はじめに
AI技術の進化は目覚ましく、特に大規模言語モデル(LLM)は様々なタスクで高い性能を発揮しています。しかし、LLMが知らない情報を扱う際には課題があり、それを解決する手法の一つとしてRAG(Retrieval Augmented Generation)が注目されています。RAGは、外部の知識ソースから関連情報を取得し、それをLLMに与えることで、より正確で最新の情報に基づいた応答を生成させようという技術です。
RAGは確かにLLMの性能を向上させますが、それでもまだ望ましくない応答をすることがあります。例えば、事実と異なる情報をさも事実のように答えてしまうハルシネーション(hallucination)です。エラーの原因として、LLMが与えられた文脈(Context)をうまく利用できないのか、それともそもそも与えられた文脈が質問に答えるのに十分(Sufficient)なのか、という点が明確ではありませんでした。
Google、デューク大学、カリフォルニア大学サンディエゴ校の研究チームが発表した論文「SUFFICIENT CONTEXT: A NEW LENS ON RETRIEVAL AUGMENTED GENERATION SYSTEMS」は、この問いに答えるために、「十分な文脈(Sufficient Context)」という新しい概念を提案し、RAGシステムの振る舞いを詳細に分析した研究です。この概念が、RAGシステムのエラー分析や性能改善にどのような新しい視点をもたらすのかを、論文の内容に沿ってご紹介していきます。
引用元論文
- 論文タイトル:Sufficient Context: A New Lens on Retrieval Augmented Generation Systems
- 論文発表日:2024年10月9日(3校版:2025年4月23日)
- 論文発表者:Hailey Joren, Jianyi Zhang, Chun-Sung Ferng, Da-Cheng Juan, Ankur Taly, Cyrus Rashtchian
- 論文URL:https://arxiv.org/abs/2411.06037
・あくまで個人の理解に基づくものであり、正確性に問題がある場合がございます。
必ず参照元論文をご確認ください。
・本記事内での画像は、上記論文より引用しております。
要点
- 「十分な文脈(Sufficient Context)」という新しい概念を定義し、質問と文脈のペアが質問に答えるのに必要な情報を含んでいるかを判定する手法(自動評価器)を開発しました。これは、回答の正誤を知らなくても判定できる点が実用的です。
- この概念を用いてRAGシステムを分析した結果、十分な文脈が与えられても、LLMはしばしばハルシネーションを起こすことが明らかになりました。これは、RAGのエラーが情報検索(Retrieval)の質だけでなく、LLMの応答生成能力にも起因することを示唆しています。
- 驚くべきことに、不十分な文脈しかなくても、モデルが正解を出すケースが少なくないことも分かりました。これは、モデルが自身の学習済みの知識(パラメータ知識)を活用したり、文脈を補助的に使ったりすることで可能になっていると考えられます。
- 「十分な文脈」であるかどうかの信号を活用することで、モデルが回答するか、あるいは答えないか(非回答、abstain)を選択的に制御し、ハルシネーションを削減できる手法を提案しました。この手法により、回答したクエリの中での正解率を向上させられることが示されました。
詳細解説
論文の構成に従って、各セクションの内容を詳しく解説していきます。
1. INTRODUCTION
