はじめに
OpenAIが2025年12月11日、専門的な知識業務向けの新しいフロンティアモデル「GPT-5.2」を発表しました。本稿では、この発表内容をもとに、GPT-5.2の性能向上、新機能、価格設定、そして実務への影響について解説します。
参考記事
- タイトル: GPT-5.2 が登場
- 発行元: OpenAI
- 発行日: 2025年12月11日
- URL: https://openai.com/ja-JP/index/introducing-gpt-5-2/
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
※図の赤い枠に関しては、執筆者による加工です。
要点
- GPT-5.2は、GPT-5.2 Instant、Thinking、Proの3バリエーションで提供され、それぞれ異なる用途に最適化されている
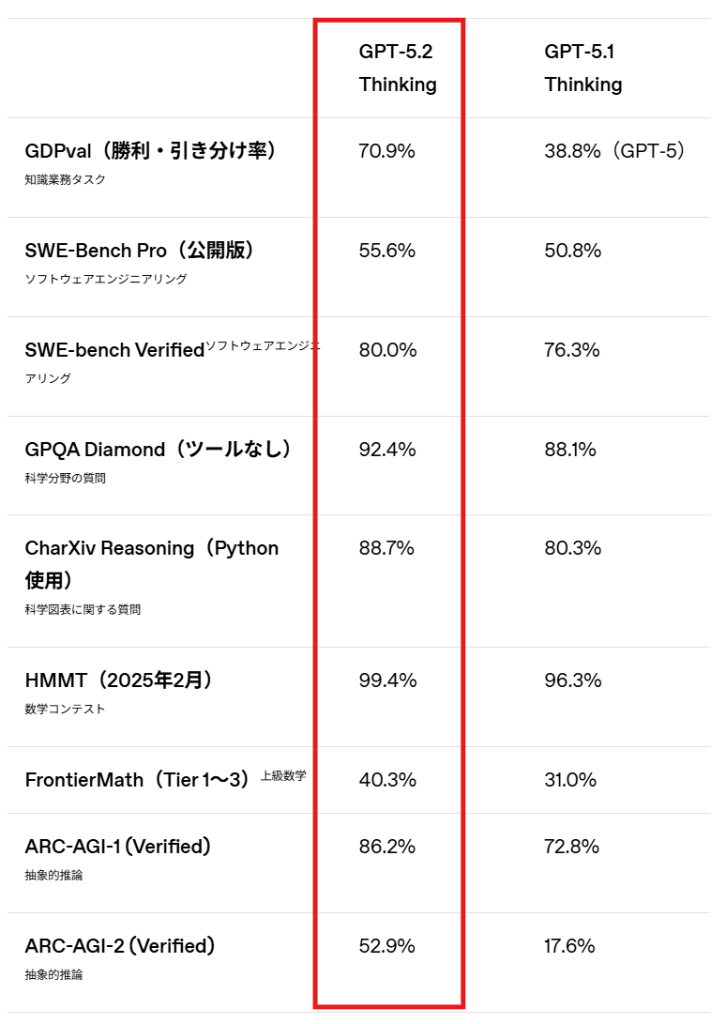
- 知識業務タスクを評価するGDPvalベンチマークで、GPT-5.2 Thinkingは70.9%のスコアを達成し、OpenAIのモデルとして初めて人間の専門家レベルに到達した
- SWE-Bench Proでは55.6%、SWE-bench Verifiedでは80%を記録し、ソフトウェアエンジニアリング分野で新たな最高水準を示した
- 長文コンテキスト処理能力が大幅に向上し、256kトークンまでの文書を高精度で扱えるようになった
- API価格は入力トークン100万あたり1.75ドル、出力トークン100万あたり14ドルで、GPT-5.1より高い設定となっている
詳細解説
GPT-5.2の3つのバリエーション
GPT-5.2は用途に応じて3つのバリエーションが用意されています。
- GPT-5.2 Instant:日常の仕事や学習に適した高速モデルで、情報探索や技術文書作成などで明確な改善を示しています。
- GPT-5.2 Thinking:より深い業務向けに設計されており、コーディングや長文ドキュメントの要約、複雑な計画立案などで高い性能を発揮します。
- GPT-5.2 Pro:最も高度なモデルで、高品質な回答が求められる難しい質問に適しています。
