
はじめに
近年、目覚ましい発展を遂げているAI技術の中でも、特に注目を集めているのが画像を生成するAIです。これまでも様々な画像生成AIが登場してきましたが、今回OpenAIが発表した「GPT-4o image generation」は、その性能と安全性において新たな一歩を踏み出すものとして、大きな話題を呼んでいます。
本記事では、OpenAIが2025年3月25日に公開した「Addendum to GPT-4o System Card: Native image generation」という公式文書に基づき、「GPT-4o image generation」がどのような技術を持ち、どのような点に力が入れられているのかを、解説します。
参考元論文
- 論文タイトル: Addendum to GPT-4o System Card: Native image generation
- URL: https://cdn.openai.com/11998be9-5319-4302-bfbf-1167e093f1fb/Native_Image_Generation_System_Card.pdf
- 発行日: 2025年3月25日
・あくまで個人の理解に基づくものであり、正確性に問題がある場合がございます。
必ず参照元論文をご確認ください。
・本記事内での画像は、上記論文より引用しております。
要点
「GPT-4o image generation」は、OpenAIの以前の画像生成モデルであるDALL·Eシリーズを大幅に進化させた、全く新しい画像生成アプローチです。
その主な特徴は以下の通りです。
- 驚異的なフォトリアリズム:まるで本物の写真のような、非常にリアルな画像を生成できます。
- 画像を入力とした変換:既存の画像を入力として、それに関連した画像や修正を加えた画像を生成できます。
- 詳細な指示への対応:複雑な指示にも正確に従い、画像内にテキストを自然に組み込むことも可能です。
- GPT-4oへのネイティブ統合:OpenAIの基盤モデルであるGPT-4oの内部に深く組み込まれているため、GPT-4oが持つ知識を活かした、繊細で表現豊かな画像を生成できます。
