
はじめに
近年、ChatGPTなどのLLM(大規模言語モデル)は、単に質問に答えるだけのチャットボットから、自律的に行動計画を立ててタスクを遂行する「エージェント」へと進化を遂げています。特に、ウェブ上の情報を検索・収集してユーザーの目的を達成する「リサーチエージェント」の需要は急速に高まっています。しかし、既存の評価手法は「フランスの首都は?」といった単一の正解を求めるものが多く、実務で求められる「〇〇に関するすべての企業をリストアップして」といった網羅的な調査能力を正しく測れていないという課題がありました。
本稿では、Google DeepMindの研究チームなどが2025年に発表した論文『DeepSearchQA: Bridging the Comprehensiveness Gap for Deep Research Agents』について解説します。この論文では、AIがどれだけ「深く、漏れなく」情報を収集できるかを測るための新しいベンチマーク「DeepSearchQA」が提案されています。
解説論文
- 論文タイトル: DeepSearchQA: Bridging the Comprehensiveness Gap for Deep Research Agents
- 論文URL: https://storage.googleapis.com/deepmind-media/DeepSearchQA/DeepSearchQA_benchmark_paper.pdf
- 発行日: 2025年12月11日
- 発表者: Nikita Gupta, Riju Chatterjee, Lukas Haas, Connie Tao, Andrew Wang, Chang Liu, Hidekazu Oiwa, Elena Gribovskaya, Jan Ackermann, John Blitzer, Sasha Goldshtein, Dipanjan Das (Google DeepMind, Google Search, Kaggle, Google Research)
本論文の要点
- 既存評価の限界:従来のベンチマーク(SimpleQAなど)は単一の事実確認(Factuality)に焦点を当てており、実務で必要な「網羅的なリスト作成」や「複雑な条件付き検索」の能力を評価できていなかった。これを「Comprehensiveness Gap(網羅性のギャップ)」と定義した。
- DeepSearchQAの提案:900の難解なプロンプトからなる新たなベンチマークを構築した。情報の断片化されたソースからの体系的な収集、重複の排除(Entity Resolution)、そして検索をいつ終えるかという停止基準(Stopping Criteria)の判断能力をテストするものである。
- 評価指標の刷新:単なる正解率ではなく、情報検索(IR)分野で用いられるF1スコア(適合率と再現率の調和平均)を採用し、過不足のない回答セットを作成できるかを厳密に評価する手法を導入した。
- 実験結果と課題:Gemini Deep Research AgentやGPT-5 Proといった最先端モデルであっても、適合率(Precision)と再現率(Recall)のバランスを取ることに苦労していることが判明した。特に、自信がない情報をあえて含める「ヘッジ(保険)」行動や、探索不足による「早期停止」といった失敗モードが明らかになった。