これらのバリエーションは、推論の深さとレイテンシーのトレードオフを考慮した設計となっています。Instantは即座の応答が必要な場面で、Thinkingは多段階の思考が必要な複雑なタスクで、Proは最高品質が求められる場面で選択することが推奨されます。
専門業務での性能向上
GPT-5.2 Thinkingは44の職種にまたがる知識業務タスクを評価するGDPvalベンチマークで70.9%のスコアを達成しました。これは業界トップクラスの専門家と同等以上の結果を示しており、OpenAIのモデルとして初めて人間の専門家レベルに到達したことを意味します。
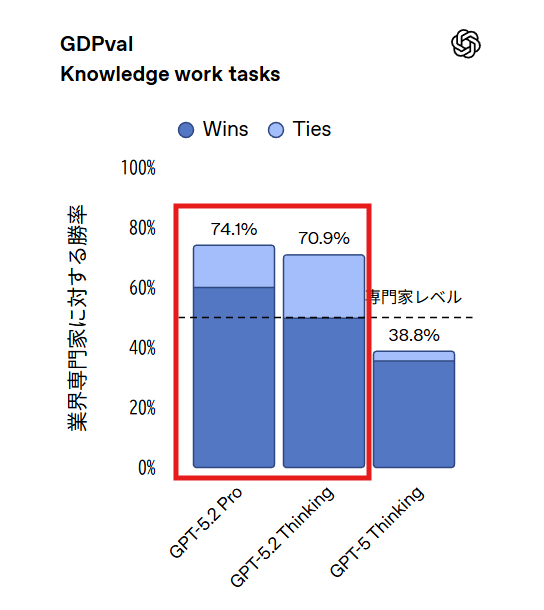
※GDPvalは、米国GDPに大きく寄与する上位9産業の44職種を対象としたベンチマークです。営業用プレゼンテーション、会計スプレッドシート、救急診療スケジュール、製造図面など、実際の成果物の作成を求めるタスクで構成されています。このベンチマークは実務での経済的価値を直接測定する設計となっており、従来の学術的なベンチマークとは異なる評価軸を提供します。
OpenAIの発表では、GPT-5.2 ThinkingがGDPvalのタスクを業界専門家の11倍以上の速度、1%未満のコストで生成したとされています。ただし、この数値は人による確認と組み合わせることを前提としており、完全な自動化を意味するものではない点に留意が必要です。
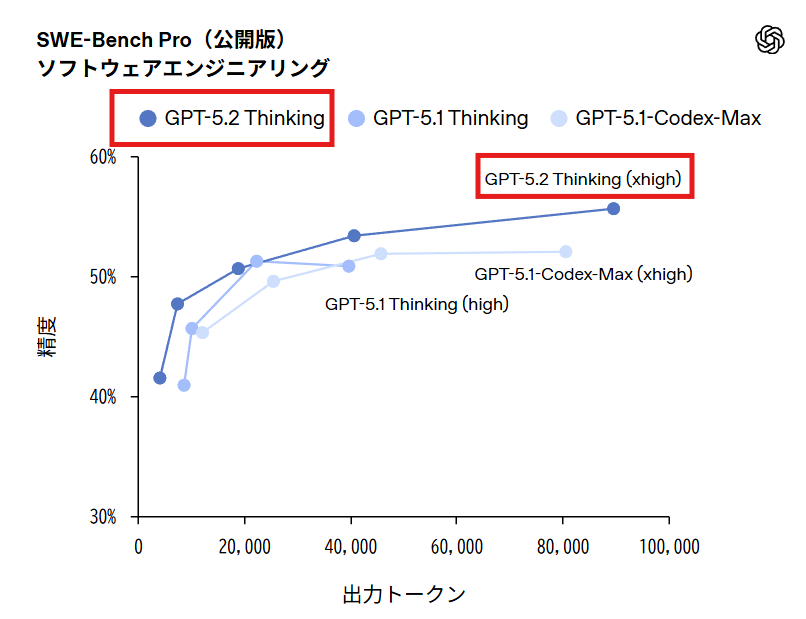
ソフトウェアエンジニアリング性能
GPT-5.2 Thinkingは実世界のソフトウェアエンジニアリングを評価するSWE-Bench Proで55.6%という新たな最高スコアを達成しました。SWE-bench Verifiedでは80%を記録しています。
SWE-Bench Proは、Python、JavaScript、TypeScript、Goの4言語を対象とした評価ベンチマークで、実際のGitHubリポジトリから抽出された現実的なソフトウェアエンジニアリングタスクで構成されています。モデルはコードリポジトリを与えられ、バグ修正や機能追加のためのパッチを生成する必要があります。従来のSWE-bench VerifiedがPythonのみを対象としていたのに対し、SWE-Bench Proはより幅広い言語と産業的関連性を重視した設計となっています。