このような高度な機能を持つ一方で、OpenAIは安全性にも細心の注意を払っています。DALL·EやSoraの開発・運用で得られた教訓を活かし、新たなリスクに対応するための安全対策が講じられています。
詳細解説
「GPT-4o image generation」とは?
「GPT-4o image generation」は、OpenAIが開発した最新の画像生成AIであり、従来のDALL·Eシリーズとは根本的に異なるアプローチを採用しています 。DALL·Eが拡散モデル(diffusion model)として動作するのに対し、「GPT-4o image generation」は、ChatGPTの中にネイティブに組み込まれた自己回帰モデル(autoregressive model)です。この基本的な違いが、以前の画像生成モデルにはなかった新しい機能と、それに伴う新たなリスクをもたらしています。
主な新機能とその可能性
「GPT-4o image generation」が持つ主な新機能は以下の3点です。
Image-to-Image Transformation(画像から画像への変換)
この機能により、ユーザーは1枚または複数の画像を入力として、「GPT-4o image generation」に関連する新しい画像を生成したり、入力画像を修正したりすることができます。例えば、簡単なスケッチを入力して、それをリアルな風景画に変換したり、既存の写真を異なるスタイルに加工したりすることが考えられます。
Photorealism(フォトリアリズム)
従来の画像生成AIと比較して、「GPT-4o image generation」は非常に高いレベルの写実性を実現しています。生成された画像は、場合によっては本物の写真と見分けがつかないほどリアルであり、広告、デザイン、エンターテイメントなど、幅広い分野での活用が期待されます。
Instruction Following(指示に従う能力)
ユーザーが与える詳細な指示を正確に理解し、その内容を画像に反映させることができます。さらに、画像の中に自然な形でテキストや説明図をレンダリングする能力も持っており、例えば、製品の取扱説明書に挿入するイラストや、特定のメッセージを込めた画像を生成する際に非常に役立ちます。