詳細解説
1. Introduction(はじめに)
AIの分野では、静的なLLMから、動的な環境と相互作用する自律型ウェブエージェントへのパラダイムシフトが起きています。これを「エージェント革命(agentic revolution)」と呼びますが、計画立案やツール利用といった高度な能力の評価手法が開発に追いついていないのが現状です。既存のベンチマークは飽和しているか、あるいは実世界のニーズとかけ離れているというボトルネックが存在します。
1.1. The Prevailing Paradigm: Single-Answer Verification(支配的なパラダイム:単一回答の検証)
これまでの主要な評価手法(TruthfulQA、SimpleQAなど)は、「フランスの首都は?」といった単一の回答を求めるタスクに焦点を当てていました。この形式は自動採点が容易であり、客観的な評価が可能であるため、ハルシネーション(もっともらしい嘘)の抑制という点では大きな成果を上げてきました。しかし、これらはあくまで特定の「事実」の検証に留まっており、長い時間をかけて行う調査プロセス全体の完全性を評価するものではありませんでした。
1.2. The Comprehensiveness Gap: Beyond Finding an Answer(網羅性のギャップ:回答を見つけることの先へ)
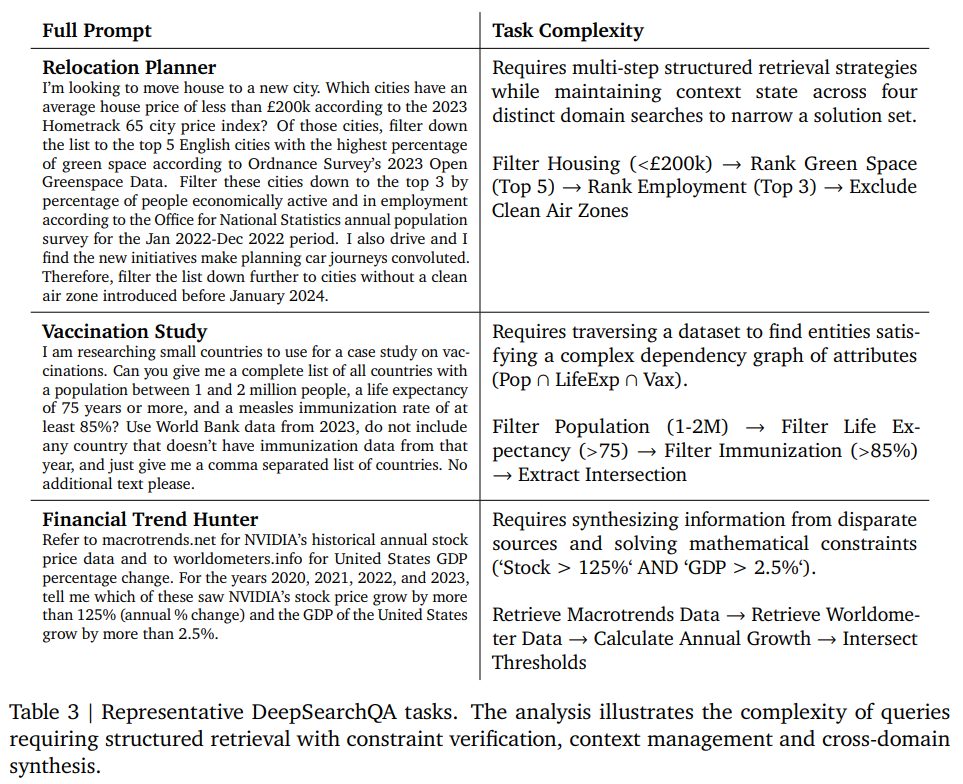
単一回答アプローチの限界として、研究チームは「Comprehensiveness Gap(網羅性のギャップ)」を指摘しています。現実の情報収集タスク、例えば「東南アジアに拠点を持ち、PER(株価収益率)が20以下の半導体関連企業をすべてリストアップせよ」といった要求は、単一のデータポイントを見つけるだけでは満たされません。このような「エージェント的情報検索」には、以下の3つの高度な能力が必要とされます。
Systematic Collation(体系的な照合)
単一のソースにすべての答えが載っていることは稀です。エージェントは数百にも及ぶ異なるソースを巡回し、断片的な情報を統合してマスターリストを作成する能力が求められます。
Entity Resolution / De-duplication(実体の解決 / 重複排除)
ウェブ上の情報は表記揺れを含みます。異なる表現であっても同一の実体であることを認識し、リストの重複を防ぐ能力(構造化推論)が必要です。重複の解消に失敗するとリストが膨れ上がり、精度の低下を招きます。
Stopping Criteria(停止基準)
最も重要な能力の一つが、いつ検索を終了するかという判断です。「まだ見つかっていないだけ(証拠の不在)」なのか、「そもそも存在しない(不在の証拠)」なのかを見極める必要があります。明確な終了シグナルがない中で、不確実性に対処する高度な推論が求められます。
1.3. DeepSearchQA Core Contributions(DeepSearchQAの主要な貢献)
DeepSearchQAの最大の貢献は、評価の軸を「高精度な検索」から「網羅的な回答セットの生成」へとシフトさせた点にあります。ここでは、検索のプロセス(どのページを見たか)ではなく、最終的に提出された回答セットの完全性(再現率)と正確性(適合率)のみで評価を行います。これにより、エージェントは「探索(広範囲に網を張る)」と「活用(候補を検証する)」のトレードオフを自律的に制御することを迫られます。
