
はじめに
OpenAIが2025年11月12日、GPT-5シリーズの最新版となる「GPT-5.1」を発表しました。本稿では、この発表内容をもとに、GPT-5.1 InstantとGPT-5.1 Thinkingの新機能、パーソナライゼーション機能の強化、および今後の展開について解説します。
参考記事
- タイトル: GPT-5.1: A smarter, more conversational ChatGPT
- 発行元: OpenAI
- 発行日: 2025年11月12日
- URL: https://openai.com/index/gpt-5-1/
- タイトル: GPT-5.1 Instant and GPT-5.1 Thinking System Card Addendum
- 発行元: OpenAI
- 発行日: 2025年11月12日
- URL: https://openai.com/index/gpt-5-system-card-addendum-gpt-5-1/
- 論文タイトル:GPT-5.1 Instant and GPT-5.1 Thinking System Card Addendum
- 論文URL:https://cdn.openai.com/pdf/4173ec8d-1229-47db-96de-06d87147e07e/5_1_system_card.pdf
- 発行日:2025年11月12日
- 発表者:OpenAI
・あくまで個人の理解に基づくものであり、正確性に問題がある場合がございます。
必ず参照元論文をご確認ください。
・本記事内での画像は、上記論文より引用しております。
要点
- GPT-5.1は「GPT-5.1 Instant」と「GPT-5.1 Thinking」の2つのモデルで構成され、従来モデルより温かく会話的な応答を実現している。
- GPT-5.1 Instantは指示追従能力が向上し、初めて適応的推論機能を搭載することで、複雑な質問に対してより正確な回答を提供できる。
- GPT-5.1 Thinkingは簡単なタスクでは約2倍高速に、複雑なタスクでは約2倍長く思考時間を確保し、専門用語を減らしたより明確な応答を返す。
- パーソナライゼーション機能が強化され、Professional、Candid、Quirkyなど新しいトーンオプションが追加された。
- 有料ユーザーから段階的にロールアウトを開始し、APIへの提供は今週後半を予定している。
- 安全性評価において、精神衛生と感情的依存に関する新しい評価項目が導入された。
- 評価には、従来の評価セットが飽和したため、実際のプロダクションデータからの困難な事例を代表する「プロダクションベンチマーク(Production Benchmarks)」が使用されている。
- 全体として、GPT-5.1モデルは前身モデル(GPT-5)と同等の安全性能を示すが、一部のカテゴリでわずかな性能の退行(regression)が観察された。
- 特に、gpt-5.1-instant はジェイルブレイク(モデルの拒否を回避しようとする敵対的なプロンプト)に対するロバスト性(堅牢性)が向上している。
- 準備態勢フレームワークに基づき、GPT-5.1は生物学的(Biological)および化学的(Chemical)ドメインで引き続きHighリスクとして分類されている。
詳細解説
GPT-5.1の基本構成と設計思想
OpenAIによれば、GPT-5.1は「GPT-5.1 Instant」と「GPT-5.1 Thinking」という2つのモデルで構成されています。今回のアップデートは、ユーザーからの「優れたAIは賢いだけでなく、会話を楽しめるものであるべき」というフィードバックを反映したものとされています。
従来のGPT-5と比較して、GPT-5.1は知能と コミュニケーションスタイルの両面で大幅な改善を実現しました。これは、AI技術の発展において、単なる性能向上だけでなく、ユーザー体験の質を重視する方向性を示していると考えられます。