これらの機能は、単独で利用できるだけでなく、組み合わせて使用することで、これまで以上に多様で創造的な表現を可能にします。
一方で、これらの強力な機能は、悪用される可能性も孕んでいます。例えば、安全対策が不十分な場合、特定の人物に不利益をもたらすような写真の作成や改ざん、武器の製造に関する図解や手順の生成などに利用されるリスクが考えられます。
安全性への取り組み:セーフティスタック(Safety stack)
OpenAIは、「GPT-4o image generation」の持つ潜在的なリスクを認識し、安全性確保のために多岐にわたる対策を講じています。これらの対策は、DALL·EやSoraの運用経験から得られた教訓に基づいており、多層的なアプローチを採用しています。
「GPT-4o image generation」の安全性は、以下の複数の防御層によって支えられています。
チャットモデルによる拒否(Chat model refusals)
ユーザーがChatGPTやAPIを通じて画像生成を要求する際、まず基盤となるチャットモデルがプロンプト(指示文)の内容を分析します。ポリシーに違反する可能性のあるプロンプトと判断された場合、画像生成プロセス自体が開始されずに拒否されます。
プロンプトブロッキング(Prompt blocking)
チャットモデルによる初期チェックを通過したプロンプトであっても、画像生成ツールに送られる前に、テキストまたは画像の分類器によって再度チェックされます。ポリシー違反の可能性が高いと判断されたプロンプトは、画像生成が実行される前にブロックされます。
出力ブロッキング(Output blocking)
画像が生成された後、その内容がポリシーに違反していないかどうかがチェックされます。これには、児童性的虐待物(CSAM)を検出する専門の分類器や、安全性に関するポリシーに基づいて推論を行うようにカスタムトレーニングされたマルチモーダル推論モデルが用いられます。ポリシーに違反する画像と判断された場合、その出力はブロックされます。
未成年者に対する追加の保護(Increased safeguards for minors)