2. DeepSearchQA: Dataset and Taxonomy(DeepSearchQA:データセットと分類法)
DeepSearchQAは、専門家によって作成された900のプロンプトで構成されており、客観的な正解が存在する情報探索タスクに厳選されています。
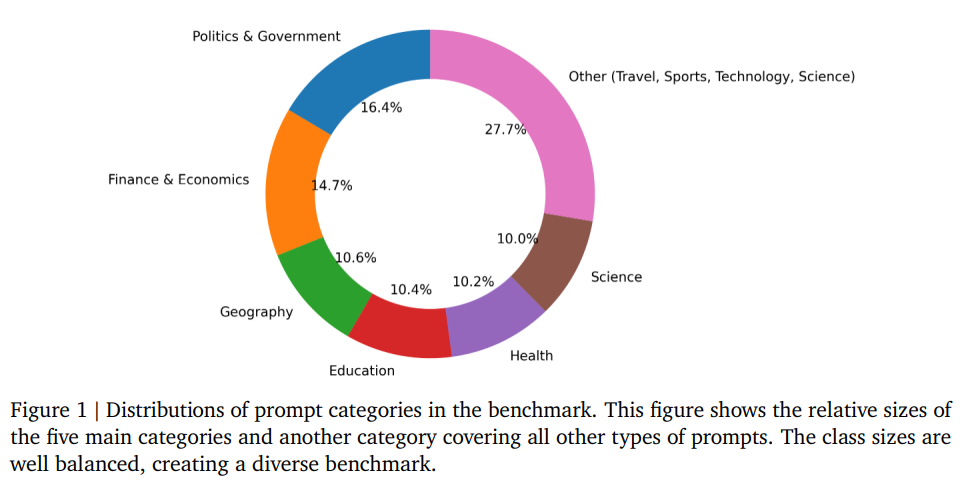
Dataset Statistics and Domains(データセットの統計とドメイン)
質問は政治、経済、科学、健康など多岐にわたります(Figure 1参照)。重要な設計として、すべてのプロンプトは「2020年の国勢調査によれば」といった形で時間的なアンカーが設定されているか、静的なデータソースを参照するようになっています。これは、ウェブ情報の変化による正解の陳腐化(ドリフト)を防ぐためです。

Answer Types(回答タイプ)
正解の形式は以下の2種類に大別されます。
- Single Answer(単一回答):特定の日付や名前など。ただし、情報がマイナーであったり、ウェブ上で情報が錯綜していたりするため、深いリサーチが必要です。
- Set Answer(集合回答):条件に合致する全項目のリスト(列挙)や、複数のサブ質問への回答(複合)などです。
Quality Verification Protocol(品質検証プロトコル)
正解データの正確性を担保するため、以下の3段階の検証プロセスを経て作成されました。
- 独立リサーチフェーズ:正解を知らない3名のレビュアーが独自にリサーチを行う。
- 検証と比較:レビュアーの回答と作成者の正解を照合する。
- 対立解消フェーズ:不一致がある場合、正解の修正やプロンプトの曖昧さを排除するためのフィルタリングを行う。
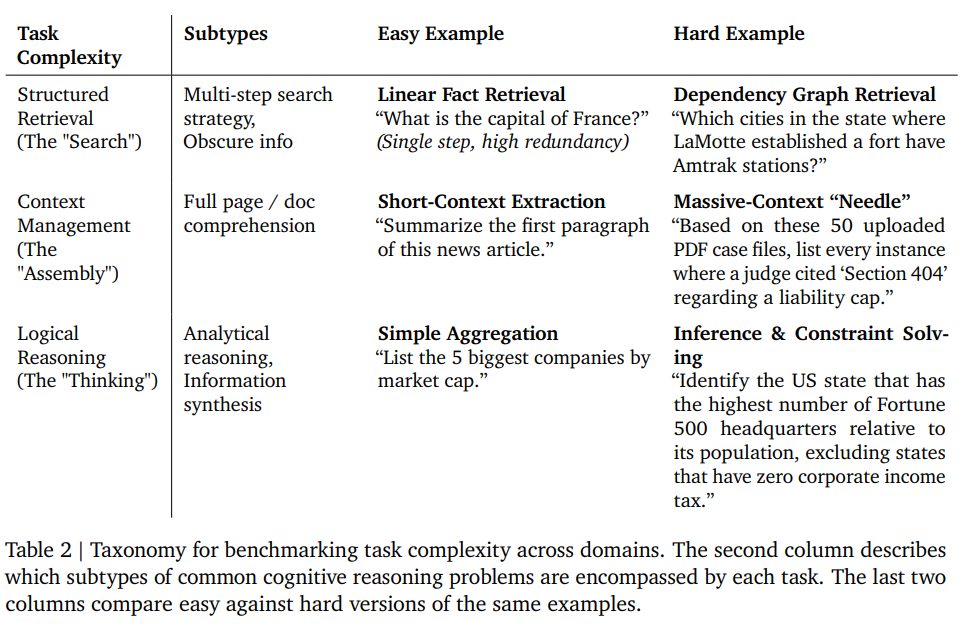
Task Complexity Taxonomy(タスク複雑性の分類法)
タスクは、エージェントに求められる認知的・操作的負荷に基づいて分類されています。
- Structured Retrieval (“The Search”) / 構造化検索(「検索」):マイナーな情報を得るための多段階の検索戦略。
- Context Management (“The Assembly”) / コンテキスト管理(「組み立て」):大量の情報を読み込み、統合する能力。コンテキストウィンドウの制限管理が課題となります。
- Logical Reasoning (“The Thinker”) / 論理的推論(「思考」):抽象的な演繹、計画立案、不完全なデータからの推論などを含みます。
3. Evaluation Methodology(評価方法)
順序が関係ない「セット形式」の回答を、公平かつ堅牢に評価するための手法です。
3.1. Formal Evaluation Metrics(公式な評価指標)
Continuous Metrics(連続的指標)
情報検索の標準的な指標を採用しています。最も重要視されるのはF1スコアです。
あるプロンプト \(i\) に対するF1スコア \(F1_i\) は、適合率(Precision, \(P_i\))と再現率(Recall, \(R_i\))の調和平均で計算されます。