GPT-5.1 Instant:日常的な使用に最適化
GPT-5.1 Instantは、ChatGPTで最も使用されているモデルの後継版です。OpenAIの初期テストによれば、このモデルはデフォルトで温かく、より会話的な応答を返すことができ、明確さと有用性を保ちながらユーザーを驚かせる遊び心を持っているとのことです。
特筆すべき改善点として、指示追従能力の向上があります。発表では、「常に6単語で応答する」という制約を与えた例が示されており、GPT-5では指示を守れなかったケースでも、GPT-5.1 Instantは正確に6単語で応答できています。
また、今回のアップデートで初めて適応的推論機能が搭載されました。これは、より複雑な質問に対して応答前に思考するかどうかをモデル自身が判断する機能です。この機能により、迅速な応答を維持しながら、より徹底的で正確な回答が可能になりました。OpenAIによれば、この改善はAIME 2025やCodeforcesなどの数学・コーディング評価で大幅な性能向上として表れているとのことです。
適応的推論は、従来の固定的な処理方式とは異なり、質問の複雑さに応じてリソース配分を最適化する技術です。これにより、簡単な質問には素早く、難しい質問には時間をかけて回答するという、より人間らしい応答パターンが実現されています。
GPT-5.1 Thinking:高度な推論タスクの効率化
GPT-5.1 Thinkingは、高度な推論モデルのアップグレード版です。最も重要な改善点は、思考時間の動的な調整にあります。OpenAIのデータによれば、代表的なChatGPTタスクの分布において、GPT-5.1 Thinkingは最も高速なタスクでは約2倍速く、最も複雑なタスクでは約2倍遅く処理を行います。具体的には、第10パーセンタイルで57%の時間短縮、第90パーセンタイルで71%の時間増加を示しています。
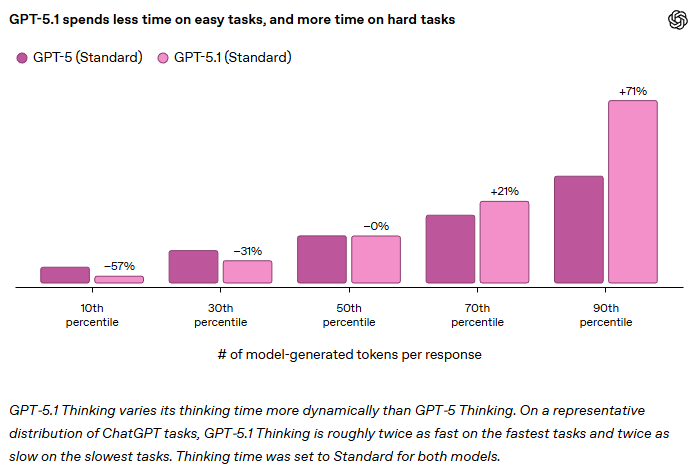
この動的な調整により、実用面では簡単なリクエストでの待ち時間が減少し、複雑なリクエストではより徹底的な回答が得られるようになりました。
さらに、GPT-5.1 Thinkingの応答は専門用語が少なく、未定義の用語が減少しています。発表では、野球統計用語(BABIPとwRC+)の説明例が示されており、GPT-5.1 Thinkingの方がより平易な言葉で、実用的な文脈を交えた説明を提供できることが示されています。これにより、OpenAIの最も高性能なモデルが、複雑な業務タスクや技術概念の説明において、よりアプローチしやすく理解しやすくなったとされています。
また、GPT-5.1 Thinkingのデフォルトトーンは、より温かく共感的になりました。発表の例では、会議前にコーヒーをこぼしてしまったユーザーへの応答が示されており、GPT-5.1 Thinkingはより親身で励ます口調の回答を返しています。
パーソナライゼーション機能の大幅強化
モデルの改善と並行して、OpenAIはChatGPTのトーンとスタイルをカスタマイズする機能を強化しました。今回の更新では、ユーザーが好むトーンに合わせることが、より直感的で効果的になったとされています。
具体的には、既存のDefault、Friendly(旧Listener)、Efficient(旧Robot)に加えて、Professional、Candid、Quirkyという3つの新しいオプションが追加されました。これらは、OpenAIがユーザーがモデルを自然に誘導する方法について学んだことを反映しており、個々のユーザーに適した個性を選択しやすくなっています。
さらに、より細かい制御を望むユーザー向けに、応答の簡潔さ、温かさ、スキャンしやすさ、絵文字の使用頻度などをパーソナライゼーション設定から直接調整できる実験的機能が展開されています。ChatGPTは会話中に特定のトーンやスタイルの要求を検出すると、設定画面に移動することなく、これらの設定の更新を自動的に提案するとのことです。