OpenAIは、18歳未満のユーザーに対して、上記全ての安全対策をさらに強化しています。特定の年齢不適切なコンテンツの生成を制限する試みが行われています。また、13歳未満のユーザーはOpenAIの製品・サービス全般の利用が禁止されています。
安全性評価
「GPT-4o image generation」の安全対策の効果を評価するために、OpenAIは様々な手法を用いてテストを実施しています。
外部による手動レッドチーム(External, manual red teaming)
OpenAIは、外部の専門家チーム(レッドチーマー)と協力し、「GPT-4o image generation」に対する攻撃を試みてもらいました。これには、モデルの安全対策を回避するための様々な手法(ジェイルブレイクなど)が含まれます。
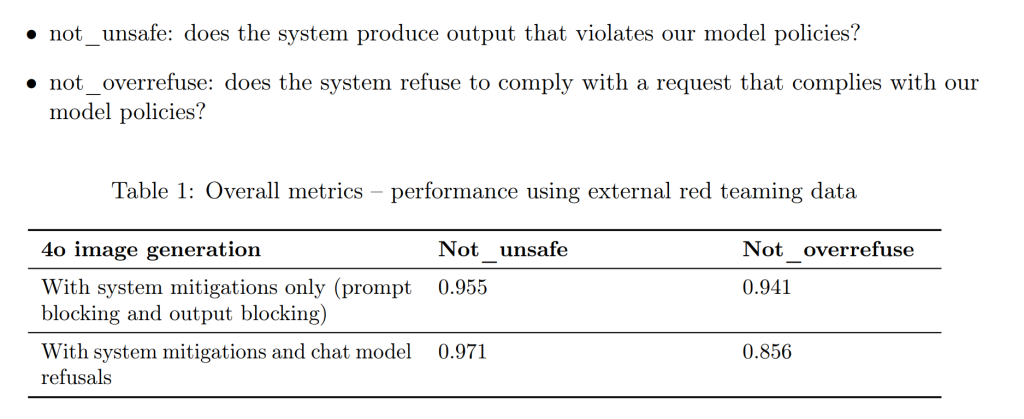
自動レッドチーム(Automated red teaming)
手動レッドチームで得られた数千件の対話データをもとに、自動評価システムを構築しました。これにより、モデルのポリシー遵守状況を網羅的にテストすることが可能になりました。
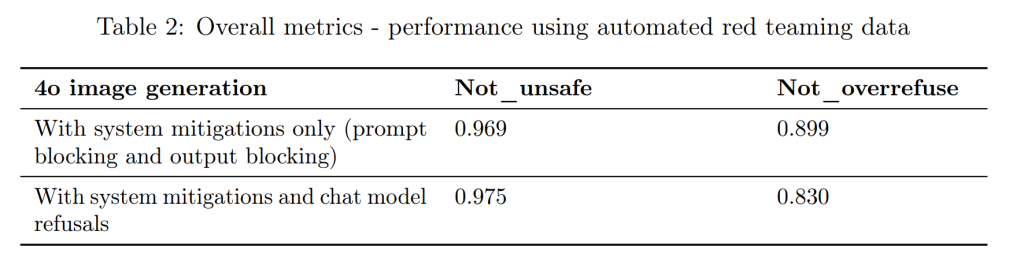
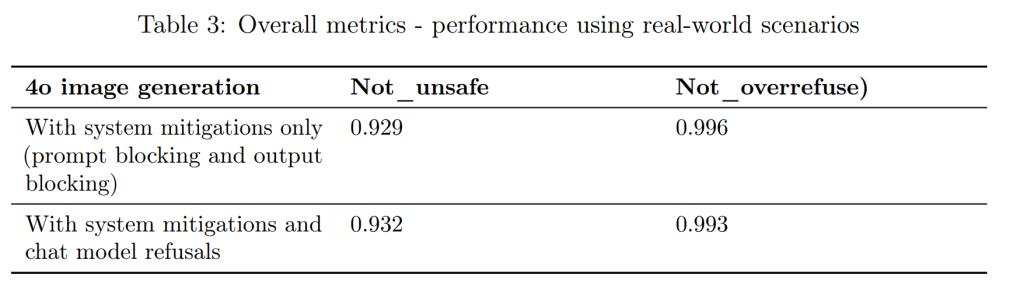
実環境シナリオを用いたオフラインテスト(Offline testing using real-world scenarios)
実際の利用状況を想定したテキストプロンプトを用いて、モデルの挙動を評価しました。これにより、実運用環境におけるモデルの性能や潜在的な課題を把握することができます。
これらの評価を通じて、「GPT-4o image generation」の安全対策が一定の効果を発揮していることが確認されています。
特定のリスク領域とその対策
OpenAIは、特に注意が必要なリスク領域を特定し、それぞれに対して具体的な対策を講じています。
児童の安全(Child Safety)
