
はじめに
近年、大規模言語モデル(LLM)の進化には目覚ましいものがあり、その応用範囲は日々広がっています。特に、LLMが複雑な問題を解決するために「推論」を行う能力は、人工知能の重要な目標の一つです。これまでの研究では、ルールが明確で正解を客観的に検証しやすい数学的な推論の領域で、強化学習(RL)を用いることで大きな成功を収めてきました。
しかしながら、数学以外のより広範な推論領域、例えば科学、人文科学、社会科学といった分野では、ルールが必ずしも明確でなかったり、答えが一つに定まらなかったりするため、RLによる学習は困難が伴いました。特に、RLの学習に必要な「報酬」をどのように設計し、与えるかが大きな課題となっていたのです。
本稿では、NVIDIAの研究者らが提案する新しいフレームワーク「NEMOTRON-CROSSTHINK」に焦点を当てて解説します。このフレームワークは、多様なドメインのデータを体系的にRLトレーニングに取り込むことで、LLMの推論能力を数学分野だけでなく、より広範な領域に汎化させることを目指しています。
引用元記事
論文
- タイトル: NEMOTRON-CROSSTHINK: Scaling Self-Learning beyond Math Reasoning
- URL: https://arxiv.org/pdf/2504.13941
関連
- タイトル:Nemotron-CrossThink
- URL:https://huggingface.co/datasets/nvidia/Nemotron-CrossThink
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
GoogleColab(弊社作成)
https://colab.research.google.com/drive/1llwouSl3RcSzKh1jK0XNGIHwSEOl0ICS?usp=sharing
要点
- 強化学習(RL)を多領域の推論タスクに拡張: 従来のRLによるLLM推論能力強化は数学やコーディングに偏っていましたが、これを人文科学、社会科学などを含む多様な分野に広げました。
- 多様なドメインと形式のデータを体系的に統合: 合成データと既存のオープンソースデータセットを組み合わせ、STEM分野から人文科学、社会科学、法律まで、幅広い領域の質問応答ペアを収集・活用します。また、多肢選択(MCQ)と自由記述(Open-Ended)といった異なる質問形式に対応します。
- 検証可能な報酬モデリングの実現: 数学のように明確な正解がない領域でも、構造化されたテンプレートやフィルタリングを用いることで、RLの学習に必要な信頼性の高い報酬信号(検証可能な報酬)を設計可能にしました。
- データブレンドとフィルタリング戦略: 異なるドメインのデータを効果的に組み合わせるブレンド戦略や、難易度の高いサンプルを選別するフィルタリングが、LLMの汎化性能を向上させることを示しました。
- 優れた汎化性能と効率性: NEMOTRON-CROSSTHINKを用いて学習したモデルは、数学および非数学ドメインの様々なベンチマークにおいて、ベースラインモデルや数学特化モデルを上回る高い精度を達成しました。さらに、正解回答に必要なトークン数が平均で28%削減されるなど、推論効率も大幅に向上しました。
詳細解説
背景と課題
大規模言語モデル(LLM)は、人間の言語を理解し、それに基づいて様々なタスクをこなす能力を持っています。特に、複雑な問題を解決するための「推論」の能力は、LLMの性能を引き上げる上で重要となっています。最近の研究では、強化学習(RL)を用いることで、LLMの推論能力を向上してきました。
RLを用いるアプローチは、特に数学やプログラミングのような分野で有効でした。これらの分野では、問題に対する正解が明確に定義されており、計算やコードの実行によって正しさを客観的に検証しやすいため、RL学習のための「報酬モデル」を比較的容易に設計できるためです。
しかし、現実世界の推論タスクは数学だけではありません。人文科学、社会科学、法律、歴史など、様々な分野で推論が求められます。これらの分野の推論は、数学のようにルールベースで構造化された記号的なアプローチ(例: 数式の展開)だけでなく、文脈的な知識、物語構造、ヒューリスティックな探索(経験や直感に基づく探索)に依存することが多いのです。