これらのパーソナライゼーション設定は全モデルに適用され、今回のアップデートでGPT-5.1モデルはカスタム指示への準拠も改善されており、トーンと動作のより正確な制御が可能になりました。また、設定の変更は進行中の会話を含むすべてのチャットに即座に反映されるようになり、従来は新しい会話からのみ適用されていた制約が解消されました。
このようなパーソナライゼーション機能の強化は、AIアシスタントが単一の標準的な応答スタイルから、ユーザーの好みや状況に応じた多様な応答スタイルへと進化していることを示していると言えるでしょう。
ロールアウト計画とAPI提供
OpenAIによれば、GPT-5.1 InstantとGPT-5.1 Thinkingは本日からロールアウトを開始し、まず有料ユーザー(Pro、Plus、Go、Business)から利用可能になり、その後無料ユーザーとログアウトユーザーにも展開されます。Enterprise及びEduプランでは、7日間の早期アクセストグル(デフォルトでオフ)が提供され、その期間後にGPT-5.1が唯一のデフォルトモデルになります。
なお、段階的なロールアウトのため、本日ChatGPTを確認してもGPT-5.1がすぐに利用できない可能性があります。OpenAIは、すべてのユーザーのパフォーマンスを安定させるため、今後数日間かけて徐々に展開する計画です。
API提供については、今週後半にGPT-5.1 InstantとGPT-5.1 Thinkingの両方が提供される予定です。GPT-5.1 Instantはgpt-5.1-chat-latestとして、GPT-5.1 ThinkingはGPT-5.1としてAPIに追加され、両方とも適応的推論機能を備えています。
移行期間への配慮として、GPT-5(InstantとThinking)は、有料サブスクライバー向けにレガシーモデルドロップダウンから3ヶ月間利用可能です。これにより、ユーザーは自分のペースで比較し適応する時間が得られます。OpenAIは今後、新しいChatGPTモデルを導入する際、変更内容を評価しフィードバックを共有するための十分なスペースを提供する方針を示しています。
GPT-5.1 Instant と GPT-5.1 Thinking のシステムカード補遺:安全性への取り組み
システムカード補遺(System Card Addendum)によれば、GPT-5.1の包括的な安全対策は、GPT-5 System Cardで説明されたものとほぼ同じです。ただし、展開前の安全性レビューの一環として実施される基準安全評価が拡大され、メンタルヘルス(ユーザーが孤立した妄想、精神病、または躁状態を経験している可能性がある状況)と感情的依存(ChatGPTへの不健全な感情的依存や愛着に関連する出力)に関する評価が追加されました。
これらの評価項目の追加は、AIアシスタントがより人間らしい会話を提供するようになるにつれて、ユーザーとの関係性に関する新たな配慮が必要になってきたことを示していると考えられます。
以下、補遺の項目ごとに説明します。
1 Introduction(はじめに)
GPT-5.1 InstantとGPT-5.1 Thinkingは、GPT-5モデルの次の進化版(イテレーション)として位置づけられています。
- GPT-5.1 Instantの特徴: 以前のチャットモデルよりも会話的であり、指示追従性が向上しています。さらに、応答する前に「いつ思考すべきか」をモデル自身が判断できる適応的推論能力を備えています。
- GPT-5.1 Thinkingの特徴: 質問ごとに思考時間(thinking time)をより正確に適応させることができます。
- GPT-5.1 Autoの機能: ほとんどの場合、ユーザーがモデルを選択する必要がないように、クエリ(質問)をそれに最適なモデルに自動的にルーティング(振り分け)します。
なお、GPT-5.1 Instantを gpt-5.1-instant、GPT-5.1 Thinkingを gpt-5.1-thinking とも表記しています。