児童性的虐待物(CSAM)の生成、検出、報告を最優先事項としています。入力と出力の両方に対して厳格なスキャンを実施し、既知のCSAMとの一致を検出するツール(ThornのSaferなど)や、新たなCSAMの可能性を検出する分類器を使用しています。また、フォトリアリスティックな子供の画像を編集する機能は、現時点では許可されていません。
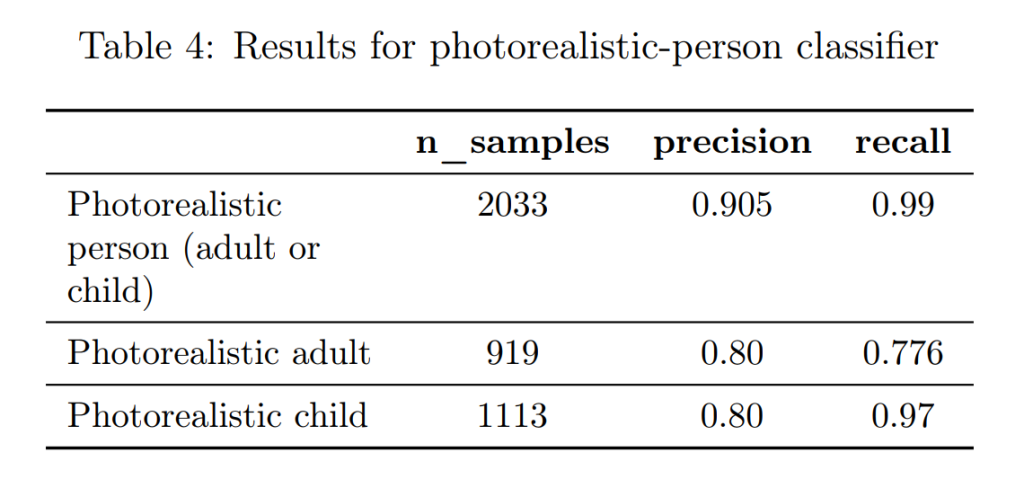
アーティストのスタイル(Artist Styles)
ユーザーが生存するアーティストの名前をプロンプトに使用して、そのアーティストのスタイルを模倣した画像を生成しようとする試みに対しては、拒否する措置を導入しています。これは、クリエイティブコミュニティからの懸念に応えるための慎重な対応です。
公的人物(Public Figures)
テキストプロンプトのみに基づいて公的人物像を生成する機能はありますが、未成年の公的人物や、暴力、憎悪表現、違法行為に関するポリシーに違反する画像の生成はブロックされます。公的人物自身が自身の画像の生成を希望しない場合は、オプトアウトすることも可能です。
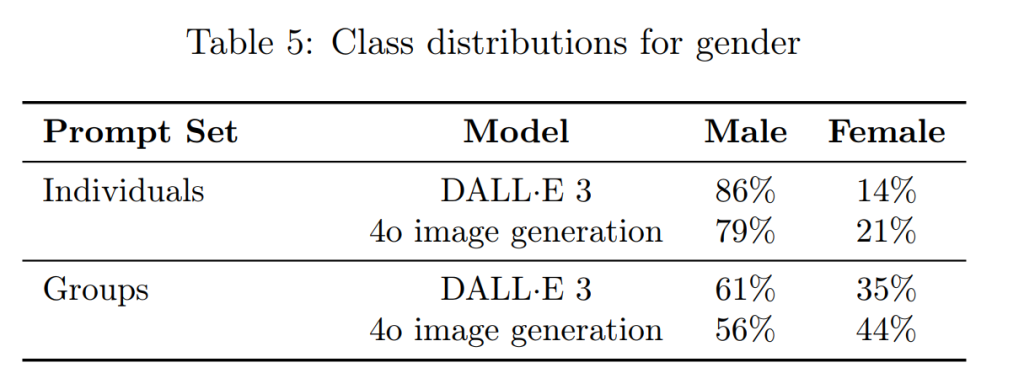
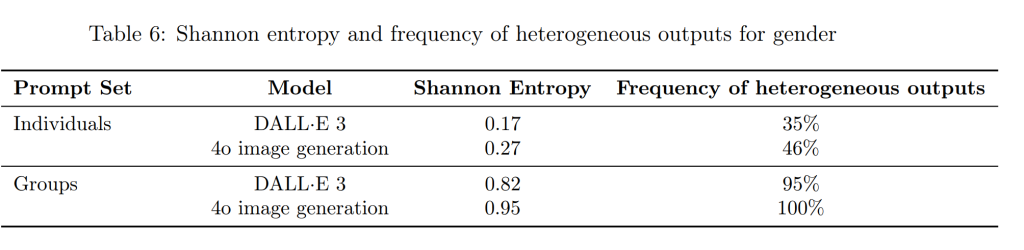
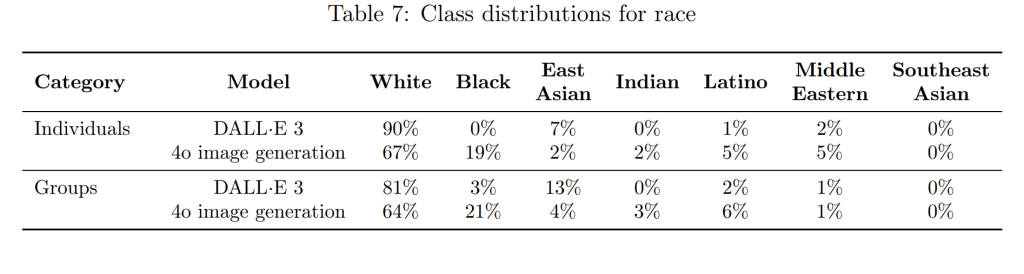
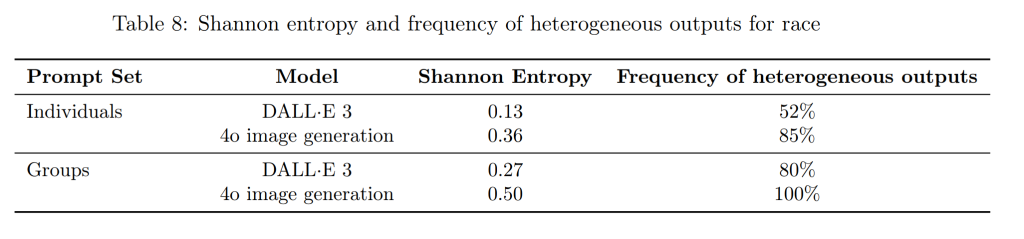
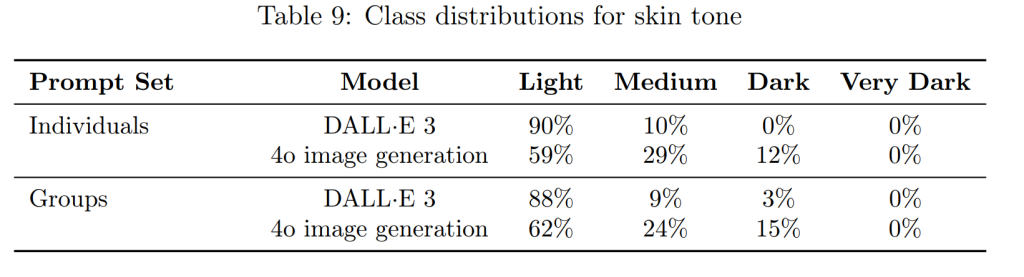
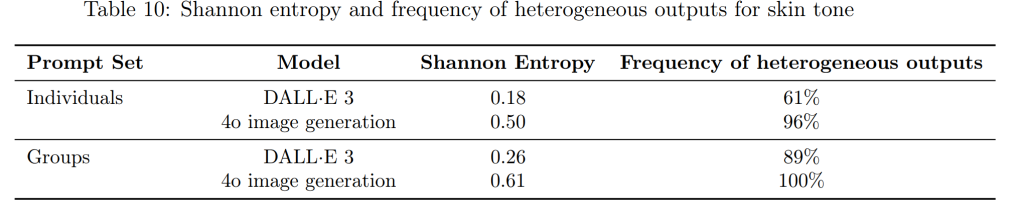
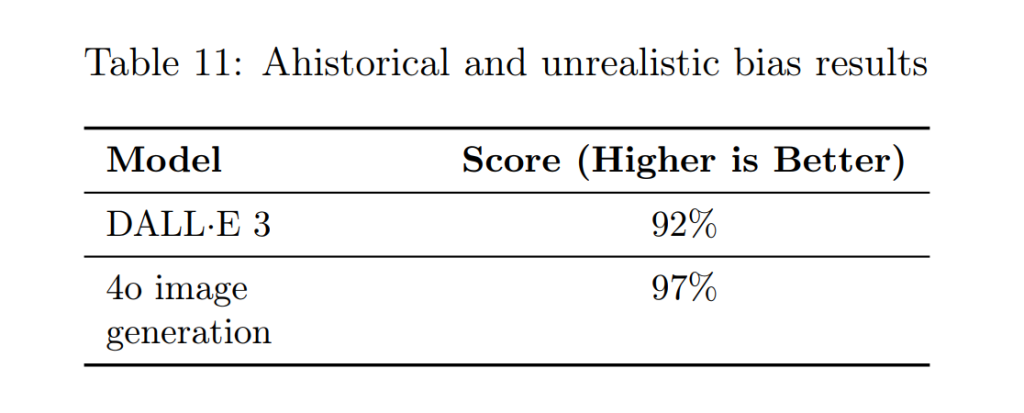
バイアス(Bias)
以前のモデル(DALL·E 3)と比較して、性別、人種、肌の色の表現におけるバイアスは低減していますが、依然として課題が残っています。今後も、よりバランスの取れた出力を実現するために、ポストトレーニングの改善などを継続していく予定です。
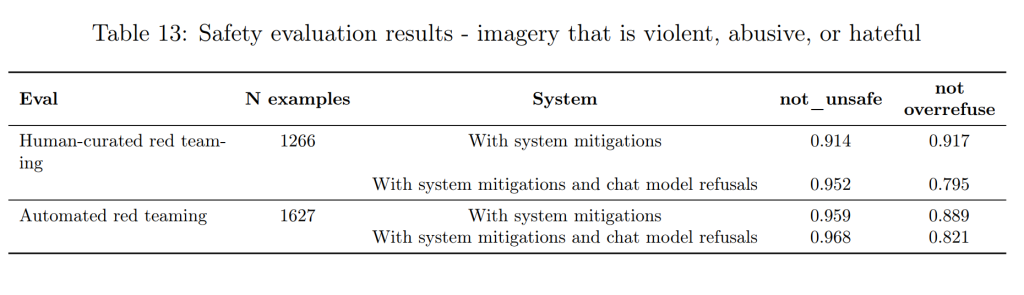
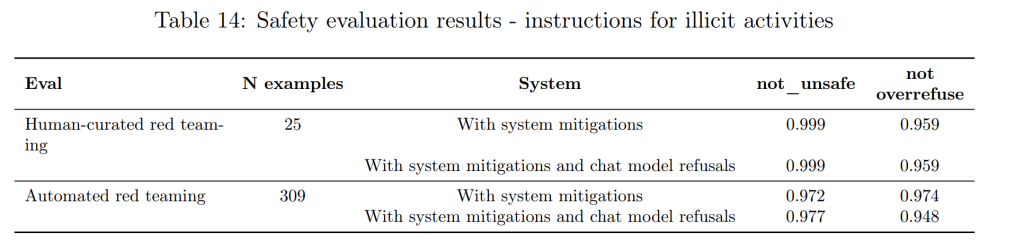
