、「デコーダのみ」と「エンコーダ・デコーダ」の違いを知る必要があります。
- エンコーダ・デコーダモデル (Encoder-Decoder Models)
- 仕組み: 入力された文章を「エンコーダ」が数値表現(文脈を理解したベクトル)に圧縮し、その情報を基に「デコーダ」が新しい文章を生成します。翻訳や要約のように、入力全体の意味をしっかり理解してから出力を生成するタスクが得意です。Googleの「T5」や「BERT」など、初期のLLMがこのタイプの代表例です。
- 得意なこと: 要約、翻訳、質疑応答など。
- デコーダのみモデル (Decoder-Only Models)
- 仕組み: 与えられた文脈(プロンプト)に続く、次に来る単語を次々と予測していくことで文章を生成します。エンコーダを持たず、デコーダ部分だけで構成されます。創造的な文章作成や対話など、自由なテキスト生成が得意です。近年のOpenAIの「GPT」シリーズやGoogleの「Gemma」がこれにあたります。
- 得意なこと: 対話、物語の執筆、コーディングなど。
最近のトレンドはデコーダのみモデルでしたが、エンコーダ・デコーダモデルにも依然として高い需要がありました。T5Gemmaは、この両者の長所を組み合わせるという新しいアプローチを取っています。
T5Gemmaの核心技術:「モデル適応」とは?
T5Gemmaの最も革新的な点は、「モデル適応(Model Adaptation)」と呼ばれる開発手法にあります。これは、ゼロから巨大なモデルを学習させるのではなく、「事前学習済みのデコーダのみモデル(Gemma 2)の重み(パラメータ)を利用して、エンコーダ・デコーダモデルを初期化する」という画期的なアイデアです。
具体的には、すでに高い言語能力を持つGemma 2の知識を流用し、それをエンコーダ部分とデコーダ部分に振り分け、追加の学習(適応)を行うことで、効率的に高性能なエンコーダ・デコーダモデルを構築します。これにより、開発コストを抑えつつ、Gemma 2の持つ優れた基礎能力をそのまま受け継ぐことができるのです。
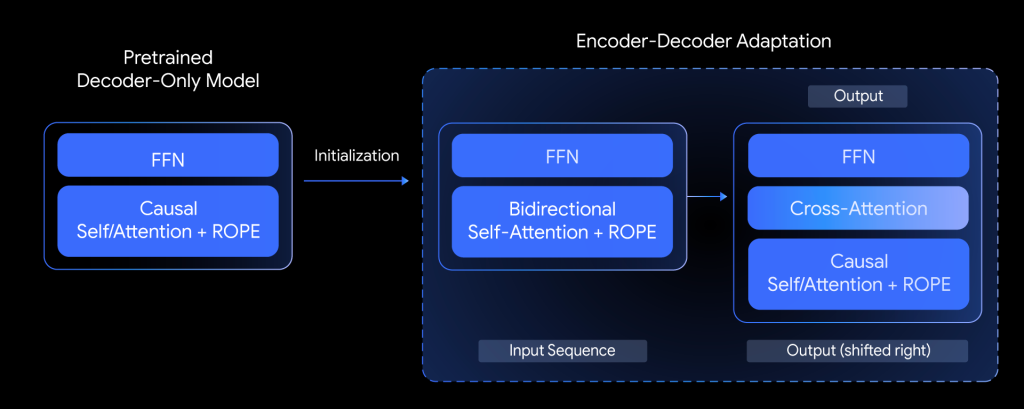
品質と効率を最適化する「アンバランス」な構成
T5Gemmaのもう一つの大きな特徴は、エンコーダとデコーダのサイズを柔軟に組み合わせられる点です。例えば、「9B(90億パラメータ)のエンコーダ」と「2B(20億パラメータ)のデコーダ」を組み合わせた「9B-2B」モデルを作成できます。
これはどのような場合に有効なのでしょうか。例えば、長文のレポートを要約するタスクを考えてみましょう。このタスクでは、まず入力されたレポートの内容を深く、正確に理解する必要があります。これは強力なエンコーダの役割です。一方、生成する要約文自体は、入力文ほど複雑ではありません。そのため、デコーダは比較的小さくても十分な品質を保てます。
このように、タスクの特性に合わせてエンコーダとデコーダの規模を最適化することで、不要な計算コストを削減し、推論速度を向上させながら、高い品質を維持するという、理想的なトレードオフを実現できるのです。
性能:Gemma 2を超える能力
では、実際の性能はどうなのでしょうか。公式の報告によると、T5Gemmaは多くのベンチマークで目覚ましい結果を出しています。
- 数学的思考能力 (GSM8K): T5Gemma 9B-9Bは、元のGemma 2 9Bモデルよりもスコアが9ポイント以上高くなっています。これは、エンコーダによる深い入力理解が論理的思考を助けていることを示唆します。
- 命令追従能力 (Instruction Tuning): 命令に応える能力を向上させるチューニング後、T5Gemma 2B-2B ITモデルは、Gemma 2 2B ITモデルと比較して、総合的な知識を測るMMLUベンチマークで12ポイント近くスコアが向上しました。