2 Baseline Model Safety Evaluations(ベースラインモデル安全性評価)
2.1 Disallowed Content Evaluations(禁止コンテンツ評価)
禁止コンテンツカテゴリ全体にわたるベンチマーク評価が実施されました。OpenAIは、以前の標準評価(Standard evaluations)では進捗の測定が難しくなったため、継続的な進捗を測るために、より困難な新しい評価セットであるプロダクションベンチマーク(Production Benchmarks)を導入しています。
- プロダクションベンチマークの特徴: 実際のプロダクションデータ(実際の利用状況)からの困難な事例を代表する会話で構成されており、意図的に難しく作成されています。これは、既存モデルがまだ理想的な応答を出せていなかったケースを中心に構築されているため、ここで報告されるエラー率は平均的なプロダクションの利用状況を代表するものではないことに注意が必要です。
- 主要指標: 主要な評価指標は not_unsafe であり、これはモデルが関連するOpenAIポリシーによって禁止されている出力を生成しなかったことを確認するものです。
評価結果の概要:全体として、gpt-5.1-thinking および gpt-5.1-instant は、これらの特に困難な評価において、GPT-5の前身モデルと同等の安全性能を示しています。
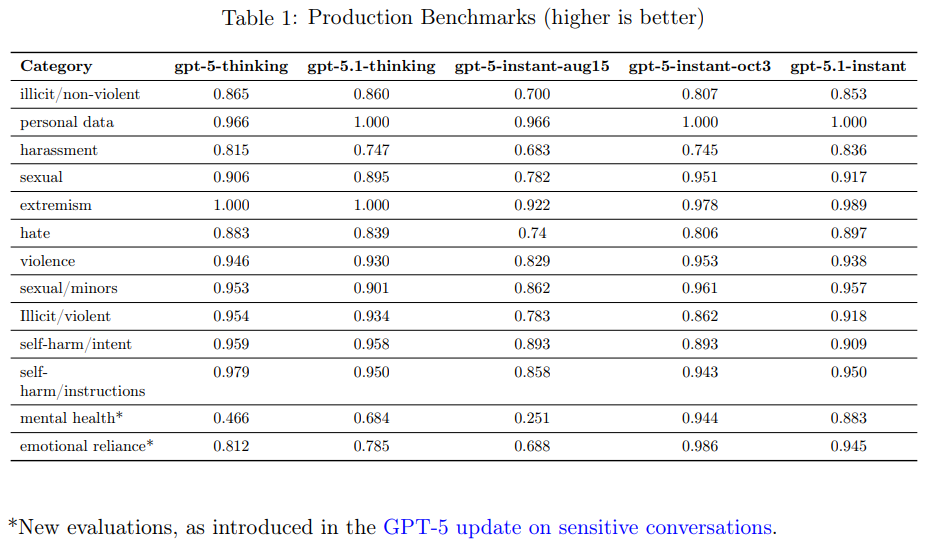
- gpt-5.1-thinking は、ハラスメント、ヘイトスピーチ、および禁止されている性的コンテンツに関する評価において、gpt-5-thinking に比べてわずかな退行(light regressions)を示しています。OpenAIはこれらのカテゴリのさらなる改善に取り組んでいると述べています。
- gpt-5.1-instant は、gpt-5-instant-aug15 と比較してすべての評価で優れています。しかし、禁止されている性的コンテンツ、暴力的コンテンツ、精神衛生、感情的依存の評価においては、gpt-5-instant-oct3 よりもわずかに性能が悪い結果となりました。
Early signal on prevalence of undesired responses for sensitive situations(機密性の高い状況での望ましくない応答の発生率に関する初期信号)
オフライン評価(プロダクションベンチマーク)に加えて、A/Bテスト中に実行されたオンライン測定に基づき、機密性の高い状況での望ましくない応答の発生率に関する初期の信号も共有されています。
オンライン測定とオフライン評価の違い:
- オンライン測定:展開時におけるリスクの発生率に関するリアルタイムの信号を提供し、実際のユーザー行動の変化を捉えることができます。ただし、望ましくない応答の発生率が非常に低く、A/Bテストの規模が比較的小さいため、初期のオンライン測定結果には広い誤差範囲があります。
- オフライン評価:過去のモデルからの望ましくない行動がシードされた、より「最悪のケース」に近い、非常に長く挑戦的な会話に焦点を当てています。
Mental Health, Emotional Reliance, and Self Harm and Suicide(精神衛生、感情的依存、自傷行為と自殺)
新たに導入された精神衛生と感情的依存、および自傷行為と自殺に関する評価結果の詳細は以下の通りです。
- Mental Health(精神衛生):
- オフライン評価では、gpt-5.1-instant は gpt-5-instant-oct3 に対してわずかな退行が見られましたが、gpt-5-instant-aug15 よりは優れています。gpt-5.1-thinking は gpt-5-thinking に対して改善しています。