論文はまず、LLMに文脈を与えるRAGシステムが、新しい分野への適応や事実に基づいた応答において有効であることを述べています。例えば、オープンなドメイン(特定の分野に限定されない広範な知識)に関する質問応答では、検索モデルが文脈となるテキストを取得し、LLMがそれを利用して回答を生成します。
しかし、現在のRAGベースのLLMにはいくつかの課題があります。取得した情報を使って自信満々に間違った答えを生成したり、無関係な情報に惑わされたり、長いテキストから必要な情報をうまく抽出できなかったり といった問題です。
理想的には、LLMは与えられた文脈と自身の知識を組み合わせて、質問に答えるのに十分な情報があれば正確な答えを出すべきです。そして、情報が不十分であれば、答えを控えたり、追加情報を求めたりすべきです。しかし、この理想的な振る舞いを実現するのは難しい課題です。
2. RELATED WORK
関連研究のセクションでは、RAGシステムの振る舞いを理解し、ハルシネーションを減らすためのこれまでの取り組みが紹介されています。
一つの方向性は、不適切な文脈(Irrelevant Context)がある場合に、LLMがどのように影響を受けるかを評価する研究です。しかし、これまでの研究では「関連性」の定義が明確でなく、単に「答えが含まれていない」ことを関連性がないと見なしたりしていました。これは、「関連情報」が、答えを直接含む場合から単に話題が関連しているだけの場合まで幅広いためです。
もう一つの方向性は、RAG設定でのLLMのハルシネーションを削減するための手法を開発する研究です。これらの多くは、検索や生成の質を向上させるためにモデルをファインチューニングするアプローチを取っています。また、文脈が非常に長い場合にLLMが必要な情報を見つけられない「lost in the middle」問題に取り組む研究もあります。これらの研究の多くは、与えられた文脈が回答可能であることを前提としており、「十分な文脈」ではない場合を十分に扱えていませんでした。
3. SUFFICIENT CONTEXT
本論文の中心的な貢献の一つが、「十分な文脈」という新しい概念の定義です。これは、入力として与えられた質問と文脈のペアに対して、その文脈が質問に答えるために必要なすべての情報を含んでいるかどうかを基準に、インスタンスを二つのカテゴリに分類するものです。
具体的には、文脈が十分(Sufficient Context)であるとは、「文脈中の情報に基づいて、質問に対するもっともらしい回答を構築するために必要なすべての情報が含まれている」場合を指します。一方、文脈が不十分(Insufficient Context)であるのは、それ以外の場合です。例えば、文脈の情報が不完全だったり、結論が出せなかったり、矛盾していたりする場合、または質問に答えるために文脈にはない専門知識が必要な場合などが含まれます。
この定義の重要な点は、回答の正解を知らなくても文脈の十分性を判断できることです。これは、実際のシステムで推論時に利用する上で非常に重要です。既存のAIS (Attributable to Identified Sources) フレームワークのような含意(Entailment)を判断する手法は、「文脈中の情報が、特定の回答Aが質問Qの答えであることを含意するか」を判断するため、正解Aを知っている必要があります。Sufficient Contextの判断は、正解を知る前に「そもそも文脈中に答えが存在しうるか」を判断する点が異なります。
論文では、この概念について補足説明を加えています。
Remark 1 (Multi-hop queries):
