AI安全性– tag –
-

[開発者向け]OpenAI、Model Specに18歳未満向け保護原則を追加——発達科学に基づく安全対策とは?
はじめに OpenAIが2025年12月18日、AIモデルの行動規範を定めた「Model Spec」に、18歳未満のユーザー向けの保護原則「U18 Principles」を追加したと発表しました。本稿では、この更新内容と、同時に公開されたティーンと保護者向けのAIリテラシーリソー... -
[論文解説]GPT-5.2システムカード解説
はじめに AIモデルの進化に伴い、その安全性とリスク評価の重要性はかつてないほど高まっています。OpenAIは、モデルのリリースごとに「システムカード(System Card)」と呼ばれる技術レポートを公開しています。これは、モデルの開発プロセス、安全性... -
[開発者向け]OpenAIがサイバーセキュリティ強化策を発表―防御側支援とAardvark脆弱性検出ツール
はじめに OpenAIが2025年12月10日、AIモデルのサイバーセキュリティ能力向上に伴う安全対策と、防御側を支援するエコシステム強化の取り組みを発表しました。本稿では、この発表内容をもとに、AIモデルの進化するサイバー能力への対応策と、防御側を支援... -
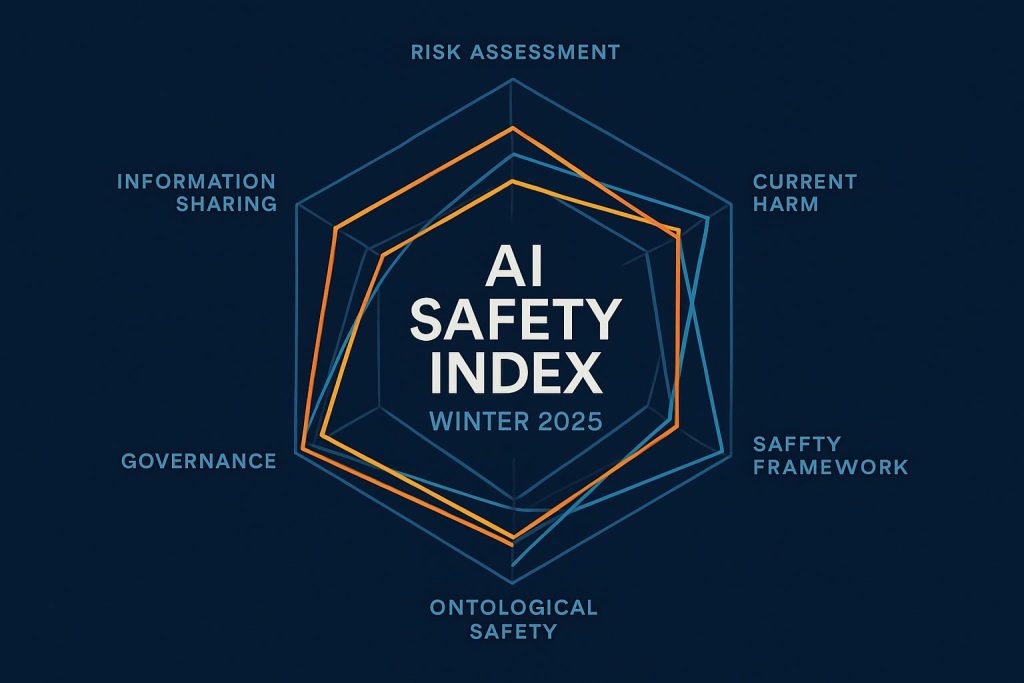
[レポート解説]AI企業の安全性評価「AI Safety Index」最新版が公開——Anthropicがトップ、存在論的リスクへの対応は全社で課題
はじめに Future of Life Institute(FLI)が2025年12月、主要AI企業8社の安全性を評価した「AI Safety Index Winter 2025」を公開しました。独立した専門家パネルが6つのドメインで企業を評価し、業界全体の安全性実践の現状と課題を明らかにしています。... -
[論文解説]LLMの普遍的な脆弱性:「詩的」文体変化が安全ガードレールを突破する
はじめに 近年、大規模言語モデル(LLM)は、人間の言葉を理解し、高度な応答を生成する能力により、ビジネスや研究、さらには社会の重要な意思決定パイプラインにおいて、ますます中心的な役割を担うようになっています。AIエンジニアである皆様もご存... -
[開発者向け]人間とAIモデルは同じコードで混乱する?ザールラント大学とマックスプランク研究所の実証研究
はじめに ザールラント大学とマックスプランク・ソフトウェアシステム研究所が人間と大規模言語モデル(LLM)が複雑なプログラムコードに対して示す反応の類似性を実証した研究成果を発表しました。本稿では、この研究の内容と、AI支援プログラミングの未... -
[開発者向け]Claude Opus 4.5はプロンプトインジェクションをどう防ぐのか?ブラウザ利用における新たな防御戦略
はじめに Anthropicが2025年11月25日、AIエージェントのセキュリティ課題であるプロンプトインジェクション攻撃への対策強化を発表しました。本稿では、この発表内容をもとに、Claude Opus 4.5における耐性向上の詳細と、ブラウザ利用時に特有のリスク、... -
[論文解説]報酬ハッキングが引き起こす創発的ミスアライメント:Anthropicの最新研究が示すAI安全性の新たな課題
はじめに AI開発において、強化学習(RL)は言語モデルを人間の意図に沿うように訓練する重要な手法として広く用いられています。しかし、2025年11月にAnthropicが発表した論文「Natural Emergent Misalignment from Reward Hacking in Production RL」は... -
[AIツール利用者向け]OpenAIが第三者評価の詳細を公開:GPT-5で実施された安全性評価の全体像
はじめに OpenAIが2025年11月19日、フロンティアAIモデルに対する第三者評価のアプローチを詳しく解説した記事を公開しました。本稿では、GPT-5を含む最新モデルで実施された外部評価の具体的な手法、評価者に提供されるアクセス権限、そして透明性と機... -
[論文解説]Anthropic:AIが自律的に実行した初の国家級サイバー諜報活動の全貌
はじめに AI技術の急速な進展は、私たちの生活を豊かにする一方で、その悪用による新たな脅威を生み出しています。 本稿では、AI開発企業であるAnthropicが、彼らの開発したAIモデルの悪用を防ぐために高度な安全・セキュリティ対策を講じているにもか...