
はじめに
OpenAIが2025年11月3日、インド文化とインド諸言語におけるAIシステムの理解度を評価する新しいベンチマーク「IndQA」を発表しました。本稿では、この発表内容をもとに、IndQAの仕組み、既存ベンチマークとの違い、そして多言語AI評価における意義について解説します。
参考記事
- タイトル: Introducing IndQA
- 発行元: OpenAI
- 発行日: 2025年11月3日
- URL: https://openai.com/index/introducing-indqa/
要点
- IndQAは、インド文化と日常生活に関する知識・推論能力を評価する新しいベンチマークである
- 2,278の質問が12のインド言語と10の文化領域にわたって作成され、261人のドメインエキスパートが協力した
- 既存のMMLLUやMGSMといったベンチマークでは捉えきれない、文化的ニュアンスや推論重視のタスクを評価できる
- GPT-5 Thinking Highが34.9%のスコアで最高性能を記録したが、改善の余地が大きいことも示された
- 質問は複数のOpenAIモデルが十分に答えられなかったものに絞られており、今後の進捗測定に活用される
詳細解説
IndQA開発の背景と目的
OpenAIによれば、世界の約80%の人々が英語を第一言語としていないにもかかわらず、非英語言語の能力を測定する既存のベンチマークには限界がありました。
特に、MMLLUのような多言語ベンチマークは飽和状態に達しており、トップモデルが高得点に集中するため、実質的な進歩を測定しにくくなっています。また、既存のベンチマークは翻訳や多肢選択問題に偏っており、文脈、文化、歴史、そして人々が実際に暮らす地域で重要なことを理解する能力を適切に評価できていません。
インドは英語を第一言語としない人々が約10億人いる国であり、22の公式言語(うち少なくとも7言語が5,000万人以上の話者を持つ)を擁し、ChatGPTの利用者数では世界第2位の市場です。こうした背景から、インドは多言語AI評価ベンチマーク開発の最初のステップとして最適な対象と言えます。
IndQAの構成と特徴
IndQAは、インド文化と日常生活に関する知識と推論を評価するベンチマークです。OpenAIの発表によれば、2,278の質問が12言語と10の文化領域にわたって用意されています。
対応言語は、ベンガル語、英語、ヒンディー語、ヒングリッシュ(英語とヒンディー語の混合)、カンナダ語、マラーティー語、オディア語、テルグ語、グジャラート語、マラヤーラム語、パンジャーブ語、タミル語です。ヒングリッシュが含まれているのは、会話におけるコードスイッチング(言語の切り替え)が一般的であることを反映したものと考えられます。
文化領域は、建築・デザイン、芸術・文化、日常生活、食・料理、歴史、法律・倫理、文学・言語学、メディア・エンターテインメント、宗教・精神性、スポーツ・レクリエーションの10分野をカバーしています。