複数の情報源を組み合わせて答えを出す必要があるマルチホップの質問の場合、文脈が十分であるためには、必要な情報がすべて含まれており、それらを論理的に結合できる必要があります。ただし、文脈にない関連性を推測することは含まれません。
Remark 2 (Ambiguous queries):
質問が曖昧な場合、文脈が十分であるのは、文脈が質問の曖昧さを解消でき、かつその解消された質問に対する答えを提供している場合です。
Remark 3 (Ambiguous contexts):
文脈中に複数のもっともらしい答えが含まれている場合、文脈が十分であるのは、文脈がどの答えが正しいかを区別するのに十分な情報を提供している場合です。例えば、「Aliはどの国に住んでいますか?」という質問に対して、文脈が「Aliはパリに住んでいます」だけでは、フランスのパリかアメリカのテキサス州パリか不明なため不十分ですが、「今週末、Aliはパリからマルセイユまで列車に乗りました」という情報が加われば、フランスのパリである可能性が非常に高くなり、文脈が十分になります。
次に、この十分な文脈のラベル付けを自動化する手法(Sufficient Context Autorater)について検討しています。論文では、人間が手作業でラベル付けしたデータセット(115件)を使って、いくつかのモデルの性能を評価しました。その結果、Gemini 1.5 Pro (1-shot) が最も高い精度(93%)を達成しました。これは、Ground Truth Answerなしで動作する手法の中で高い精度であり、スケーラブルな分析に利用可能であることを示しています。T5ベースのTRUE-NLIのような含意モデルよりも高いF1スコアを達成しており、十分な文脈の分類が含意の判定とは異なるより複雑なタスクであることを裏付けています。比較的軽量なFLAMeモデルも代替手段として有効であると述べています。
4. A NEW LENS ON RAG PERFORMANCE
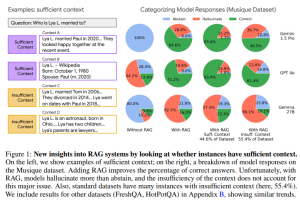
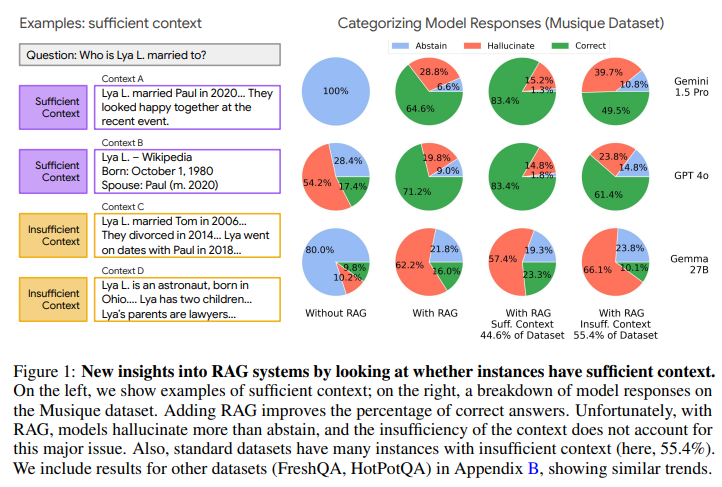
十分な文脈の自動評価器を用いて、RAGシステムの性能を分析しています。まず、FreshQA, Musique-Ans, HotpotQAといった標準的なオープンブックQAデータセットにおける、十分な文脈を持つインスタンスの割合を調査しました。その結果、FreshQAでは手作業でキュレーションされたURLを文脈として使用しているため割合が高かった(77.4%)のに対し、MusiqueやHotpotQAでは低かった(約45%程度)ことが分かりました。これは、標準的なデータセットにも不十分な文脈のインスタンスがかなりの割合で含まれていることを示しています。
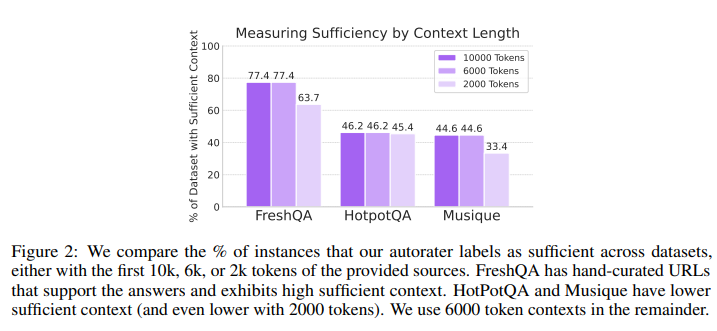
次に、これらのデータセット上で、いくつかのLLM(Gemini 1.5 Pro, GPT 4o, Claude 3.5 Sonnet, Gemma 27B)の応答を、十分な文脈がある場合とない場合で分類・分析しました。応答の分類(正解、非回答、ハルシネーション)には、LLMを用いた自動評価パイプライン(LLMEval)を使用しました。これは、厳密な文字列一致よりも柔軟な評価が可能であるためです。
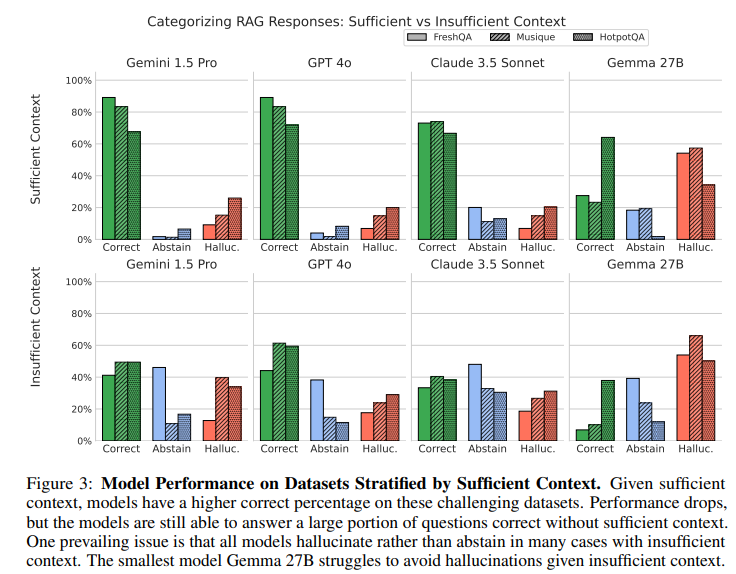
分析結果から、いくつかの重要な発見がありました。
- RAGを使用すると、全体的な正解率は向上しますが、非回答の割合は低下します。モデルは文脈情報があると、たとえそれが不十分でも、応答することに自信を持つ傾向があるのかもしれません。