このような多様な推論タスクに対してRLを適用しようとすると、いくつかの大きな課題に直面します。まず、RL学習に適した質の高いトレーニングデータが限られていること。そして、数学のように明確な正解や検証方法がないため、「正しい推論」や「良い答え」に対する報酬を設計するのが非常に難しいこと。さらに、特定のドメインで学習した推論能力を、他の未知のドメインでも発揮できるような汎化能力をどう確保するか、といった点が挙げられます。NEMOTRON-CROSSTHINKは、これらの課題に体系的に取り組むために開発されました。
NEMOTRON-CROSSTHINKフレームワークの概要
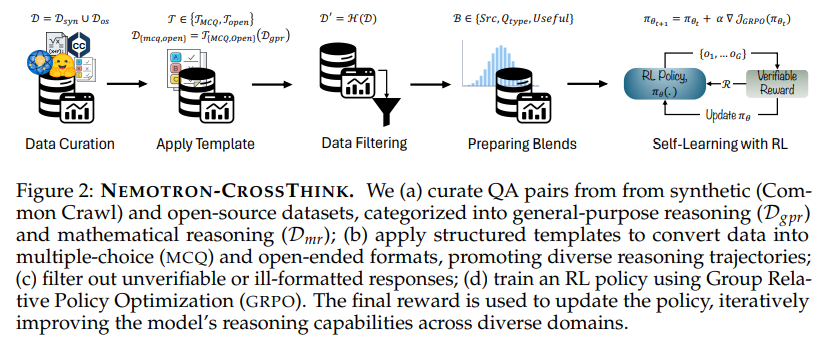
NEMOTRON-CROSSTHINKは、LLMの自己学習を数学分野を超えてスケールさせるための体系的なフレームワークです。そのプロセスは、主に以下のステップから構成されます。
- データキュレーション (Data Curation): 多様なソースから質問応答(QA)ペアを収集します。これには、インターネット上の膨大なテキストデータ(Common Crawl)から合成されたデータや、既存のオープンソースQAデータセットが含まれます。収集されたデータは、一般推論(Dgpr)と数学推論(Dmr)という二つのカテゴリに分類されます。
- テンプレート適用 (Apply Templates): 収集されたデータ、特に合成データに対して、多肢選択(MCQ)形式や自由記述形式といった構造化されたテンプレートを適用します。これにより、モデルが生成すべき回答の回答空間を制限し、多様な推論プロセスを促進します。
- フィルタリング (Data Filtering): 適用されたテンプレートに従っているか、そして生成された回答が検証可能であるかを基準にデータをフィルタリングします。これにより、不適切だったり、RL学習のための報酬を与えるのが難しいサンプルを除外します。
- データブレンド (Prepare Blends): 異なるデータソースやドメインのデータを効果的に組み合わせるための「ブレンドレシピ」を作成します。学習効果を最大化するための最適なデータ比率などを検討します。
- 強化学習による自己学習 (Self-Learning with RL): 準備された多様なデータを活用し、RLを用いてLLMの推論能力を洗練させます。検証可能な報酬モデルを用いて、モデルの応答が良いか悪いかを評価し、ポリシー(行動方針)を更新していきます。
この体系的なアプローチにより、NEMOTRON-CROSSTHINKは、単に大量のデータを学習するだけでなく、多様な知識領域と推論戦略を効果的に取り込み、モデルの汎化能力と効率性を高めることを目指します。
多様なデータの活用:キュレーションとテンプレート
NEMOTRON-CROSSTHINKの基盤となるのは、その多様なデータです。本フレームワークで使用されるデータセット(Nemotron-CrossThinkデータセット)は、大きく分けて合成データ(Dsyn)とオープンソースデータ(Dos)から構成されます。
合成データは、Common Crawlのような広範なウェブテキストから、特定のドメインをシードとして質問応答ペアを自動生成することで得られます。これにより、既存のデータセットだけではカバーしきれないような、多様なトピックや表現を含むデータを大規模に用意することができます。
オープンソースデータとしては、「Natural Reasoning」 や「MMLU [Train]」 のような既存の高品質なQAデータセットを利用しています。これらのデータセットは、STEM(科学、技術、工学、数学)分野はもちろん、経済学、社会科学など、幅広いドメインを網羅しています。
収集されたデータは、さらに一般推論(Dgpr)と数学推論(Dmr)に分類されます。一般推論データ(Dos_gpr、 Dsyn_gpr)は、科学、人文科学、法律、社会科学など多岐にわたる分野を対象とします。一方、数学推論データ(Dos_mr、 Dsyn_mr)は、数学に関連する問題を含みます。
このように多様なドメインのデータを集めるだけでなく、NEMOTRON-CROSSTHINKでは、構造化されたテンプレートを適用することが重要視されています。特に、合成データに対しては、質問を多肢選択形式(MCQ)または自由記述形式に変換するテンプレートが適用されます。例えば、以下のようなテンプレートが使用されます:
<|im_start|> A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. The reasoning process and answer are enclosed within <think> </think> and <answer> </answer> tags, respectively, i.e., <think> reasoning process here </think> then <answer> answer here </answer>. \n\nUser: [ここに質問文] \nPlease reason in <think></think> and put your solution in <answer> put your final answer inside \boxed{} </answer>.\n\nAssistant:\n<think>\nこのテンプレートを見るとわかるように、モデルにはまず思考プロセスを<think></think>タグ内に生成させ、最終的な答えを\boxed{}タグの中に含めるように指示しています。このようなテンプレートを用いることで、モデルがどのように推論を進めるかを制御・観察しやすくなり、また、後述する報酬設計を容易にすることができます。異なる形式の質問(MCQと自由記述)を学習に含めることは、モデルが多様な認知戦略(例えば、MCQでは選択肢の評価、自由記述ではゼロから生成)を習得するのに役立ちます。
検証可能な報酬モデリングの実現
強化学習において、モデルの行動が良い結果につながったか(=正しい推論ができたか)を評価し、それに応じて「報酬」を与えることが基本的な学習の流れです。数学問題のように正解が一つで明確な場合は、モデルが出力した答えが正解と一致するかどうかで報酬を設定できます。しかし、一般的な推論タスクでは、正解が複数あったり、答えの正しさを自動で判断するのが難しい場合が多々あります。これが、数学以外の領域にRLを拡張する上での大きな障壁でした。
NEMOTRON-CROSSTHINKでは、この課題に対して、前述のテンプレート適用とフィルタリングというアプローチで取り組みます。テンプレートによって回答の形式を構造化し、さらに検証可能な回答のみをフィルタリングして学習に使用します。
具体的には、ルールベースの報酬システムを採用しています。これは、モデルの出力に対して、あらかじめ定められたルールに基づいて報酬を与える仕組みです。NEMOTRON-CROSSTHINKの報酬関数 R は、精度報酬(Racc)とフォーマット報酬(Rformat)という二つの要素の論理積(AND)として定義されます。
R = Racc ∧ Rformat
これは、モデルの出力が正解である(精度報酬が1)かつ、指定されたフォーマットに従っている(フォーマット報酬が1)場合にのみ、全体の報酬が与えられる(報酬が1になる)ことを意味します。それ以外の場合は報酬が0になります。
精度報酬 Racc は、モデルの応答が「グラウンドトゥルース(正解)」と一致するかどうかで決まります。ここで、「一致するかどうか」の判断は、多肢選択問題であれば選択肢の記号や内容、自由記述問題であれば定められた基準(例えば、\boxed{}タグ内の最終的な答え)に基づくと考えられます。ソースからは、\boxed{}タグ内の最終的な答えとグラウンドトゥルースを比較していることが読み取れます。
フォーマット報酬 Rformat は、モデルの出力が<think></think>と\boxed{}という定義済みのタグ構造に従っているかどうかで決まります。推論プロセスが<think></think>内にあり、最終的な答えが\boxed{}内にある、という形式が正しいフォーマットとされます。
このように、回答の形式をテンプレートで制限し、その形式と内容の正しさをルールベースで自動検証可能にすることで、数学以外のドメインにおいてもスケーラブルで検証可能な報酬モデリングを実現しています。これにより、多様な汎用推論タスクに対してRLを効果的に適用できるようになったのです。
強化学習による推論能力の向上
NEMOTRON-CROSSTHINKでは、前述のようにキュレーション、テンプレート適用、フィルタリングによって準備された多様なデータを使い、強化学習によってLLMの推論能力を学習します。学習には、Group Relative Policy Optimization (GRPO) という手法が採用されています。
GRPOは、ポリシーベースの強化学習アルゴリズムの一種です。ポリシーとは、特定の状況(プロンプト)に対してモデルがどのような応答(トークン)を生成するか、という行動方針のことです。RL学習では、このポリシーを更新することで、より良い応答(=報酬が高くなる応答)を生成できるようモデルを訓練します。