フロントエンド開発においても、GPT-5.2 Thinkingは大幅な強化が見られます。初期テスターからは、3D要素を伴う複雑なUI作業で特に優れた性能を発揮しているとの評価が寄せられています。単一のプロンプトから、インタラクティブな海の波シミュレーションやタイピングゲームなどの完全に機能するアプリケーションを生成できることが示されています。
事実性の向上
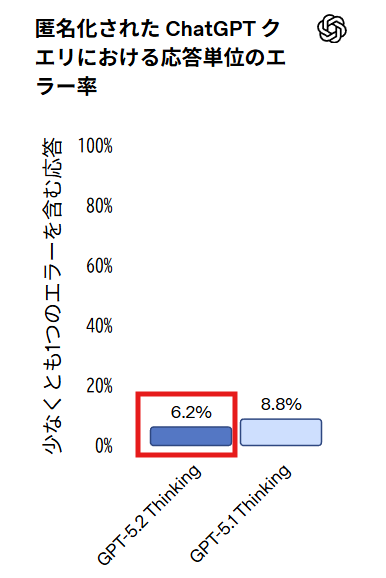
GPT-5.2 ThinkingはGPT-5.1 Thinkingと比べてハルシネーション(幻覚)の発生が少なくなっています。匿名化したChatGPTのクエリセットにおいて、誤りを含む回答は相対的に38%少なくなりました。
ハルシネーションとは、AIモデルが事実に基づかない情報を生成する現象を指します。特に知識業務においては、調査、文書作成、分析、意思決定支援など、正確性が求められる場面が多く、このような誤りの削減は実用性の向上に直結します。
ただし、OpenAIの発表でも明記されているように、GPT-5.2 Thinkingも完全ではありません。重要な用途では必ず回答を確認することが推奨されています。エラー率6.2%という数値は、約16回に1回は何らかの誤りを含む応答が生成される可能性があることを意味しており、人間による検証プロセスの重要性は依然として高いと考えられます。
長文コンテキスト処理能力
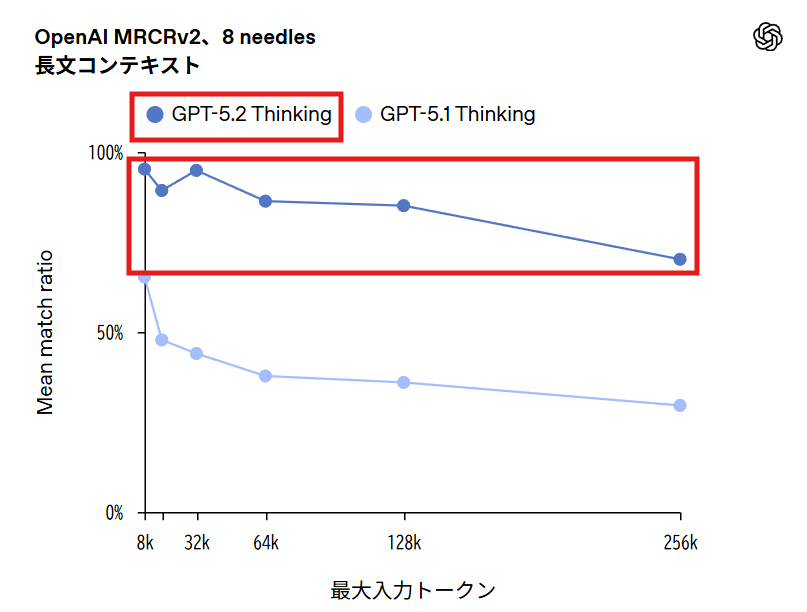
GPT-5.2 Thinkingは長文コンテキスト推論において新たな水準を達成し、OpenAI MRCRv2でトップレベルの性能を示しました。特に256kトークンまで扱える4-needle MRCRバリアントで、ほぼ100%の精度を達成した初めてのモデルです。
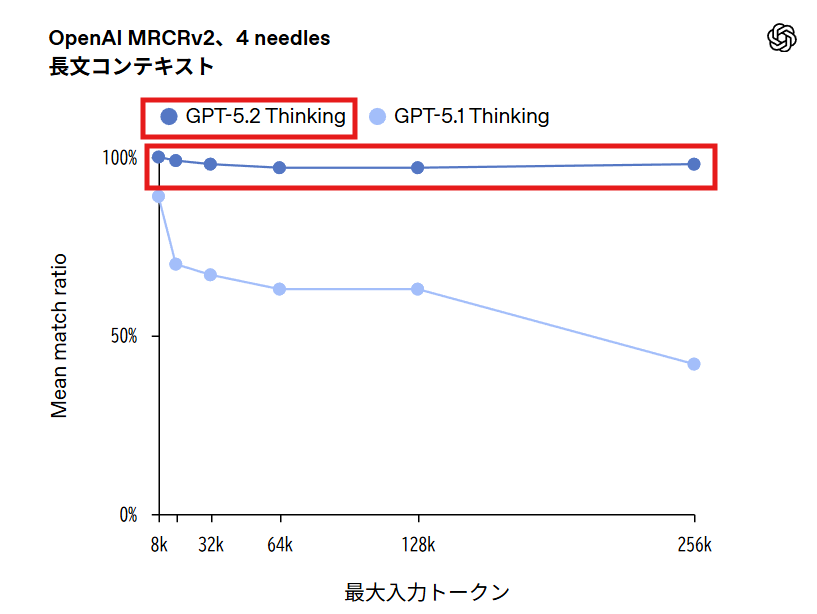