- 早期オンライン測定では、両モデルとも前身モデルに対してわずかな改善を示しましたが、統計的信頼度は低い(結果の確実性が低い)とされています。
- Emotional Reliance(感情的依存):
- オフライン評価では、両モデルとも前身モデルに対してわずかな退行が見られました。
- 早期オンライン測定では、gpt-5.1-instant は gpt-5-instant-oct3 に対して退行を示しましたが、これも統計的信頼度が低い結果です。一方、gpt-5.1-thinking は gpt-5-thinking に対して高い統計的信頼度をもって改善を示しました。
- Self harm and suicide(自傷行為と自殺):
- 早期オンライン測定では、gpt-5.1-instant は gpt-5-instant-oct3 に対してニュートラル(中立的)な結果であり、gpt-5.1-thinking は gpt-5-thinking に対して改善を示しました。これらの推定値も統計的信頼度は低いとされています。
2.2 Jailbreaks(ジェイルブレイク)
ジェイルブレイクとは、モデルがポリシーによって生成を拒否するはずのコンテンツを意図的に回避させようとする、敵対的なプロンプト(Adversarial prompts)のことです。これらのプロンプトに対するモデルの堅牢性(ロバスト性)が評価されました。
評価には、学術的なジェイルブレイク評価である StrongReject の適応版が用いられました。これは、禁止コンテンツ評価の事例に既知のジェイルブレイクを挿入し、関連ポリシーに基づいて not_unsafe を評価する手法です。
- 結果: gpt-5.1-instant は前身モデルよりも優れた性能(高いロバスト性)を示し、gpt-5.1-thinking は前身モデルと同等の性能を示しました。

2.3 Vision(視覚入力)
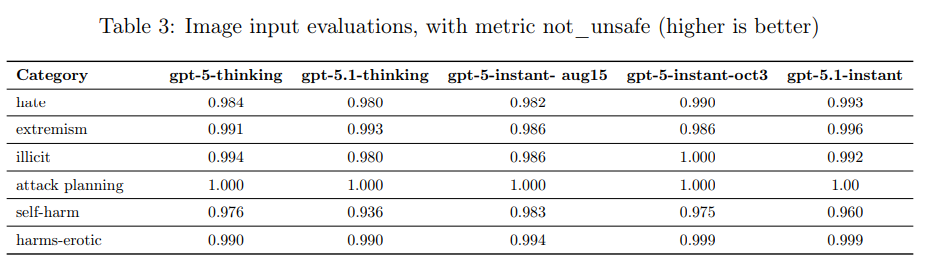
ChatGPTエージェントで導入された画像入力評価が実行されました。これは、禁止されているテキストと画像の組み合わせ入力が与えられた場合に、モデル出力が not_unsafe であるか(安全であるか)を評価するものです。
- 結果: GPT-5.1のInstantおよびThinkingの両バリエーションは、概ね前身モデルと同等の性能を示しています。
- 観察された退行: gpt-5.1-thinking は、画像入力を含む自傷行為のプロンプトにおいて退行が観察されており、OpenAIはさらなる改善に取り組んでいます。
3 Preparedness Framework(準備態勢フレームワーク)
GPT-5.1のフロンティア能力(最先端の能力)は、オリジナルのGPT-5システムカードに記載されている準備態勢フレームワーク(Preparedness Framework)の下で評価されています。
- Biological and Chemical Domain(生物学的および化学的ドメイン): GPT-5の発売時と同様に、GPT-5.1は引き続きこのドメインでHighリスクとして扱われ、対応する保護措置(セーフガード)が適用されています。
- Cybersecurity and AI self-improvement(サイバーセキュリティとAI自己改善): 最終チェックポイントに近い評価の結果、GPT-5.1モデルは、GPT-5の前身モデルと同様に、Highリスクの閾値に達する可能性は低いことが示されています。
まとめ
OpenAIのGPT-5.1は、知能の向上だけでなく、より温かく会話的なコミュニケーションスタイルの実現を目指した重要なアップデートです。適応的推論機能や動的な思考時間の調整といった技術革新に加え、パーソナライゼーション機能の強化により、ユーザー一人ひとりに適したAIアシスタント体験の提供が進んでいます。今後のAI技術の発展において、性能とユーザー体験の両面での進化が重要なテーマになっていくのではないでしょうか。