GRPOの特徴は、評価のための「クリティックモデル」という別のモデルを使用せず、複数のサンプル出力(グループ)の報酬を比較することで、ポリシーの改善方向(アドバンテージ)を推定する点にあります。これにより、学習の効率を高め、必要とされるメモリ量を削減できるとされています。具体的なアルゴリズムは複雑ですが、概念としては、複数の応答候補を生成し、それらの良し悪し(報酬)を相対的に評価することで、モデルがより良い応答を生成するように学習を進めるものと捉えていればよいとおもいます。ポリシー更新の数式が論文に示されています。

学習プロセスでは、ベースモデルとしてQwen2.5-7BやQwen2.5-32Bといった、既に高い性能を持つLLMが使用されます。これらのベースモデルに対して、GRPOを用いたRL学習が施されます。トレーニングデータには、様々なドメインからの異なる形式の質問が混在しています。これにより、モデルは多様な推論タスクに同時に対応できるよう学習を進めます。
効果的な学習のためのデータ戦略:ブレンドとフィルタリング
NEMOTRON-CROSSTHINKの重要な要素の一つは、学習データの「ブレンド戦略」です。多様なドメインのデータを集めただけでは十分ではなく、それらをどのような比率で組み合わせるか(ブレンドするか)が、最終的なモデルの性能に大きく影響します。本研究では、様々なブレンド比率の効果を検証しています。
実験の結果、一般推論データ(Dgpr)と数学推論データ(Dmr)を2:1の比率で組み合わせたブレンド(Bgpr↑)が、最も効果的であることが分かりました。このブレンドで学習したモデルは、7つの多様な汎用推論および数学ベンチマークにおいて、ベースラインモデルに対して平均で13.36%の精度向上を達成しています。これは、単一ドメインのデータ(数学のみ、一般推論のみ)で学習するよりも、異なるドメインのデータを組み合わせることで、より幅広い汎化能力が引き出されることを明確に示しています。
また、NEMOTRON-CROSSTHINKでは、学習データの「難易度フィルタリング」についても検討されています。全ての学習データがモデルの能力向上に等しく貢献するわけではありません。特に、ベースラインモデルでも簡単に解けてしまうような「簡単な」問題は、RLによる能力向上にはあまり寄与しない可能性があります。
そこで本研究では、比較的小さいモデル(例: Qwen-2.5-7B)がゼロショット(追加学習なし)で間違える問題を「難しい」問題と定義し、そのような難しいサンプルだけをフィルタリングして学習に用いるアプローチを試みました。実験では、フィルタリングせずに全てのデータで学習する場合と、難しいサンプルのみで学習する場合を比較しました。その結果、より大きなモデル(Qwen-2.5-32B)において、難しいサンプルで学習することで、RLの効果がさらに増幅され、全ドメインで性能が向上することが確認されました。これは、質の高い、特にモデルにとってチャレンジングなデータで学習することが、性能向上に繋がることを示唆しています。
これらのデータ戦略(ブレンドとフィルタリング)は、RLを用いたLLM学習の成功において、使用するアルゴリズムだけでなく、どのようなデータを、どのように使うかが非常に重要であることを示しています。
評価結果と成果
NEMOTRON-CROSSTHINKで学習されたモデルの性能は、多様なベンチマークを用いて評価されています。評価対象には、数学ベンチマーク(MATH-500、AMC23)、そして一般推論ベンチマーク(MMLU、MMLU-PRO、AGIEVAL、GPQA-DIAMOND、SUPERGPQA)が含まれます。特にSUPERGPQAは、285分野の大学院レベルの知識を問う厳格なベンチマークであり、LLMの真の汎化能力を測る上で重要視されています。
主要な成果は、様々なベンチマークでの高い精度向上率として示されています。
- 数学ベンチマーク: MATH-500で +30.1%、AMC23で +27.5%
- 非数学(一般推論)ベンチマーク: MMLU-PROで +12.8%、GPQA-DIAMONDで +11.3%、AGIEVALで +15.1%、SUPERGPQAで +3.8%
これらの数値は、ベースラインモデルや、数学ドメイン特化のRL手法(ORZ など)と比較して、NEMOTRON-CROSSTHINKが数学だけでなく、幅広い一般推論タスクにおいても一貫して高い性能向上を達成したことを示しています。特に、単一ドメインで学習したモデルよりも、多領域データをブレンドして学習したモデル(Bgpr↑)が全体的に優れた結果を出しています。