OpenAI-MRCR v2(multi-round co-reference resolution)は、長い文書に分散した情報を統合する能力を評価するベンチマークです。複数の同一の「needle」(検索対象のリクエスト)を、類似したリクエストと応答から成る長い「haystack」(干し草の山)に挿入し、モデルにn番目のneedleに対する応答を再現させます。256kトークンは約26万トークン、日本語で換算すると数十万文字規模の文書を扱えることを意味します。
実務面では、レポート、契約書、研究論文、書き起こし、多ファイルのプロジェクトなどの長文ドキュメントを扱う場合に、数十万トークン規模でも一貫性と精度を保ちながら作業できます。そのため、深い分析、情報統合、複数の情報源を扱う複雑なワークフローに特に適していると考えられます。
Vision(画像認識)性能の向上
GPT-5.2 Thinkingはチャート推論やソフトウェアインターフェース理解におけるエラー率を約半分に削減しています。科学論文の図表に関する質問に回答するCharXiv ReasoningベンチマークではPythonツール使用時に88.7%、GUI スクリーンショット理解を評価するScreenSpot-Proでは86.3%を記録しました。
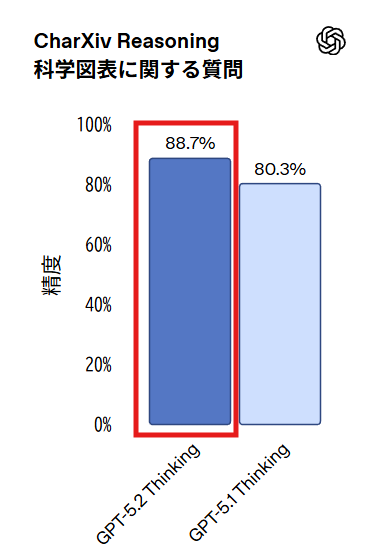
これらの改善により、ダッシュボード、製品スクリーンショット、技術図面、ビジュアルレポートなどをより正確に解釈できるようになります。特に財務、オペレーション、エンジニアリング、デザイン、カスタマーサポートといった視覚情報が中心となる領域のワークフローで有用と考えられます。
興味深い点として、GPT-5.2 Thinkingは画像内の要素の配置をより正確に把握できるようになっています。低品質な画像であっても、マザーボードのコンポーネントを特定し、各部品のおおよその位置に一致するバウンディングボックスを配置できることが示されています。

ツール呼び出し性能
GPT-5.2 ThinkingはTau2-bench Telecomにおいて98.7%という新たな水準を達成し、長時間かつ複数ターンにわたるタスクでもツールを安定して活用できる能力を示しました。Tau2-bench Retailでは82.0%を記録しています。