- 十分な文脈が与えられても、モデルは非回答よりもハルシネーションを多く生成する傾向が見られました (Figure1, Figure3を参照)。特に高性能なモデル(Gemini 1.5 Pro, GPT 4o, Claude 3.5)は、文脈が十分な場合に正解を出すのが得意ですが、不十分な文脈の際には間違った答えを出力することが多い傾向が見られました。
- 不十分な文脈の場合でも、モデルは非回答とハルシネーションを多く生成します。この傾向はモデルによって異なり、例えばClaudeは不十分な文脈の場合に非回答を増やす傾向がありましたが、GeminiやGPTは正解率が高めでした。一方、小規模なGemmaは不十分な文脈の場合にハルシネーションが非常に多い傾向が見られました。
不十分な文脈でもモデルが正解を出すケースについても、定性的な分析を行っています。論文では、これを8つのタイプに分類し、例を挙げています (Table 2)。例えば、はい/いいえ質問でたまたま正解したり、限られた選択肢の中から正解を選んだり、文脈が不十分でもモデルが自身の持つパラメータ知識を補完的に利用したり、複雑な推論を自力で行ったり、質問の曖昧さをうまく解釈したり といったケースがあります。また、評価器自身の誤りである可能性も示唆されています。モデルがクローズドブック(RAGなし)の設定でも正解を出すケースが少なくないことを考えると、不十分な文脈での正解の多くは、モデルのパラメータ知識に起因すると考えられます。
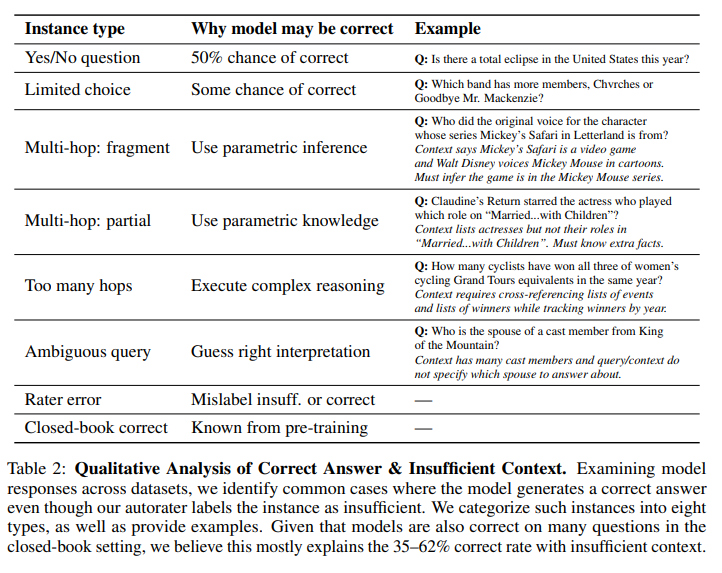
また、十分な文脈があるにもかかわらず、モデルが間違った答えを出力するケースについても調査しています。原因としては、文脈中の情報が誤っていたり、文脈中の情報をモデルがうまく組み合わせられなかったり(マルチホップ質問や計算が必要な場合) といった可能性が考えられます。
5. TECHNIQUES TO REDUCE HALLUCINATIONS WITH RAG
これまでの分析で、RAGを使用するとモデルは非回答よりもハルシネーションを起こしやすく、これはクローズドブック設定よりも顕著であることが分かりました。そこで、論文ではハルシネーションを減らすための手法を検討しています。理想的には、モデルが正解を出すか、あるいは非回答とするように誘導したいと考えました。
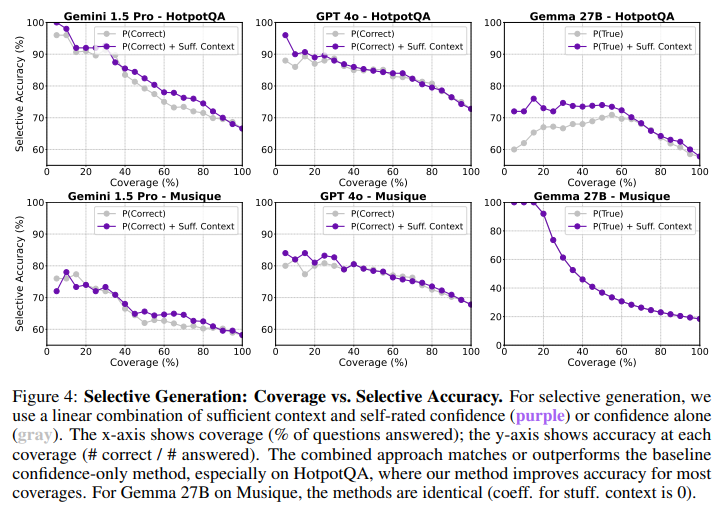
一つのアプローチとして、選択的生成(Selective Generation)を提案しています。これは、「十分な文脈」であるかどうかの信号と、モデルが自身の回答に対する自信スコア(self-rated confidence score)を組み合わせることで、モデルが回答するか非回答するかを選択的に制御する手法です。これにより、回答する質問の割合(Coverage)と、その中での正解率(Selective Accuracy)のトレードオフを調整できます。
自信スコアとしては、モデルに複数回サンプリングさせて回答の確率を推定する方法 (P(True)) や、回答とその確率を直接推定させる方法 (P(Correct)) を使用しました。十分な文脈の信号は、軽量なFLAMeモデルを使って取得しました。これらの信号を組み合わせて、ハルシネーションを予測する単純なロジスティック回帰モデルを学習させ、そのスコアを閾値として回答するか非回答するかを決定します。