$$ F1_i = \frac{2 \cdot P_i \cdot R_i}{P_i + R_i} $$
- 適合率 \(P_i\):提出された回答のうち、正解が含まれる割合(ハルシネーションの少なさ)。
- 再現率\(R_i\):正解セットのうち、どれだけ網羅できたかの割合(取りこぼしの少なさ)。
この指標により、単に大量の推測を出力して再現率を稼ごうとする行為(ハルシネーションやトピックの逸脱)にはペナルティが与えられます。
Categorical Classification(カテゴリカル分類)
回答を以下の4つのカテゴリに分類して評価します。
- Fully Correct(完全正解):正解セットと完全に一致(過不足なし)。
- Fully Incorrect(完全不正解):正解が一つも含まれていない。
- Partially Correct(部分正解):一部の正解を含んでいる(セット回答のみ)。
- Correct with Extraneous Answers(余分な回答を含む正解):すべての正解を含んでいるが、不正解も混じっている状態。これは「ヘッジ(保険をかける)」失敗モードを示します。例えば、「優勝国は?」に対して「ブラジルとイタリア(準優勝)」と答えるようなケースです。
3.2. Automated Evaluation Pipeline(自動評価パイプライン)
抽出された回答が正解と意味的に等価であるかを判定するために、LLM(Gemini 2.5 Flash)を裁判官(Judge)として使用する自動パイプラインを採用しています。
4. Results and Analysis(結果と分析)
State-of-the-Art in Deep Research(ディープリサーチにおける最先端)
評価の結果、「Gemini Deep Research Agent」と「GPT-5 Pro High Reasoning」がトップクラスの成績を収めました。重要な発見は、単体の推論モデルよりも、検索と推論を反復する「エージェント」の方が高いパフォーマンスを示した点です。これは、網羅性のギャップを埋めるにはエージェント的なループ処理が不可欠であることを示唆しています。

また、Gemini Deep Research Agentは致命的な失敗(Fully Incorrect)が最も少なく(約10%)、安定性が高いことが示されました。
Scaling Behavior and the Reasoning Threshold(スケーリング挙動と推論の閾値)
モデルの規模や推論能力とパフォーマンスの関係を見ると、ある閾値を下回ると急激に性能が低下することがわかりました。例えば、Gemini 2.5 Flashのような軽量モデルでは、F1スコアがトップモデルの半分程度に落ち込み、完全不正解率は約45%に達しました。これは、DeepSearchQAのようなタスクは単純な検索では太刀打ちできず、一定以上の推論能力がないと検索方針すら立てられないことを意味しています。
Metric Divergence: The Last Mile Problem(指標の乖離:ラストワンマイル問題)