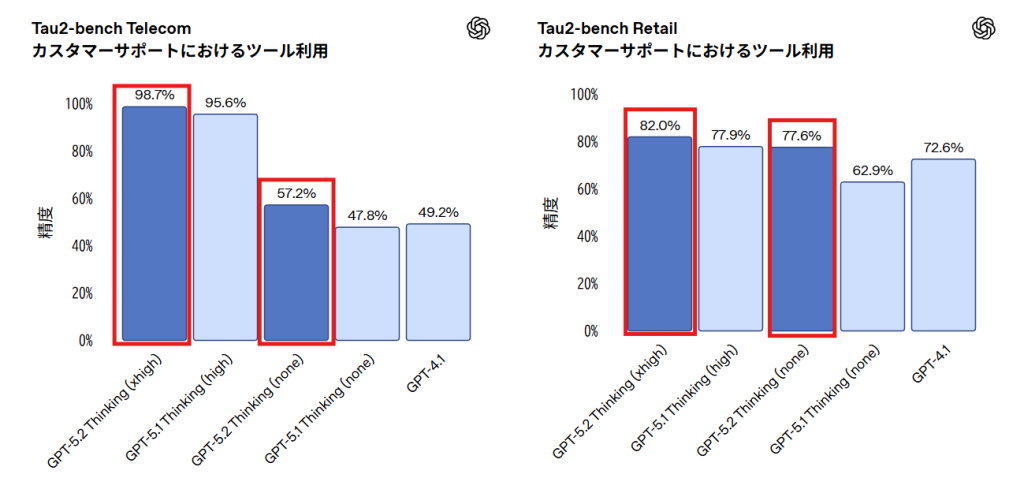
Tau2-benchは、モデルがツールを使用し、ユーザーを模した対話相手との複数ターンのやり取りを通じてカスタマーサポート業務を完了する能力を評価します。98.7%という高い精度は、複雑なカスタマーサービスの問い合わせに対して、複数のエージェントを連携させ、全体のワークフローを効果的に調整できることを示唆しています。
実例として、フライト遅延、乗り継ぎの失敗、一泊の宿泊、医療上の配慮が必要な座席指定といった複数の課題を含む問い合わせに対して、GPT-5.2は再予約、特別支援が必要な座席の手配、補償対応といった一連のタスクをすべて処理できることが示されています。
科学と数学の分野での性能
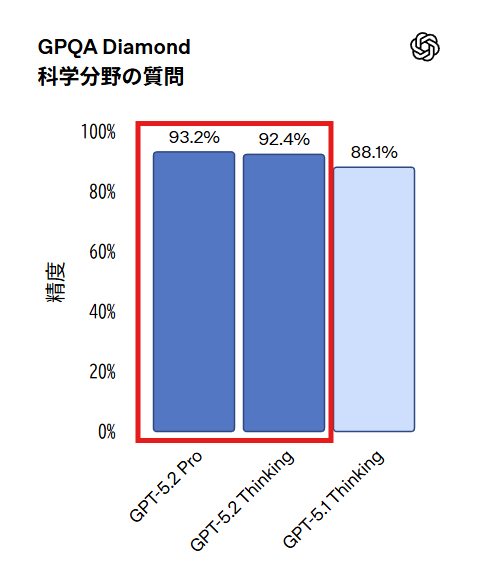
GPT-5.2 ProとGPT-5.2 Thinkingは科学研究を支援し加速するための世界屈指のモデルです。大学院レベルの科学分野の質問に回答するGPQA Diamondでは、GPT-5.2 Proが93.2%、GPT-5.2 Thinkingが92.4%を達成しました。
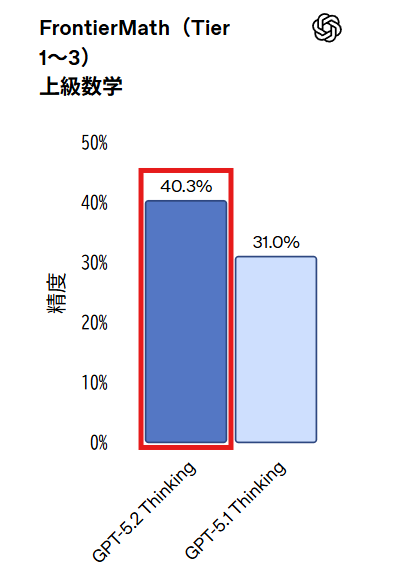
専門家レベルの数学能力を評価するFrontierMath(Tier 1〜3)では、GPT-5.2 Thinkingが40.3%の問題を解き、新たな最高スコアを達成しています。FrontierMathは現代数学の最先端の問題で構成されており、40.3%という数値は依然として多くの問題が解けないことを意味しますが、従来のGPT-5.1 Thinkingの31.0%から大幅に向上しています。
注目すべき事例として、研究者がGPT-5.2 Proを用いて統計的学習理論における未解決問題を検討し、モデルが提示した証明が著者らと外部専門家によって検証されたケースが報告されています。これは、フロンティアモデルが人による綿密な監督のもとで数学研究を支援できる可能性を示す具体例と言えます。
抽象的推論能力