各質問には、インド言語による文化的に根ざしたプロンプト、監査可能性のための英語翻訳、採点用のルーブリック基準、そして専門家の期待を反映した理想的な回答が含まれます。
ルーブリック方式による評価システム
IndQAの評価方法は、従来の多肢選択式とは異なるルーブリック方式を採用しています。
各回答は、その特定の質問のためにドメインエキスパートが作成した基準に照らして採点されます。基準には、理想的な回答が含むべき内容や避けるべき内容が明記され、それぞれの重要度に応じて重み付けされたポイント値が割り当てられます。モデルベースの採点者が各基準が満たされているかをチェックし、最終スコアは満たされた基準のポイント合計を総ポイントで割った値として算出されます。
このアプローチは、エッセイ問題の採点ルーブリックに似た仕組みで、単純な正誤判定では捉えきれない、より細やかな理解度評価を可能にします。

IndQA作成プロセスの詳細
OpenAIによれば、IndQAの作成には以下のプロセスが用いられました。
まず、10の異なる領域にわたってインド国内の専門家を見つけるためにパートナーと協力しました。これらの専門家は、自身の地域や専門分野に関連した、難易度が高く推論に焦点を当てたプロンプトを作成しました。専門家は該当言語のネイティブレベル話者(かつ英語話者)であり、深い専門知識を持っています。
次に、各質問はGPT-4o、OpenAI o3、GPT-4.5、そして(公開後の一部については)GPT-5といった、作成時点でのOpenAIの最強モデルに対してテストされました。これらのモデルの過半数が受け入れ可能な回答を生成できなかった質問のみが採用され、今後の進歩の余地が確保されています。このプロセスは「敵対的フィルタリング」と呼ばれ、ベンチマークが飽和しにくい設計になっています。
さらに、各質問とともに、ドメインエキスパートがモデル回答の採点に使用される基準を提供しました。これは、エッセイ問題の採点ルーブリックに相当します。
最後に、専門家が理想的な回答と英語翻訳を追加し、ピアレビューと反復的な修正を経て最終承認されました。
この一連のプロセスには、ジャーナリスト、言語学者、学者、芸術家、業界実務家など、261人のインド専門家が協力しました。OpenAIの発表では、750本以上の映画に出演したテルグ語俳優・脚本家、マラーティー語新聞の編集者、カンナダ語辞書編集者、国際チェスグランドマスター、タミル語の作家・詩人、受賞歴のあるパンジャーブ音楽作曲家など、多様な専門家の参加が紹介されています。
モデル性能の推移と現状
OpenAIは、IndQAを使用して最近のフロンティアモデルの性能を評価し、過去数年間の進歩を測定しました。
結果によれば、GPT-5 Thinking Highが34.9%のスコアで最高性能を記録し、次いでGemini 2.5 Pro Thinking(34.3%)、Gemini 2.5 Flash Thinking(29.7%)、Grok 4(28.5%)と続きました。OpenAI o3 Highは28.1%、Gemini 2.5 Flash NoThinkingは26.1%、OpenAI o1 Highは23.3%、GPT-4oは20.3%、GPT-4 Turboは12.1%という結果でした。