この手法を評価した結果、モデルの自信スコアのみを使用する場合と比較して、「十分な文脈」の信号を組み合わせることで、特に高い正解率を目指す場合に、selective accuracy-coverageのトレードオフが改善されることが示されました (Figure 4を参照)。HotpotQAデータセットでは、特に顕著な改善が見られました。これは、文脈が十分であるかどうかの情報が、モデルの回答の信頼性を予測する上で有用な補助信号となることを示唆しています。
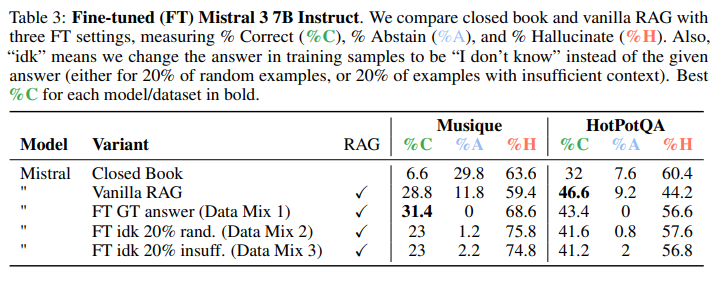
また、別の手法としてファインチューニングによるアプローチも検討しています。学習データの一部で正解を「I don’t know」に置き換えることで、モデルが不確実な場合に非回答を促すことを試みました。しかし、詳細な結果 (Table 3) によると、ファインチューニングによって正解率が向上する場合もあるものの、仮説に反して非回答率が劇的に増加することはなく、依然としてハルシネーションが頻繁に発生することが分かりました。ファインチューニングで非回答と正解のバランスをうまく取るには、さらなる研究が必要であると結論づけています。
6. CONCLUSION
本論文は、「十分な文脈」という新しい概念を導入し、それに基づいてRAGシステムの応答を分析する新しい視点を提供しました。十分な文脈の自動評価器を構築したことで、スケーラブルな分析が可能になり、モデルの振る舞いに関するいくつかの洞察が得られました。
主な発見として、十分な文脈があってもLLMはハルシネーションを起こしやすく、一方で不十分な文脈でもモデルは正解を出すケースが少なくないことが明らかになりました。不十分な文脈での正解ケースの定性的な分類は、文脈がどのようにLLMにとって有用でありうるかについて、より深い理解をもたらしました。そして、「十分な文脈」の信号を活用する選択的生成手法が、ハルシネーションを削減し、回答の正解率を向上させるのに有効であることを示しました。
論文の限界(Limitations)としては、分析がQAデータセットに限定されている点や、異なる情報検索手法が文脈の十分性にどの程度影響するかを深く検討していない点などが挙げられています。また、自動評価器を使って追加の情報検索が必要かを判断し、検索を繰り返すような応用も考えられますが、本研究ではそこまでは踏み込んでいません。
今後の展望(Future Work)としては、「十分な文脈」をバイナリなラベルではなくスコアとして出力する、より細やかな評価器の開発 や、画像やPDFなどを扱うマルチモーダルなRAG設定への概念の拡張、そして選択的生成の可能性を示唆する、入力からの補助信号を用いたハルシネーション削減のさらなる探求 が挙げられています。
まとめ
本論文は、RAGシステムのエラー分析に「十分な文脈」という明確な基準を導入し、その振る舞いを定量的に分析した非常に興味深い研究です。十分な文脈が与えられてもハルシネーションが起こるという発見は、RAGシステムの改善が検索だけでなく生成モデル側の能力向上も必要であることを示唆しています。また、不十分な文脈でも正解するケースの分析は、LLMのパラメータ知識と文脈情報の相互作用の複雑さを示しています。
今回提案された「十分な文脈」の概念とその自動評価器は、今後のRAGシステムの研究開発において、エラーの原因特定や性能評価、そしてハルシネーション対策を考える上で、非常に有用なツールとなるでしょう。特に、選択的生成のアプローチは、実用的なRAGシステムの信頼性を向上させるための一歩となる可能性を秘めています。
RAGシステムは、今後もLLMの能力を補完し、より信頼性の高いAIアプリケーションを構築するための重要な技術であり続けると考えられます。本研究が示した新しい視点と手法は、その発展に大きく貢献するものと言えるでしょう。