汎用的な推論能力を測定するARC-AGI-1(Verified)では、GPT-5.2が初めて90%のしきい値を超えました。より難易度を高めたARC-AGI-2(Verified)で、GPT-5.2 Thinkingは52.9%を記録し、思考の連鎖モデルとして新たな最高スコアを達成しています。
ARC-AGI(Abstraction and Reasoning Corpus for Artificial General Intelligence)は、新規性の高い抽象的な問題に対する推論能力を評価するベンチマークです。既存の知識やパターン認識だけでは解けない問題が含まれており、汎用的な知性の指標の一つとされています。ARC-AGI-2はARC-AGI-1よりもさらに難易度が高く、GPT-5.2 Thinkingの52.9%に対してGPT-5.1 Thinkingは17.6%でした。この大幅な向上は、GPT-5.2が複雑な技術タスクにおいて、より強力な多段階推論と一貫性のある問題解決能力を備えていることを示していると考えられます。
安全性への取り組み
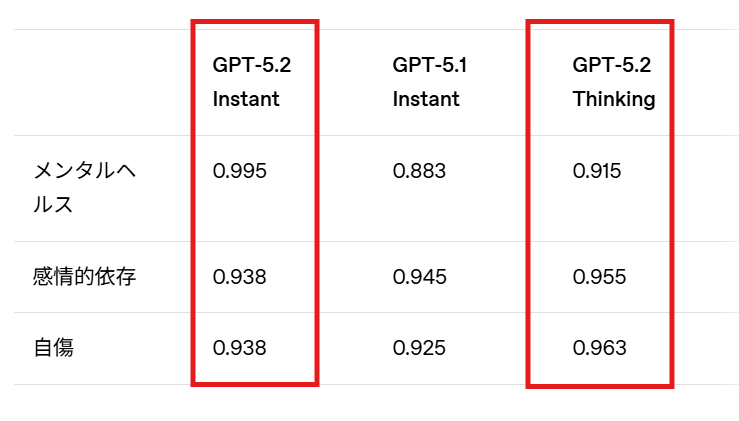
GPT-5.2は安全性を保ちつつ最も有用な回答を返せるように訓練されたモデルです。自殺や自傷の兆候、メンタルヘルスの困難、モデルへの感情的な依存を示すプロンプトへの応答において大きな改善が見られました。
メンタルヘルス関連の評価では、GPT-5.2 Instantが0.995、GPT-5.2 Thinkingが0.915のスコアを記録しており、GPT-5.1と比べて望ましくない応答が少なくなっています。また、18歳未満のユーザーに対してセンシティブなコンテンツへのアクセスを制限する年齢推定モデルの導入も開始されています。
ただし、OpenAIの発表では、GPT-5.2は継続的な改善の一歩であり、まだ道半ばであることも認識されています。過度な拒否といった既知の課題に取り組みつつ、安全性と信頼性の全体的な水準向上を進めているとのことです。
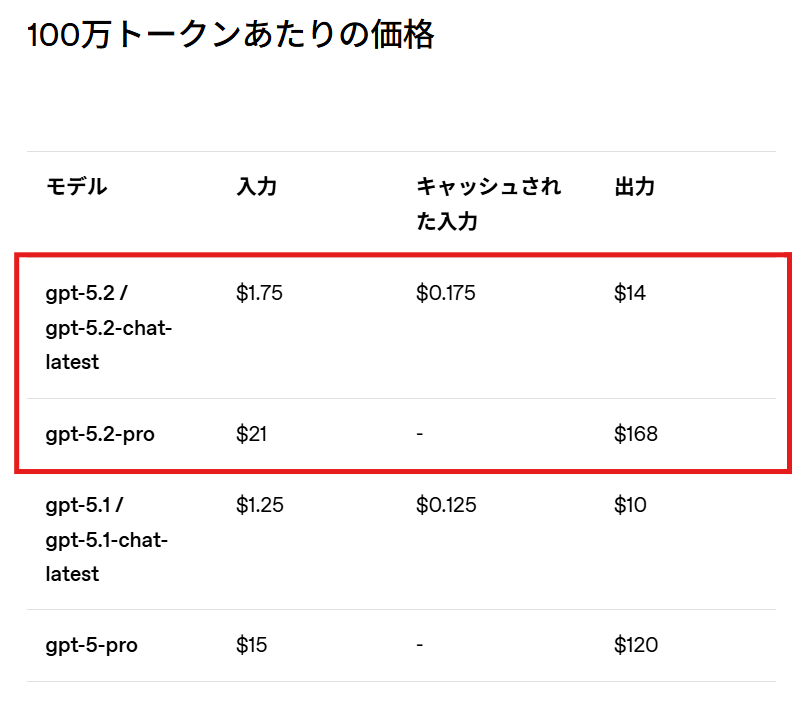
価格設定と提供状況