F1スコアと完全正解率(Fully Correct)の間には約15ポイントの乖離が見られました。これは、エージェントが「大部分の正解を見つけるが、マイナーな項目を見落とす(探索不足)」か、「すべて見つけるが、余計なものまで含めてしまう(過剰検索)」という2つの相反する失敗モードに陥っていることを示します。これを「自律的ディープリサーチにおけるラストワンマイル問題」と呼んでいます。
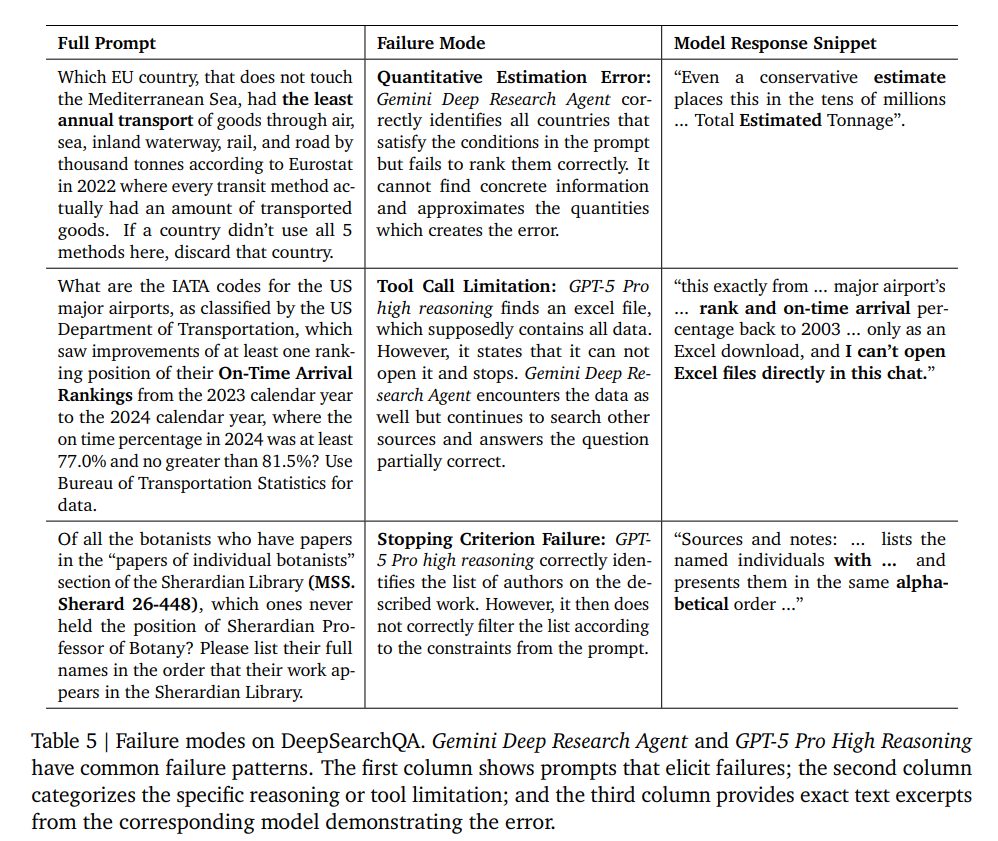
主な失敗パターンとして以下が挙げられています。
- Quantitative Estimation Error(量的推定エラー):具体的な数値が見つからず、概算で答えようとして失敗する。
- Tool Call Limitation(ツール呼び出しの制限):Excelファイルなどの特定のフォーマットを開けず、処理が停止する。
- Stopping Criterion Failure(停止基準の失敗):リスト自体は見つけたが、プロンプトの制約(条件)によるフィルタリングに失敗し、不要な項目を含めてしまう。
5. Future Work(今後の展望)
5.1. Limitations(限界)
本ベンチマークは結果のみを評価するブラックボックスアプローチであるため、エージェントが「まぐれ」で正解したのか、正しい推論を経たのかを区別しにくいという課題があります。また、静的なウェブを前提としているため、リアルタイムの速報性などは評価範囲外となります。
5.2. Methodological Extensions(手法の拡張)
将来的には、エージェントの検索軌跡(どのページを見たかなど)を評価に含めるプロセスベースの指標や、時間の経過とともに正解が変わる動的なリストへの対応、回答の重要度に応じた重み付け採点などが検討されています。
5.3. Implications for Advancements in Agent Architecture(エージェントアーキテクチャの進歩への示唆)
DeepSearchQAで高得点を取るには、以下の新しいスキルセットが必要です。
- Systematic Exploration Strategies(体系的な探索戦略):キーワード検索だけでなく、見落としがないように体系的にページを巡回する戦略。
- Advanced Information Synthesis(高度な情報統合):異種ソースからの情報を統合し、実体の重複を解決するメカニズム。
- Dynamic Stopping Criteria(動的な停止基準):これ以上の検索が非生産的であると判断し、探索を打ち切るための自己認識能力。
6. Conclusion(まとめ)
DeepSearchQAは、従来の「一点突破型」の検索評価から、「面を制圧する」ような網羅的なリサーチ能力の評価へとパラダイムを移行させるものです。最先端のAIモデルであっても、適合率と再現率のトレードオフに苦戦している現状が明らかになりました。
まとめ
本稿では、Google DeepMindらが発表した新しいベンチマーク「DeepSearchQA」について解説しました。従来のAI評価は単一の事実確認が中心でしたが、DeepSearchQAは網羅的な調査能力という実務で重要なスキルを測定する指標です。最先端モデルであっても適合率と再現率のバランスに苦戦している現状が明らかになりました。今後は「質問に答えるエージェント」から「トピックを深く理解し、情報の全体像を把握できるエージェント」への進化が求められると考えられます。