さらに注目すべきは、応答の効率性です。NEMOTRON-CROSSTHINKで学習したモデルは、正解の回答を生成する際に、平均で28%少ないトークン数で済ませることができることが分かりました。これは、より焦点を絞った、効率的な推論ができていることを示唆しており、推論にかかる計算コストや時間(例えば、API利用時の費用など)の削減にも繋がります。例えば、一般推論タスクにおいて、多領域ブレンド(Bgpr↑)で学習したモデルは、数学のみで学習したモデルやORZと比較して、正解回答の平均トークン長が大幅に短くなっています。これは、タスクの複雑さに応じて推論の深さを調整し、正確性と簡潔さのバランスを取れている証拠と言えます。
これらの結果は、NEMOTRON-CROSSTHINKが提案する、多領域・多形式データのRLへの統合というアプローチが、LLMの推論能力の汎化と効率化の両面で非常に有効であることを実証しています。
※データセットを試すコード
本稿でご紹介したNEMOTRON-CROSSTHINKは、学習に**「Nemotron-CrossThink」データセット**を使用しています。このデータセットはHugging Face Hubで公開されており、誰でもアクセスして内容を確認したり、自身の研究や開発に利用したりすることが可能です。
ここでは、Google Colab環境を使って、このデータセットの一部を読み込み、構造を確認する簡単なPythonコード例をご紹介します。これはデータセットの内容を理解するための一歩として役立ちます。
# Google Colabでのデータセット読み込み例
# 必要なライブラリをインストールします
# すでにインストールされている場合はスキップされます
!pip install datasets
# datasetsライブラリからload_dataset関数をインポートします
from datasets import load_dataset
print("データセットをロードしています...")
# データセットをHugging Face Hubからロードします。
# 'nvidia/Nemotron-CrossThink' はデータセットの識別子です。
# split='train' はトレーニング用データセットを読み込むことを指定します。
# 大きなデータセットですので、環境によっては時間がかかる場合があります。
try:
dataset = load_dataset("nvidia/Nemotron-CrossThink", split="train")
print("データセットの構造:")
# ロードしたデータセットオブジェクトの情報を表示します。
# データセットのサイズ(レコード数)や、含まれるカラム(フィールド)が分かります。
print(dataset)
print("\nデータセットのカラム(フィールド)情報:")
# データセットに含まれる各カラムの名前とデータ型を表示します。
# 'data_source', 'prompt', 'reward_model', 'meta_data' といったフィールドがあることが確認できます。
print(dataset.features)
print("\nサンプルデータ:")
# データセットから最初の5件のサンプルデータを取得し、内容を表示します。
# 各サンプルは辞書のような形式で、各フィールドにアクセスできます。
# promptフィールドはリストになっており、実際の質問内容はその中の'content'キーに含まれます。
# 長いcontentは一部のみ表示します。
for i in range(5):
print(f"\n--- サンプル {i+1} ---")
sample = dataset[i]
print(f"data_source: {sample.get('data_source', 'N/A')}") # data_sourceフィールドの値
prompt_content = "N/A"
if sample.get('prompt') and len(sample['prompt']) > 0 and isinstance(sample['prompt'], dict):
# promptはリスト形式で、その要素は辞書形式です
prompt_content = sample['prompt'].get('content', 'N/A')
if len(prompt_content) > 500: # 長い場合は省略
prompt_content = prompt_content[:500] + "..."