- 品質と速度のバランス: 下の図が示すように、同じ推論計算量(≒速度)で比較した場合、T5Gemma(青い星)はデコーダのみモデル(灰色の丸)よりも一貫して高いスコアを達成しており、品質と効率の面で非常に優れていることがわかります。
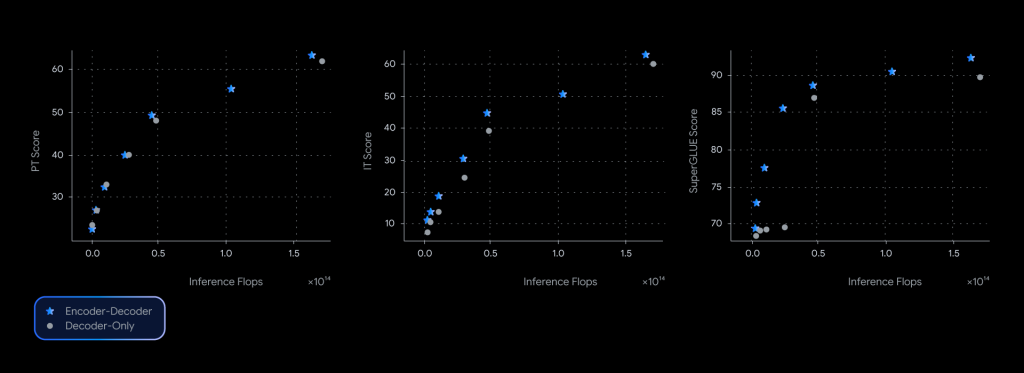
特に、T5Gemma 9B-2Bモデルは、Gemma 2 2Bモデルとほぼ同じ推論速度でありながら、精度は大幅に向上しており、「アンバランス」構成の有効性を明確に示しています。
T5Gemmaの利用方法
1. 学習とリサーチ
論文で詳細を学ぶ
- 公式論文でT5Gemmaの技術的背景と研究成果を深く理解
- 論文URL: https://arxiv.org/abs/2504.06225
- モデル適応手法の詳細やベンチマーク結果を確認
2. モデルのダウンロードと入手
Hugging Face
- 最も一般的なモデル配布プラットフォーム
- T5Gemmaコレクション: https://huggingface.co/collections/google/t5gemma-686ba262fe290b881d21ec86
- ドキュメント: https://huggingface.co/docs/transformers/model_doc/t5gemma
- 簡単なAPIでモデルをダウンロード・利用可能
- コミュニティによる追加リソースやサンプルコードが豊富
Kaggle
- データサイエンティスト向けプラットフォーム
- T5Gemmaモデル: https://www.kaggle.com/models/google/t5gemma
- データセットと組み合わせた実験が容易
- 競技やノートブックでの活用例が参考になる
3. 実践的な利用
Google Colabノートブック
- 機能確認: モデルの基本的な能力をテスト
- ファインチューニング: 独自のデータセットで追加学習
- プロトタイピング: アイデアの素早い検証
- 公式Colabノートブック:https://colab.research.google.com/github/google-gemini/gemma-cookbook/blob/main/Research/[T5Gemma]Example.ipynb
Vertex AI
- 本格的な推論環境: 商用レベルのスケーラブルな推論
- API経由でのアクセス: アプリケーションへの組み込みが容易
- マネージドサービス: インフラ管理が不要
- T5GemmaモデルがVertex AIで利用可能
4. 開発とカスタマイズ
適用可能なタスク
- 文書要約: 長文レポートの要点抽出
- 質疑応答: FAQ システムや顧客サポート
- 翻訳: 高精度な多言語翻訳
- データ分析: 構造化データの理解と説明生成
選択指針
- 軽量・高速重視: Small、Base、2Bモデル
- 精度重視: Large、XL、9Bモデル
- バランス重視: アンバランス構成(9B-2B)
- 生成タスク重視: PrefixLMバリアント
- 理解タスク重視: UL2バリアント
まとめ
本稿では、Googleの新しいAIモデル「T5Gemma」について解説しました。T5Gemmaは、単なる新しいモデルではなく、LLMのアーキテクチャ設計に新たな可能性を示すものです。
「モデル適応」という賢い手法で、のみモデルの強力な能力をエンコーダ・デコーダの枠組みに引き継ぎ、さらに「アンバランス」な構成という柔軟性によって、タスクに合わせた最適な品質と効率のバランスを追求できます。
このオープンなモデルがコミュニティに提供されることで、研究者や開発者は、より少ない計算資源で高性能なAIアプリケーションを開発できるようになるでしょう。要約、翻訳、高度な質疑応答システムなど、これまで以上にインテリジェントで効率的なサービスの登場が期待されます。T5Gemmaは、AI技術の民主化をさらに一歩前進させる、重要なマイルストーンと言えるでしょう。