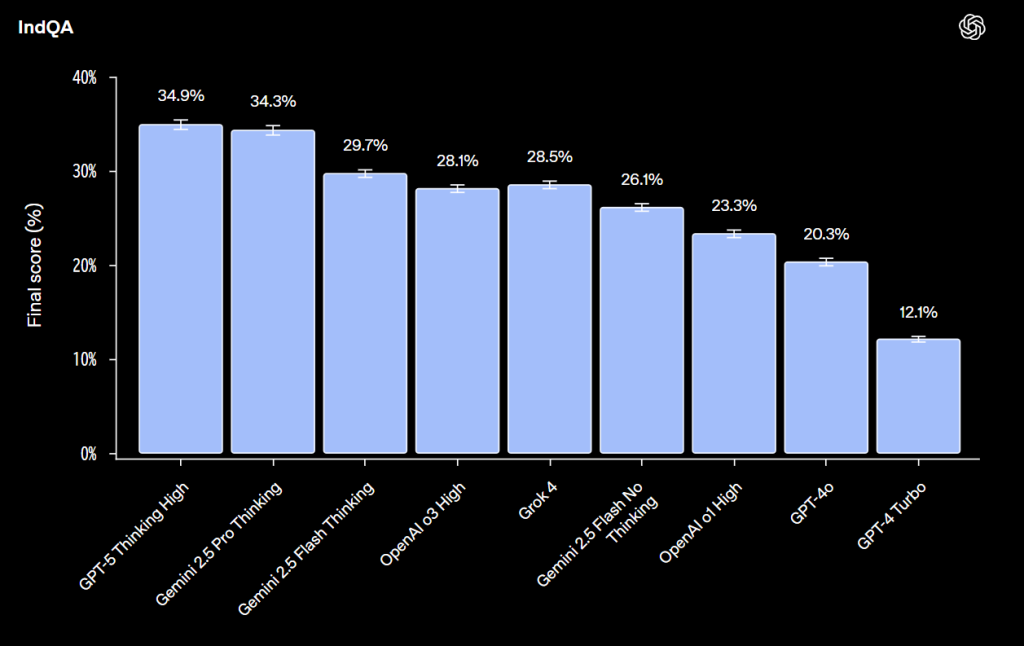
OpenAIのモデルは時間の経過とともにインド言語において大きく改善していますが、最高スコアでも35%未満であることから、改善の余地が依然として大きいことが分かります。
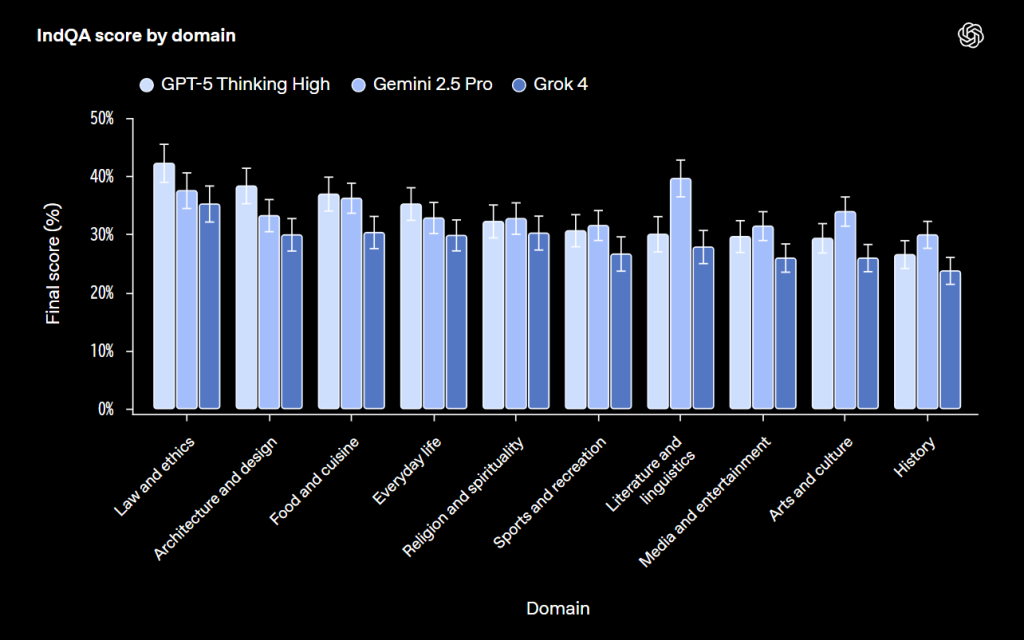
言語別の性能では、GPT-5 Thinking Highはヒンディー語で最も高いスコアを示し、次いでヒングリッシュ、グジャラート語と続きました。

領域別では、法律・倫理、建築・デザイン、食・料理の分野で比較的高い性能を示しています。
ベンチマークの制約事項
OpenAIの発表では、IndQAの制約についても明示されています。
まず、言語間で質問が同一ではないため、IndQAは言語のリーダーボードではありません。言語間のスコアを言語能力の直接比較として解釈すべきではなく、モデルファミリーや設定内での時間経過による改善を測定するために使用される予定です。
また、質問がGPT-4o、OpenAI o3、GPT-4.5、GPT-5が十分に答えられなかったものに絞られているため、これらのモデルに対して敵対的な選択となっています。これは、GPT-5の相対的な性能を混乱させる可能性があり、非OpenAIモデルと比較してOpenAIモデル全体を不利にする可能性があります。
この点は、ベンチマーク結果を解釈する際に考慮すべき重要な要素と言えるでしょう。
今後の展開と意義
OpenAIによれば、IndQAのリリースが研究コミュニティからの新しいベンチマーク作成を促すことを期待しています。
IndQAスタイルの質問は、既存のAIベンチマークで十分にカバーされていない言語や文化領域で特に価値があります。IndQAと同様のベンチマークを作成することで、AI研究機関は現在モデルが苦戦している言語や領域についてより深く学び、将来の改善の指針を得ることができるでしょう。
この取り組みは、OpenAIによれば、インドユーザー向けの製品とツールを改善し、インド全土でテクノロジーをよりアクセスしやすくするという継続的なコミットメントの一部です。今後、他の言語や地域についても同様のベンチマークを作成する計画があるとのことです。
まとめ
OpenAIが発表したIndQAは、インド文化と言語におけるAI評価の新しい基準を提示するベンチマークです。261人の専門家との協力により、2,278の文化的に根ざした質問が12言語にわたって作成されました。現在のトップモデルでも35%未満のスコアという結果は、多言語・多文化対応AIの開発において、まだ大きな改善の余地があることを示しています。今後、同様のアプローチが他の言語・地域にも展開されることで、真にグローバルなAI評価の枠組みが構築されていくことが期待されます。