print(f"prompt content (冒頭): {prompt_content}") # promptフィールドの内容(一部)
print(f"reward_model: {sample.get('reward_model', 'N/A')}") # reward_modelフィールドの内容
print(f"meta_data: {sample.get('meta_data', 'N/A')}") # meta_dataフィールドの内容
except Exception as e:
print(f"データセットのロードまたは表示中にエラーが発生しました: {e}")
print("データセットのフルバージョンや利用方法の詳細は、Hugging Face Hubのページを直接ご確認ください。")上記のコードを実行すると、Nemotron-CrossThinkデータセットの構造(カラム名など)や、いくつかのサンプルデータの内容(質問文、報酬モデル情報、メタデータなど)を確認することができます。特に、promptフィールドの中に質問の本文が含まれており、reward_modelフィールドに正解(ground_truth)などが含まれている様子が見て取れるでしょう。
このコードはデータセットを「見る」ための基本的なステップにすぎませんが、実際のRL学習に進むためには、このデータセットを読み込み、必要に応じて前処理(例: モデルの入力形式に変換)を行い、RLアルゴリズム(GRPOなど)を使ってモデルのパラメータを更新していくことになります。具体的な学習コードの実装はさらに複雑になりますが、データセットの構造を理解することはその第一歩となります。
ライセンスと利用について
Nemotron-CrossThinkデータセットは、Creative Commons Attribution 4.0 International License (CC BY 4.0) の下で利用可能です。これは、適切な帰属表示を行えば、商業目的でも非商業目的でも、データセットを共有、翻案して利用できることを意味します。
ただし、このデータセットはQwenモデル を用いて合成されたデータを含んでいるため、このデータセットを用いてAIモデルを作成、訓練、ファインチューニング等を行い、それを配布または利用可能にする場合には、Qwen License Agreement(Hugging Faceページにリンクがあります)の再配布および利用に関する要件に従う必要がある場合があることに注意が必要です。ご利用の際は、ライセンス条項を十分に確認してください。
まとめ
本稿では、LLMの推論能力を数学分野を超えて多様な領域に汎化させるための革新的なフレームワーク、NEMOTRON-CROSSTHINKについて詳細に解説いたしました。従来のRLを用いた推論能力強化が数学に偏っていた背景や、一般的な推論領域への拡張が抱える課題に触れ、NEMOTRON-CROSSTHINKがどのようにこれらの課題を克服しているのかをご紹介しました。
特に、多様なドメイン・形式のデータ収集と体系的な活用、テンプレートとフィルタリングによる検証可能な報酬モデリングの実現、効果的なデータブレンドと難易度フィルタリング戦略 といった技術的な側面が、本フレームワークの鍵となっています。これらのアプローチにより、NEMOTRON-CROSSTHINKで学習したモデルは、幅広い推論ベンチマークで高い精度を達成し、さらにトークン効率も大幅に向上する という優れた成果を示しました。
NEMOTRON-CROSSTHINKは、RLパラダイムのもとで、多領域データを活用してより能力が高く、信頼性が高く、そして汎化可能なLLMを訓練するための実践的かつ拡張可能なフレームワークとして期待されます。AIエンジニアの皆様にとって、LLMの推論能力を様々な応用分野で活用していく上で、本フレームワークの考え方やアプローチは非常に参考になることでしょう。提供されているデータセット を実際に触ってみることで、さらに理解を深めることができるはずです。