不適切なコンテンツ(Erotic content, Imagery that is violent, abusive or hateful, Instructions for illicit activities)
エロティックなコンテンツや性的搾取につながる画像の生成、暴力、虐待、憎悪を助長する画像の生成、武器や違法行為に関する指示を含む画像の生成は、厳しく禁止されています。ただし、芸術的、創造的、教育的な文脈における暴力表現や、批判的、教育的、中立的な文脈におけるヘイトシンボルの使用など、慎重な判断が必要なケースについては、より寛容なアプローチを取りつつ、未成年者の保護には特に注意を払っています。

来歴(Provenance)への取り組み
生成された画像の信頼性を高めるために、OpenAIは来歴(Provenance)に関するツールの開発にも力を入れています。
C2PAメタデータ
生成された全ての画像には、C2PA(Coalition for Content Provenance and Authenticity)のメタデータが付与されます。これにより、画像の起源を検証することが可能になります。
内部ツール
OpenAIは、特定の画像が自社の製品によって生成されたものかどうかを評価するための内部ツールを開発しています。
OpenAIは、Provenanceの確立には単一の解決策がないことを認識しており、業界や市民社会との協力を通じて、この問題への取り組みを継続していくとしています。
まとめ
OpenAIの「GPT-4o image generation」は、かつてないレベルの表現力と安全性を兼ね備えた、次世代の画像生成AIと言えるでしょう。フォトリアリズム、画像変換、詳細な指示への対応能力は、ビジネスやクリエイティブな活動において新たな可能性を開きます。一方で、OpenAIは、その強力な機能がもたらす潜在的なリスクに真摯に向き合い、多層的な安全対策と継続的な評価を通じて、安全なAIシステムの開発・運用に取り組んでいます。
今後、「GPT-4o image generation」がどのように活用され、社会にどのような影響を与えていくのか、注目が集まります。