GPT-5.2の価格は入力トークン100万あたり1.75ドル、出力トークン100万あたり14ドルで、キャッシュされた入力には90%の割引が適用されます。GPT-5.1の入力1.25ドル、出力10ドルと比較すると、1トークンあたりのコストは約40%高い設定となっています。
GPT-5.2 Proはさらに高価格で、入力トークン100万あたり21ドル、出力トークン100万あたり168ドルに設定されています。ただし、OpenAIの発表では、複数のエージェント型評価において、GPT-5.2は1トークンあたりのコストは高いものの、トークン効率が高いため、同じ品質レベルに到達するための総コストはむしろ低く抑えられるケースがあるとされています。
ChatGPTでは、GPT-5.2(Instant、Thinking、Pro)が有料プラン(Plus、Pro、Go、Business、Enterprise)から順次提供開始されます。APIでは、すべての開発者が本日から利用可能です。なお、GPT-5.1、GPT-5、GPT-4.1を非推奨とする予定は現時点ではないとのことです。
開発パートナーとインフラ
GPT-5.2は長年のパートナーであるNVIDIAとMicrosoftとの協力のもと構築されました。H100、H200、GB200-NVL72を含むNVIDIA GPUとAzureデータセンターが、OpenAIの大規模な学習インフラを支えています。
これらの先端的なGPUとクラウドインフラの組み合わせにより、計算リソースを確実に拡張し、新しいモデルをより迅速に提供できるようになっているとのことです。特にGB200-NVL72は、NVIDIAの最新世代のGPUシステムであり、大規模言語モデルの訓練と推論の両方において高い性能を発揮します。
まとめ
OpenAIのGPT-5.2は、専門業務、ソフトウェアエンジニアリング、長文コンテキスト処理、画像認識、科学・数学など幅広い分野で大幅な性能向上を実現しました。特に知識業務タスクで人間の専門家レベルに到達したことは、実務での活用可能性を大きく広げる成果と言えます。価格設定は従来モデルより高めですが、トークン効率の向上により総コストは抑えられる可能性があります。今後、実務での検証が進むにつれて、具体的な活用領域がより明確になっていくと思います。